前端面試的資料結構與演算法
- 面試大廠時會問的資料結構與演算法
- 資料結構(二叉樹)
- 1.找出二叉樹中節點值的和等于固定值的路徑
- 2.深度優先遍歷與廣度優先遍歷
- 2-1 深度優先遍歷
- 2-2 廣度優先遍歷
- 演算法
- 1.時間復雜度
- 2.判斷陣列中是否滿足有其中一項等于其它兩項之和;
- 3.堆疊和佇列
- 4.斐波那契數列
- 總結
面試大廠時會問的資料結構與演算法
資料結構(二叉樹)
首先來了解一下什么是二叉樹(Binary tree),它是樹形結構的一個重要型別,二叉樹的存盤結構及其演算法都較為簡單,二叉樹特點是每個結點最多只能有兩棵子樹,且有左右之分,一個是左側子節點,一個是右側子節點;在這里概念性的東西不做過多介紹,大家有興趣可以私下去了解,直接上題:
如下圖:
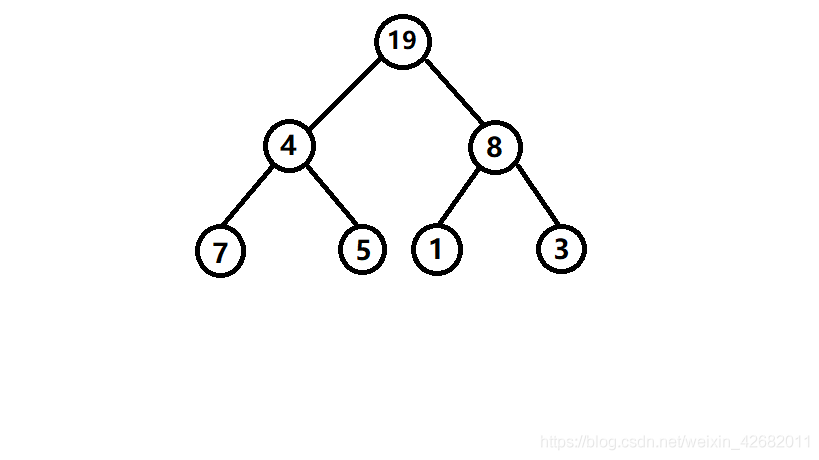
1.找出二叉樹中節點值的和等于固定值的路徑
查找上圖二叉樹中節點值的和等于固定值的路徑,并輸出滿足條件的所有路徑;(例如:節點值的和等于28的路徑);
分析: 那明顯有兩條路徑[19,4,5]和[19,8,1],那么它是如何通過代碼表達出來呢?大家一看到二叉樹這種題,可能由于之前了解的不多,感覺很高端無從下手,腦袋一片空白,首先就自亂陣腳了,那面試的結果就可想而知了,其實二叉樹就是一種資料結構,沒有那么難,我換一種問法大家就知道了;
var tree={
val:19,
left:{
val:4,
left:{
val:7,
},
right:{
val:5
}
},
right:{
val:8,
left:{
val:1
},
right:{
val:3
}
}
};
查找tree物件中val值相加等于28的路徑,并輸出滿足條件的所有路徑;這樣問大家是不是就好理解多了,其實二叉樹就是一種資料結構,沒那么難,下回再遇到相信大家肯定是不會暈頭轉向了,下面來分析一下這道題
var findPath = function (obj, sum) {
let arrPath = [];
let result = [];//用來存放滿足條件的所有路徑,最后把這個值return出去
let init = 0;
var isLeaf = function (root) {//判斷是否還有子節點
if (!root.left && !root.right) {
return true
};
return false;
}
function computed(root, init, arrPath, result) {
arrPath = [...arrPath, root["val"]]
init += root["val"];
if (init > sum) {
return false
};
if (init == sum && isLeaf(root)) {
result.push(arrPath)
return;
};
if (root.left) {
computed(root.left, init, arrPath, result);
}
if (root.right) {
computed(root.right, init, arrPath, result);
}
}
computed(obj, init, arrPath, result);
return result;
};
console.log(findPath(objData, 28));
最后的輸出結果:
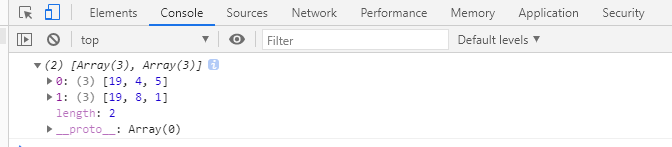
2.深度優先遍歷與廣度優先遍歷
2-1 深度優先遍歷
(如下圖1-2-3-4-5-6-7順序遍歷)
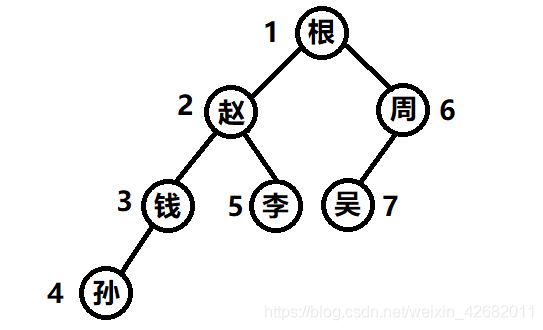
var data={
name: "根",
children: [
{
name: "趙",
children: [{
name: "錢",
children: [{
name: "孫"
}]
}, {
name: "李"
}]
},
{
name: "周",
children: [{
name: "吳"
}]
}
]
}
例題一:
按指定順序輸出值[“根”,“趙”,“錢”,“孫”,“李”,“周”,“吳”];
深度優先遍歷:
function find(data){//深度優先遍歷
const arr=[];
function result(data){
data.name&&arr.push(data.name);
while(data.children&&data.children.length>0){
result(data.children.shift());
};
};
result(data);
return arr;
}
console.log(find(data));
2-2 廣度優先遍歷
(如下圖1-2-3-4-5-6-7順序遍歷)
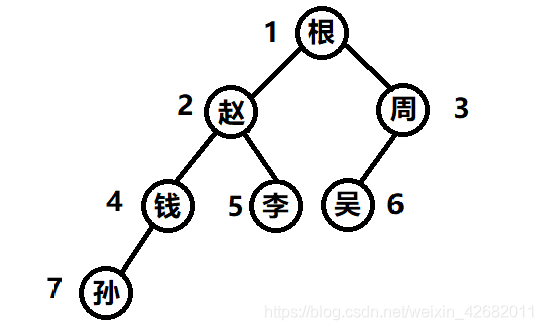
例題二:
按指定順序輸出值[“根”,“趙”,“周”,“錢”,“李”,“吳”,“孫”];
function find(data) { //廣度優先遍歷
let queue = [],item,total=[];
function result(data) {
if (data.children && data.children.length > 0) {
queue= [...queue, ...data.children];
}
data.name&&total.push(data.name);
while(queue.length!=0){
item=queue.shift();
total.push(item.name);
item.children?queue=[...queue,...item.children]:"";
}
};
result(data);
return total;
}
console.log(find(data));
演算法
1.時間復雜度
1.概念
一般情況下,演算法中基本操作重復執行的次數是問題規模n的某個函式,用T(n)表示,若有某個輔助函式f(n),使得當n趨近于無窮大時,T(n)/f (n)的極限值為不等于零的常數,則稱f(n)是T(n)的同數量級函式,記作T(n)=O(f(n)),稱O(f(n)) 為演算法的漸進時間復雜度,簡稱時間復雜度,
本次只介紹時間復雜度為O(1)、 O(n)、O(n2)、 O(log(n));
1.1 O(1)
function total(num){
return ++num
}
上述函式的時間復雜度為O(1)(常數);
1.2 O(n)
function fn(arr,item){
for(i=0;i<arr.length;i++){
if(arr[i]==item){
return true;
}
}
return false;
};
最壞情況下,假如陣列有10個元素,那就是搜索10次,有100個元素就是搜索100次,可以得出fn的時間復雜度O(n),n是輸入的陣列的長度
1.3 O(n2)
function bubbleSort(arr) {
var max = arr.length - 1;
for (var i = 0; i < max; i++) {
for (var j = 0; j < max - i; j++) {
if (arr[j] > arr[j + 1]) {
var temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
return arr;
}
這是比較常見的陣列冒泡排序;它時間復雜度就是O(n2);
如果用長度為10的陣列,開銷就是100 (102) ,如果用長度為100的陣列,開銷就是10000 (1002) ,時間復雜度O(n)的代碼只有一層回圈,而O(n2)的代碼是雙層回圈嵌套,如果是三層回圈嵌套,那時間復雜度就是O(n3);
1.3 O(log(n))
function search(arr,data){ // 二分搜索
var max = arr.length-1,
min = 0;
while(min<=max){
var mid = Math.floor((max+min)/2);
if(arr[mid]<data){
min = mid+1;
}else if(arr[mid]>data){
max = mid-1;
}else{
return mid;
}
}
return -1;
}
2.判斷陣列中是否滿足有其中一項等于其它兩項之和;
var arr = [0, 3, 6, 4,7,5,6,2,3,56,4];
function find(arr) {
arr=Array.from(new Set(arr)).sort();
if(arr[0]+arr[1]>arr[arr.length-1]){
return false;
}
for (var i = 0,j = arr.length - 1; i < j;) {
if (arr.indexOf(arr[j] - arr[i]) > -1 && (arr[j] - arr[i]) != arr[i]&& (arr[j] - arr[i]) != arr[j]) {//此處判斷的作用是排除6-3=3或者是6-0=6這種情況
return true;
} else if (i+1<j) {
i++;
} else if (j > 2) {
j--;
i=0;
}else{
return false;
}
}
}
console.log(find(arr));
注意:例如這道題其實面試官考察的不是你能不能寫出來,而是你寫的是不是最優解(時間復雜度),在寫代碼時盡量不要用回圈嵌套解決問題,可以用遞回或者其它的方式代替,思路要靈活,在寫代碼時一定要注意這點!
3.堆疊和佇列
堆疊和佇列都是線性表,只是限制了插入和洗掉的位置;
堆疊:它是一種具有后進先出性質的資料結構,也就是說后存放的先取,先存放的后取,舉個簡單的例子,就如同我們給手電筒裝電池,先放進的電池最后才能取出,最后放進的電池最先取出,只能插入在表尾,洗掉的時候也只能在表尾,就類似于我們操作陣列只能使用pop和push方法去解決一些問題,
佇列:FIFO(first in first out)它是一種具有先進先出性質的資料結構,也就是說先存放的先取,后存放的后取,舉個簡單的例子,就如同我們排隊買票,必須按照順序來,不能插隊,只能對表的頭部進行洗掉,尾部進行添加,就類似于我們操作陣列只能使用shift和push方法去解決一些問題;
例題:
實作用一個堆疊實作另一個堆疊的排序(一個堆疊中元素型別為整型,現在想將該堆疊從頂到底按從大到小的順序排序,只許申請一個輔助堆疊,
除此之外,可以申請新的變數,但不能申請額外的資料結構,如何完成排序?)
let arr=[6,8,5,7,4,2,9]
function stackSort(arr){
let stack=[],cur,item;
while(arr.length){
cur=arr.pop();
if(!stack.length){
stack.push(cur);
}else if(cur<stack[stack.length-1]){
stack.push(cur);
}else if(cur>stack[stack.length-1]){
while(stack.length){
item=stack.pop();
if(cur<item){
stack.push(item)
stack.push(cur);
break;
}else if(cur>item){
arr.push(item);
if(!stack.length){
stack.push(cur);
break;
}
}
}
}
}
return stack;
}
console.log(stackSort(arr));
思路:
- 遍歷給定堆疊(arr),堆疊頂出堆疊(cur=arr.pop()),cur與stack堆疊頂元素比較
- 如果cur小于stack堆疊頂元素值,那么將cur添加至stack堆疊頂
- 如果cur大于stack堆疊頂元素值,那么遍歷stack堆疊元素與cur進行比較,如果cur大于stack堆疊頂元素,那么就把stack堆疊頂元素重新壓入給定堆疊(arr),直到找到cur小于stack堆疊頂元素,再把cur壓入stack堆疊;
- 直到給定堆疊arr為空,回圈結束;
4.斐波那契數列
什么是斐波那契數列?
1,1,2,3,5,8,13,21,…
這個數列從第3項開始,每一項都等于前兩項之和,
- 遞回實作
function fibonacci(n){
return (n<=2)?1:fibonacci(n-1)+fibonacci(n-2)
}
- 回圈實作
function fibonacci(n){
let [a,b]=[0,1];
for(let i=0;i<n;i++){
[a,b]=[b,a+b];//起到了var t = a + b;a = b;b = t;的作用
}
return b
}
- 陣列的reduce實作
function fn2(n){
return Array(n).fill().reduce(([a,b],_)=>{
return [b,a+b]
},[0,1])[1]
}
總結
對之前前端面試的資料結構與演算法題做出的一些總結,可能有一些瑕疵,但希望能對正在找作業的您起到一些幫助作用,如果大家看完之后感覺寫的還可以,麻煩您幫忙點個贊+評論一下,謝謝!最后預祝大家作業順利!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/259850.html
標籤:AI