文章目錄
- 1 簡介
- 引入
- 2 學習基礎
- 3 逐飛方案
- 4 Tensorflow模型部署
- 搭建
- 讀取
- C語言
- 5 TC377
1 簡介
引入
b乎:如何評價2020屆智能車比賽的AI電磁組?
通過學長介紹,在假期觀看了吳恩達老師的機器學習與深度學習相關課程,
2 學習基礎
以視頻為主,筆記為輔,
在每周課程結束后,自己撰寫課后作業,與CSDN版課后作業和和鯨社區版本對比,
3 逐飛方案
逐飛方案
千等萬等終于等出逐飛的部署方案后便與隊友開始了方案嘗試,
經過兩天的測驗發現不論如何更改神經網路,都無法正確部署在單片機得到正確結果,
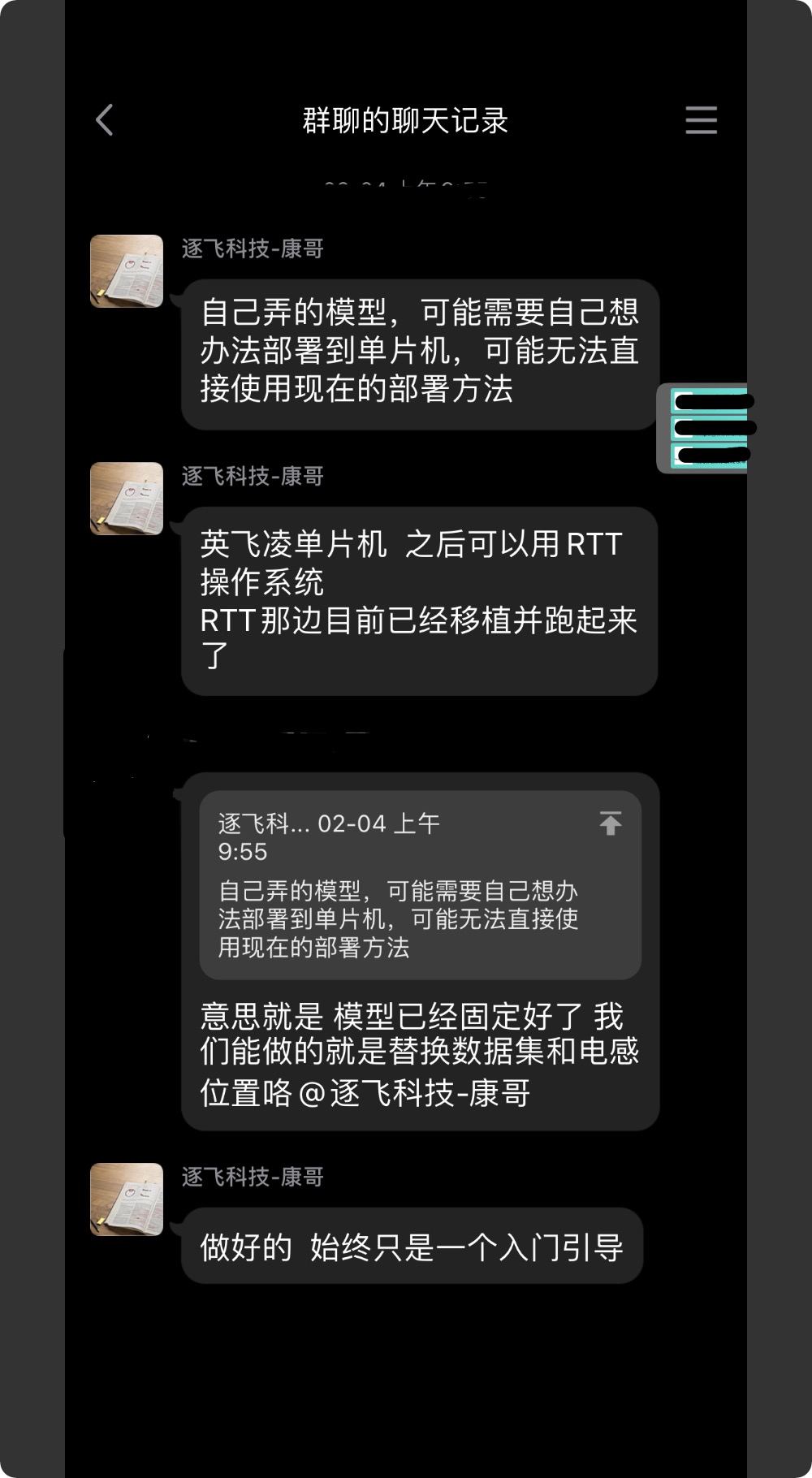
在看到此聊天記錄后,決定自己開發,深度學習神經網路難點在于超引數的調整與反向傳播的代碼構建,而在部署端只需要實作簡單的前向傳播即可,模型的搭建與調整都在框架下進行,整體難度不大,
4 Tensorflow模型部署
搭建
根據部署流程,在使用Keras搭建出神經網路后,匯入訓練集,并將模型保存在本地,
model = Sequential()
model.add(Dense(100, activation='relu', input_dim=2))
model.add(Dense(50, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(2, activation='softmax'))
model.compile(optimizer=keras.optimizers.SGD(lr=0.1), loss='mean_squared_error')
x_train = np.array([[100,100],[50,10],[80,30],[1,1],
[-2,1],[-70,80],[-200,25],[-1, 10]])
y_train = np.array([0,0,0,0,1,1,1,1])
y_train = to_categorical(y_train.T) # 獨熱碼
model.fit(x_train,y_train,epochs=500)
x_test = np.array([90,10])
print(x_test)
print(model.predict(x_test))
model.save('softmax1.h5')
讀取
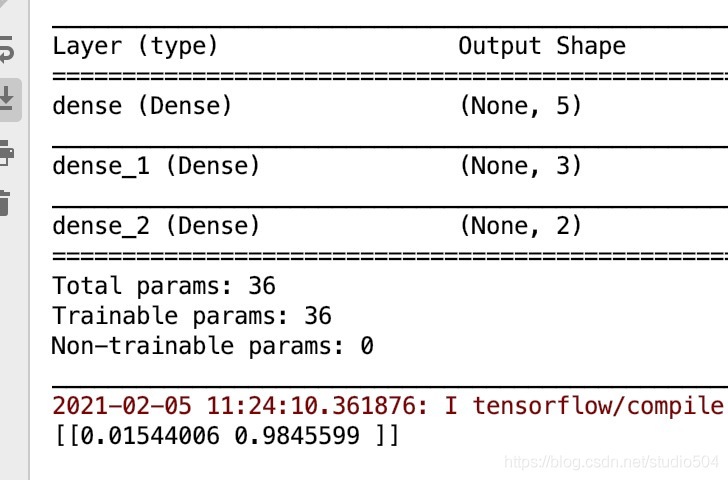
model = load_model('softmax1.h5')
model.summary()
x_test = np.array([0, 0])
x_test = np.reshape(x_test,(1,2))
print(model.predict(x_test))
列印出模型概要,并輸入測驗集,
def Kernel_transform(Kernel, f):
def Bias_transform(Kernel, f):
def Weights_transform(Hide_num, Kernel, Bias, f):
def Shape_transform(dense_kernel, dense_bias , f):
def quantitative_model_weights(in_file_name, out_file_name):
quantitative_model_weights('softmax1.h5', 'Weights.c')
接下來撰寫讀取函式,注意處理權重陣列的{ , } \n,
運行得到檔案Weights.c,
//圖片與代碼不符,找不到老圖拿新圖湊數
舊版
新版(添加了宏定義與維度陣列便于使用


C語言
在C語言端,我們只需要實作神經網路的前向傳播即可,

讀出了各層權重后,撰寫C端代碼
盡管官網標注TC377有DSP,經網上搜尋、詢問乾勤科技技術人員甚至翻閱芯片手冊,并未找到相關描述,決定棄置向量化吳恩達老師對不起 ,以回圈的方式實作前向傳播,
void autoModel_Predict(double* X_in, double* Y_out, int layers);
int main()
{
double y_test[2] = {0};
double x[] = {0,0};
autoModel_Predict(x, y_test, 1);
printf("%lf\n%lf", y_test[0], y_test[1]);
return 0;
}
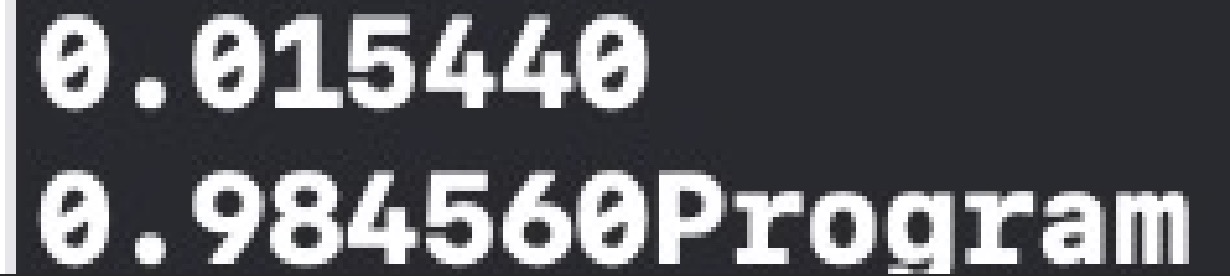
可以看到結果與py下運行一致,至此移植成功,
5 TC377
代碼最侄訓是要落實到單片機的,因本人是mac os,所以找來了我的好哥兒們 黃大佬 幫我們測驗,
在搭建了與逐飛相同數量的隱藏層后,匯出引數,TC377 300M主頻下 使用core_0的運算時間為1868us,
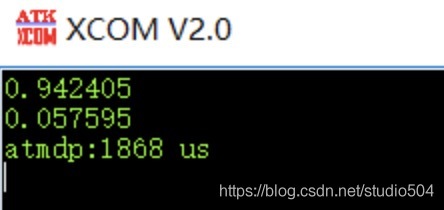
逐飛:5、任意打開一個串口助手以ascii方式接收,此時復位一下單片機即可看到如下圖所示,從顯示的資訊可以看到,運行一次模型所需的時間大約為502us,
逐飛在將輸入、輸出、權重全部量化成int8后運行速度在502us,自己構建部署的全double輸入,計算用時1868us,
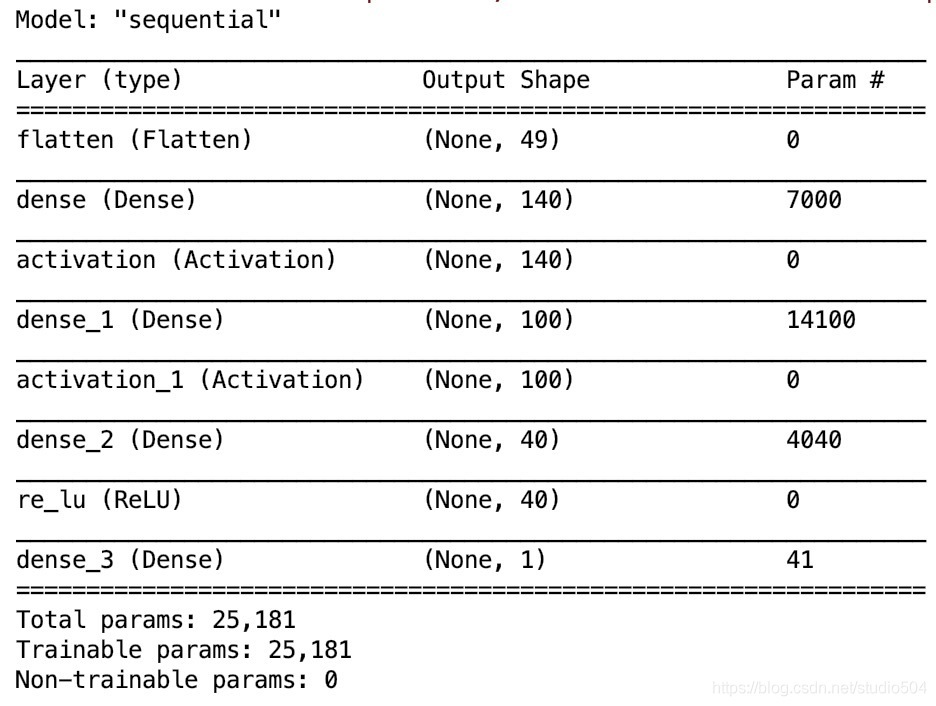
以舵機50Hz 也就是20ms控制頻率來看,全double型別計算在此運算效率下是綽綽有余的,甚至攝像頭組也可部署此方案
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/259852.html
標籤:AI