面向機器閱讀理解的雙向認知思維網路

專知閱讀鏈接
摘要
本文從互補學習系統理論的角度提出了一種新的閱讀理解雙向認知知識框架(BCKF),它旨在模擬大腦中兩種回答問題的思維方式,包括逆向思維和慣性思維,為了驗證該框架的有效性,我們設計了一個相應的雙向認知思維網路(BCTN),對文章進行編碼,生成一個給定答案(問題)的問題(答案),并對雙向知識進行解耦,該模型具有逆向推理的能力,有助于慣性思維產生更準確的答案,在DuReader資料集中觀察到有效地改善,證實了我們的假設,即雙向知識有助于QA任務,同時,這個新穎的框架也展示了機器閱讀理解和認知科學的一個有趣的視角,
1. 介紹
機器閱讀理解(MRC)已經取得了長足的進步,一系列的神經模型在一些基準上,如SQuAD,迅速接近人類的對等水平,然而,現有的方法在認知科學的水平上還處于初級階段,近年來,腦科學和心理學為類腦計算的發展和模擬人類的感知、思考、理解和推理能力提供了重要的基礎,
思維是人腦對客觀事物的性質、相互關系和內在規律的概括和間接反映,在心理學中,有兩種思維是互補的:一種是從前向刺激到后向刺激的慣性思維,另一種是從后向刺激到前向刺激的逆向思維,比如數學中常用的反證法,就是對結論取反,一直推導到矛盾結束,具體地說,在MRC任務中,這兩種思維可以看作是從問題(答案)到答案(問題)的推理程序,例如,如圖1所示,我們可以通過定位物體{懷孕的孕婦}和{枇杷}很容易得到答案,相反地,生成問題可以通過閱讀答案和文章來推理,這個答案描述了兩個方面的問題,包括{孕婦能吃枇杷}和{孕婦吃枇杷有什么好處},我們希望這種逆向推理問題的能力能夠提高閱讀理解任務的表現,

以往的方法只考慮一個正向的邏輯關系,即基于給定的問題和文章,他們忽略了給定段落和答案之間的反向關系,盡管有相關作業提出了一個既問又答的聯合模型,但它將正向和逆向的知識耦合起來,而不是以一種解耦合的方式進行處理,類似的,我們假設逆向推理問題的能力可以幫助模型獲得更好的性能,這部分源于心理學的觀察,即在閱讀時設計問題可以幫助學生提高閱讀和理解的文本處理能力,
因此,可以從人類的認知程序中獲得對問題解決方案的見解,互補學習系統理論(CLST)認為,人腦包含互補的學習系統,在我們試圖理解一個經歷過的情況時,支持同時使用許多資訊源,其中一個系統是通過累積學習逐步獲得一個完整的知識體系,包括我們對詞義、常見事物性質和熟悉情景特征的知識,就像慣性思維一樣,長時間學習現實世界中不同事物之間的關系,另一個系統是一個類似于逆向思維的快速學習系統,它的目標是從另一個不尋常的角度來刺激和增強大腦中不經常使用的回路區域
2. 雙向認知知識框架
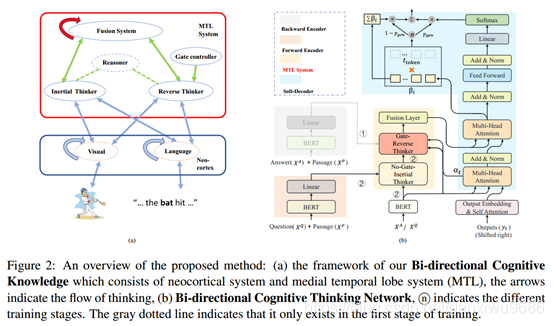
在互補學習系統理論(CLST)的啟發下,我們提出了雙向認知知識框架(BCKF),如圖2(a)所示,藍色和方塊包含圍繞一組輸入組織的新皮層系統,紅盒是內側顳葉(MTL)系統,其中藍色橢圓形(融合系統、慣性思考器、逆向思考器、推理機和門控制器)代表與橙色橢圓有著直接或間接相關的關系,這些橙色的橢圓定義為包含少量資訊(如視覺和語言輸入)的輸入池,綠色箭頭表示不同藍色橢圓之間的學習連接,它們將嵌入的元素系結在一起,以便以后重新激活,綠色虛線表示雙向思考者包含推理模塊,藍色箭頭表示不同系統之間的資訊傳輸,紅色和藍色的圓形箭頭表示自我學習和自我更新,控制者決定記憶中逆向思維的刺激強度,以便在不同的情況下做出不同的決定,最后,理解系統通過慣性思維和逆向思維相結合來指導模型的行為和對語言的理解,
3. 方法
本文提出了雙向認知知識框架(BCKF),并設計相應的雙向認知思維網路(BCTN)來驗證逆向思維的有效性,如圖2所示,
該方法概述:(a)我們的雙向認知知識框架由大腦皮層系統和內側顳葉系統(MTL)組成,箭頭表示思維的流動,(b)雙向認知思維網路,n表示不同的訓練階段,灰色虛線表示它只存在于訓練的第一階段,
根據圖2的概述,我們提出的基于雙向認知知識框架的模型由以下模塊組成,模型的訓練包括兩個階段,
在{第一階段}(反向編碼器->基于門控的反向思考器->融合層->軟解碼器)中,反向編碼器模擬答案和文章之間的互動關系,生成問題,稱為反向思維訓練,
前向編碼器類似于具有不同引數和輸入的反向編碼器,在{第二階段}(正向編碼器->無門的慣性思考器->基于門控的反向思考器->融合層->軟解碼器)期間,使用給定的段落和問題進行再訓練,生成最終的答案,稱為慣性思維再訓練,
內側顳葉(MTL)系統包括基于門控的反向思考器、無門的慣性思考器和融合層,基于門控的反向思考器從逆向的一面學習神經元的反向連接,并決定記憶中反向思維的刺激強度,無門的慣性思考器建立文章和問題的正向關系,融合層結合雙向知識為解碼做準備,
軟解碼器輸出一個指標生成器加復制機制的答案(問題),以綜合詞匯分布和源輸入的tokens分布,
3.1 逆向思維訓練
在這一節中,我們用答案和文章訓練基于門控的反向思考器,其中保留的引數被視為大腦中反向回路的連接,所述圖2(a)中的控制器,其確定存盤器中反向思維的刺激強度,以在不同的情況下做出不同的決定,最后,解碼器根據答案推斷出問題,
反向編碼器
我們使用BERT的編碼器,添加了特殊分類嵌入([CLS]),它對兩個句子之間的蘊涵資訊進行編碼,并用一個特殊的符號([SEP])將答案A和段落P分開,輸入的總長度是L=(K+N+3),其中K和N分別是答案和文章的長度,為了review答案(問題),找到答案(問題)相關的語意資訊,我們再用一個BERT對答案(問題)進行編碼,得到一個帶有K+2個tokens的純答案向量V,
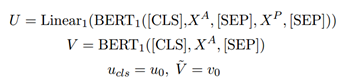
基于門控的反向思考器
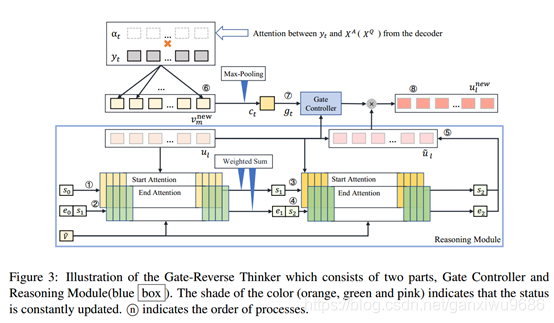
示意圖說明,它由兩部分組成:門控制器和推理模塊(藍框),顏色的陰影(橙色、綠色和粉色)表示狀態不斷更新,n表示行程的順序,
如圖3所示,推理模塊(藍框)包含由開始(橙色)和結束(綠色)子塊組成的推理塊,這兩個子塊具有時序依賴性,即在計算結束子塊時需要考慮起始子塊的結果,推理模塊模擬人類的思維程序,通過多個推理步驟不斷挖掘U和V之間的關系,在第j步推理程序中,sj和ej是推理的起始和結束向量,可以看作是隱藏狀態來增強U的表示,
最終的推理向量s2和e2基于與答案(或問題)的相關性融合所有可能的推理片段,此外,思考器基于已經解碼的詞來計算門控向量g,以確定記憶中逆向思維的刺激強度,因此我們可以得到最終的隱層狀態的表示:
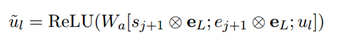
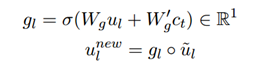
ui 表示的BERT的第l個token編碼,gi 表示第l個token的打分,最終的unew即編碼器的輸出表示,
融合層
為了將逆向思維和慣性思維相結合,我們采用了Wang等人(2018a)中使用的融合核來更好地理解語意:
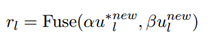
軟解碼器
我們在單詞嵌入層和self-attention提供的嵌入之上使用了一組Transformer解碼器塊,此外,還使用了指標softmax機制,該機制學習在從檔案復制單詞和從指定詞匯表生成單詞之間進行轉換,
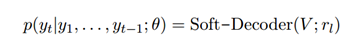
3.2 慣性思維再訓練
接下來我們會重復第二階段的訓練,同樣的以BERT作為正向編碼器,經過無門的慣性思考器得到正向的知識,同時基于門控的反向思考器基于第一階段訓練得到的引數,模擬逆向的知識,在這個程序中,我們把雙向的知識進行了解耦合,得:
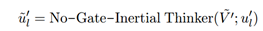
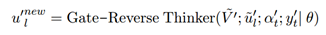
最終進行雙向知識得融合和解碼,兩個超引數表示的是人工設計的,來決定雙向思維的比例:
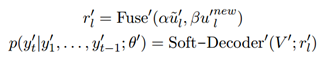
4. 實驗設定
4.1資料集
為了證明我們作業的有效性,我們選擇了DuReader基準資料集,它是從真實世界的搜索引擎(BaiDu)設計的,在資料量方面,它包含了300k個問題,并且資料被分成了一個訓練集(290k對)和一個開發集(10k對),測驗分割對公眾是隱藏的,因此,我們從開發資料中隨機抽取5k個問題-答案對作為驗證集,并使用其余的開發資料來報告測驗結果,至于評價指標,答案是人為生成的,因此DuReader中的評測指標我們考慮的是{ROUGE-L}(R-L)和{BLEU-4}(B-4),
4.2 實驗結果
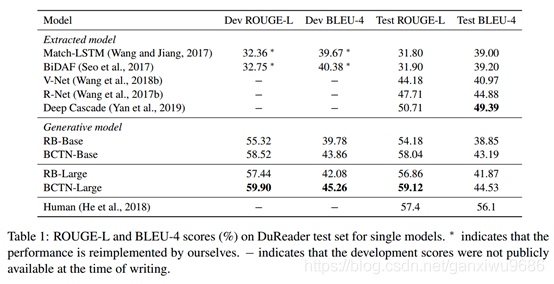
在DuReader資料集中,基線可分為三類:最新模型、RoBERTa-base(RB-base)模型和RoBERTa-large(RB-large)模型,RB-base和RB-large表明我們直接使用預先訓練好的語言模型作為編碼器,而不需要MTL系統,為了降低模型的復雜度,以往的方法將其轉化為抽取任務,因此,我們將模型分為抽取模型和生成模型,如表1所示,我們在DuReader上的單個模型的主要結果優于BERT-Style的基線,在RoBERTa基礎模型上ROUGE-L和BLEU4分別增加了3.86%和4.34%,在RoBERTa大型模型上,ROUGE-L和BLEU-4分別增加了2.26%和2.66%,雖然我們的模型在BLEU-4上比提取模型略有下降,但它在ROUGE-L上的表現要優于它們約8.4%,這是因為抽取式模型相比而言,通常具有更好的性能,這一現象在生成摘要任務中也可以體現,
4.3 消融實驗和不同引數的影響
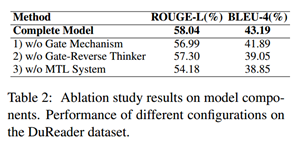
我們對我們的模型進行了消融研究,以討論在我們的框架中可以移除的增強組件的影響,表2顯示了我們提出的BCTN中不同部分的有效性,注意,通過洗掉所有不同的元素,配置3減少到RB基本模型,
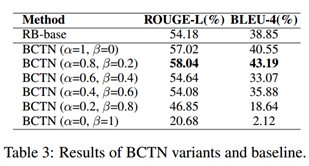
此外,我們手動設定不同的引數alpha和beta來探索雙向知識如何影響BCTN的性能,從表3可以看出,僅使用慣性思維時,模型在ROUGE-L上的性能達到57.02%,而加入反向思維后,模型達到了一個峰值,在模型只使用逆向思維而忽略慣性思維的情況下,模型的有效性顯著下降,這與心理學中的人類行為相一致,即逆向思維可以幫助慣性思維產生更準確的答案,僅僅使用逆向思維或慣性思維是不夠的,
4.4 Case study
定性地說,我們在加入雙向思考者之前和之后觀察到了一些有趣的例子,如表4所示,在案例1中,提出的模型輸出了一個生成性問題{如何通過“噩夢結束”}的大師級別,該問題的語意與gold question相同,我們提出的BCTN得到了正確的答案,并給出了更詳細的解釋,然而,RB基線輸出了一個錯誤的答案,尤其是句子{他們必須到達血},在案例二中,也可以得出同樣的結論,RB基線的答案描述的是枇杷的營養成分,而不是真正的問題對應的答案,但BCTN不僅給出了正確的反應,而且解釋了孕婦為什么能吃枇杷,在我們的模型的幫助下,答案變得更加可解釋和正確,說明我們的想法確實可以幫助系統回答更準確的問題,

5. 結論
本文從心理學角度提出了與雙向認知知識框架(BCKF)相對應的雙向認知思維網路(BCTN),BCTN通過模擬慣性思維和逆向思維,以雙向知識回答問題,我們將這兩個部分的知識解耦,進行最終的答案生成,為了確定記憶中反向思維的刺激強度,我們考慮解碼后的tokens來計算基于門機制的分數,我們證明了所提出的BCTN方法是有效的,它與文獻中關于DuReader的單模型方法相比具有競爭力,我們未來的作業將考慮使用不同的資料集和設計各種模型來模擬我們大腦的行為,以嘗試獲取人類水平的語言理解和智能,這篇論文的作業是我們在認知科學中的淺層理解,我們希望有更多的研究者能夠共同交流和學習,最后,我們相信我們的框架可以推廣到其他的生成任務,例如摘要生成和image caption等任務,
團隊介紹
中國科學院資訊工程研究所雛鷹團隊,在ACL、AAAI、IJCAI、TIP、ACM Multimedia、EMNLP、COLING等國際/國內會議及期刊上均有論文發表,同時也在2019 年世界視覺對話比賽,WMT 2020國際機器翻譯大會,SemEval2020國際語意評測大會,CCMT 2019全國機器翻譯大會取得TOP-3的成績,目前由胡玥老師和于靜老師帶領,學生總共13名,博士生10名,碩士生3名,主要的研究方向分為兩大類,一類是自然語言處理,一類是跨媒體智能分析,在自然處理領域中,主要研究機器翻譯,機器閱讀理解,對話系統,在跨媒體智能分析領域,主要研究視覺問答,視覺對話,跨媒體檢索以及影像視頻描述生成,歡迎對上述方向感興趣的研究學者和同學們加入到我們團隊共同學習!共同交流!
聯系郵箱:胡玥huyue@iie.ac.cn、于靜yujing02@iie.ac.cn
論文地址
:https://www.aclweb.org/anthology/2020.coling-main.235.pdf
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/259973.html
標籤:AI