1. Kafka 簡介及使用場景
1.1 寫在前面
我們提到訊息中間件,往往都會聊到,RabbitMQ,RocketMQ,Kafka,
對于剛入門訊息中間件,聽到這三個主流訊息中件,心中難免會有疑惑,這訊息中間件搞這么多干什么?傻傻分不清楚,況且都是訊息中間件,我開發中用哪個?知用而學,學以致用,本文將帶你聊聊 Kafka ,讓你知用,致用,
1.2 簡介
官網:http://kafka.apache.org/
Kafka 是最初由 Linkedin 公司開發,是一個分布式、支持磁區的(partition)、多副本的(replica),基于 zookeeper 協調的分布式訊息系統,
它的最大的特性就是可以實時的處理大量資料以滿足各種需求場景:比如基于hadoop的批處理系統、低延遲的實時系統、Storm/Spark 流式處理引擎,web/nginx 日志、訪問日志,訊息服務等等,用scala語言撰寫,
Linkedin于2010年貢獻給了Apache基金會并成為頂級開源 專案,
我摘取幾個關鍵字給大家強調一下:
分布式訊息系統、基于 zookeeper 、大資料處理、低延遲、scala 開發
那么 Kafka 相較于 RabbitMQ、RocketMQ,更加適用于大資料處理的場景且強依賴于 zookeeper ,
1.3 使用場景
日志收集:
使用 Kafka 作為中間層收集各種服務的 log 日志,最后將訊息發送給下游 consumer 進行消費處理,如 hadoop、hbase、soler 、es 等,
訊息系統:
作為訊息中間件,快取訊息,解耦上下游系統,
大資料收集運營監控處理分析:
用戶活動跟蹤、運營指標監控等一些分析型資料的收集分發處理等,
如記錄 web 或者 app 用戶各種活動記錄,如 瀏覽、點擊、搜索 等,這些活動資訊被各個服務器發布到 kafka 的 topic 中,然后訂閱者通過訂閱這些 topic 來做實時的監控分析,或者裝載到 hadoop、資料倉庫中做離線分析和挖掘,
這里我給大家總結一個關鍵字 實時大資料分析與監控
其實相對于傳統的訊息中間件的用法上 Kafka 更偏向于大資料處理的體系上 ,屬于 hadoop 全家桶的一員,那么我們對于訊息中間件的常規使用,如應用解耦,削峰填谷上,我們會選擇 RabbitMQ 、或者 RocketMQ 這類訊息中間件
關于 RabbitMQ 歡迎閱讀文章:訊息佇列之-RabbitMQ
2. Kafka 核心概念點
如果要了解 Kafka 首先需要搞懂其核心概念點,后面到架構就是順水推舟的事情了,
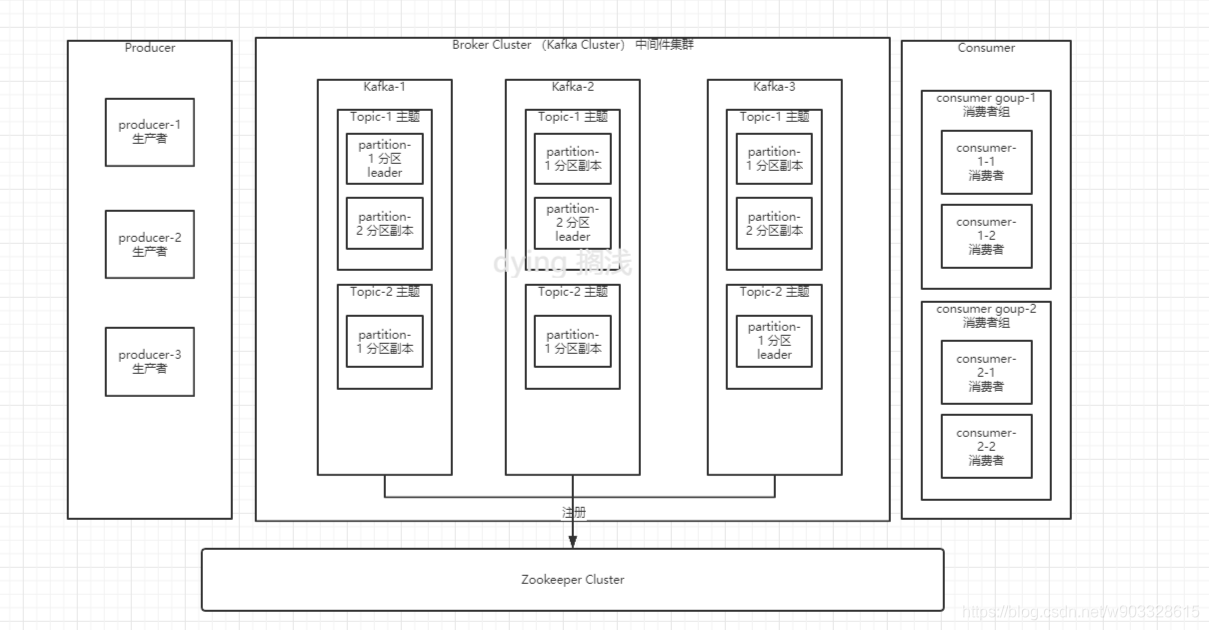
Broker 訊息中間件
一個 Kafka 節點就是一個 broker,一 個或者多個 Broker 可以組成一個 Kafka 集群
Topic 主題
Kafka 根據 topic 對訊息進行歸類,發布到 Kafka 集群的每條訊息都需要指定一個 topic
Partition 磁區
物理上的概念,一個 topic 可以分為多個 partition,每個 partition 內部訊息是有序的
Producer 訊息生產者
向 Broker 發送訊息的客戶端
Consumer 訊息消費者
從 Broker 讀取訊息的客戶端
ConsumerGroup 消費組
每個 Consumer 屬于一個特定的 Consumer Group,一條訊息可以被多個不同的 Consumer Group 消費,但是一個 Consumer Group 中只能有一個 Consumer 能夠消費該訊息,
相信如果看過我的上篇文章 訊息佇列之-RabbitMQ 的同學,或者了解過 RabbitMQ 的同學對上面這組概念都是比較熟悉了,相對于 RabbitMQ來說,Kafka 給出了幾個陌生的概念 ,我這里給出一張圖來對比一下
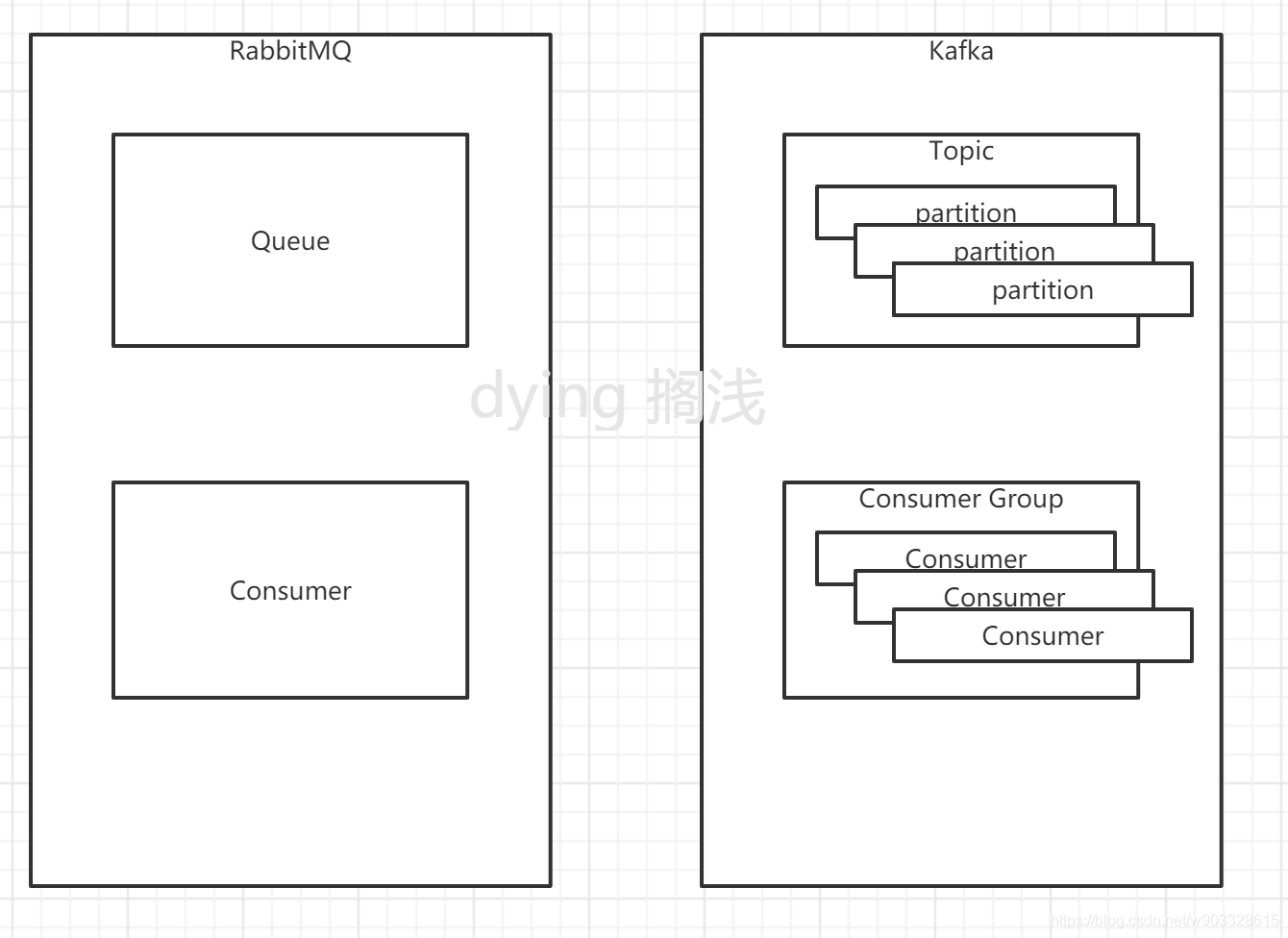
相對于 RabbitMQ 來說 Kafka 對訊息的最終存盤位置 “佇列” 和訊息消費方 “消費者” 做了更細致的分類,
Queue 和 Topic 的功能差不多 但是 Topic 下多了 partition 的概念,在 Kafka 中最終的資料時存盤在 partition 磁區中的,這個 Topic 磁區化為服務的水平擴容帶來了很大的便利,理論上這個存盤是可以無限大的,只要你的機器夠多,而對于 Consumer ,Kafka 又給出了更大的一層 Consumer Group ,以組為一個消費單位,不同的組內的消費者,相同的訊息只可消費一次,
3. Kafka 安裝
Kafka 是依賴于 Zookeeper 及 JDK 的所以在安裝 Kafka 之前我們需要準備好 Zookeeper 及 JDK 環境,
安裝 JDK
yum install java‐1.8.0‐openjdk* ‐y
下載安裝 Zookeeper
wget https://mirror.bit.edu.cn/apache/zookeeper/zookeeper‐3.5.8/apache‐zookeeper‐3.5.8‐bin.tar.gz
tar ‐zxvf apache‐zookeeper‐3.5.8‐bin.tar.gz
cd apache‐zookeeper‐3.5.8‐bin
cp conf/zoo_sample.cfg conf/zoo.cfg
# 啟動zookeeper
bin/zkServer.sh start
bin/zkCli.sh
ls / #查看zk的根目錄相關節點
下載安裝 Kafka
# 2.12是scala的版本,2.6.1是kafka的版本
# 404 可以直接訪問 https://mirror.bit.edu.cn/apache/kafka 找到合適的地址
wget https://mirror.bit.edu.cn/apache/kafka/2.6.1/kafka_2.12-2.6.1.tgz
tar -xzf kafka_2.12-2.6.1.tgz
cd kafka_2.12-2.6.1
修改 Kafka 組態檔 config/server.properties
# 唯一標識 broker.id 該屬性在 kafka 集群中必須是唯一
broker.id=0
# kafka 部署的機器 ip 和提供服務的埠號
listeners=PLAINTEXT://your.ip:9092
# kafka 的訊息存盤檔案
log.dir=/data/logs/kafka‐logs
# kafka 連接 zookeeper 的地址
zookeeper.connect=your.zk.ip:2181
Kafka 服務啟動
基礎語法 kafka--server--start.sh [--daemon] server.properties
組態檔 server.properties 是必須的,-daemon 表示可以后臺運行
# 啟動 kafka,運行日志在 logs 目錄的 server.log 檔案里
bin/kafka‐server‐start.sh ‐daemon config/server.properties
# 后臺啟動,不會列印日志到控制臺 或者
bin/kafka‐server‐start.sh config/server.properties &
server.properties 部分核心配置解釋
| 引數 | 默認值 | 描述 |
|---|---|---|
| broker.id | 0 | 每個 broker 使用一個唯一的非負整數進行標識,你可以自定義但需要保證唯一 |
| log.dirs | /tmp/kafka-logs | 存放資料路徑,可配置多個,使用英文逗號分隔,每當創建新的 partition 會選擇磁區最少的路徑進行創建 |
| listeners | PLAINTEXT://:9092 | server 接受客戶端連接的埠,ip 配置 kafka 本機 ip 即可,如 PLAINTEXT://localhost:9092 |
| zookeeper.connect | localhost:2181 | zookeeper 注冊中心連接地址,多個使用英文逗號分隔 |
| log.retention.hours | 168 | 每個日志檔案洗掉之前保存的時間,默認資料保存時間對所有 topic 都一樣, |
| num.partitions | 1 | topic 默認磁區數 |
| default.replication.factor | 1 | 自動創建 topic 的默認副本數量,建議設定為大于等于2 |
| min.insync.replicas | 1 | 當 producer 設定 acks 為 -1 時,min.insync.replicas 用于指定 replicas 的最小同步數目(必須確認每一個 repica 的寫資料都是成功的),如果這個數目沒有達到,producer發送訊息會產生例外 |
| delete.topic.enable | false | 是否允許洗掉主題 |
4. 從命令列級別了解 Kafka 常用操作
創建主題
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic dyingGQ
成功:Created topic dyingGQ.
值得一提的是:當 producer 向一個 topic 發送訊息且 topic 不存在時,該 topic 會被自動創建
查詢存在的 topic 主題
bin/kafka-topics.sh --list --zookeeper localhost:2181
洗掉主題
bin/kafka-topics.sh --delete --topic dyingGQ --zookeeper localhost:2181
Topic dyingGQ is marked for deletion.
// 這里會提示你設定允許洗掉主題,否則不會有任何影響
Note: This will have no impact if delete.topic.enable is not set to true.
發送訊息
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic dyingGQ
>this is dying 擱淺
>hello kafka
消費訊息
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic dyingGQ
該命令默認消費最新的訊息,也就是說該命令執行后發送的訊息可以消費到,如果想消費歷史所有訊息可添加引數 --from-beginning :
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic dyingGQ
多主題消費
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --whitelist "dyingGQ|dyingGQ-1|dyingGQ-2"
單播消費
開啟兩個屬于同組的消費者,同一組別下只有一個消費者可以消費到訊息
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-property group.id=group1 --topic dyingGQ
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-property group.id=group1 --topic dyingGQ
多播消費
不同組可以同時消費同一條訊息
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-property group.id=group2 --topic dyingGQ
查看消費組名
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list
查看消費組訊息偏移量
對于 Kafka 來說,它以組為單位來記錄訊息消費的偏移量來實作多播訊息的消費,這樣訊息只需要存盤一份即可 ,
值得一提的是:訊息的消費情況只與消費組系結,與組下的消費者并無太大關系,即所有消費以組為準
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group group1
current-offset:當前消費組的已消費偏移量
log-end-offset:主題對應磁區訊息的結束偏移量(HW)
lag:當前消費組未消費的訊息數
5. Kafka 的存盤與磁區
總的來說,我認為訊息佇列最重要的,也是我們最應該關心的幾點就是:訊息的發送、訊息的接收、訊息的存盤 ,
對于發送和接收來說,相信通過上面的講解大家心里大概都有一定的理解了,這個時候我們來聊聊存盤,
Kafka 的存盤以 Topic 主題為單位,下分為多個邏輯磁區,就如同我們電腦存盤要分多個磁盤,或者說我們單個磁盤下要分多個檔案夾這樣的關系,
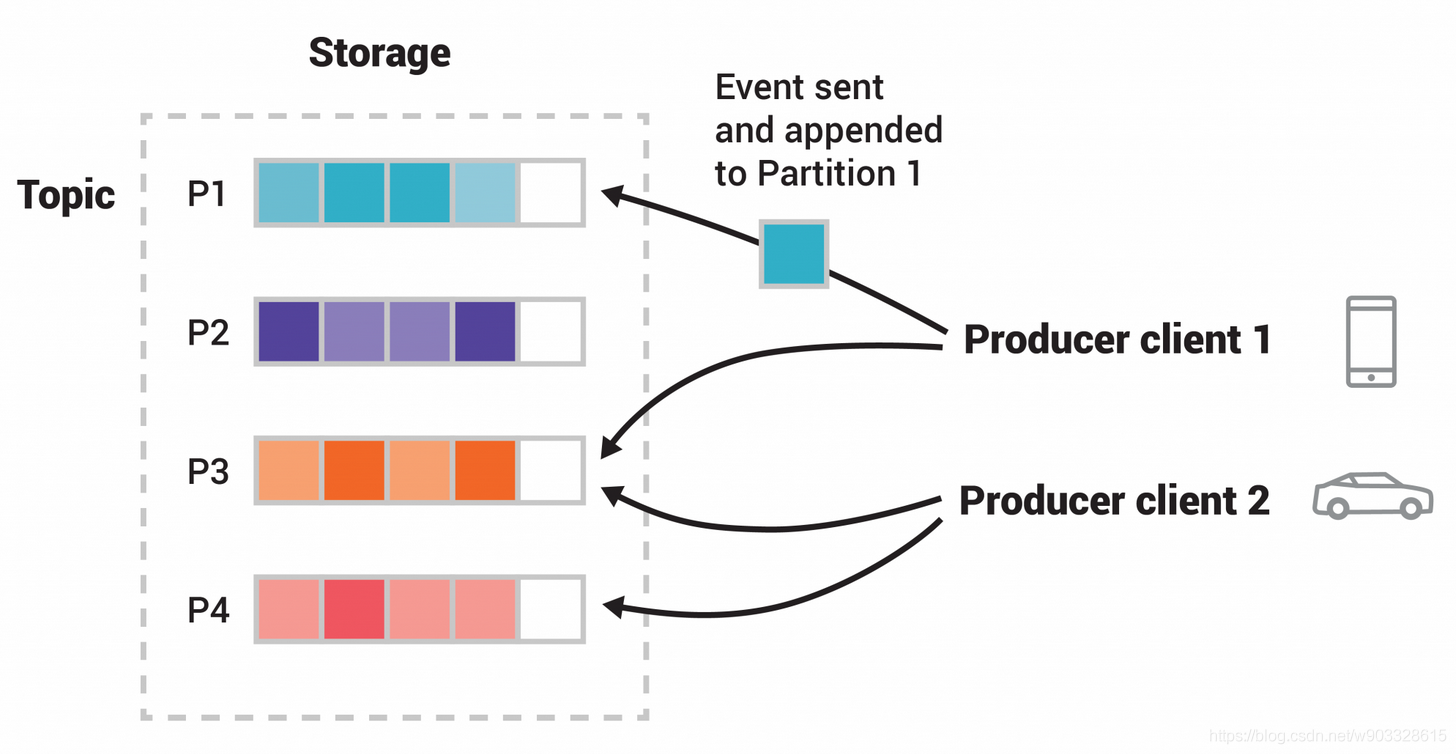
partition 是一個 有序的訊息序列 資訊最終存盤于 commit log 檔案 中, partition 中的訊息都對應一個唯一標識 offset 該存盤位置即我們在 server.properties 中配置的 log.dirs 地址

如圖中文稿所示 dyingGQ 為我們創建的話題,后面的編號 0 為磁區編號,
創建多磁區主題
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 2 --topic dyingGQ1
可以看到 Kafka 為我們的主題創建了兩個磁區的檔案夾 dyingGQ1-0 以及 dyingGQ1-1

查看磁區詳情
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic dyingGQ1

leader 該 partition 磁區相對于備份來說負責所有讀寫請求,
replicas 表示某個 partition 在哪幾個 broker 上存在備份,
isr 是 replicas 的一個子集,它只列出當前還存活著的,并且已同步備份了該 partition 的節點,
磁區擴容
可以執行以下命令對我們已有的主題進行磁區擴容
bin/kafka-topics.sh -alter --partitions 3 --zookeeper localhost:2181 --topic dyingGQ
可以看到執行成功后磁區檔案夾變成了 3 個

我們進入其中一個,真正的訊息資料就存放在 .log 檔案夾中

為什么 Topic 要進行 partition 磁區?
我認為主要的理由兩點:
- 方便水平擴容,分布式存盤可支持海量資料,
- 可以提供并行處理能力,
6. Kafka 集群
以上,基礎內容已經講解完了,那么既然說到 Kafka ,集群是一定逃不開的,而對于 Kafka 來說其設計上就是天然的集群,單機可以理解為集群中只有一個節點,重要的一點是 Kafka 集群的主從關系是以磁區即 partition 為單位的
嘗試啟動集群
我們可以在一臺機器上啟動多個 Kafka broker 實體來模擬真實的集群,為此我們需要創建多個 server.properties 檔案并更改部分配置:
拷貝組態檔
cp config/server.properties config/server-1.properties
cp config/server.properties config/server-2.properties
修改組態檔資訊 server-1.properties
broker.id=1
listeners=PLAINTEXT://192.168.65.60:9093
log.dir=/usr/local/data/kafka-logs-1
zookeeper.connect=192.168.65.60:2181
修改組態檔資訊 server-2.properties
broker.id=2
listeners=PLAINTEXT://192.168.65.60:9094
log.dir=/usr/local/data/kafka-logs-2
zookeeper.connect=192.168.65.60:2181
啟動多個實體
bin/kafka-server-start.sh -daemon config/server-1.properties
bin/kafka-server-start.sh -daemon config/server-2.properties
值得一提的是:Kafka 在啟動 JVM 時默認 虛擬機堆大小 是 1G ,所以如果你的記憶體不夠可以適當下調該值(至少大于等于 256M)
vim bin/kafka-server-start.sh

可以通過 zkCli 查看你的 Kafka 集群是否都已注冊成功


在集群環境下創建多磁區主題
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 2 --topic dyingGQ-replicated
查看 topic 主題詳情
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic dyingGQ-replicated
訊息生產:
bin/kafka-console-producer.sh --broker-list localhost:9092,localhost:9093,localhost:9094 --topic dyingGQ-replicated
>my test msg 1
>my test msg 2
消費訊息:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092,localhost:9093,localhost:9094 --from-beginning --topic my-replicated-topic
my test msg 1
my test msg 2
與之前的區別僅僅是增加了多臺 Kafka 的地址而已,
7. 集群特性
集群 partition 備份
Kafka 支持設定針對每個 partition 備份,可以將 partition 備份到不同的 broker 上,其中 leader partition 負責讀寫,其他 follower 僅負責同步,當 leader 掛掉后會從 follower 中選取新的 leader ,
訊息消費順序
一個 partition 同一時刻在一個 consumer group 中只能有一個 consumer 實體在消費,從而保證了消費順序,
consumer group 中的 consumer 實體的數量不能比一個 topic 中的 partition 的數量多,否則,多出來的 consumer 無法消費到訊息
Kafka 的訊息在單個 partition 上是可以保證順序的,但是在整體上無法保證順序消費
訊息消費模式
關于消費模式,Kafka 通過 消費組的概念可以靈活設定
如常見的 佇列模式 即 所有的 consumer 在同一個 consumer group 下,發布訂閱模式 則設定多個 consumer group 進行消費即可
總結
最后做一個總結,本文首先帶大家簡單介紹了一下 Kafka 的使用場景以及一些核心概念點,重點要理清楚 topic 和 partition 以及 consumer group 和 consumer 的一個對應關系,帶大家過了一遍 Kafka 的安裝及命令列常規使用流程,以及資料的持久化存盤,建議自己手動操作一遍加深印象,最后簡單聊了聊集群相關的配置及特性,如果有相關問題可以在評論區留言,如果本文對你有所幫助,歡迎轉發點贊收藏,喜歡我的文章歡迎關注公眾號,有語音版本等你來聽, 我是 dying 擱淺 我們下篇文章再見~

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/260007.html
標籤:其他
上一篇:Python_while回圈