?利用滑動視窗進行目標檢測時,低級做法是:滑動一下視窗,送入CNN執行一次分類,再滑一下,再分類,,,,這樣效率太低,
?我們很容易發現,在每次滑動得到的視窗卷積的程序中,很多地方是重復進行了卷積,那我們可不可以一次性送入整張圖片,直接得到所有滑動視窗的結果呢?
Sure!
?假設我們有個14x14x3的圖,其要送入如圖所示的+全連接的網路進行分類:
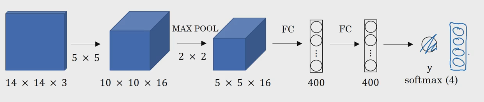
?那么由于全連接層的存在,會改變原先矩陣的結構,無法達到我們只傳入一整張圖實作所有滑動視窗的目的(即FC的存在會使輸入影像固定大小),
?所以我們先要將全連接層等價地變成卷積層,
How FC layer -----> Conv layer?
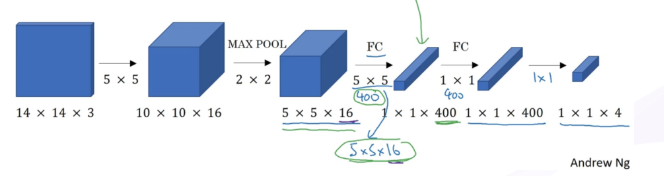
?So easy,看圖!最后一層卷積層我們得到了5x5x16的特征圖,
?1. 然后第一層全連接層我們換成采用400個5x5x16的卷積核進行卷積,
?2. 第二層卷積用400個1x1x400的卷積核進行卷積
?3. 最后用4個1x1x400代替softmax不就OK,
?其實這樣的操作和全連接是一樣的,因為我們得出的這400個節點,都是分別用400個卷積核核特征圖進行線性加權求和得到,所以和全連接層起到一樣的效果,
?(注:全卷積網路引數量沒有變,只是為了實作在卷積層上實作滑動視窗,在目標檢測中很有用)
Convolutional implementation of sliding windows:
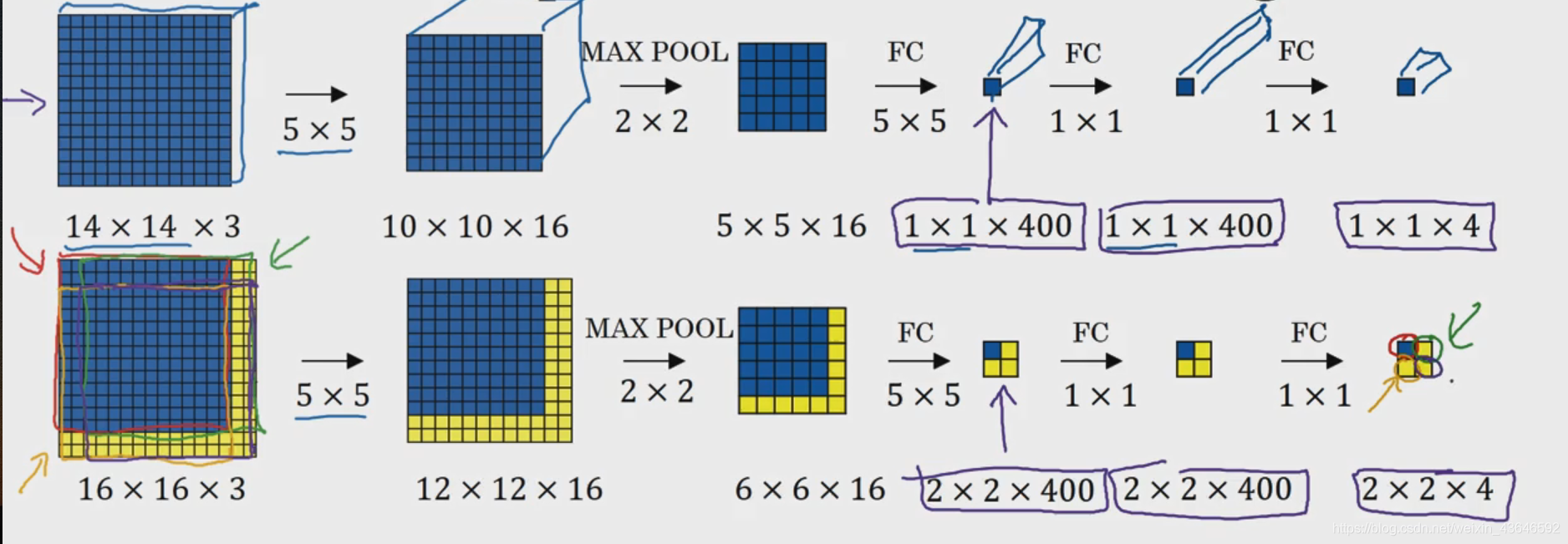
?假設輸入CNN的圖片為14x14x3,測驗圖片為16x16x3,
?那就需要移動視窗(視窗大小:14x14x3),得到4個14x14x3的圖片,分別將其輸入CNN,得到4個結果,
?這樣效率太低,存在很多重復的卷積運算,其實我們可以將整張16x16x3的圖輸入CNN,如上圖(下)所示,最后得出4個小方塊,其實每個小方塊對剛好就是對應的一個滑動視窗的預測結果(不信的話,你可以自己用筆圈一圈,看看卷積后的結果即懂),
?這里滑動步幅是2是如何實作的呢?其實是通過max-pooling中的池化引數為2,這就相當于以大小為2的步幅在原始圖片上應用CNN,
?以上我們就實作了在卷積層上應用滑動視窗,它能夠提高整個檢測演算法的效率,
?不過這種演算法仍然存在一個缺點,就是邊界框的位置可能不夠準確,其中一個能得到更精準邊界框的演算法是YOLO演算法,基本思想就是將影像劃分成nxn個grid cell,物件的中點落在哪個cell中,哪個cell就負責該物件的預測,,,,這里就不講YOLO了哈哈哈,
參考:Andrew Ng 的教學視頻
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/260150.html
標籤:其他
上一篇:Leetcode No.83 洗掉排序鏈表中的重復元素
下一篇:讀取某行檔案方法