目錄
一、BERT簡單認識
二、Google BERT以及中文模型下載
1、Google BERT原始碼下載
2、bert-as-server 框架下載
3、中文預訓練模型下載
三、bert生成中文句子向量
1、啟動BERT服務
2、中文句子向量編碼
四、cosine相似度計算
五、完整實驗代碼
一、BERT簡單認識
Google BERT預訓練模型在深度學習、NLP領域的應用已經十分廣泛了,在文本分類任務達到很好的效果,相比傳統的詞嵌入word2vec、golve,使用bert預訓練得到的效果有更好地提升,
這篇不會很深入復雜地分析bert的原理以及高級應用,而是從零開始,定位于初學者對BERT的簡單認識和應用,使用bert框架 bert-as-server(CS架構),
二、Google BERT以及中文模型下載
1、Google BERT原始碼下載
Google BERT的完整原始碼下載地址:https://github.com/google-research/bert
官方給出BERT的解釋:
BERT是一種預先訓練語言表示的方法,這意味著我們在一個大型文本語料庫(如Wikipedia)上訓練一個通用的“語言理解”模型,然后將該模型用于我們關心的下游NLP任務(如回答問題),BERT優于以前的方法,因為它是第一個無監督的,深度雙向的預訓練自然語言處理系統,
原始碼的應用在以后學習程序可以進一步研究,現在入門階段可以使用框架更加簡單,
2、bert-as-server 框架下載
pip install bert-serving-server #server
pip install bert-serving-client #client3、中文預訓練模型下載
google下載地址:https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip
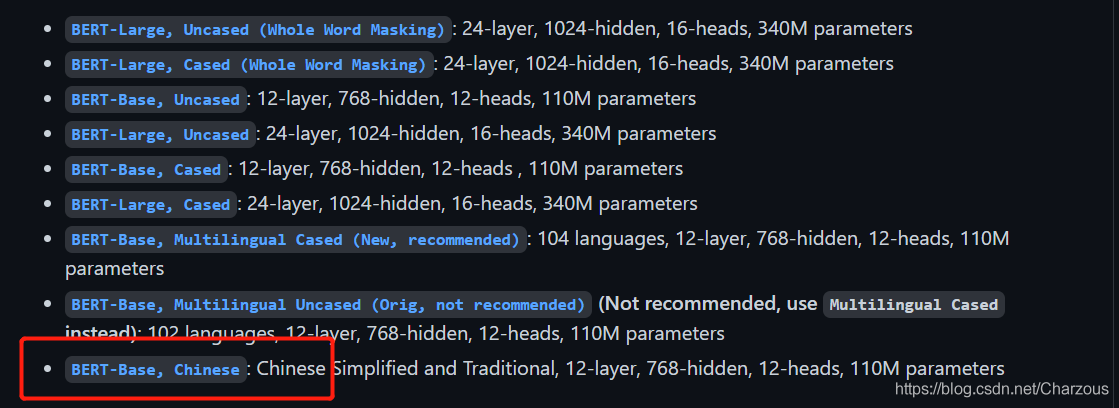
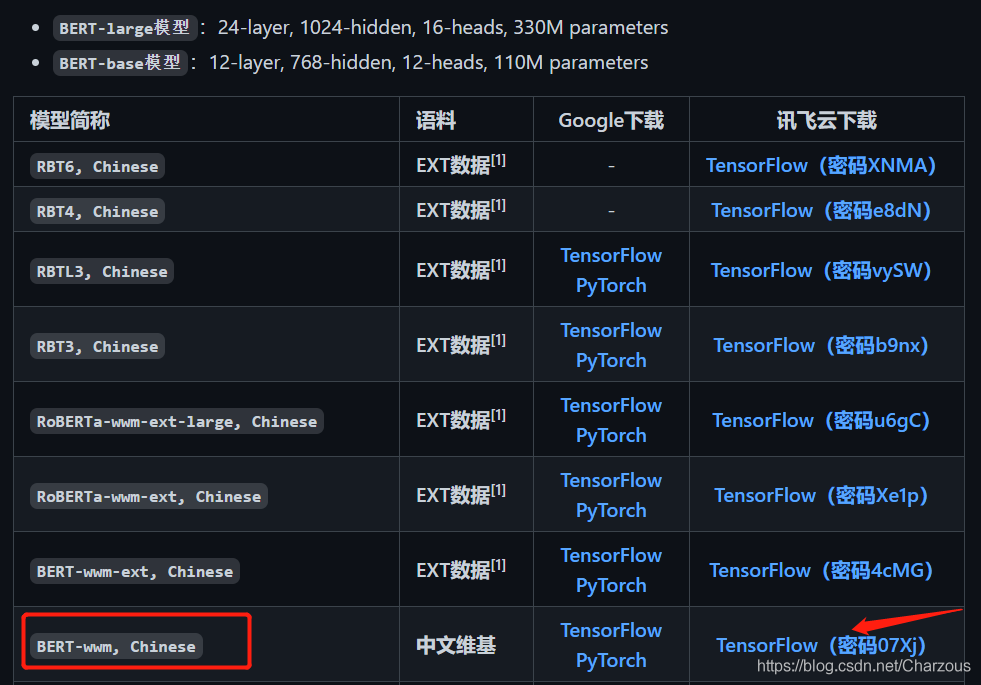
哈工大下載地址:https://pan.iflytek.com/link/A2483AD206EF85FD91569B498A3C3879 (密碼07Xj)
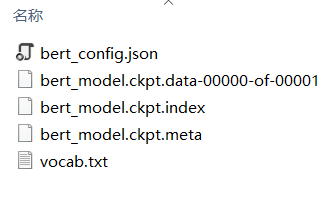
解壓之后檔案目錄如下,包括bert組態檔、預訓練模型和詞匯表,
三、bert生成中文句子向量
1、啟動BERT服務
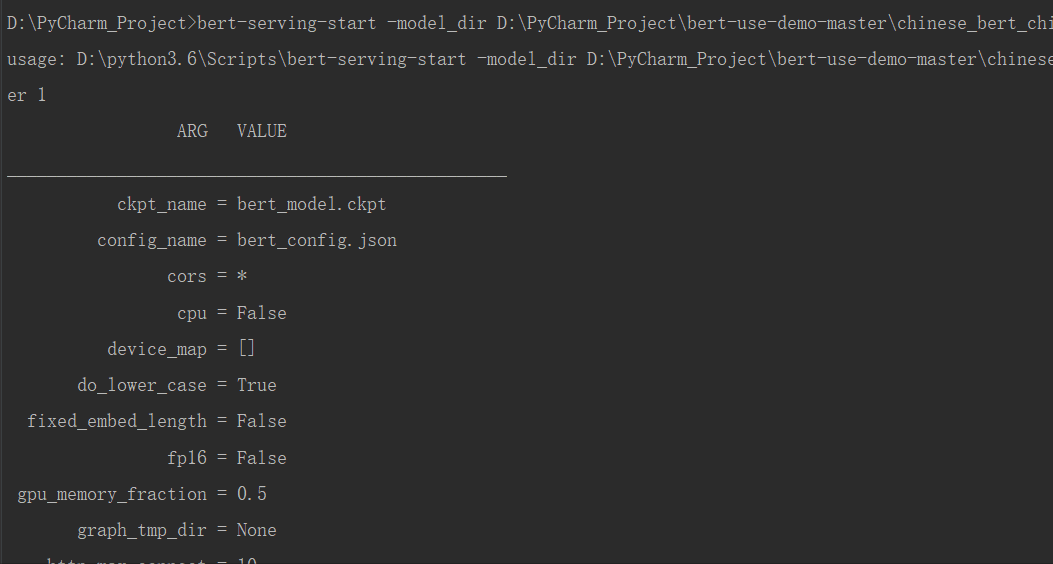
bert-serving-start -model_dir D:\PyCharm_Project\bert-use-demo-master\chinese_bert_chinese_wwm_L-12_H-768_A-12 -max_batch_size 10 -max_seq_len 20 -num_worker 1檔案目錄為上一步解壓的中文預訓練模型,引數可以自行設定,
啟動成功效果:
2、中文句子向量編碼
from bert_serving.client import BertClient
import numpy as np
def main():
bc = BertClient()
doc_vecs = bc.encode(['今天天空很藍,陽光明媚', '今天天氣好晴朗', '現在天氣如何', '自然語言處理', '機器學習任務'])
print(doc_vecs)
if __name__ == '__main__':
main()得到每個句子的向量表示為:
[[ 0.9737132 -0.0289975 0.23281255 ... 0.21432212 -0.1451838
-0.26555032]
[ 0.57072604 -0.2532929 0.13397914 ... 0.12190636 0.35531974
-0.2660934 ]
[ 0.33702925 -0.27623484 0.33704653 ... -0.14090805 0.48694345
0.13270345]
[ 0.00974528 -0.04629223 0.48822984 ... -0.24558026 0.09809375
-0.08697749]
[ 0.29680184 0.13963464 0.30706868 ... 0.05395972 -0.4393276
0.17769393]]
四、cosine相似度計算
def cos_similar(sen_a_vec, sen_b_vec):
'''
計算兩個句子的余弦相似度
'''
vector_a = np.mat(sen_a_vec)
vector_b = np.mat(sen_b_vec)
num = float(vector_a * vector_b.T)
denom = np.linalg.norm(vector_a) * np.linalg.norm(vector_b)
cos = num / denom
return cos實驗結果:
句子:
'今天天空很藍,陽光明媚', '今天天氣好晴朗'相似度:0.9508827722696014
句子:
'自然語言處理', '機器學習任務'
相似度:0.9187518514435784
句子:
'今天天空很藍,陽光明媚', '機器學習任務'相似度:0.7653104788070156
五、完整實驗代碼
from bert_serving.client import BertClient
import numpy as np
def cos_similar(sen_a_vec, sen_b_vec):
'''
計算兩個句子的余弦相似度
'''
vector_a = np.mat(sen_a_vec)
vector_b = np.mat(sen_b_vec)
num = float(vector_a * vector_b.T)
denom = np.linalg.norm(vector_a) * np.linalg.norm(vector_b)
cos = num / denom
return cos
def main():
bc = BertClient()
doc_vecs = bc.encode(['今天天空很藍,陽光明媚', '今天天氣好晴朗', '現在天氣如何', '自然語言處理', '機器學習任務'])
print(doc_vecs)
similarity=cos_similar(doc_vecs[0],doc_vecs[4])
print(similarity)
if __name__ == '__main__':
main()
這篇簡單介紹了BERT的基本應用,使用bert框架對中文句子進行編碼,生成句子向量,同時可以進行句子語意的相關性分析,
Google BERT預訓練模型在深度學習、NLP領域的應用已經十分廣泛了,在文本分類任務達到很好的效果,相比傳統的詞嵌入word2vec、golve,使用bert預訓練得到的效果有更好地提升,
可以看到BERT的基礎使用相對簡單,這篇沒有很深入復雜地分析bert的原理以及高級應用,而是從零開始,定位于初學者對BERT的簡單認識和應用,使用bert框架 bert-as-server(CS架構),也算是為之后深入的學習研究做了一點基礎功課,
如果覺得不錯歡迎“一鍵三連”哦,點贊收藏關注,有問題直接評論,交流學習!
我的CSDN博客:https://blog.csdn.net/Charzous/article/details/113824876
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/260358.html
標籤:AI
上一篇:緒論-演算法【資料結構與演算法】