- rabbitmq的訊息可靠性
- rabbitmq-冪等引出的性能分析
- 從rabbitmq到rocketmq
經過上面三篇文章的學習,本篇再來學習 kafka 就會比較簡單,概念都是相通的,關鍵是要聯系和對比,
那么直接進入正題,按照同樣的思路,首先看看單個 Broker 內部邏輯結構,圖片來源
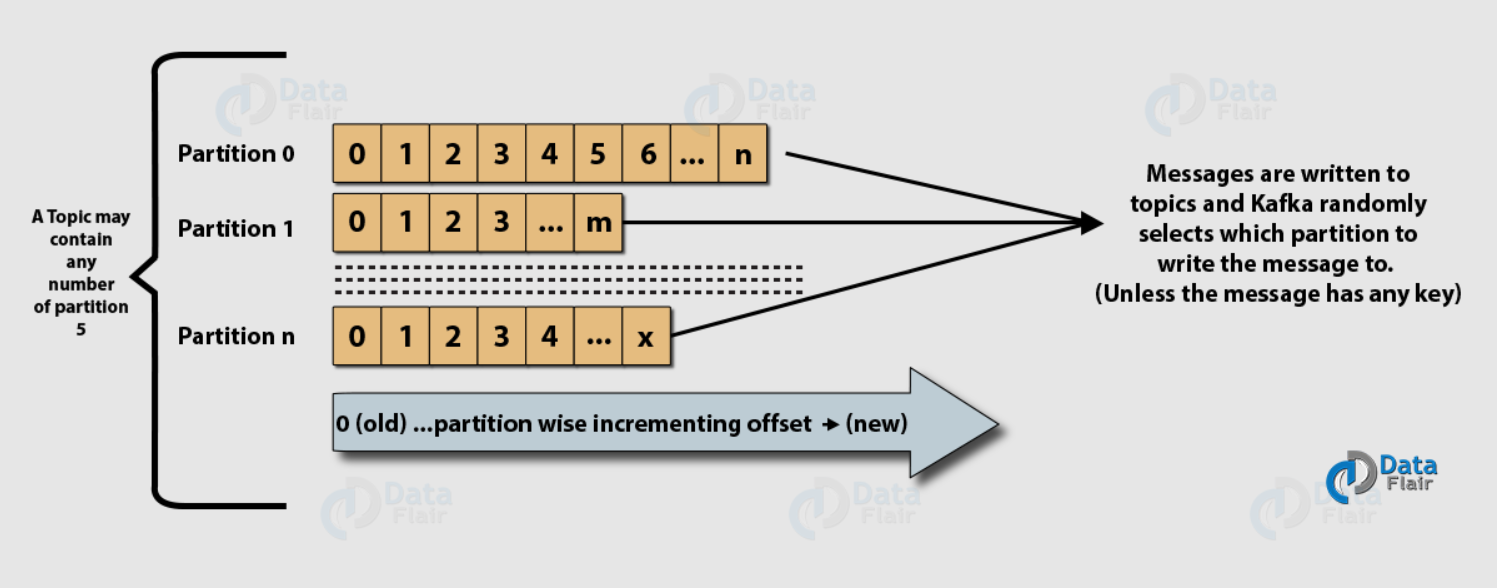
圖中的 partition 看成是 rocketmq 中的佇列,只不過 kafka 中叫做磁區,主題、消費者組、消費者、生產者這些概念還是一樣的,
順便說一句,kafka 的磁區叫法也是很合理的,本來每個主題都是由N個磁區(佇列)組成的,而磁區(佇列)又可以看成是訊息存盤的地方(或者說從邏輯上來看是的),
那么,kafka 集群架構是怎么樣的呢?還是看圖,圖片來源
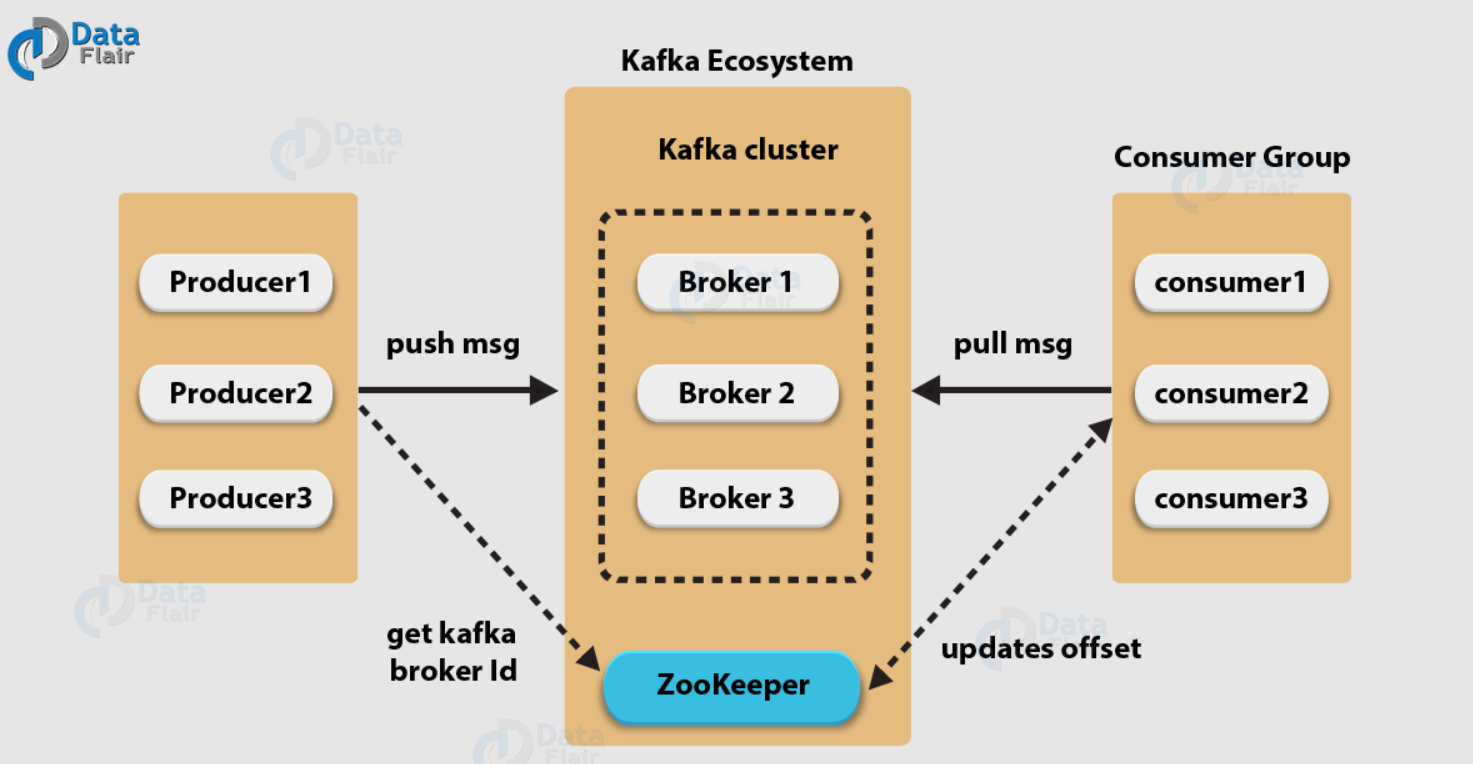
同樣對比 rocketmq,最大的區別就是 rocketmq 中是 NameServer,而 kafka 則是 zookeeper,為什么 kafka 沒有選擇自己實作類似 NameServer 的組件呢?猜測原因是受了 unix 哲學影響,舉個例子:
ls t.txt | grep 'abc' | wc -l
該條指令就是統計檔案中總共有幾行包含 abc 字串,其中 ls、grep、wc 三種指令都是不同的職責,但是通過管道組合在一起,就實作了特殊的功能,
那么換句話說,kafka 和 zookeeper 的關系就像這些指令一樣,組合在一起實作具體系統,
但是分久必合合久必分,現在 kafka 也在準備全面脫離對 zookeeper 的依賴,kafka 和 zookeeper 的這種耦合和分離,在一定程度上也體現了一種哲學的思辨,
基于此,我們來比較一下三個訊息佇列在構建集群上的區別:
-
rabbitmq:節點通信的集群構建方式
-
kafka、rocketmq:基于注冊中心的集群構建方式
之所以這樣寫,其實這就是分布式系統中兩種不同的集群構建模式,我們再補充一種:
- 第三種:基于負載均衡的集群構建方式
假設集群機器是 s1、s2,那么構建集群的目的是對外提供服務的同時,提高了系統的可用性,并且分攤了負載,既然集群是對外用的,那么客戶端 c1 到底該如何正確的訪問到具體的服務呢?
- 第一種就是s1、s2屬于無狀態服務,訪問任何一臺均可得到正確結果,那么就是負載均衡方式來實作,在 前級增加 LB ,代理 s1、s2的請求流量,
- 第二種就是 s1、s2屬于有狀態服務,比如這里的 rabbitmq(因為每個 Broker 上都存盤了訊息資料,且不同 broker 上存在的佇列可能不同),所以當c1通過s1訪問佇列a時,假如佇列a在 s2上,那么必然需要請求轉發,要么s1將請求自動轉到 s2,要么c1 重新訪問s2,
- 第三種就是利用注冊中心,實作客戶端通過注冊中心獲取到集群資訊后,可以根據需要直接去目標機器獲取正確的服務,
三種方式,最難的肯定是第二種,關于這一點,可以參見 rabbitmq 的這篇博客 quorum-queues-local-delivery 重點針對如何減少不必要的請求路由,對 quorum 佇列進行了探討,
再來看看kafka集群中,關于資料一致性的處理,這一點上,和 rabbitmq 的 quorum 佇列比較相似,kafka 也是對 磁區 層面進行的資料一致性處理,
但是 kafka 沒有采用 raft 演算法實作,而是基于微軟的 pacificA 協議實作,可能是因為 raft(2013年)落地的比 kafka 晚,而且 raft 要求至少半數以上存活才可以,并且無法靈活指定同步副本數,
所以 kafka 引入了新的概念:ISR,也就是和領導者資料是同步的節點的集合(包括領導者本身),這里領導者和追隨者的資料同步與否,是根據 replica.lag.time.max.ms 引數設定的時間間隔來判斷,超過此間隔的,就不會列入到 ISR 集合中,
當生產者寫入訊息時,領導者節點需要根據配置的引數(acks=0,1all)來判斷,當該訊息同步到n個 ISR 中的節點后,才算寫入成功,那么 n 到底如何確定?
- 當 acks=0,自然不用說,無法同步到任何節點,
- acks=1,只要領導者節點存盤了即可,
- acks=all,這時,另一個引數就登場了
這個引數就是 min.insync.replicas = m ,當配置了該引數后,n的范圍就是:
m <= n <= ISR 中節點的數量,
到這里,可以看到,同步數量是可以靈活調整的,是不是很像我們之前提到的 NWR 機制?
現在,我們可以再分析一下單個 Broker 內訊息刷盤機制了,因為有了上述 NWR 機制的保證,kafka 只保留了訊息寫入到作業系統的 PageCache中,后面就依靠作業系統的機制來落盤,
Rebalance:重平衡
基于上面的分析,我們對 kafka 的內部原理和集群架構有了更多的理解,最后,再來看一下 kafka 中的 Rebalance 機制,重平衡說的是某個主題下面的磁區重新分配給一個消費者組中的消費者,
這里就可以類比 2PC 協議的處理程序,首先是每個主題都有一個協調者,并且消費者和協調者之間存在定時的心跳,其次,兩階段為:
- joinGroup請求:請求入組
- syncGroup請求:分配佇列結果
假設是新增消費者的場景,新增消費者C3,那么 C3 主動向協調者發起 joinGroup 請求,協調者就知道該啟動重平衡了,協調者會在回應其他消費者的心跳中,攜帶發起重平衡的通知,這樣,當其他消費者收到心跳回應后,就會主動發起 joinGroup 請求,
joinGroup 請求中攜帶的是該消費者的訂閱資訊,協調者會認為第一個發起 joinGroup 請求的是領導者,也即負責計算分配結果的,對于普通節點的請求,會直接回傳入組成功,對于領導者的 joinGroup 請求,會在收集到所有節點入組資訊后,統一回傳給領導者,
那么領導者會對這些資訊做判斷,并按規則計算分配結果,與此同時各節點可以發起 syncGroup 請求,等到領導者的 syncGroup 請求發到協調者以后,協調者會根據分配結果,在各節點的 syncGroup 回應中攜帶其被分配的佇列資訊,這樣就實作了磁區的負載均衡,
不過,要特意提醒的一點是,重平衡協議在 kafka 中還有其他用途,是比較通用的分布式任務分配演算法,
本篇就到這里,主要還是著眼于從之前學過的理論知識角度來看待 kafka,下篇文章,我們對 rabbitmq、rocketmq、kafka、pulsar 做一個對比總結,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/260380.html
標籤:其他