史上最全面的spark原始碼分析,獨一無二的分析,讓你徹底明白spark 如何開啟driver,以及什么時候會開啟executor,
本文使用spark3.0.1提供計算π 的案例進行演示 ,運行調度Standalone Cluster模式,
演示步驟如下:
啟動master,ip:169.254.150.140
啟動worker:傳參 spark://169.254.150.140:7077
環境變數設定:除錯的時候會報錯java.lang.IllegalStateException: Cannot find any build directories,設定完環境變數就可以了哦,
SPARK_HOME=D:\spark-3.0.1-bin-hadoop2.7
SCALA_HOME=E:\install_soft\scala-2.11\scala
SPARK_SCALA_VERSION=scala-2.11
window idea運行結果:Pi is roughly 3.1419757098785492
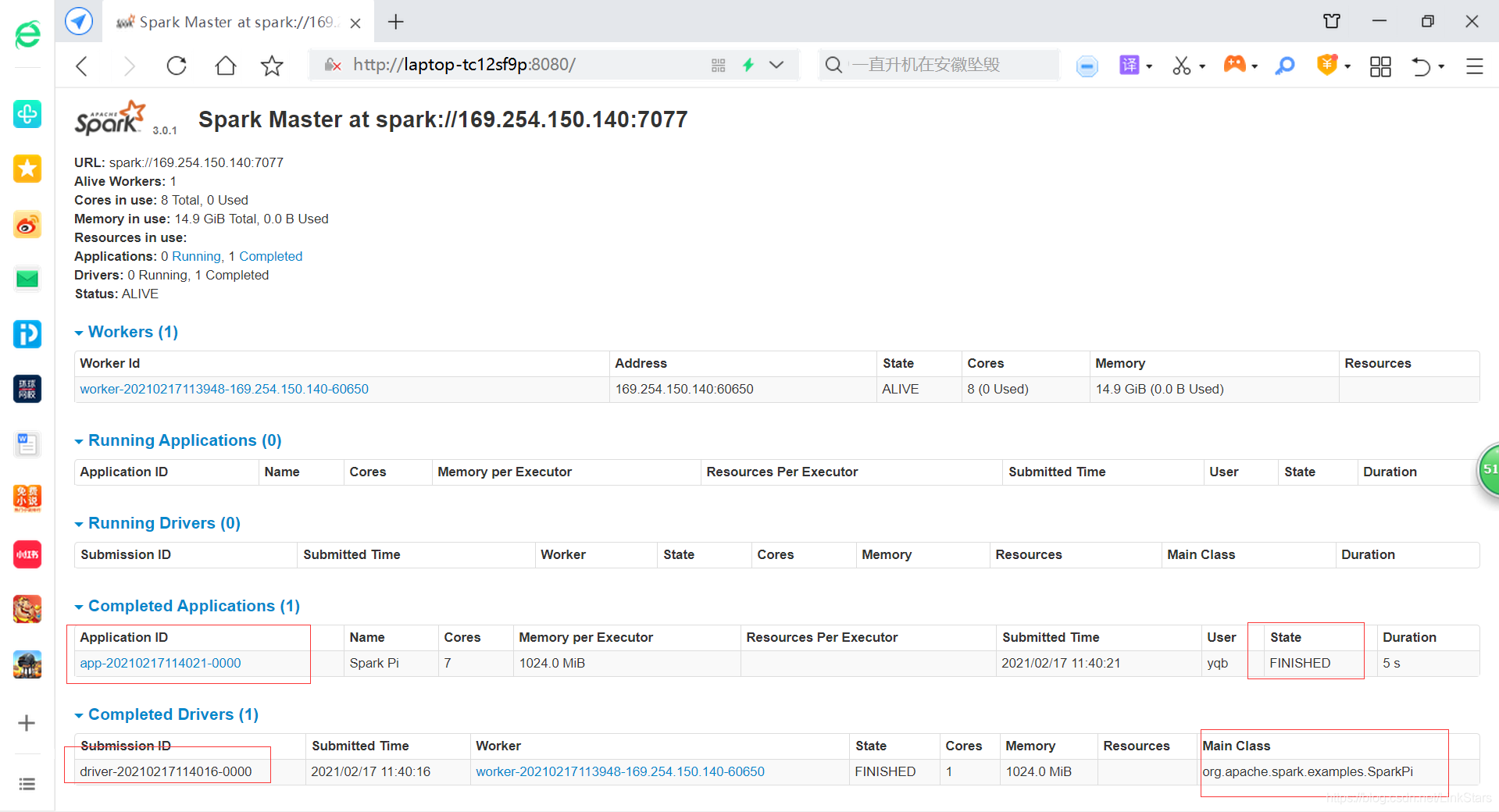
一、運行spark-submit:
exec “
S
P
A
R
K
H
O
M
E
"
/
b
i
n
/
?
?
s
p
a
r
k
?
c
l
a
s
s
?
?
?
?
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
d
e
p
l
o
y
.
S
p
a
r
k
S
u
b
m
i
t
?
?
"
{SPARK_HOME}"/bin/**spark-class** **org.apache.spark.deploy.SparkSubmit** "
SPARKH?OME"/bin/??spark?class????org.apache.spark.deploy.SparkSubmit??"@”
二、運行spark-class:
build_command() {
“$RUNNER” -Xmx128m
S
P
A
R
K
L
A
U
N
C
H
E
R
O
P
T
S
?
c
p
"
SPARK_LAUNCHER_OPTS -cp "
SPARKL?AUNCHERO?PTS?cp"LAUNCH_CLASSPATH" org.apache.spark.launcher.Main “$@”
printf “%d\0” $?
}
Main類引數 “$@”:
org.apache.spark.deploy.SparkSubmit --class org.apache.spark.examples.SparkPi --master spark://169.254.150.140:7077 --deploy-mode cluster D:\spark-examples_2.12-3.0.1.jar
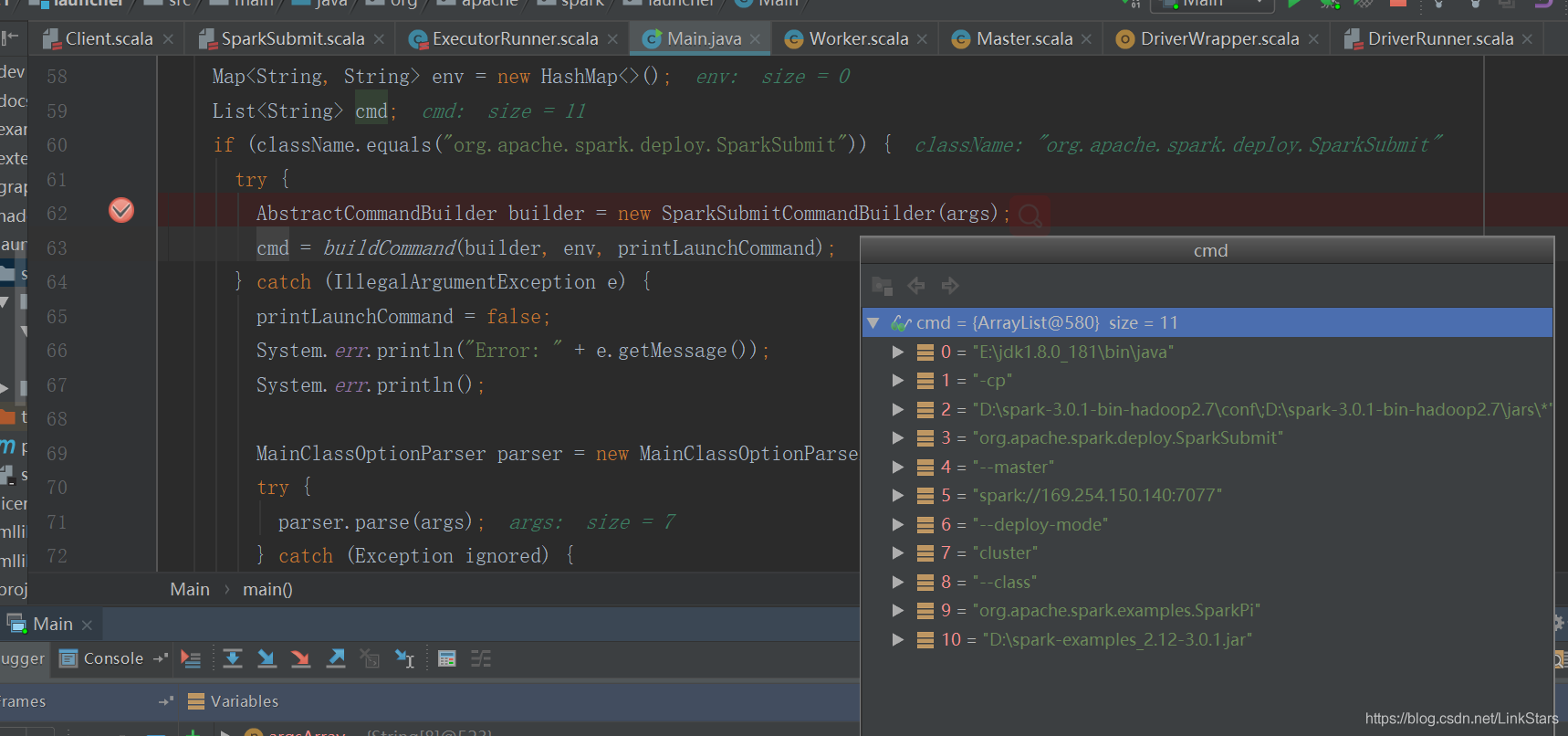
Main類運行結束后,spark-class會執行如下命令:
E:\jdk1.8.0_181\bin*java* -cp “D:\spark-3.0.1-bin-hadoop2.7\conf;D:\spark-3.0.1-bin-hadoop2.7\jars*” org.apache.spark.deploy.SparkSubmit --master spark://169.254.150.140:7077 --deploy-mode cluster --class org.apache.spark.examples.SparkPi D:\spark-examples_2.12-3.0.1.jar
三、SparkSubmit類:
按上面的進行傳參:
–class org.apache.spark.examples.SparkPi --master spark://169.254.150.140:7077 --deploy-mode cluster D:\spark-examples_2.12-3.0.1.jar
val submit = new SparkSubmit()
submit.doSubmit(args)
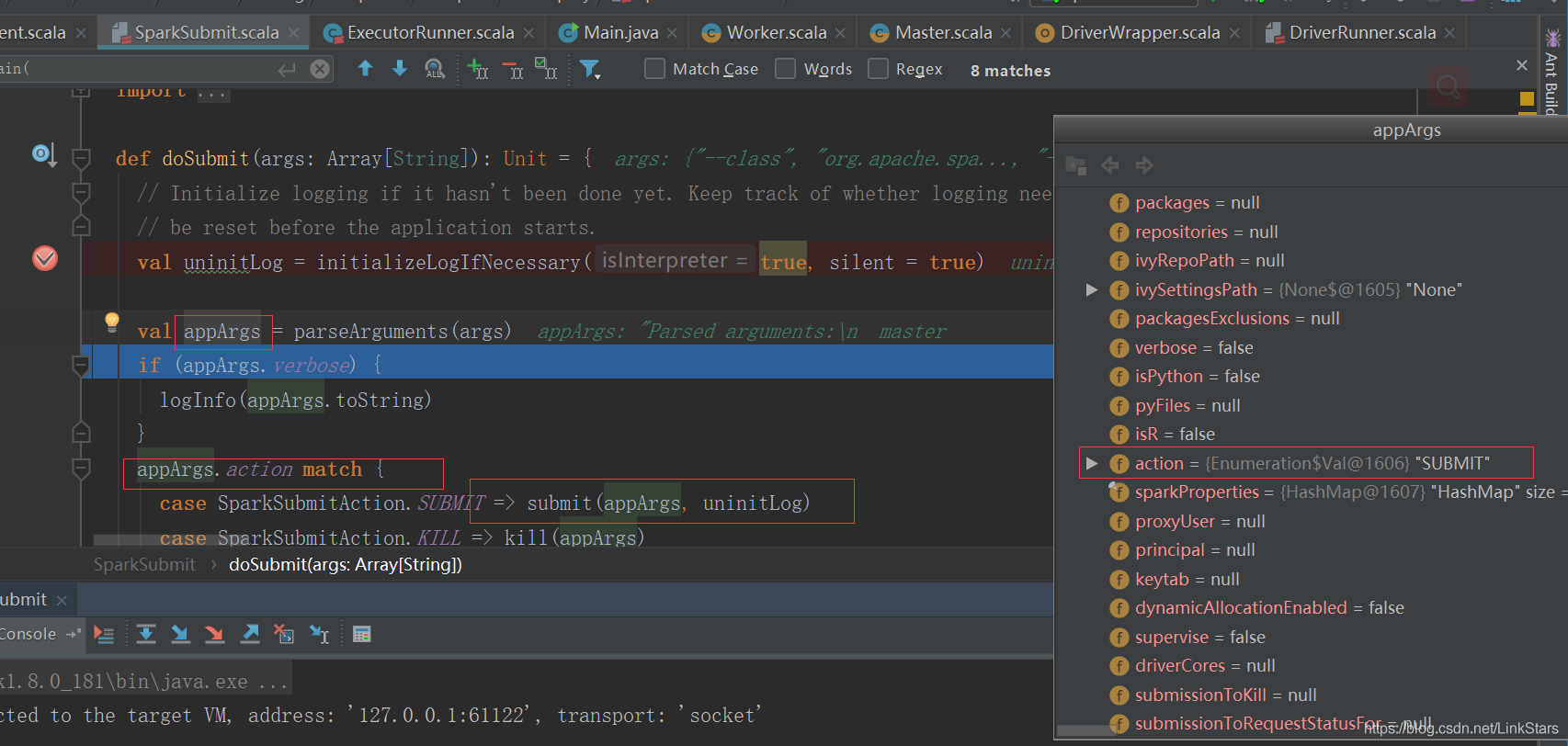
submit(args: SparkSubmitArguments, uninitLog: Boolean)
doRunMain()
runMain(args, uninitLog)
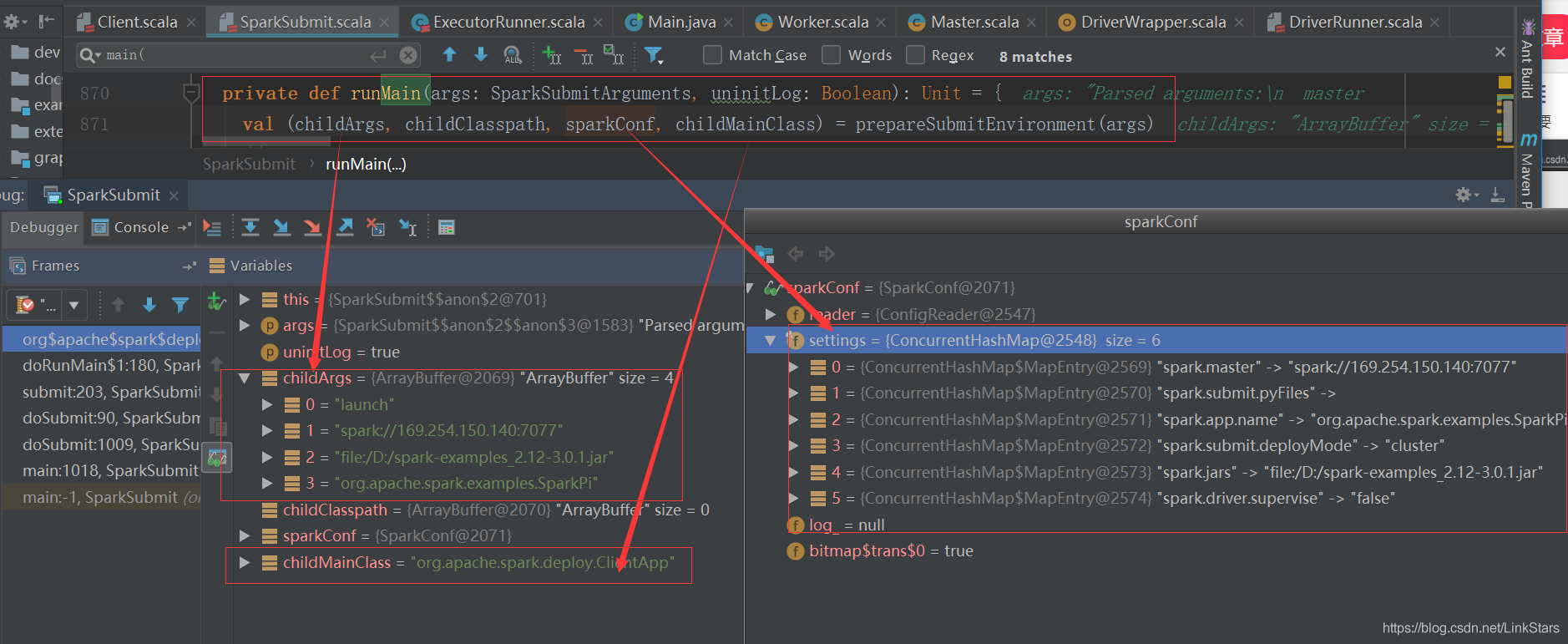
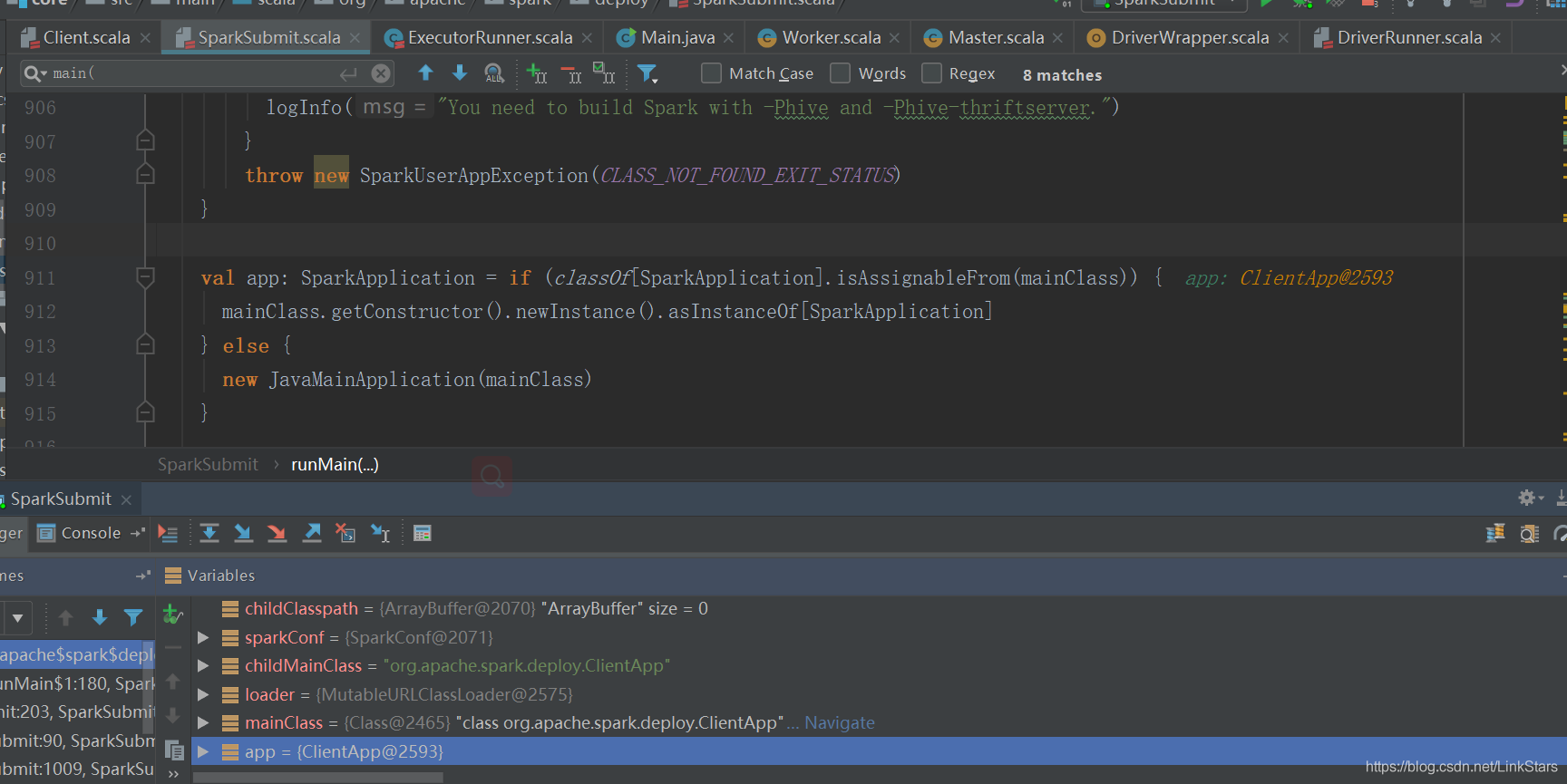
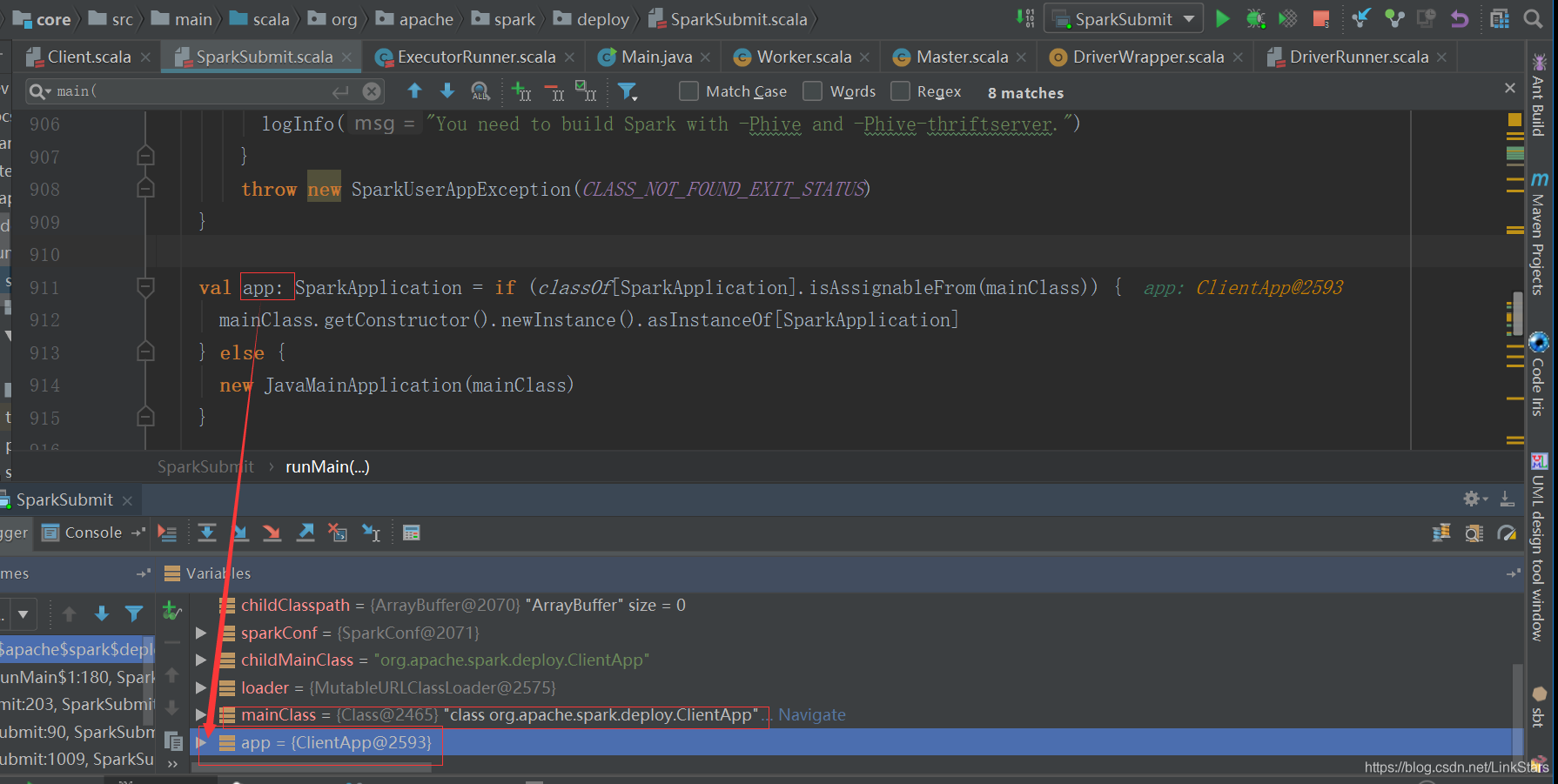
四、ClientApp類:
start(args: Array[String], conf: SparkConf)
開啟netty服務端,向master注冊,該步驟不是創建dirver,而是driverClient,
rpcEnv.setupEndpoint(“client”, new ClientEndpoint(rpcEnv, driverArgs, masterEndpoints, conf)),會調度該端點的onStart方法,為什么調onStart,可以參考我的文章:https://blog.csdn.net/LinkStars/article/details/112982187
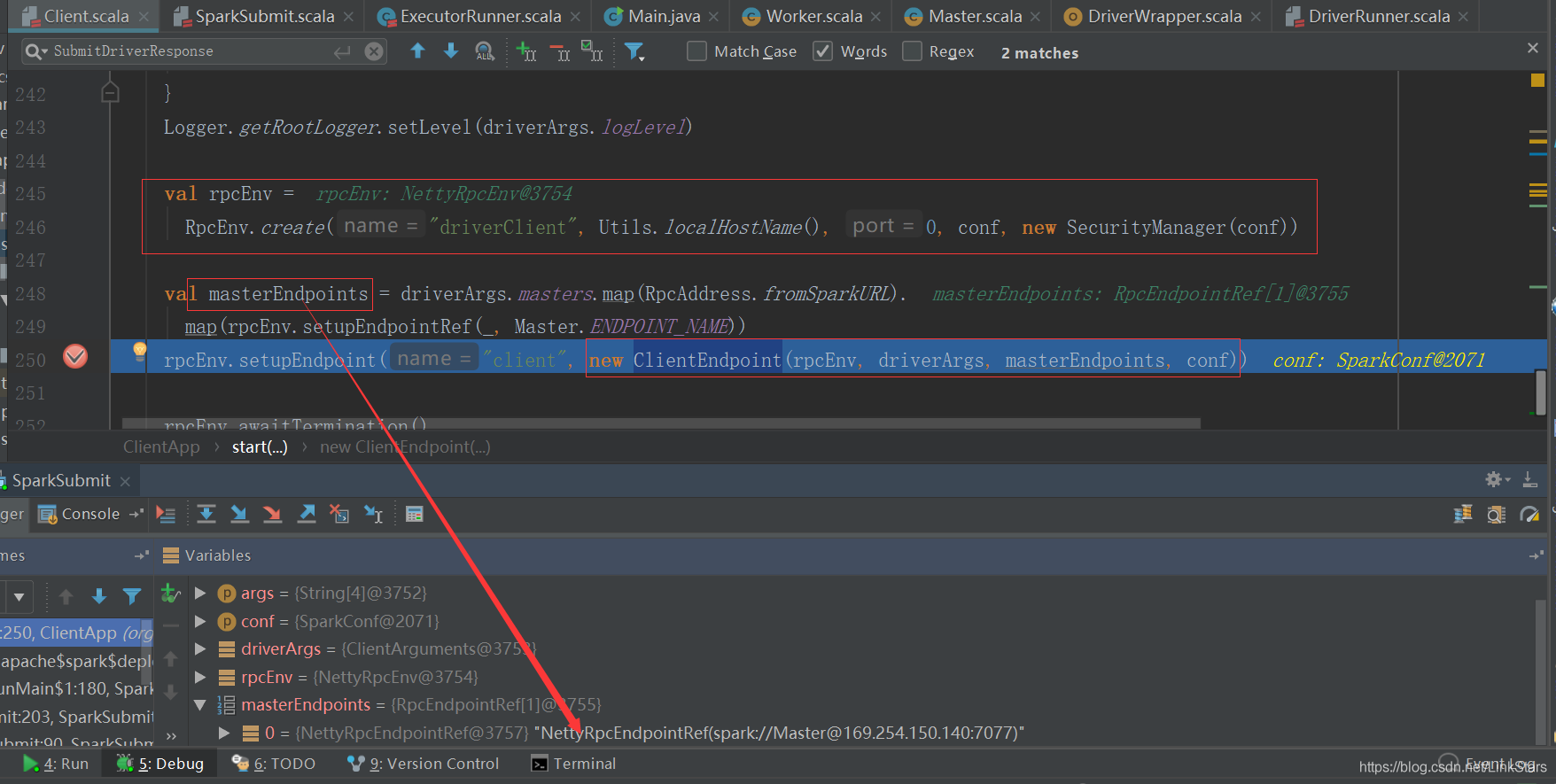
五、ClientEndpoint類:
override def onStart(): Unit = {
driverArgs.cmd match {
case “launch” =>
val mainClass = "org.apache.spark.deploy.worker.DriverWrapper"
val command = new Command(mainClass,
Seq("{{WORKER_URL}}", “{{USER_JAR}}”, driverArgs.mainClass) ++ driverArgs.driverOptions,
sys.env, classPathEntries, libraryPathEntries, javaOpts)
val driverDescription = new DriverDescription(
driverArgs.jarUrl,
driverArgs.memory,
driverArgs.cores,
driverArgs.supervise,
command,
driverResourceReqs)
asyncSendToMasterAndForwardReplySubmitDriverResponse//向master進行通信
}
六、master類:
master 收到RequestSubmitDriver訊息
21/02/17 12:40:50 INFO Master: Driver submitted org.apache.spark.deploy.worker.DriverWrapper
21/02/17 12:40:50 INFO Master: Launching driver driver-20210217124050-0001 on worker worker-20210217113948-169.254.150.140-60650
21/02/17 12:40:54 INFO Master: Registering app Spark Pi
case RequestSubmitDriver(description) =>
logInfo(“Driver submitted " + description.command.mainClass) //Driver submitted org.apache.spark.deploy.worker.DriverWrapper
val driver = createDriver(description)
persistenceEngine.addDriver(driver)
waitingDrivers += driver
drivers.add(driver)
**schedule()//會調度 launchDriver(worker, driver)**查看那臺有資源,向worker發送訊息 worker.endpoint.send(LaunchDriver(driver.id, driver.desc, driver.resources))
context.reply(SubmitDriverResponse(self, true, Some(driver.id),
s"Driver successfully submitted as ${driver.id}”))
}
七、worker 類:
case LaunchDriver(driverId, driverDesc, resources_) =>
logInfo(s"Asked to launch driver $driverId")
val driver = new DriverRunner(
conf,
driverId,
workDir,
sparkHome,
driverDesc.copy(command = Worker.maybeUpdateSSLSettings(driverDesc.command, conf)),
self,
workerUri,
securityMgr,
resources_)
drivers(driverId) = driver
driver.start()// prepareAndRunDriver()
coresUsed += driverDesc.cores
memoryUsed += driverDesc.mem
addResourcesUsed(resources_)
八、DriverRunner類:
private[worker] def prepareAndRunDriver(): Int = {
val driverDir = createWorkingDirectory()
val localJarFilename = downloadUserJar(driverDir)
val resourceFileOpt = prepareResourcesFile(SPARK_DRIVER_PREFIX, resources, driverDir)
def substituteVariables(argument: String): String = argument match {
case “{{WORKER_URL}}” => workerUrl
case “{{USER_JAR}}” => localJarFilename
case other => other
}
// config resource file for driver, which would be used to load resources when driver starts up
val javaOpts = driverDesc.command.javaOpts ++ resourceFileOpt.map(f =>
Seq(s"-D
D
R
I
V
E
R
R
E
S
O
U
R
C
E
S
F
I
L
E
.
k
e
y
=
{DRIVER_RESOURCES_FILE.key}=
DRIVERR?ESOURCESF?ILE.key={f.getAbsolutePath}")).getOrElse(Seq.empty)
// TODO: If we add ability to submit multiple jars they should also be added here
val builder = CommandUtils.buildProcessBuilder(driverDesc.command.copy(javaOpts = javaOpts),
securityManager, driverDesc.mem, sparkHome.getAbsolutePath, substituteVariables)
runDriver(builder, driverDir, driverDesc.supervise)// 后面去調 runCommandWithRetry(),再運行DriverWrapper類,再去找logInfo("Launch Command: " + redactedCommand)
}
運行結果日志:
21/02/17 12:40:51 INFO DriverRunner: Launch Command: “E:\jdk1.8.0_181\bin\java” “-cp” “D:\spark-3.0.1-bin-hadoop2.7\conf;D:\spark-3.0.1-bin-hadoop2.7\jars*” “-Xmx1024M” “-Dspark.jars=file:/D:/spark-examples_2.12-3.0.1.jar” “-Dspark.driver.supervise=false” “-Dspark.master=spark://169.254.150.140:7077” “-Dspark.app.name=org.apache.spark.examples.SparkPi” “-Dspark.submit.deployMode=cluster” “-Dspark.submit.pyFiles=” “-Dspark.rpc.askTimeout=10s” “org.apache.spark.deploy.worker.DriverWrapper” “spark://Worker@169.254.150.140:60650” “D:\spark-3.0.1-bin-hadoop2.7\work\driver-20210217124050-0001\spark-examples_2.12-3.0.1.jar” “org.apache.spark.examples.SparkPi”
九、DriverWrapper類:
def main(args: Array[String]): Unit = {
args.toList match {
case workerUrl :: userJar :: mainClass :: extraArgs =>
val conf = new SparkConf()
val host: String = Utils.localHostName()
val port: Int = sys.props.getOrElse(config.DRIVER_PORT.key, “0”).toInt
val rpcEnv = RpcEnv.create(“Driver”, host, port, conf, new SecurityManager(conf))//開啟driver
logInfo(s"Driver address: ${rpcEnv.address}")
rpcEnv.setupEndpoint(“workerWatcher”, new WorkerWatcher(rpcEnv, workerUrl))
val currentLoader = Thread.currentThread.getContextClassLoader
val userJarUrl = new File(userJar).toURI().toURL()
val loader =
if (sys.props.getOrElse(config.DRIVER_USER_CLASS_PATH_FIRST.key, “false”).toBoolean) {
new ChildFirstURLClassLoader(Array(userJarUrl), currentLoader)
} else {
new MutableURLClassLoader(Array(userJarUrl), currentLoader)
}
Thread.currentThread.setContextClassLoader(loader)
setupDependencies(loader, userJar)
// Delegate to supplied main class
val clazz = Utils.classForName(mainClass)
val mainMethod = clazz.getMethod(“main”, classOf[Array[String]])
mainMethod.invoke(null, extraArgs.toArray[String])//運行org.apache.spark.examples.SparkPi中的main方法,去開啟SparkContext
rpcEnv.shutdown()
十、SparkContext類:
val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode)
createTaskScheduler(…){
case SPARK_REGEX(sparkUrl) =>
checkResourcesPerTask(clusterMode = true, None)
val scheduler = new TaskSchedulerImpl(sc)
val masterUrls = sparkUrl.split(",").map(“spark://” + _)
val backend = new StandaloneSchedulerBackend(scheduler, sc, masterUrls)
}
十一、TaskSchedulerImpl類:
backend.start()
十二、StandaloneSchedulerBackend類:
override def start(): Unit = {
val command = Command(“org.apache.spark.executor.CoarseGrainedExecutorBackend”,
args, sc.executorEnvs, classPathEntries ++ testingClassPath, libraryPathEntries, javaOpts)
val appDesc = ApplicationDescription(sc.appName, maxCores, sc.executorMemory, command,
webUrl, sc.eventLogDir, sc.eventLogCodec, coresPerExecutor, initialExecutorLimit,
resourceReqsPerExecutor = executorResourceReqs)
client = new StandaloneAppClient(sc.env.rpcEnv, masters, appDesc, this, conf)
client.start()
launcherBackend.setState(SparkAppHandle.State.SUBMITTED)
waitForRegistration()
launcherBackend.setState(SparkAppHandle.State.RUNNING)
}
十三、StandaloneAppClient類: endpoint.set會執行onStart()
def start(): Unit = {
// Just launch an rpcEndpoint; it will call back into the listener.
endpoint.set(rpcEnv.setupEndpoint(“AppClient”, new ClientEndpoint(rpcEnv)))
}
十四、ClientEndpoint類:
override def onStart(): Unit = {
try {
registerWithMaster(1)//調tryRegisterAllMasters() ,向master注冊app
} catch {
case e: Exception =>
logWarning(“Failed to connect to master”, e)
markDisconnected()
stop()
}
private def tryRegisterAllMasters(): Array[JFuture[_]] = {
for (masterAddress <- masterRpcAddresses) yield {
registerMasterThreadPool.submit(new Runnable {
override def run(): Unit = try {
if (registered.get) {
return
}
logInfo(“Connecting to master " + masterAddress.toSparkURL + “…”)
val masterRef = rpcEnv.setupEndpointRef(masterAddress, Master.ENDPOINT_NAME)
masterRef.send(RegisterApplication(appDescription, self))
} catch {
case ie: InterruptedException => // Cancelled
case NonFatal(e) => logWarning(s"Failed to connect to master $masterAddress”, e)
}
})
}
}
十五、master類:
case RegisterApplication(description, driver) =>
// TODO Prevent repeated registrations from some driver
if (state == RecoveryState.STANDBY) {
// ignore, don’t send response
} else {
logInfo("Registering app " + description.name)
val app = createApplication(description, driver)
registerApplication(app)
logInfo("Registered app " + description.name + " with ID " + app.id)
persistenceEngine.addApplication(app)
driver.send(RegisteredApplication(app.id, self))
schedule()//去調度開啟executor
}
十六、worker類:
case LaunchExecutor(masterUrl, appId, execId, appDesc, cores_, memory_, resources_) =>
if (masterUrl != activeMasterUrl) {
logWarning(“Invalid Master (” + masterUrl + “) attempted to launch executor.”)
} else {
try {
logInfo(“Asked to launch executor %s/%d for %s”.format(appId, execId, appDesc.name)//Worker: Asked to launch executor app-20210217124054-0001/0 for Spark Pi
logInfo(s"workercommand-------------------: ${appDesc.command}")
運行結果:
// Worker: workercommand------------------:Command(org.apache.spark.executor.CoarseGrainedExecutorBackend,List(–driver-url, spark://CoarseGrainedScheduler@LAPTOP-TC12SF9P:61716, --executor-id, {{EXECUTOR_ID}}, --hostname, {{HOSTNAME}}, --cores, {{CORES}}, --app-id, {{APP_ID}}, --worker-url, {{WORKER_URL}}),Map(SPARK_USER -> yqb, SPARK_EXECUTOR_MEMORY -> 1024m),List(),List(),ArraySeq(-Dspark.driver.port=61716, -Dspark.rpc.askTimeout=10s))
val manager = new ExecutorRunner(
appId,
execId,
appDesc.copy(command = Worker.maybeUpdateSSLSettings(appDesc.command, conf)),
cores_,
memory_,
self,
workerId,
webUi.scheme,
host,
webUi.boundPort,
publicAddress,
sparkHome,
executorDir,
workerUri,
conf,
appLocalDirs,
ExecutorState.LAUNCHING,
resources_)
executors(appId + “/” + execId) = manager
manager.start()
coresUsed += cores_
memoryUsed += memory_
addResourcesUsed(resources_)
十七、ExecutorRunner類:
val builder = CommandUtils.buildProcessBuilder(subsCommand, new SecurityManager(conf),
memory, sparkHome.getAbsolutePath, substituteVariables)
val command = builder.command()
logInfo(s"command:--------------- -------------${command}")
process = builder.start()
運行命令:
21/02/17 12:40:54 INFO ExecutorRunner: command:--------------- -------------[E:\jdk1.8.0_181\bin\java, -cp, D:\spark-3.0.1-bin-hadoop2.7\conf;D:\spark-3.0.1-bin-hadoop2.7\jars*, -Xmx1024M, -Dspark.driver.port=61716, -Dspark.rpc.askTimeout=10s, org.apache.spark.executor.CoarseGrainedExecutorBackend, --driver-url, spark://CoarseGrainedScheduler@LAPTOP-TC12SF9P:61716, --executor-id, 0, --hostname, 169.254.150.140, --cores, 7, --app-id, app-20210217124054-0001, --worker-url, spark://Worker@169.254.150.140:60650]
十八、CoarseGrainedExecutorBackend類:
env.rpcEnv.setupEndpoint(“Executor”,
backendCreateFn(env.rpcEnv, arguments, env, cfg.resourceProfile))//運行onStart方法,向driver發送RegisterExecutor
override def onStart(): Unit = {
logInfo("Connecting to driver: " + driverUrl)
try {
_resources = parseOrFindResources(resourcesFileOpt)
} catch {
case NonFatal(e) =>
exitExecutor(1, “Unable to create executor due to " + e.getMessage, e)
}
rpcEnv.asyncSetupEndpointRefByURI(driverUrl).flatMap { ref =>
// This is a very fast action so we can use “ThreadUtils.sameThread”
driver = Some(ref)
ref.ask[Boolean](RegisterExecutor(executorId, self, hostname, cores, extractLogUrls,
extractAttributes, resources, resourceProfile.id))
}(ThreadUtils.sameThread).onComplete {
case Success() =>
self.send(RegisteredExecutor)
case Failure(e) =>
exitExecutor(1, s"Cannot register with driver: $driverUrl”, e, notifyDriver = false)
}(ThreadUtils.sameThread)
}
作者:小亦
好好學習,天天向上
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/260546.html
標籤:其他
下一篇:初識redis