【論文筆記】An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale(Vision Transformer, ViT)
- 文章題目:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
- 作者:Dosovitskiy, A., Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, M. Dehghani, Matthias Minderer, Georg Heigold, S. Gelly, Jakob Uszkoreit and N. Houlsby
- 時間:2020
- 來源:ICLR 2021 / ArXiv
- paper:http://arxiv.org/pdf/2010.11929v1
- code:https://github.com/google-research/vision_transformer , https://github.com/lucidrains/vit-pytorch , https://github.com/likelyzhao/vit-pytorch
- 參考:Dosovitskiy, A., Beyer, L., Kolesnikov, A., et al (2020). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale.ArXiv, abs/2010.11929.
感性認識
- 研究的基本問題
將Transformer直接應用于影像領域,進行影像分類任務,而不修改Transformer架構,也不使用CNN, - 主要想法
將image分割成大小一致的patch,對應于NLP中的token,再將其進行嵌入表示,成為Transformer的輸入,在patch前加入一個class表示,對應全域資訊(圖片分類),進行最終的預測, - 結果與結論
在中規模資料上,表現一般,在大規模資料集預訓練下,表現優異,且節省訓練開銷, - 不足與展望
1.無法保留影像的二維結構資訊(區域特性,歸納偏置),要依靠大量資料來彌補,
2.預訓練與微調的開銷問題,如何更有效利用自監督的預訓練,
3.將transformer應用于cv中的其他領域,
理性認識
1. 摘要(abstract)
盡管Transformer架構已經在自然語言處理領域大殺特殺,但是在計算機視覺領域只有有限的應用,在視覺領域中,注意力機制要么與卷積網路結合使用,要么在保持整體結構不變的情況下,替換卷積網路的某些組件,我們證明了,對CNN的依賴不是必要的,在圖象識別任務中,在影像塊(image patches)的序列上應用純粹的Transformer模型也可以表現得很好,當使用大量資料進行預訓練,再遷移到多個中小型圖象識別基準庫后,ViT得到了優異的結果,相比于最先進(SOTA)的卷積網路,而訓練所需要的計算資源更少,
2. 引言(INTRODUCTION)
基于Self-attention的架構,特別是Transformer,已經成為自然語言處理(NLP)的不二選擇,其主要方法是在一個大型文本語料庫上進行預訓練,然后在一個較小的特定于任務的資料集上進行微調,得益于Transformer的計算效率和可擴展性,它可以訓練具有超過100B的引數的超大模型,而且隨著模型和資料集的增長,性能仍然沒有飽和的跡象,
當然,在計算機視覺中,卷積仍然占主導地位,受NLP成功的啟發,許多作業嘗試將Self-attention融合進cnn架構,甚至一些人使用Self-attention替換卷積,后一種模型雖然理論上有效,但還沒有在現代硬體加速器上得到有效擴展,因此,在大規模影像識別中,經典的ResNet(殘差網路)式結構仍然是最先進的,
受NLP中Transformer成功的啟發,我們嘗試將一個標準Transformer直接應用到影像上,盡可能少的修改,為此,我們將影像分割成小塊,并將這些塊轉化為線性嵌入序列,作為Transformer的輸入,影像塊(image patches)就相當于NLP任務中的單詞(token)來做處理,并以有監督的方式訓練影像分類模型,
當在中等規模的資料集(如ImageNet)上進行訓練時,模型的準確率比同等規模的resnet低幾個百分點,這一看似令人沮喪的結果是意料之中的:Transformer缺乏cnn所固有的一些歸納偏置(inductive biases),如平移不變性(translation equivariance)和區域性(locality),因此在資料量不足的情況下訓練時不能很好地泛化,
然而,如果在更大的資料集(1400 -300萬張影像)上訓練模型,情況就會發生變化,我們發現大規模的訓練可以克服歸納偏置(inductive biases),當ViT在足夠的規模上進行預先訓練,并遷移到具有較少資料量的任務時,可以獲得出色的結果,
3.相關作業
Transformer是由Vaswani等人提出,應用于機器翻譯,并已成為許多自然語言處理任務中最先進的方法,基于Transformer的大型模型通常在大型語料庫上進行預先訓練,然后針對當前的任務進行微調,
單純地對影像進行Self-attention需要每兩個像素計算attention,這是像素的平方倍的開銷,為了將Transformer應用到影像中,嘗試許多近似方法,Parmar等人對每個query像素只在區域鄰域計算Self-attention,而非全域,這種區域多頭點積Self-attention塊可以完全替代卷積,其他的,稀疏Transformer采用可擴展的近似全域Self-attention,以適用于影像,計算attentio的另一種方法是將其應用于不同大小的塊中,在極端情況下,僅沿著單個軸,這些專門的注意力架構在計算機視覺任務中表現出了很好的效果,但需要復雜的工程設計,
最為相關的是Cordonnier等人的模型,該模型從輸入影像中提取大小為2 × 2的小塊,并在之上使用完全的Self-attention,這個模型與ViT非常相似,但我們的作業進一步證明,大規模的預培訓可以使香草Transformer與最先進的cnn競爭(甚至更好),此外,Cordonnier 使用的是2 × 2像素的小塊,這使得該模型僅適用于小解析度的影像,而我們也可以處理中等解析度的影像,
最近的另一種相關模型是image GPT (iGPT),它在降低影像解析度和顏色空間后,對影像像素使用Transformer,該模型以無監督的方式作為生成模型進行訓練,然后可以對結果表示進行微調或線性探測以提高分類性能,在ImageNet上達到72%的最大精度,
4.方法(Method)
在模型設計中,盡可能地遵循原Transformer結構,這樣做的優點是可擴展性和易實作——幾乎可以開箱即用,
4.1 VIT
結構圖:
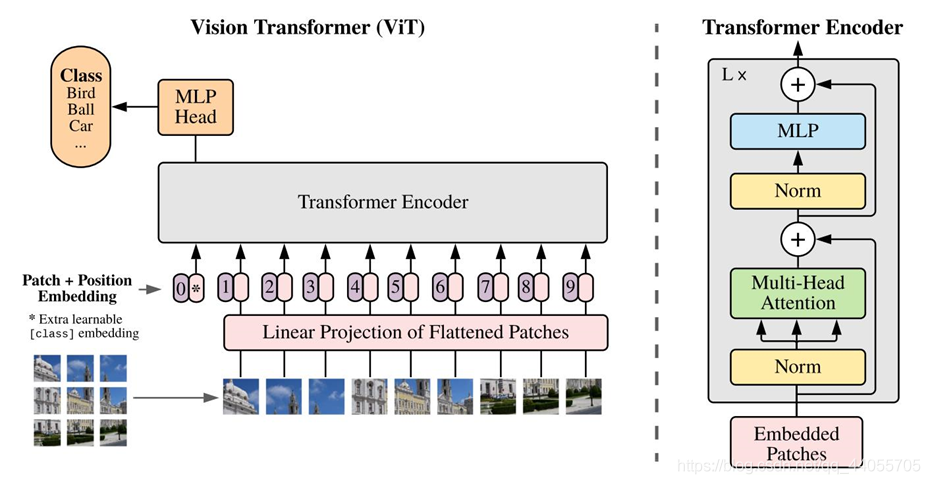
標準的接受token的一維嵌入向量作為輸入,為了處理二維資料,要進行reshape,
原始影像輸入:(H,W)是圖片解析度,C是通道數
x
∈
R
H
×
W
×
C
\text{x\ }\in \ \mathbb{R}^{H\times W\times C}
x ∈ RH×W×Creshape(分割patch):P是patch的大小,N是patch的個數
x
∈
R
N
×
(
P
2
?
C
)
,
N
=
H
W
/
P
2
\text{x\ }\in \ \mathbb{R}^{N\times \left( P^2\cdot C \right)} , N=HW/P^2
x ∈ RN×(P2?C),N=HW/P2flatten(拍平,映射成Transformer接受的固定大小D,映射E是可學習的):
z
0
=
[
x
c
l
a
s
s
;
x
p
1
E
;
x
p
2
E
;
?
?
;
x
p
N
E
]
+
E
p
o
s
,
E
∈
R
(
P
2
?
C
)
×
D
,
E
p
o
s
∈
R
(
N
+
1
)
×
D
\mathbf{z}_0=\left[ \mathbf{x}_{class};\mathbf{x}_{p}^{1}\mathbf{E;x}_{p}^{2}\mathbf{E;}\cdots ;\mathbf{x}_{p}^{N}\mathbf{E} \right] +\mathbf{E}_{pos}\ ,\ \mathbf{E}\in \mathbb{R}^{\left( P^2\cdot C \right) \times D},\ \mathbf{E}_{pos}\in \mathbb{R}^{\left( N+1 \right) \times D}
z0?=[xclass?;xp1?E;xp2?E;?;xpN?E]+Epos? , E∈R(P2?C)×D, Epos?∈R(N+1)×D映射后的結果稱為 patch embeddings,
在patch前面添加一個可學習的xclass,代表著圖片的標簽資訊(全域資訊)
歸納偏置(Inductive bias):vit比cnn有更少的特定于影像的歸納偏置,在cnn中,區域性、二維鄰域結構和平移不變性貫穿整個模型的每一層,在ViT中,只有MLP層是區域和平移等變的,而Self-attention是全域的,二維鄰域結構使用地非常少:在模型開始時,將影像切割成小塊,并在微調時對不同解析度的影像進行位置嵌入調整,除此之外,初始化時的位置嵌入不包含塊的二維位置資訊,所有塊之間的空間關系都需要從頭學習,
混合結構(Hybrid Architecture):輸入序列可以由CNN的feature map組成,從而替代原始影像塊,在這個混合模型中,將patch embedding 應用于從CNN feature map中提取的patches,作為一種特殊情況,patches的尺寸可以是1x1,即簡單地將feature map平坦化,并映射到Transformer的尺寸即可得到輸入序列,如上所述添加分類輸入嵌入和位置嵌入,
4.2 微調和更高的解析度 (FINE-TUNING AND HIGHER RESOLUTION)
通常,在大型資料集上預訓練ViT,并微調到(較小的)下游任務,為此,我們去掉預先訓練的預測頭,并附加一個零初始化的D*K前饋層,其中K是下游類的數量,在輸入高解析度的影像時,我們保持了相同的patch大小,從而得到了更大的有效序列長度,視覺轉換器可以處理任意序列長度(達到記憶體限制),然而,預先訓練的位置嵌入不再有意義,因此,我們根據預先訓練好的位置嵌入在原始影像中的位置,對其進行二維插值,解析度調整和塊提取是唯一一處人工將影像二維結構的歸納偏置注入vit的地方,
5.實驗(EXPERIMENTS)
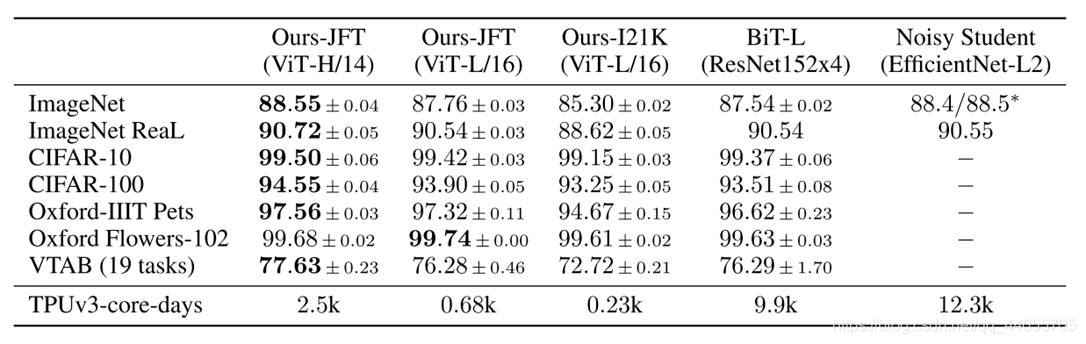
評估了ResNet、Vision Transformer (ViT)和hybrid的學習能力,為了了解每個模型的資料需求,對不同大小的資料集進行了預訓練,并評估了許多基準任務,在考慮模型預訓練的計算成本時,ViT表現得非常好,以較低的預訓練成本在大多數識別基準上達到了最先進的水平,
5.1 setup
資料集(datasets):各種大小的資料集以及測驗基準,
模型變體(Model Variants):基于BERT配置VIT,各種大小的VIT(base,large,huge),patch的大小P也是可調的,P越大,序列長度越小,P越小,長度越長,計算開銷越大,
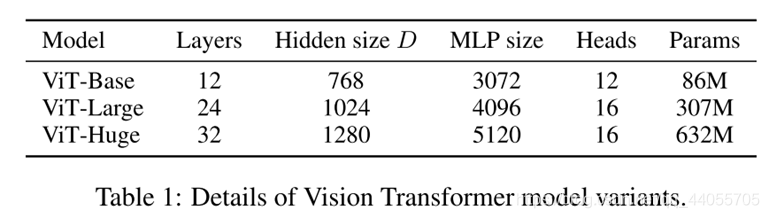
訓練和微調(Training & Fine-tuning.):模型的引數配置,見附錄,
5.2 與SOTA比
6.結論(CONCLUSION)
探討了Transformer在影像識別中的直接應用,與之前在計算機視覺中使用Self-attention的作業不同,除了初始的patch提取步驟,我們不引入影像特有的歸納偏差到架構中,相反,我們將影像解釋為一系列塊,并使用NLP中使用的標準Transformer編碼器來處理它,這種簡單但可擴展的策略,在與大型資料集的預訓練相結合時,效果驚人地好,因此,視覺Transformer 在許多影像分類資料集上匹配或超過了最先進的水平,同時相對低成本地進行預訓練,
雖然這些初步結果令人鼓舞,但仍然存在許多挑戰,一種是將ViT應用于其他計算機視覺任務,如檢測和分割,我們的研究結果,以及Carion等人(2020年)的研究結果,表明了這種方法的前景,另一個挑戰是繼續探索自監督的預訓練方法,我們的初步實驗表明,自監督的預訓練有所改善,但自監督的預訓練與大規模監督的預訓練之間仍有很大的差距,最后,進一步擴展ViT可能會提高性能,
小尾巴
1.歸納偏置
2.自監督預訓練
3.像素級別的影像應用
重點相關論文
1.Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ?ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NIPS, 2017.
Transformer 的提出,祖師爺
2.Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In NAACL, 2019.
BERT 模型,這篇論文中大量的設計來自BERT,如xclass標志位,自監督預訓練等
3.Jean-Baptiste Cordonnier, Andreas Loukas, and Martin Jaggi. On the relationship between selfattention and convolutional layers. In ICLR, 2020.
像素級,小塊級別的attention,和vit很一致
4.Mark Chen, Alec Radford, Rewon Child, Jeff Wu, and Heewoo Jun. Generative pretraining from pixels. In ICML, 2020a.
像素級別,使用Transformer的影像生成模型
參考串列
1.https://blog.csdn.net/weixin_38443388/article/details/113059350
2.https://zhuanlan.zhihu.com/p/336911305
3.https://blog.csdn.net/qq_16236875/article/details/108964948
4.https://zhuanlan.zhihu.com/p/273652295
5.https://blog.csdn.net/weixin_44106928/article/details/110268312
6.https://blog.csdn.net/moxibingdao/article/details/109127507
7.http://www.360doc.com/content/21/0126/16/73546223_959052179.shtml
8.http://www.360doc.com/content/21/0116/16/32196507_957302113.shtml
9.https://zhuanlan.zhihu.com/p/266311690
10.https://openreview.net/forum?id=YicbFdNTTy
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/260579.html
標籤:其他
上一篇:作業系統(二)