下一篇:理解深度學習中的“卷積神經網路”(二)
博主最近在學習YOLO系列演算法,本文是博主學習后的筆記,詳細介紹了卷積,希望能幫助到入門深度學習和卷積網路的童鞋,
宣告:本文用到的部分材料來自吳恩達老師的《深度學習》和51CTO小超老師的 “YOLOV4代碼復現-—行人車輛檢測”課程,文章目錄
- 卷積介紹
- 二維卷積
- 三維卷積
- 卷積核
- 為什么要使用卷積?( 卷積核與全連接層的關系)
卷積介紹
二維卷積
假設:
這里我們假設3種網格,對應3個矩陣,
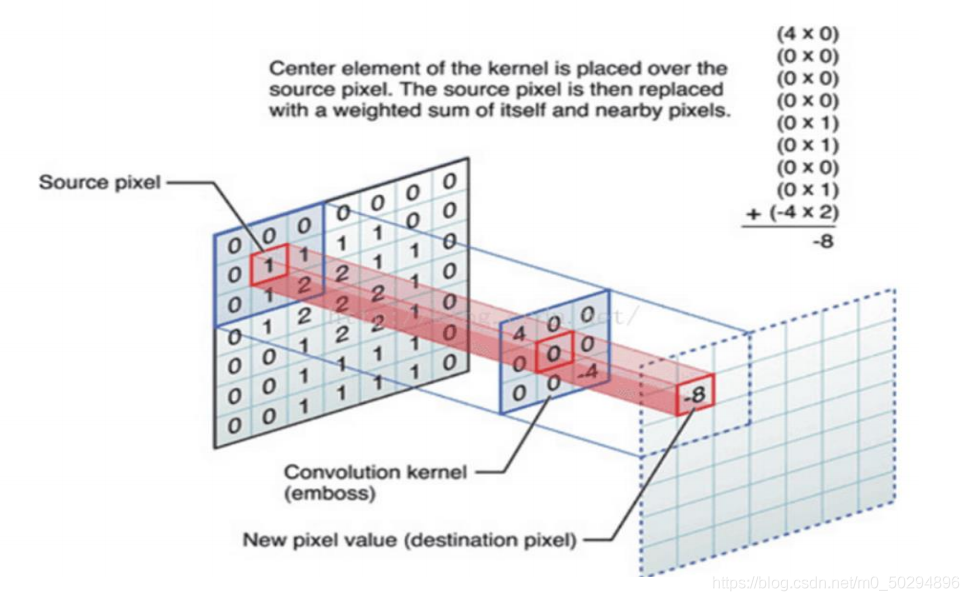
假設我們有一張7×7的輸入圖片,在計算機中,就是一個7×7的矩陣,記為A,同時,假設我們人為構建了另一個3×3的矩陣,這個3×3的矩陣,就是卷積中的過濾器(filter),也稱作卷積核(kernal),最后,假設有一個空的矩陣,存放卷積結果,記為B,
操作:
(1)對7×7的原始影像進行卷積操作時,我們先從左上角開始,圈定一個和卷積核同樣大小的區域,這里就是3×3,然后將此區域單獨拿出,和卷積核執行一個類似點乘的操作,將它們對應位置的元素分別相乘,乘完之后,將得到的9個數值相加,會生成一個新的數,而這個數值,就是我們得到的新的特征值,在下圖中,這個新的特征值就是-8,
將新特征值-8填入存放卷積結果的空矩陣中,對應第一行第一列,即B[0][0]的位置,
(2)在原圖中,記水平為x,豎直為y,將原圖中被圈定執行卷積的區域向右挪一步,即y保持不變,x向右移動一個單位,在下圖中,圈定的9個數就從000 011 012 變為 000 111 122,對這個區域重復執行卷積操作,即與卷積核對應位置元素點乘后相加,得到新的特征數,算出后也是-8,將其填入矩陣B的第一行第二列,B[0][1],
(3)不斷重復上述步驟,對x方向操作完后y方向下移一格,重復操作,直到卷積的區域一直移到右下角,最終生成的B就是一個5×5的矩陣,即原本7×7的影像,經過了3×3的卷積核后,生成了新的5×5的特征圖,
當然這個引數都是可變的,原始影像的影像可能不是7×7,而是608×608甚至更大,而卷積核常見的有1×1,3×3和5×5,
三維卷積
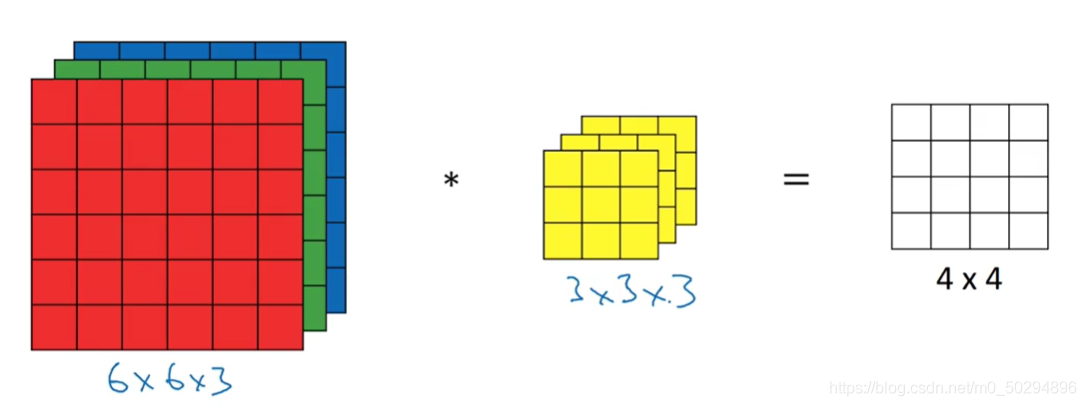
我們需要處理的影像多數情況下并不是灰度圖,可以用二維矩陣模擬,而是彩色圖,假設輸入影像是RGB形式,那么一個影像就有3個通道,分別對應紅色,綠色和藍色,每個通道都對應單獨的一個輸入矩陣,
如圖所示,輸入有3個通道,因此相對應的,卷積核也需要3個通道,在具體卷積時,核的第一層與紅色卷積,第二層與綠色卷積,第三層與藍色卷積,每一層都輸出9個數,一共27個數,值得注意的是,在進行三維卷積時,并不是紅色部分單獨卷,單獨輸出,而是三個通道一起卷積,最終的輸出是一個特征值,這個特征值是27個數值相加得到,
因此,在3維卷積中,輸入是3維,卷積核是3維,但輸出是2維的,
這是單個卷積核所用的結果,如果不只有一個卷積核,而是2個卷積核,那么將對每個卷積核重復上述步驟,得到一個2維輸出,最終得到2個二維輸出,將這2個輸出拼接起來,就是一個3維的新特征輸出,在本例中,為4×4×2,
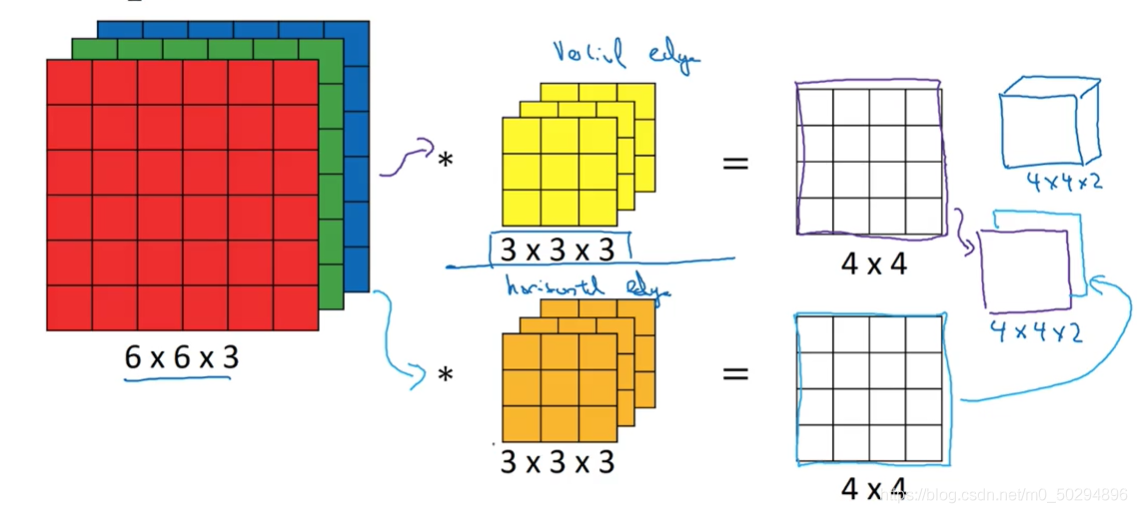
在三維卷積中,卷積核的通道數必須與輸入的通道數相等,而輸出的通道數就是卷積核的數量,
卷積核
在深度學習中,卷積核的尺寸是人為設定的,比如3×3,或者5×5,而里面具體的數則有所不同,可以人為設定,即人工卷積核,也可以通過神經網路學習得到,
人工卷積核的特點:
上文中二維卷積假設的卷積核,左上角是4,右下角是-4,其他區域都是0,這表明此卷積核只關注影像中被圈定部分的左上角和右下角,其權重分別是4和-4,其他地方不關注,
下圖展現了另外兩種卷積核,分別能達到檢測影像垂直邊緣和水平邊緣的作用,詳細可以參考吳恩達老師的深度學習課程中垂直檢測的部分,

下圖中的卷積核只有中間有數值,且權重為1,作用于原圖后最終輸出和原圖的區別只是少了最外面的一圈像素,其他地方不變,

下圖中的卷積核中間數值最大,而其余部分很小,卷積后的結果非常突出中間部分,銳化影像,

此外,通過設定整齊的(0,1)之間的引數,比如都為0.2,有均值模糊的作用,美顏軟體應用較多,可以達到光滑肌膚的作用,
當然,更常見的情況是,不設定卷積核中具體的引數,而是只給它一個尺寸,里面具體的引數則放到神經網路中,讓它自己學習,
為什么要使用卷積?( 卷積核與全連接層的關系)
下面是一個簡單的全連接層的神經網路
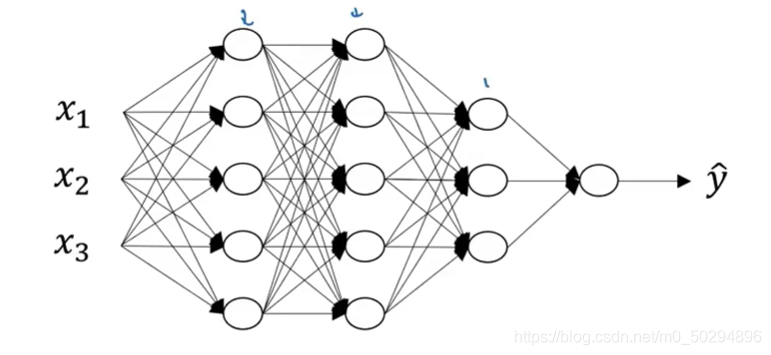
這個神經網路非常小,輸入只有3個特征值,
x
1
,
x
2
x_1,x_2
x1?,x2?和
x
3
x_3
x3?,而且神經網路只有4層,非常淺,而在上文中,即使我們的輸入影像也很小,只有7×7,那也有49個輸入特征,如果是1000×1000的影像呢?如果神經網路有幾十層呢?那么可想而知,需要學習的引數將非常多,一般計算機的計算能力遠遠達不到要求,
同時,全連接層的每一個神經元都是前一層網路經過權重計算得到,對于影像來說,這種操作會損失影像的空間資訊,不利于目標檢測的任務,
基于以上兩個原因,卷積核被應用到神經網路中,卷積核只關注部分資訊,舉例來講,在上文-8的輸出特征中,只是卷積核和原圖中左上角的9個特征輸入做了計算,而其他地方的特征值則沒有參與,相當于將全連接層人為拆開,
對7×7的輸入影像,如果用全連接層,假設第一層神經網路的神經元個數為50,權重引數有50×49約有2500個(如何理解權重:數數上圖中 x 1 , x 2 x_1,x_2 x1?,x2?和 x 3 x_3 x3?到第一層的那5個雞蛋中間是不是有5×3=15條連線?),而如果用10個3×3的卷積核,則引數只有90個,引數縮減效果十分明顯,所以在很多模型中,比如YOLOv4,使用了全卷積網路,在保留空間資訊同時,極大縮減了學習引數的數量,
如果設計的卷積核足夠大,和輸入影像一樣大,也是7×7,那么只能對原圖做一次卷積操作,這個輸出和原圖所有特征都有關,相當于全連接層,
所以,全連接層相當于對全圖做了卷積運算,
關于卷積的其他操作,如步長,池化,padding等,請閱讀
理解深度學習中的“卷積神經網路”(二)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/260726.html
標籤:其他