Graph Embedding
- DeepWalk:圖網路與NLP的巧妙融合
- 先驗知識
- Random Walk
- Skip-Gram
- DeepWalk
- LINE:不得不看的大規模資訊網路嵌入
- 先驗知識
- 一階相似性的LINE模型
- 二階相似性的LINE模型
- 模型優化與輸出結果
因為莫名其妙的審稿意見(laji意見還拒稿了)就要開始學習Graph Embedding, 直接看論文看的一頭霧水,所以來CSDN上搜集資料,從零開始學習Graph Embedding,
DeepWalk:圖網路與NLP的巧妙融合
學習資料:DeepWalk:圖網路與NLP的巧妙融合
DeepWalk是首次將深度學習技術(無監督學習)引入到網路分析(network analysis)中的作業,它的輸入是一個圖,最終目標就是獲得網路圖中每個結點的向量表示
X
e
∈
R
∣
V
∣
×
d
\mathbf{X}_{e} \in \mathbb{R}^{|V| \times d}
Xe?∈R∣V∣×d.
deepwalk給網路學習方向打開了一個新思路,有很多優點:
- 支持資料稀疏場景
- 支持大規模場景(并行化)
但是仍然存在許多不足:
- 游走是完全隨機的,但其實是不符合真實的社交網路的;
- 未考慮有向圖、帶權圖
先驗知識
將network embedding的問題轉化為word embeddin,轉化的方式就是Random Walk ,通過這種方式將圖結構表示為一個個序列,然后把這些序列當成一個個句子,每個序列中的結點就是句子中的單詞,簡單的說,DeepWalk = RandomWalk + SikpGram,
Random Walk
從輸入圖中的任意一個結點 v i v_{i} vi?開始,隨機選取與其鄰接的下一個結點,直至達到給定長度 t t t, 生成的序列 W ~ v i = ( W v i 1 , ? ? , W v i k , ? ? , W v i t ) \tilde{\mathcal{W}}_{v_{i}}=\left(\mathcal{W}_{v_{i}}^{1}, \cdots, \mathcal{W}_{v_{i}}^{k}, \cdots, \mathcal{W}_{v_{i}}^{t}\right) W~vi??=(Wvi?1?,?,Wvi?k?,?,Wvi?t?) ,對于每一個頂點 v i v_{i} vi?, 都會隨機游走出 γ \gamma γ 條序列,
采用隨機游走有兩個好處:
「利于并行化」:隨機游走可以同時從不同的頂點開始采樣,加快整個大圖的處理速度;
「較強適應性」:可以適應網路區域的變化;
Skip-Gram
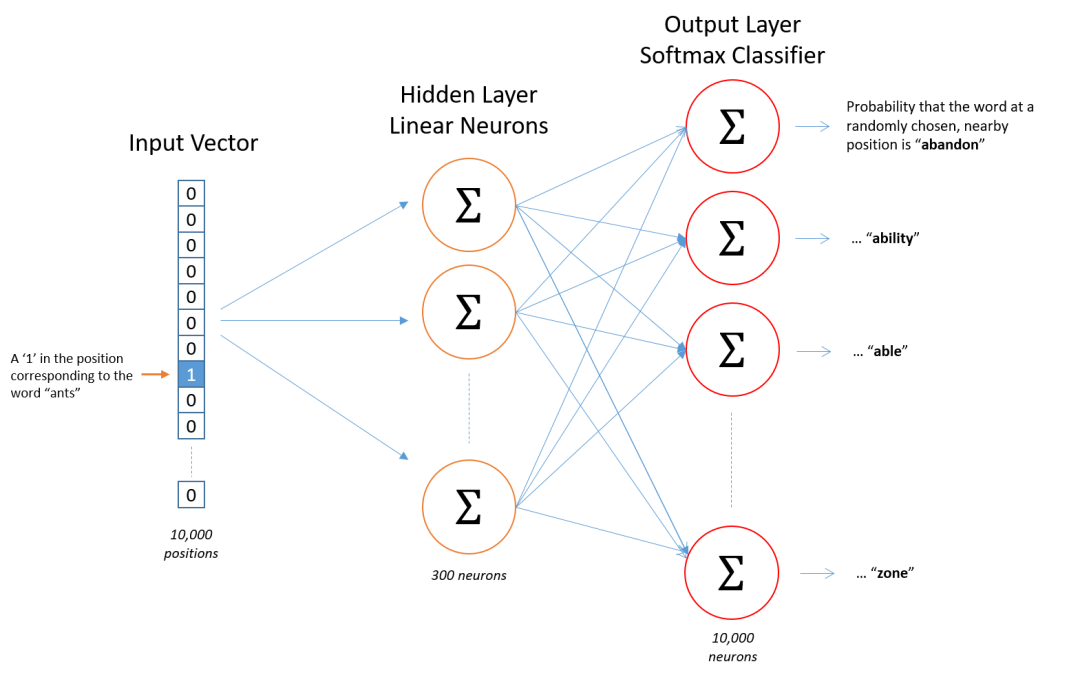
DeepWalk
deepwalk其實就是首先利用random walk來表示圖結構,然后利用skip-gram模型來更新學習節點表示,演算法流程如下所示:

演算法有兩層回圈,第一層回圈采樣
γ
\gamma
γ 條路徑,第二層回圈遍歷圖中的所有結點隨機采樣一條路徑并利用skip-gram模型進行引數更新,
其中第2步構建二叉樹的目的是為了方便后續 SkipGram模型的層次softmax演算法,
引數更新的流程如下:

LINE:不得不看的大規模資訊網路嵌入
學習資料:
- LINE:不得不看的大規模資訊網路嵌入.
- 圖嵌入-LINE-WWW-2015
論文來自2015年微軟,
論文:LINE: Large-scale Information Network Embedding
鏈接:https://arxiv.org/abs/1503.03578
原始碼:https://github.com/tangjianpku/LINE
從論文標題就可以看出,文章主打大規模圖網路,當時大多數的嵌入表示研究在小型圖網路上表現非常不錯,但是當網路規模擴展到百萬、百億級別時,就會顯得不盡人意,此外,適用場景也比較有限,無法應用到有向或者帶權重圖中,為此,本文提出了一種新的網路向量嵌入模型LINE,以解決上述等問題,
先驗知識
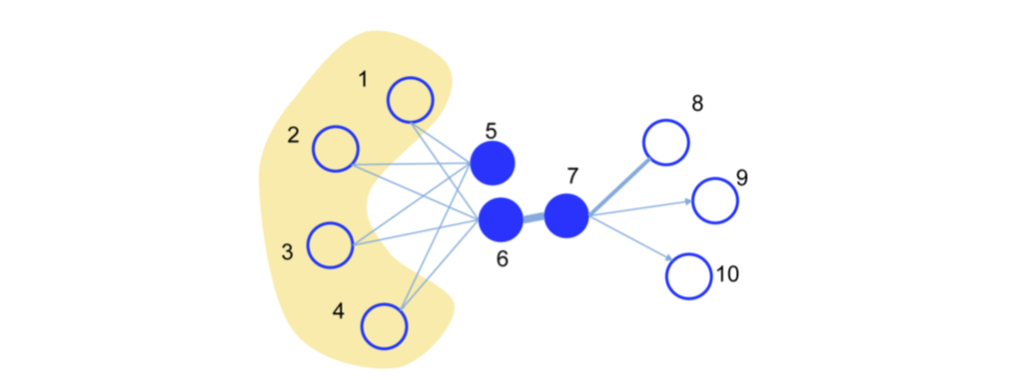
一階相似性
一階相似性定義為兩個頂點
u
u
u 和
v
v
v 之間的鄰近度,用該邊的權重
W
u
v
W_{u v}
Wuv? 表示,如果兩個頂點之間沒有邊,那么它們的一階相似性為0,這個概念是用于模型刻畫區域資訊的,
如上圖,一階相似性的大小就可以用鏈接線的粗細來表示,
二階相似性
在真實場景中,大規模圖中有鏈接的結點相對少,因此如果只用上述一階相似性來建模是不全面的,比如上圖中的5和6結點,兩者沒有鏈接,但是擁有幾乎完全相同的鄰居結點,我們可以認為它們的距離應該也是近的,二階相似性定義為一對結點的鄰居網路結構相似性,這個概念用于模型刻畫全域資訊,
KL散度 (KL-divergence)
KL散度是用于衡量兩個概率分布相似性的指標,定義為:
D K L ( p ∥ q ) = ∑ i = 1 N p ( x i ) log ? p ( x i ) ? ∑ i = 1 N p ( x i ) log ? q ( x i ) D_{K L}(p \| q)=\sum_{i=1}^{N} p\left(x_{i}\right) \log p\left(x_{i}\right)-\sum_{i=1}^{N} p\left(x_{i}\right) \log q\left(x_{i}\right) DKL?(p∥q)=∑i=1N?p(xi?)logp(xi?)?∑i=1N?p(xi?)logq(xi?)
表示概率分布 p p p 和概率分布 q q q 之間的差異,越小越接近,其中 p p p 為真實分布, q q q 為近似 p p p 的分布,
一階相似性的LINE模型
原空間:將邊權歸一化為概率
直觀上兩個結點的相似度是用鏈接強度表示,即邊的權重,可以表示為,
p ^ 1 ( i , j ) = w i j W \hat{p}_{1}(i, j)=\frac{w_{i j}}{W} p^?1?(i,j)=Wwij??
新空間:計算兩點的共現概率
對于兩個頂點
v
i
v_{i}
vi? 和
v
j
v_{j}
vj? ,它們之間的相似性可以用向量距離來表示(其中
u
i
u_{i}
ui? 和
u
j
u_{j}
uj? 分別表示對應的向量 )
p 1 ( v i , v j ) = 1 1 + exp ? ( ? u ? i T ? u ? j ) p_{1}\left(v_{i}, v_{j}\right)=\frac{1}{1+\exp \left(-\vec{u}_{i}^{T} \cdot \vec{u}_{j}\right)} p1?(vi?,vj?)=1+exp(?u iT??u j?)1?
優化目標:兩個空間中的概率分布保持一致
目標函式就是使得節點相似性 p 1 ( v i , v j ) p_{1}\left(v_{i}, v_{j}\right) p1?(vi?,vj?) 和鏈接強度 p ^ 1 ( i , j ) \hat{p}_{1}(i, j) p^?1?(i,j) 盡可能地相同,論文里使用了上一節介紹的KL散度,本場景下,原空間的邊概率分布 p ^ 1 ( i , j ) \hat{p}_{1}(i, j) p^?1?(i,j) 即真實分布 p p p ,新空間中的 p 1 ( v i , v j ) p_{1}\left(v_{i}, v_{j}\right) p1?(vi?,vj?) 即近似分布 q q q.
O 1 = D K L ( p 1 ∥ p ^ 1 ) = ∑ ( i , j ) ∈ E p ^ 1 ( i , j ) log ? p ^ 1 ( i , j ) ? ∑ ( i , j ) ∈ E p ^ 1 ( i , j ) log ? p 1 ( i , j ) O_{1}=D_{K L}\left(p_{1} \| \hat{p}_{1}\right)=\sum_{(i, j) \in E}\hat{p}_{1}(i, j) \log\hat{p}_{1}(i, j)-\sum_{(i, j) \in E} \hat{p}_{1}(i, j) \log {p}_{1}(i, j) O1?=DKL?(p1?∥p^?1?)=∑(i,j)∈E?p^?1?(i,j)logp^?1?(i,j)?∑(i,j)∈E?p^?1?(i,j)logp1?(i,j)
第一項為常數, W W W也是常數,省略所有常數后,目標函式如下:
O 1 = ? ∑ ( i , j ) ∈ E w i j log ? p 1 ( v i , v j ) O_{1}=-\sum_{(i, j) \in E} w_{i j} \log p_{1}\left(v_{i}, v_{j}\right) O1?=?∑(i,j)∈E?wij?logp1?(vi?,vj?)
注意,一階相似度僅適用于無向圖,
二階相似性的LINE模型
原空間:點的鄰居邊權歸一化為概率
將從點 i i i 出發,指向的所有鄰居的集合記為 N ( i ) \mathcal{N}(i) N(i) ,將相應的邊集映射到一個概率空間中:記點 i i i 與它的鄰居 j j j 之間的邊權為 w i j w_{ij} wij?,點 i i i 的出邊的邊權總和為 d i = ∑ j ∈ N ( i ) w i j d_{i}=\sum_{j \in \mathcal{N}(i)} w_{i j} di?=∑j∈N(i)?wij?,出邊 ( i , j ) (i, j) (i,j) 對應的邊概率為:
p ^ 2 ( j ∣ i ) = w i j d i \hat p_{2}(j \mid i)=\frac{w_{i j}}{d_{i}} p^?2?(j∣i)=di?wij??
這個概率可以理解為當前節點是 i i i 的情況下,連接到它的鄰居 j j j 的概率,
新空間:點的鄰居內積歸一化為概率
二階相似性模型和word2vec類似,認為中間結點的背景關系結點交集越大則越相似,對于每個節點 v i v_{i} vi? 都有兩個向量表示:一個是作為中間結點時的表示 u ? i \vec{u}_{i} u i? ,以及作為背景關系結點時的表示 u ? i ′ \vec{u}_{i}^{\prime} u i′? ,對于每一條邊 ( i , j ) (i, j) (i,j) , 由結點 v ? i \vec{v}_{i} v i? 生成背景關系 v ? j \vec{v}_{j} v j? 的概率為:
p 2 ( v j ∣ v i ) = exp ? ( u ? j ′ T ? u ? i ) ∑ k = 1 ∣ V ∣ exp ? ( u ? k ′ T ? u ? i ) p_{2}\left(v_{j} \mid v_{i}\right)=\frac{\exp \left(\vec{u}_{j}^{\prime T} \cdot \vec{u}_{i}\right)}{\sum_{k=1}^{|V|} \exp \left(\vec{u}_{k}^{\prime T} \cdot \vec{u}_{i}\right)} p2?(vj?∣vi?)=∑k=1∣V∣?exp(u k′T??u i?)exp(u j′T??u i?)?
優化目標:兩個空間中的概率分布保持一致
對于每個點,當它在原空間中的鄰居概率分布和它在新空間的鄰居概率分布趨于一致,便可認為原空間中的該點的二階相似性被新空間保留下來,同一階相似性,論文中定義了一個函式表示圖上所有點的新舊空間概率分布差距和:
O 2 = ∑ i ∈ V λ i d ( p ^ 2 ( ? ∣ v i ) , p 2 ( ? ∣ v i ) ) O_{2}=\sum_{i \in V} \lambda_{i} d\left(\hat{p}_{2}\left(\cdot \mid v_{i}\right), p_{2}\left(\cdot \mid v_{i}\right)\right) O2?=∑i∈V?λi?d(p^?2?(?∣vi?),p2?(?∣vi?))
其中, λ i \lambda_{i} λi? 表示點 i i i 在圖中的重要性,論文中函式 d d d 采用了 KL 散度,推理同一階相似性,最后得到
O 2 = ? ∑ ( i , j ) ∈ E w i j log ? p 2 ( v j ∣ v i ) O_{2}=-\sum_{(i, j) \in E} w_{i j} \log p_{2}\left(v_{j} \mid v_{i}\right) O2?=?∑(i,j)∈E?wij?logp2?(vj?∣vi?)
注意,二階相似度既可用于無向圖,也可用于有向圖、帶權圖,
模型優化與輸出結果
二階相似性的目標函式中, 與word2vec相同, p 2 ( v j ∣ v i ) p_{2}\left(v_{j} \mid v_{i}\right) p2?(vj?∣vi?) 這一項的計算會涉及所有和結點 i i i 相鄰結點的內積,計算量很大,為此作者采用了『負采樣』的方式進行優化,其中第一項為正樣本的邊,第二項為采樣的負樣本邊,
log ? σ ( u ? j T ? u ? i ) + ∑ i = 1 K E v n ~ P n ( v ) [ log ? σ ( ? u ? n ′ T ? u ? i ) ] \log \sigma\left(\vec{u}_{j}^{T} \cdot \vec{u}_{i}\right)+\sum_{i=1}^{K} E_{v_{n} \sim P_{n}(v)}\left[\log \sigma\left(-\vec{u}_{n}^{\prime T} \cdot \vec{u}_{i}\right)\right] logσ(u jT??u i?)+∑i=1K?Evn?~Pn?(v)?[logσ(?u n′T??u i?)]
然后,當模型在優化更新程序中,對結點embedding的計算如下,
? O 2 ? u ? i = w i j ? ? log ? p 2 ( v j ∣ v i ) ? u ? i \frac{\partial O_{2}}{\partial \vec{u}_{i}}=w_{i j} \cdot \frac{\partial \log p_{2}\left(v_{j} \mid v_{i}\right)}{\partial \vec{u}_{i}} ?u i??O2??=wij???u i??logp2?(vj?∣vi?)?
很明顯,當邊的權重存在較大的方差時,會導致學習不穩定,無法選擇一個合適的學習率,不難想到如果邊的權重都相同,這個問題不就解決了,于是一個簡單的做法是將權重為 w w w 的邊拆分成 w w w 條binary edge,但是如果 w w w 很大則會很費存盤空間,
一種更合理的思路是對邊進行采樣,采樣概率正比于邊的權重,然后把被采樣到的邊認為是binary edge處理,
通過優化一階相似性和二階相似性,可以得到頂點的兩個表示向量,源向量和目標向量,在使用時,將兩個向量結合起來作為頂點的最終表示,論文中說結合的方式是直接拼接,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/260958.html
標籤:AI