22王道資料結構P39 T22
【2012統考真題】假定采用帶頭結點的單鏈表保存單詞,當兩個單詞有相同的后綴時,可共享相同的后綴存盤空間,例如"loading"和"begin"的存盤映像如下圖所示,
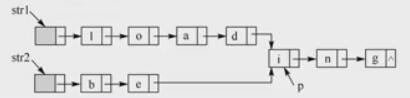
設str1和str2分別指向兩個單詞所在單鏈表的頭結點,鏈表的結點結構為data,next,請設計一個時間上盡可能高效的演算法,找出由str1和str2所指向兩個鏈表共同后綴的起始位置(如圖中字符i所在結點的位置p)
拿到題目我們可以先把鏈表結點結構的結構體寫出來
struct LNode{
char data;//資料域
LNode *next;//指標域
};
typedef LNode* LinkList;
然后我們很容易的就想到了一個很暴力的演算法,str1這個鏈表中的每一個結點和str2中的每一個結點進行比較,假設兩個鏈表的長度分別是len1和len2,那么這個演算法的時間復雜度為
O
(
len
?
1
×
len
?
2
)
\mathrm{O}(\operatorname{len} 1 \times \operatorname{len} 2)
O(len1×len2)
下面我們用代碼來實作一下
LNode* search_start_suffix(LinkList &str1,LinkList &str2){
//尋找str1和str2兩個鏈表中共同后綴的起始位置
LNode *p1=str1->next,*p2=str2->next;
while(p1!=NULL){
p2=str2->next;
while(p2!=NULL){
if(p1==p2)
return p1;//找到共同的結點
p2=p2->next;
}
p1=p1->next;
}
return NULL;//沒有共同結點
}
作為跨考的同學和基礎不好的同學,能寫出上述演算法已經很不錯了,該題也能拿到大部分分數,畢竟標準答案給出的演算法如果沒有接觸過的話的確很難想到,但如果作為本科就是計算機專業的同學,結合本科課程學的一些知識,有能力能快速準確的秒殺本題,
下述內容需要一定的專業知識,跨考生可跳過
如果本科資料結構學的還可以的,第一眼看過去可以發現本題有點類似于Trie(前綴樹,字典樹),但是Trie的前綴是公用的,而本題公用的是后綴,如果忘了Trie是什么的同學可以看一下下面這道題目
10. 英文拼寫檢查工具
目的:
通過設計一個英文拼寫檢查工具,提高學生通過所學知識解決實際問題,
內容:
設計一個“英文拼寫檢查工具”,具體描述如下:
(1) 待檢查的英文文本檔案存放在checked.txt文本中;
(2) 對checked.txt文本中的單詞進行拼寫檢查,將檢查結果輸出到checkout.txt檔案中,其格式為:
單詞 判斷結果
This 0
Thee 1
ada -1
(0 表示正確 1表示錯誤 -1表示無法判斷)
(3) 在checkout.txt檔案最后給出統計果:
總詞匯數:xxxx 正確詞匯數:xxxx 錯誤詞匯: xxx 無法判斷:xxxx,
報告要求:
(1)仔細觀察設計中的各種現象及出現的問題,分析產生各種現象的原因,尋找解決問題的辦法,
(2)報告應至少包括帶注釋的程式清單、輸出的結果及對各種現象的分析意見,
相信你們在學資料結構這門課程的時候一定做過這種類似的題目,具體實作方法就是運用Trie,雖然本題看似是Trie的樣子,但是并不需要用Trie的知識解答,由于不是本文的重點,所以就不再詳細展開講解,
如果想復習Trie相關知識的可以參考我這篇文章leetcode208. 實作 Trie (前綴樹)
相信你們在學習圖論的時候,一定會遇到一道題目,求樹上兩個結點x,y的最短距離,回想一下你們離散數學,資料結構,演算法設計與分析這些課,一定遇到過這個問題,這個問題的解法是求這兩個結點的最近公共祖先,該結點就是結點x與y路上深度最小的結點,也就是路上的拐彎點,
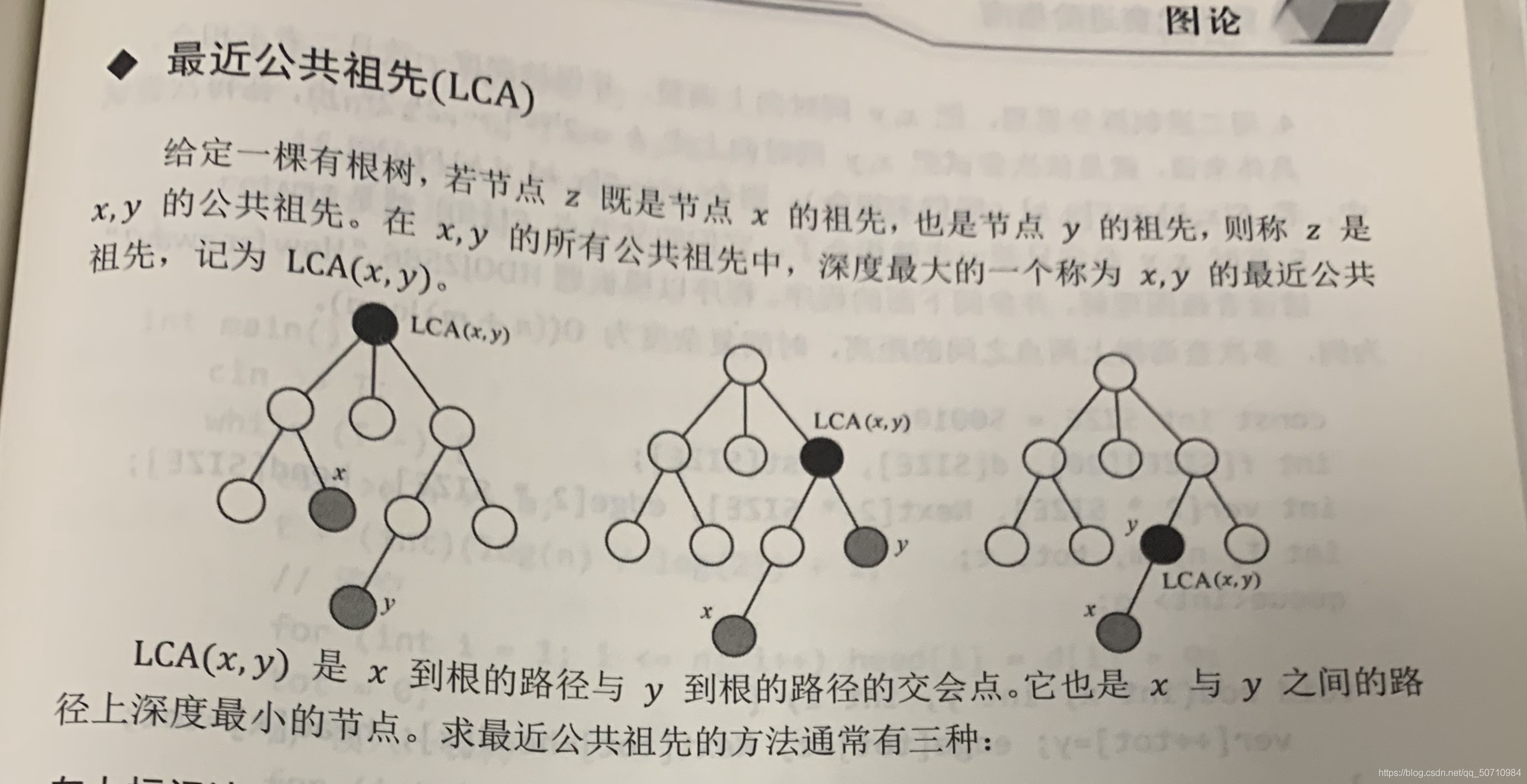
圖片來自于李煜東著作的《演算法競賽進階指南》
求LCA的方法有很多,本題運用的就是一種“同步深度,一起往上爬”的思想,同步深度就是如果結點x與y深度不一樣,那么先讓深度深的往上爬,爬到和另一個結點深度相同的位置,這樣他們到最近公共祖先的結點的距離是一樣的,一起往上爬就是一邊比較一邊往上爬直到到達相同結點,該結點就是結點x與y的最近公共祖先,
下面我們把題目的圖片旋轉逆時針旋轉90°,是不是就可以用求LCA的方法做本題,
所以本題的做法我們可以總結為“同步長度,一起往后走”
演算法設計思想如下:
如果兩個結點x和y是公共結點,那么這兩個結點到達尾結點的距離是相等的,所以只有兩個距離尾結點距離相等的結點才有機會成為公共結點,
用指標p1,p2分別指向兩個鏈表的頭結點,然后分別遍歷兩個鏈表求出鏈表的表長len1,len2,如果鏈表的表長不相等的話,讓指向表長較長的鏈表的指標先往后走,直到剩余長度和另一個鏈表相同,然后p1,p2一邊比較一邊往后走,直到指向相同結點或鏈表尾為止,
代碼實作如下:
int length(LinkList &L){
//求鏈表L的結點個數
Lnode *p=L;//作業指標
int count=0;//計數
while(p->next!=NULL){
p=p->next;
count++;
}
return count;
}
LNode* search_start_suffix(LinkList &str1,LinkList &str2){
//尋找str1和str2兩個鏈表中共同后綴的起始位置
LNode *p1=str1,*p2=str2;
int len1=length(str1),len2=length(str2);
//同步長度,長的先走
if(len1<len2)
for(int i=0;i<len2-len1;i++)
p2=p2->next;
if(len1>len2)
for(int i=0;i<len1-len2;i++)
p1=p1->next;
//一起往前走
while(p1!=NULL){
if(p1!=p2){
p1=p1->next;
p2=p2->next
}
else
return p1;//找到共同結點
}
return NULL;//沒有共同結點
}
本演算法的時間復雜度為
O
(
l
e
n
1
+
l
e
n
2
)
O(len1+len2)
O(len1+len2),可見該演算法優于第一種演算法,
總結:作為本科就是計算機專業的考生,如果本科有扎實的基本功那么遇到這種型別的題目可以達到快速秒殺,從而和其他考生拉開差距,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/261377.html
標籤:其他
下一篇:去年今日(一)