本系列為新TensorRT的第一篇,為什么叫新,因為之前已經寫了兩篇關于TensorRT的文章,是關于TensorRT-5.0版本的,好久沒寫關于TensorRT的文章了,所幸就以新來開頭吧~
接下來將要講解的TensorRT,將會是基于7.0版本,
7版本開頭的TensorRT變化還是挺大的,增加了很多新特性,但是TensorRT的核心運作方式還是沒有什么變化的,關于TensorRT的介紹可以看之前寫的這兩篇:
- 利用TensorRT對深度學習進行加速
- 利用TensorRT實作神經網路提速(讀取ONNX模型并運行)
本文的內容呢,主要是講解:
- TensorRT自定義插件的使用方式
- 如何添加自己的自定義算子
看完本篇可以讓你少踩巨多坑,客官記得常來看啊,
前言
隨著tensorRT的不斷發展(v5->v6->v7),TensorRT的插件的使用方式也在不斷更新,插件介面也在不斷地變化,由v5版本的IPluginV2Ext,到v6版本的IPluginV2IOExt和IPluginV2DynamicExt,未來不知道會不會出來新的API,不過這也不是咱要考慮的問題,因為TensorRT的后兼容性做的很好,根本不用擔心你寫的舊版本插件在新版本上無法運行,
目前的plugin-API:

TensorRT插件的存在目的,主要是為了讓我們實作TensorRT目前還不支持的算子,畢竟眾口難調嘛,我們在轉換程序中肯定會有op不支持的情況,這個時候就需要使用TensorRT的plugin去實作我們的自己的op,此時我們需要通過TensorRT提供的介面去實作自己的op,因此這個plugin的生命周期也需要遵循TensorRT的規則,
一個簡單的了解
那么plugin到底長啥樣,可以先看看TensorRT的官方plugin庫長啥樣,截止寫這篇文章時,master分支是7.2版本的plugin:
https://github.com/NVIDIA/TensorRT/tree/master/plugin
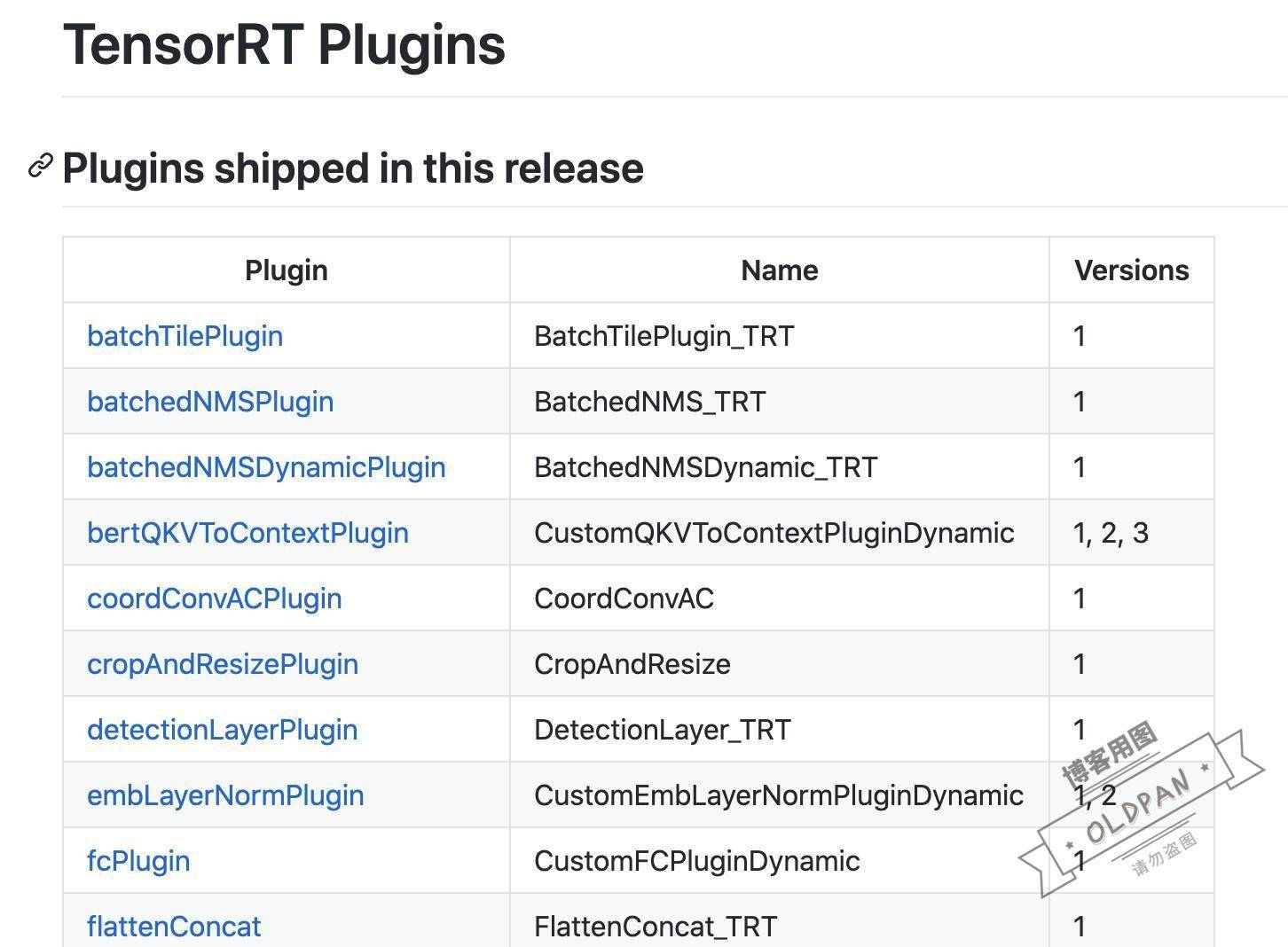
官方提供的插件已經相當多,而且TensorRT開源了plugin部分(可以讓我們白嫖!),并且可以看到其原始碼,通過模仿原始碼來學習plugin是如何寫的,
如果要添加自己的算子,可以在官方的plugin庫里頭進行修改添加,然后編譯官方的plugin庫,將生成的libnvinfer_plugin.so.7替換原本的.so檔案即可,或者自己寫一個類似于官方plugin的組件,將名稱替換一下,同樣生成.so,在TensorRT的推理專案中參考這個元件即可,
以下介紹中,我們需要寫的IPlugin簡稱為插件op,
開始寫插件
有興趣的可以先看看TensorRT的官方檔案,官方檔案的介紹簡單意駭,不過坑是少不了的..而本文的目的,就是盡量讓你少趟坑,
首先按照官方plugin的排布方式,下面隨便挑了個官方plugin:
準備一個自己的插件:custom.cpp和custom.h,copy并paste官方代碼,名字替換成自己的,以最新的IPluginV2DynamicExt類為介面,
我們需要寫兩個類:
MyCustomPlugin,繼承IPluginV2DynamicExt,是插件類,用于寫插件具體的實作MyCustomPluginCreator,繼承BaseCreator,是插件工廠類,用于根據需求創建該插件
對了,插件類繼承IPluginV2DynamicExt才可以支持動態尺寸,其他插件類介面例如IPluginV2IOExt和前者大部分是相似的,
// 繼承IPluginV2DynamicExt就夠啦
class MyCustomPlugin final : public nvinfer1::IPluginV2DynamicExt
class MyCustomPluginCreator : public BaseCreator
MyCustomPlugin 插件類
總覽:
class MyCustomPlugin final : public nvinfer1::IPluginV2DynamicExt
{
public:
MyCustomPlugin( int in_channel,
const std::vector<float>& weight,
const std::vector<float>& bias);
MyCustomPlugin( int in_channel,
nvinfer1::Weights const& weight,
nvinfer1::Weights const& bias);
MyCustomPlugin(void const* serialData, size_t serialLength);
MyCustomPlugin() = delete;
~MyCustomPlugin() override;
int getNbOutputs() const override;
DimsExprs getOutputDimensions(int outputIndex, const nvinfer1::DimsExprs* inputs, int nbInputs, nvinfer1::IExprBuilder& exprBuilder) override;
int initialize() override;
void terminate() override;
size_t getWorkspaceSize(const nvinfer1::PluginTensorDesc* inputs, int nbInputs, const nvinfer1::PluginTensorDesc* outputs, int nbOutputs) const override;
int enqueue(const nvinfer1::PluginTensorDesc* inputDesc, const nvinfer1::PluginTensorDesc* outputDesc,
const void* const* inputs, void* const* outputs,
void* workspace,
cudaStream_t stream) override;
size_t getSerializationSize() const override;
void serialize(void* buffer) const override;
bool supportsFormatCombination(int pos, const nvinfer1::PluginTensorDesc* inOut, int nbInputs, int nbOutputs) override;
const char* getPluginType() const override;
const char* getPluginVersion() const override;
void destroy() override;
nvinfer1::IPluginV2DynamicExt* clone() const override;
void setPluginNamespace(const char* pluginNamespace) override;
const char* getPluginNamespace() const override;
DataType getOutputDataType(int index, const nvinfer1::DataType* inputTypes, int nbInputs) const override;
void attachToContext(cudnnContext* cudnn, cublasContext* cublas, nvinfer1::IGpuAllocator* allocator) override;
void detachFromContext() override;
void configurePlugin(const nvinfer1::DynamicPluginTensorDesc* in, int nbInputs,
const nvinfer1::DynamicPluginTensorDesc* out, int nbOutputs) override;
private:
int _in_channel;
std::vector<float> weight;
std::vector<float> bias;
float* weight;
float* bias;
bool _initialized;
const char* mPluginNamespace;
std::string mNamespace;
};
成員變數
如果你的插件有weights(類似于conv操作的weight和bias),有引數(類似于conv中的kernel-size、padding),在類中則需要定義為成員變數,為private型別:
以MyCustomPlugin為例,假設我們的這個MyCustomPlugin有兩個權重weight和bias以及一個引數in_channel(這個權重和引數沒有啥意義,純粹,純粹為了演示):
private:
int _in_channel; // 引數
std::vector<float> _weight; // 權重,在cpu空間存放
std::vector<float> _bias; // 偏置權重,在cpu空間存放
float* _d_weight; // 權重,在GPU空間存放
float* _d_bias;
bool _initialized;
cudnnHandle_t _cudnn_handle;
const char* mPluginNamespace;
std::string mNamespace;
建構式和解構式
建構式一般設定為三個,
第一個用于在parse階段,PluginCreator用于創建該插件時呼叫的建構式,需要傳遞權重資訊以及引數,
第二個用于在clone階段,復制這個plugin時會用到的建構式,
第三個用于在deserialize階段,用于將序列化好的權重和引數傳入該plugin并創建愛你哦,
以我們的MyCustomPlugin為例:
MyCustomPlugin(int in_channel, nvinfer1::Weights const& weight, nvinfer1::Weights const& bias);
MyCustomPlugin(float in_channel, const std::vector<float>& weight, const std::vector<float>& bias);
MyCustomPlugin(void const* serialData, size_t serialLength);
解構式則需要執行terminate,terminate函式就是釋放這個op之前開辟的一些顯存空間:
MyCustomPlugin::~MyCustomPlugin()
{
terminate();
}
注意需要把默認建構式刪掉:
MyCustomPlugin() = delete;
getNbOutputs
插件op回傳多少個Tensor,比如MyCustomPlugin這個操作只輸出一個Tensor(也就是一個output),所以直接return 1:
// MyCustomPlugin returns one output.
int MyCustomPlugin::getNbOutputs() const
{
return 1;
}
initialize
初始化函式,在這個插件準備開始run之前執行,
主要初始化一些提前開辟空間的引數,一般是一些cuda操作需要的引數(例如conv操作需要執行卷積操作,我們就需要提前開辟weight和bias的顯存),假如我們的算子需要這些引數,則在這里需要提前開辟顯存,
需要注意的是,如果插件算子需要開辟比較大的顯存空間,不建議自己去申請顯存空間,可以使用Tensorrt官方介面傳過來的workspace指標來獲取顯存空間,因為如果這個插件被一個網路呼叫了很多次,而這個插件op需要開辟很多顯存空間,那么TensorRT在構建network的時候會根據這個插件被呼叫的次數開辟很多顯存,很容易導致顯存溢位,
getOutputDataType
回傳結果的型別,一般來說我們插件op回傳結果型別與輸入型別一致:
nvinfer1::DataType InstanceNormalizationPlugin::getOutputDataType(
int index, const nvinfer1::DataType* inputTypes, int nbInputs) const
{
ASSERT(inputTypes && nbInputs > 0 && index == 0);
return inputTypes[0];
}
getWorkspaceSize
這個函式需要回傳這個插件op需要中間顯存變數的實際資料大小(bytesize),這個是通過TensorRT的介面去獲取,是比較規范的方式,
我們需要在這里確定這個op需要多大的顯存空間去運行,在實際運行的時候就可以直接使用TensorRT開辟好的空間而不是自己去申請顯存空間,
size_t MyCustomPlugin::getWorkspaceSize(const nvinfer1::PluginTensorDesc* inputs, int nbInputs, const nvinfer1::PluginTensorDesc* outputs, int nbOutputs) const
{
// 計算這個op前向程序中你認為需要的中間顯存數量
size_t need_num;
return need_num * sizeof(float);
}
enqueue
實際插件op的執行函式,我們自己實作的cuda操作就放到這里(當然C++寫的op也可以放進來,不過因為是CPU執行,速度就比較慢了),與往常一樣接受輸入inputs產生輸出outputs,傳給相應的指標就可以,
int enqueue(const nvinfer1::PluginTensorDesc* inputDesc, const nvinfer1::PluginTensorDesc* outputDesc,
const void* const* inputs, void* const* outputs, void* workspace, cudaStream_t stream){
// 假如這個fun是你需要的中間變數 這里可以直接用TensorRT為你開辟的顯存空間
fun = static_cast<float*>(workspace);
}
需要注意的是,如果我們的操作需要一些分布在顯存中的中間變數,可以通過傳過來的指標引數workspace獲取,上述代碼簡單說明了一下使用方法,
再多說一句,我們默認寫的.cu是fp32的,TensorRT在fp16運行模式下,運行到不支持fp16的插件op時,會自動切換到fp32模式,等插件op運行完再切換回來,
getOutputDimensions
TensorRT支持Dynamic-shape的時候,batch這一維度必須是explicit的,也就是說,TensorRT處理的維度從以往的三維[3,-1,-1]變成了[1,3,-1,-1],最新的onnx-tensorrt也必須設定explicit的batchsize,而且這個batch維度在getOutputDimensions中是可以獲取到的,
在舊版的IPluginV2類中,getOutputDimensions的定義如下:
virtual Dims getOutputDimensions(int index, const Dims* inputs, int nbInputDims) TRTNOEXCEPT = 0;
而在新版的IPluginV2DynamicExt類中定義如下:
virtual DimsExprs getOutputDimensions(int outputIndex, const DimsExprs* inputs, int nbInputs, IExprBuilder& exprBuilder) = 0;
我們要做的就是在這個成員函式中根據輸入維度推理出模型的輸出維度,需要注意的是,雖然說輸出維度
是由輸入維度決定,但這個輸出維度其實“內定”的(也就是在計算之前就算出來了),如果咱的插件op的輸出維度需要通過實際運行計算得到,那么這個函式就無法滿足咱了,

set/getPluginNamespace
為這個插件設定namespace名字,如果不設定則默認是"",需要注意的是同一個namespace下的plugin如果名字相同會沖突,
PluginFieldCollection
這個是成員變數,也會作為getFieldNames成員函式的回傳型別,PluginFieldCollection的主要作用是傳遞這個插件op所需要的權重和引數,在實際的engine推理程序中并不使用,而在parse中會用到(例如caffe2trt、onnx2trt),
當使用這些parse去決議這個op的時候,這個op的權重和引數會經歷Models --> TensorRT engine --> TensorRT runtime這個程序,
舉個例子,在onnx-tensorrt中,我們用過DEFINE_BUILTIN_OP_IMPORTER去注冊op,然后通過parse決議onnx模型,根據注冊好的op去一個個決議構建模型,假如我們定義的op為my_custom_op,在DEFINE_BUILTIN_OP_IMPORTER(my_custom_op)會這樣實作:
DEFINE_BUILTIN_OP_IMPORTER(mycustom_op)
{
ASSERT(inputs.at(0).is_tensor(), ErrorCode::kUNSUPPORTED_NODE);
...
const std::string pluginName = "CUSTOM-OP";
const std::string pluginVersion = "001";
// 這個f保存這個op需要的權重和引數,從onnx模型中獲取
std::vector<nvinfer1::PluginField> f;
f.emplace_back("in_channel", &in_channel, nvinfer1::PluginFieldType::kINT32, 1);
f.emplace_back("weight", kernel_weights.values, nvinfer1::PluginFieldType::kFLOAT32, kernel_weights.count());
f.emplace_back("bias", bias_weights.values, nvinfer1::PluginFieldType::kFLOAT32, bias_weights.count);
// 這個從將plugin工廠中獲取該插件,并且將權重和引數傳遞進去
nvinfer1::IPluginV2* plugin = importPluginFromRegistry(ctx, pluginName, pluginVersion, node.name(), f);
RETURN_FIRST_OUTPUT(ctx->network()->addPluginV2(tensors.data(), tensors.size(), *plugin));
}
進入importPluginFromRegistry函式內部,可以發現引數通過fc變數通過createPlugin傳遞給了plugin:
nvinfer1::IPluginV2* importPluginFromRegistry(IImporterContext* ctx, const std::string& pluginName,
const std::string& pluginVersion, const std::string& nodeName,
const std::vector<nvinfer1::PluginField>& pluginFields)
{
const auto mPluginRegistry = getPluginRegistry();
const auto pluginCreator
= mPluginRegistry->getPluginCreator(pluginName.c_str(), pluginVersion.c_str(), "ONNXTRT_NAMESPACE");
if (!pluginCreator)
{
return nullptr;
}
// 接受傳進來的權重和引數資訊 傳遞給plugin
nvinfer1::PluginFieldCollection fc;
fc.nbFields = pluginFields.size();
fc.fields = pluginFields.data();
return pluginCreator->createPlugin(nodeName.c_str(), &fc);
}
上述步驟中,會提供pluginName和pluginVersion初始化MyCustomPluginCreator,其中createPlugin成員函式是我們需要撰寫的(下文會說),
configurePlugin
配置這個插件op,判斷輸入和輸出型別數量是否正確,官方還提到通過這個配置資訊可以告知TensorRT去選擇合適的演算法(algorithm)去調優這個模型,
但自動調優目前還沒有嘗試過,我們一般自己寫的plugin執行代碼都是定死的,所謂的調優步驟可能更多地針對官方的op,
下面的plugin中configurePlugin函式僅僅是簡單地確認了下輸入和輸出以及型別,
void MyCustomPluginDynamic::configurePlugin(
const nvinfer1::DynamicPluginTensorDesc *inputs, int nbInputs,
const nvinfer1::DynamicPluginTensorDesc *outputs, int nbOutputs) {
// Validate input arguments
assert(nbOutputs == 1);
assert(nbInputs == 2);
assert(mType == inputs[0].desc.type);
}
clone
這玩意兒干嘛的,顧名思義,就是克隆嘛,將這個plugin物件克隆一份給TensorRT的builder、network或者engine,這個成員函式會呼叫上述說到的第二個建構式:
MyCustomPlugin(float in_channel, const std::vector<float>& weight, const std::vector<float>& bias);
將要克隆的plugin的權重和引數傳遞給這個建構式,
IPluginV2DynamicExt* MyCustomPlugin::clone() const
{
//
auto plugin = new MyCustomPlugin{_in_channel, _weight, _bias};
plugin->setPluginNamespace(mPluginNamespace);
return plugin;
}
clone成員函式主要用于傳遞不變的權重和引數,將plugin復制n多份,從而可以被不同engine或者builder或者network使用,
getSerializationSize
回傳序列化時需要寫多少位元組到buffer中,
size_t MyCustomPlugin::getSerializationSize() const
{
return (serialized_size(_in_channel) +
serialized_size(_weight) +
serialized_size(_bias)
);
}
supportsFormatCombination
TensorRT呼叫此方法以判斷pos索引的輸入/輸出是否支持inOut[pos].format和inOut[pos].type指定的格式/資料型別,
如果插件支持inOut[pos]處的格式/資料型別,則回傳true, 如果是否支持取決于其他的輸入/輸出格式/資料型別,則插件可以使其結果取決于inOut[0..pos-1]中的格式/資料型別,該格式/資料型別將設定為插件支持的值, 這個函式不需要檢查inOut[pos + 1..nbInputs + nbOutputs-1],pos的決定必須僅基于inOut[0..pos],
bool MyCustomPlugin::supportsFormatCombination(
int pos, const nvinfer1::PluginTensorDesc* inOut, int nbInputs, int nbOutputs)
{
// 假設有一個輸入一個輸出
assert(0 <= pos && pos < 2);
const auto *in = inOut;
const auto *out = inOut + nbInputs;
switch (pos) {
case 0:
return in[0].type == DataType::kFLOAT &&
in[0].format == nvinfer1::TensorFormat::kLINEAR;
case 1:
return out[0].type == in[0].type &&
out[0].format == nvinfer1::TensorFormat::kLINEAR;
}
}
serialize
把需要用的資料按照順序序列化到buffer里頭,
void MyCustomPlugin::serialize(void *buffer) const
{
serialize_value(&buffer, _in_channel);
serialize_value(&buffer, _weight);
serialize_value(&buffer, _bias);
}
attachToContext
如果這個op使用到了一些其他東西,例如cublas handle,可以直接借助TensorRT內部提供的cublas handle:
void MyCustomPlugin::attachToContext(cudnnContext* cudnnContext, cublasContext* cublasContext, IGpuAllocator* gpuAllocator)
{
mCublas = cublasContext;
}
MyCustomPluginCreator 插件工廠類
總覽:
class MyCustomPluginCreator : public BaseCreator
{
public:
MyCustomPluginCreator();
~MyCustomPluginCreator() override = default;
const char* getPluginName() const override; // 不介紹
const char* getPluginVersion() const override; // 不介紹
const PluginFieldCollection* getFieldNames() override; // 不介紹
IPluginV2DynamicExt* createPlugin(const char* name, const nvinfer1::PluginFieldCollection* fc) override;
IPluginV2DynamicExt* deserializePlugin(const char* name, const void* serialData, size_t serialLength) override;
private:
static PluginFieldCollection mFC;
static std::vector<PluginField> mPluginAttributes;
std::string mNamespace;
};
建構式
創建一個空的mPluginAttributes初始化mFC,
MyCustomPluginCreator::MyCustomPluginCreator()
{
mPluginAttributes.emplace_back(PluginField("in_channel", nullptr, PluginFieldType::kFLOAT32, 1));
mPluginAttributes.emplace_back(PluginField("weight", nullptr, PluginFieldType::kFLOAT32, 1));
mPluginAttributes.emplace_back(PluginField("bias", nullptr, PluginFieldType::kFLOAT32, 1));
mFC.nbFields = mPluginAttributes.size();
mFC.fields = mPluginAttributes.data();
}
createPlugin
這個成員函式作用是通過PluginFieldCollection去創建plugin,將op需要的權重和引數一個一個取出來,然后呼叫上文提到的第一個建構式:
MyCustomPlugin(int in_channel, nvinfer1::Weights const& weight, nvinfer1::Weights const& bias);
去創建plugin,
MyCustomPlugin示例:
IPluginV2DynamicExt* MyCustomPlugin::createPlugin(const char* name, const nvinfer1::PluginFieldCollection* fc)
{
int in_channel;
std::vector<float> weight;
std::vector<float> bias;
const PluginField* fields = fc->fields;
for (int i = 0; i < fc->nbFields; ++i)
{
const char* attrName = fields[i].name;
if (!strcmp(attrName, "in_channel"))
{
ASSERT(fields[i].type == PluginFieldType::kINT32);
in_channel= *(static_cast<const int32_t*>(fields[i].data));
}
else if (!strcmp(attrName, "weight"))
{
ASSERT(fields[i].type == PluginFieldType::kFLOAT32);
int size = fields[i].length;
h_weight.reserve(size);
const auto* w = static_cast<const float*>(fields[i].data);
for (int j = 0; j < size; j++)
{
h_weight.push_back(*w);
w++;
}
}
else if (!strcmp(attrName, "bias"))
{
ASSERT(fields[i].type == PluginFieldType::kFLOAT32);
int size = fields[i].length;
h_bias.reserve(size);
const auto* w = static_cast<const float*>(fields[i].data);
for (int j = 0; j < size; j++)
{
h_bias.push_back(*w);
w++;
}
}
}
Weights weightWeights{DataType::kFLOAT, weight.data(), (int64_t) weight.size()};
Weights biasWeights{DataType::kFLOAT, bias.data(), (int64_t)_bias.size()};
MyCustomPlugin* obj = new MyCustomPlugin(in_channel, weightWeights, biasWeights);
obj->setPluginNamespace(mNamespace.c_str());
return obj;
}
deserializePlugin
這個函式會被onnx-tensorrt的一個叫做TRT_PluginV2的轉換op呼叫,這個op會讀取onnx模型的data資料將其反序列化到network中,
一些官方插件的注意事項
使用官方插件會遇到些小問題,
topk問題
官方的topk插件最多支持k<=3840,否則會報:
[TensorRT] ERROR: Parameter check failed at: ../builder/Layers.cpp::TopKLayer::3137, condition: k > 0 && k <= MAX_TOPK_K
相關問題:https://github.com/tensorflow/tensorflow/issues/31671
batchednms問題
官方的batchednms最大支持的topk為4096,太大也會崩潰,不過可以修改源代碼實作突破這個數值,但仍然有bug:
void (*kernel[])(const int, const int, const int, const int, const float,
const bool, const bool, float *, T_SCORE *, int *,
T_SCORE *, int *, bool) = {
P(1), P(2), P(3), P(4), P(5), P(6), P(7), P(8), P(9), P(10),
P(11), P(12), P(13), P(14), P(15), P(16)
};
關于plugin的注冊
簡單說下plugin的注冊流程,
在加載NvInferRuntimeCommon.h頭檔案的時候會得到一個getPluginRegistry,這里類中包含了所有已經注冊了的IPluginCreator,在使用的時候我們通過getPluginCreator函式得到相應的IPluginCreator,
注冊插件有兩種方式,第一種可以看官方的plugin代碼,
extern "C" {
bool initLibNvInferPlugins(void* logger, const char* libNamespace)
{
initializePlugin<nvinfer1::plugin::GridAnchorPluginCreator>(logger, libNamespace);
initializePlugin<nvinfer1::plugin::NMSPluginCreator>(logger, libNamespace);
initializePlugin<nvinfer1::plugin::ReorgPluginCreator>(logger, libNamespace);
...
return true;
}
其中initializePlugin函式執行了addPluginCreator函式:
template <typename CreatorType>
void initializePlugin(void* logger, const char* libNamespace)
{
PluginCreatorRegistry::getInstance().addPluginCreator<CreatorType>(logger, libNamespace);
}
addPluginCreator函式又執行了getPluginRegistry()->registerCreator對pluginCreator進行了注冊,這樣就完成注冊任務了:
void addPluginCreator(void* logger, const char* libNamespace)
{
...
if (mRegistryList.find(pluginType) == mRegistryList.end())
{
bool status = getPluginRegistry()->registerCreator(*pluginCreator, libNamespace);
if (status)
{
mRegistry.push(std::move(pluginCreator));
mRegistryList.insert(pluginType);
verboseMsg = "Plugin creator registration succeeded - " + pluginType;
}
else
{
errorMsg = "Could not register plugin creator: " + pluginType;
}
}
else
{
verboseMsg = "Plugin creator already registered - " + pluginType;
}
...
}
另一種注冊可以直接通過REGISTER_TENSORRT_PLUGIN來注冊:
//!
//! \brief Return the plugin registry
//!
// 在加載`NvInferRuntimeCommon.h`頭檔案的時候會得到一個`getPluginRegistry`
extern "C" TENSORRTAPI nvinfer1::IPluginRegistry* getPluginRegistry();
namespace nvinfer1
{
template <typename T>
class PluginRegistrar
{
public:
PluginRegistrar() { getPluginRegistry()->registerCreator(instance, ""); }
private:
T instance{};
};
#define REGISTER_TENSORRT_PLUGIN(name) \
static nvinfer1::PluginRegistrar<name> pluginRegistrar##name {}
} // namespace nvinfer1
也就是說,如果我們已經在plugin的.h檔案中執行了REGISTER_TENSORRT_PLUGIN(BatchedNMSPluginCreator);就不需要再創建一個類似于官方的initLibNvInferPlugins()函式去一個一個注冊了,
參考鏈接
https://github.com/NVIDIA/TensorRT/tree/release/7.0/plugin
https://github.com/triton-inference-server/server/issues/767
https://blog.csdn.net/u010552731/article/details/106520241
https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#work_dynamic_shapes
https://forums.developer.nvidia.com/t/tensorrt-5-1-6-custom-plugin-with-fp16-issue/84132/4
https://forums.developer.nvidia.com/t/tensorrt-cask-error-in-checkcaskexecerror-false-7-cask-convolution-execution/109735
https://github.com/NVIDIA/TensorRT/tree/release/7.0/samples/opensource/samplePlugin
https://forums.developer.nvidia.com/t/unable-to-run-two-tensorrt-models-in-a-cascade-manner/145274/2
DCNv2-github
https://github.com/CharlesShang/DCNv2
https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch
交流
如果你與我志同道合于此,老潘很愿意與你交流;如果你喜歡老潘的內容,歡迎關注和支持,博客每周更新一篇深度原創文,關注公眾號「oldpan博客」不錯過最新文章,老潘也會整理一些自己的私藏,希望能幫助到大家,公眾號回復"888"獲取老潘學習路線資料與文章匯總,還有更多等你挖掘,如果不想錯過老潘的最新推文,請點擊神秘鏈接,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/261659.html
標籤:其他