仿真法,自助法
- 仿真法/統計模擬方法(simulation based methods)
- 自助法(Bootstrap method)
- 三. 結語
在最后一章,小弟為大家介紹兩個統計方法,說老實話,這兩個方法可以說的是上古秘籍,統計的起源最早可追溯到1910年,那時候計算機還沒出生呢,當中國還是清朝偽滿洲的時候,有這么一群數學家利用紙和筆在條件很艱苦的情況下,想出了一些統計方法,這些方法就是本章要介紹的,我們不能忘記過去數學家們的智慧和對如今大資料時代的貢獻,
仿真法/統計模擬方法(simulation based methods)
在18世紀,也就是中國乾隆時期,西方有這么個問題—蒲豐投針問題:
假設我們有一個以平行且等距木紋(黑線)鋪成的地板(如圖),

隨意拋一支長度比木紋之間距離小的針(紅線段),求針和其中一條木紋相交的概率,
經過蒲豐計算,如果條紋間距為a,針的長度為
l
l
l,那么針與其中平行線中任意一條相交的概率為
2
l
π
a
\frac{2l}{\pi a}
πa2l?.這里推導也是比較簡單的(相關推導網上均有),但小弟在這還是寫幾筆:
設X表示針的中點到平行線的距離,X服從均勻分布(0,
a
2
\frac{a}{2}
2a?),也就是(0<X<
a
2
\frac{a}{2}
2a?)的概率是均勻的(資料分析模型第二章,連續均勻分布)
f
(
X
)
=
{
1
a
2
?
0
=
2
a
,
0
<
X
<
a
2
0
,
其
他
f(X)=\begin{cases} \frac{1}{\frac{a}{2}-0}=\frac{2}{a}, & 0<X<\frac{a}{2} \\ 0, & 其他 \\ \end{cases}
f(X)={2a??01?=a2?,0,?0<X<2a?其他?
設Y表示針與平行線的夾角,Y服從均勻分布(0,
π
2
\frac{\pi}{2}
2π?)
f
(
Y
)
=
{
1
π
2
?
0
=
2
π
,
0
<
Y
<
π
2
0
,
其
他
f(Y)=\begin{cases} \frac{1}{\frac{\pi}{2}-0}=\frac{2}{\pi}, & 0<Y<\frac{\pi}{2} \\ 0, & 其他 \\ \end{cases}
f(Y)={2π??01?=π2?,0,?0<Y<2π?其他?
X和Y相互獨立,那么X和Y的聯合概率為:
f
(
X
,
Y
)
=
{
2
a
?
2
π
=
4
π
a
,
0
<
X
<
a
2
,
0
<
Y
<
π
2
0
,
其
他
f(X,Y)=\begin{cases} \frac{2}{a}*\frac{2}{\pi}=\frac{4}{\pi a}, & 0<X<\frac{a}{2},0<Y<\frac{\pi}{2} \\ 0, & 其他 \\ \end{cases}
f(X,Y)={a2??π2?=πa4?,0,?0<X<2a?,0<Y<2π?其他?
當
X
<
l
2
s
i
n
Y
X<\frac{l}{2}sinY
X<2l?sinY時,針與線相交,那么:
P
{
X
<
l
2
s
i
n
Y
}
=
∫
0
π
2
∫
0
1
2
s
i
n
(
y
)
f
(
X
,
Y
)
d
x
d
y
=
∫
0
π
2
∫
0
1
2
s
i
n
(
y
)
4
π
a
d
x
d
y
=
2
l
π
a
P\{X<\frac{l}{2}sinY\}=\int_{0}^{\frac{\pi}{2}}\int_{0}^{\frac{1}{2}sin (y)}f(X,Y)dxdy=\int_{0}^{\frac{\pi}{2}}\int_{0}^{\frac{1}{2}sin(y)}\frac{4}{\pi a}dxdy=\frac{2l}{\pi a}
P{X<2l?sinY}=∫02π??∫021?sin(y)?f(X,Y)dxdy=∫02π??∫021?sin(y)?πa4?dxdy=πa2l?
(根據資料分析模型第二章知識點和內容)
因為
X
<
l
2
s
i
n
Y
X<\frac{l}{2}sinY
X<2l?sinY,所以
∫
0
1
2
s
i
n
(
y
)
\int_{0}^{\frac{1}{2}sin(y)}
∫021?sin(y)?,因為
0
<
Y
<
π
2
0<Y<\frac{\pi}{2}
0<Y<2π?所以
∫
0
π
2
\int_{0}^{\frac{\pi}{2}}
∫02π??. 先算
∫
0
1
2
s
i
n
(
y
)
(
?
)
d
x
\int_{0}^{\frac{1}{2}sin(y)}(·)dx
∫021?sin(y)?(?)dx,后算
∫
0
π
2
(
?
)
d
y
\int_{0}^{\frac{\pi}{2}}(·)dy
∫02π??(?)dy,
有位叫蒙特卡洛(Monte Carlo)同學給了另外一個解決方法,那就是實驗,硬干它,經過大量實驗,記錄多少次針與條紋相交的次數,從而得到那么針與其中平行線中任意一條相交的概率,我們也知道根據弱大數理論,如果實驗多次,那么它估計的概率其實也是很準確的,
但當時人家蒙特卡洛同學本意不是為了估計針與條紋相交的概率,人家統計這個概率是為了估計 π \pi π值,利用實驗得到的概率具體值和蒲豐利用微積分計算的概率 2 l π a \frac{2l}{\pi a} πa2l?,來反向估計出 π \pi π值,所以蒲豐投針問題也是用來計算 π \pi π值的,
以現在看,當時人家蒙特卡洛同學通過實驗的方法來估計某一事件的概率,大家覺得這不就是小兒科么,但這就是早期統計的起源,也是最早的統計模擬方法,
有的時候,對于某件事,我們很難純用數學來計算它的概率,舉幾個例子:
1.如果 X 1 , X 2 ~ N ( 0 , 1 ) X_1,X_2~N(0,1) X1?,X2?~N(0,1),那么 P ( ∣ X 1 ∣ + ∣ X 1 ∣ > 2 ) P(\sqrt{|X_1|}+\sqrt{|X_1|}>2) P(∣X1?∣ ?+∣X1?∣ ?>2)是多少?
2.如果 X 1 ~ P o i ( λ 1 ) , X 2 ~ P o i ( λ 2 ) X_1~Poi(\lambda_1),X_2~Poi(\lambda_2) X1?~Poi(λ1?),X2?~Poi(λ2?),那么 P ( X 1 ? X 2 3 2 > 0 ) P(X_1-X_2^{\frac{3}{2}}>0) P(X1??X223??>0)是多少?
這些問題,要是靠純數學計算推導是很難的,這個時候我們需要模擬這個事件,也就是做實驗來計算它的概率,
實驗概率/經驗概率收斂(Convergence of Empirical Probabilities)
我們可以利用統計模擬方法來解決這些問題:
第一步:
反復m次,每一次從它的分布中產生
X
1
,
X
2
.
.
,
X
p
X_1,X_2..,X_p
X1?,X2?..,Xp?個資料,
第二步:估計概率,利用實驗
P
(
X
1
,
X
2
,
.
.
,
X
p
∈
Z
)
≈
1
m
∑
i
=
1
m
I
(
X
1
,
X
2
,
.
.
,
X
p
∈
Z
)
P(X_1,X_2,..,X_p∈Z)≈\frac{1}{m}\sum_{i=1}^{m}I(X_1,X_2,..,X_p∈Z)
P(X1?,X2?,..,Xp?∈Z)≈m1?i=1∑m?I(X1?,X2?,..,Xp?∈Z)
I
(
?
)
I(·)
I(?)為指標方程,即滿足條件則為1,不滿足條件則為0
舉個例子:
X
~
N
(
0
,
1
)
X~N(0,1)
X~N(0,1),計算
P
{
∣
X
∣
>
1
}
P\{\sqrt{|X|}>1\}
P{∣X∣
?>1}的概率
我們先利用純數學來計算下:
設:
Q
=
∣
X
∣
Q=\sqrt{|X|}
Q=∣X∣
?,那么根據正態分布
N
(
0
,
1
)
N(0,1)
N(0,1),得:
P
(
Q
=
q
)
=
(
2
3
π
)
1
2
q
e
x
p
(
?
q
4
2
)
P(Q=q)=(\frac{2^3}{\pi})^{\frac{1}{2}}qexp(-\frac{q^4}{2})
P(Q=q)=(π23?)21?qexp(?2q4?)
那么:
P
(
Q
>
1
)
=
∫
1
∞
P
(
q
)
d
q
=
1
?
2
π
∫
0
x
e
x
p
(
?
t
2
)
d
t
=
0.3171
P(Q>1)=\int_{1}^{∞}P(q)dq=1-\frac{2}{\sqrt{\pi}}\int_{0}^{x}exp(-t^2)dt=0.3171
P(Q>1)=∫1∞?P(q)dq=1?π
?2?∫0x?exp(?t2)dt=0.3171
我們在通過實驗概率/經驗概率收斂的方法來算下:
#MATLAB或者R
X=rnorm(m,0,1)
mean(sqrt(abs(X))>1)
>m=100, 0.3300
>m=1000, 0.3310
>m=100000, 0.3176
>m=10^9, 0.317102
那么根據抽取 1 0 9 10^9 109次資料(每次實驗抽一個資料),我們利用實驗估計 P { ∣ X ∣ > 1 } P\{\sqrt{|X|}>1\} P{∣X∣ ?>1}的概率大約為0.317102.
我們可以發現其實通過實驗來計算概率和純數學計算的結果幾乎一樣,當我們的實驗次數足夠多的情況下,
當然了這個方法也有缺點:
那就是實驗多少次才算足夠,當我們計算出的概率結果比
1
m
\frac{1}{m}
m1?還要小,說明我們的計算已經被
1
m
\frac{1}{m}
m1?所影響了,那樣計算出的概率結果是不準確的,因為如果當m足夠大時,我們的
1
m
\frac{1}{m}
m1?會趨近于0.
但我們有解決這個缺點的辦法:
我們會先叫實驗的次數和每次實驗抽取多少資料均為m,如果最后計算的概率結果小于
1
m
\frac{1}{m}
m1?,那就說明估計不準確,對于較小值的概率結果,我們則需要較大的實驗次數,試驗次數至少是
1
概
率
結
果
\frac{1}{概率結果}
概率結果1?的10倍,
偽亂數(Pseudo Random Numbers)
在做仿真法/統計模擬法時,我們會需要一些亂數,例如:根據分布隨機生成資料,隨機生成數字,
雖然計算機可以隨機生成數字,但如果計算機是根據一些特定規則進而隨機生成數字,這類亂數被稱為偽亂數,偽亂數可以用計算機大量生成,是模擬研究中重要的一步,可以提高效率,
偽亂數最初是利用均勻分布的思想,但如今小弟就不知道了,因為創造偽亂數的方法多了,例如馬特塞特旋轉演算,線性同余法,乘同余法,后面的兩種方法均是離散數學范疇但還是用到了均勻分布還是比較簡單的,據小弟所知,大部分編程語言創造偽亂數還是利用均勻分布的思想,
小弟在此就分享下利用均勻分布來創建偽亂數,若有其他創造偽亂數的方法,那基本上是大同小異,
均勻分布隨機變數產生其他分布的隨機變數
首先我們要有個均勻分布
U
(
0
,
1
)
U(0,1)
U(0,1),選取變數∈(0,1),那么我們可以利用均勻分布變數∈(0,1)來得到其他分布的變數,
第一步:給定其他分布或者概率密度函式 Z = F ( Y ) Z=F(Y) Z=F(Y)
第二步:計算它的反函式 F ? 1 ( Z ) = Y F^{-1}(Z)=Y F?1(Z)=Y,那么我們都知道這個 Z Z Z∈(0,1),有的沒有反函式就分段,
第三步:生成隨機變數X從均勻分布 U ( 0 , 1 ) U(0,1) U(0,1)
第四步: 帶入反函式 F ? 1 ( X ) = Y F^{-1}(X)=Y F?1(X)=Y那么我們便利用均勻分布的變數 X X X,得到了其他分布的變數 Y Y Y了,
我們既然可以利用均勻分布隨機變數得到其他分布的隨機變數,那么,如何叫它隨機呢?
隨機化:
隨機化主要是在于隨機選取均勻分布的變數上,
f
(
X
0
,
X
1
,
.
.
.
,
X
n
?
2
,
X
n
?
1
)
=
X
n
f(X_0,X_1,...,X_{n-2},X_{n-1})=X_n
f(X0?,X1?,...,Xn?2?,Xn?1?)=Xn?
舉個例子:
我們先初始給一個
X
0
X_0
X0?的值,該值被稱為種子(seed),
f
(
?
)
f(·)
f(?)被稱為轉換方程,這里轉換方程就很多了,各有各的優點,例如有的方法可以使亂數更均勻,有的影響亂數列的周期長短,有的需要引數間互為質數等等,
當我們有了
X
0
X_0
X0?,我們利用
f
(
?
)
f(·)
f(?)得到
X
1
X_1
X1?,再利用
X
0
,
X
1
X_0,X_1
X0?,X1?帶入
f
(
?
)
f(·)
f(?)中得到
X
2
X_2
X2?,但無論怎樣我們的
X
0
,
X
1
,
.
.
.
,
X
n
?
2
,
X
n
?
1
∈
(
0
,
1
)
X_0,X_1,...,X_{n-2},X_{n-1}∈(0,1)
X0?,X1?,...,Xn?2?,Xn?1?∈(0,1).
這樣我們的實作了在均勻分布上隨機選取變數,從而隨機產生其他分布上的變數,
偽亂數缺點:
好的種子比較關鍵,另外如果使用相同的種子,那么它們產生的偽亂數是相同的,
自助法(Bootstrap method)
自助法也經常被用在統計模擬方法中,自助法和統計模擬法均為大家族多次采樣方法中的一員,我們在前兩章其實已經了解了它們家族的另外一員,那就是CV(交叉驗證),
對于交叉驗證,我們估計對于未來資料(測驗資料)預測的差值,
對于自助法, 它是用來看看我們的估計是否穩定(例如標準差,置信區間等等)
在第三章中,我們經過多次取樣,我們會得到樣本分布,即如下圖:

Population, 則是我們的總體資料,多次取樣(samples),取相同數量的資料,再利用每次取樣得來的樣本資料估計總體引數,
舉個例子:
我們目前有一組很感興趣的樣本,那么我們可以利用上圖的自助法分布來估計這組由感興趣樣本所估計出的引數
θ
ˉ
\bar \theta
θˉ偏差和方差
假如我們已經反復取樣了M次,分別估計它們的引數,偏有了M個 θ ˉ ( i ) \bar \theta^{(i)} θˉ(i),那么我們可以估計出該感興趣樣本引數的 θ ˉ \bar \theta θˉ的偏差和方差
估計
θ
ˉ
\bar \theta
θˉ的偏差:
b
i
a
s
=
1
M
∑
i
=
1
M
(
θ
ˉ
?
θ
ˉ
(
i
)
)
bias=\frac{1}{M}\sum_{i=1}^{M}(\bar \theta-\bar \theta^{(i)})
bias=M1?i=1∑M?(θˉ?θˉ(i))
估計
θ
ˉ
\bar \theta
θˉ的方差:
V
a
r
=
(
1
M
?
1
)
∑
i
=
1
M
(
θ
ˉ
(
i
)
?
θ
ˉ
)
2
Var=(\frac{1}{M-1})\sum_{i=1}^{M}(\bar \theta^{(i)}-\bar \theta)^2
Var=(M?11?)i=1∑M?(θˉ(i)?θˉ)2
除此之外,經過多次取樣后,我們自然也會得到樣本的分布,就像我們之前第三章和第四章內容所講,經過利用樣本的估計引數后(就是一些數學轉換),我們自然也會得到估計引數的分布,
舉個例子:
我們抽一次樣本得
y
=
(
y
1
,
y
2
,
.
.
,
y
n
)
y=(y_1,y_2,..,y_n)
y=(y1?,y2?,..,yn?),該樣本有n個資料,并作為我們感興趣的樣本,
我們利用該感興趣的樣本來估計引數 θ ˉ \bar \theta θˉ
利用自助法邏輯:
1.抽取M次數樣本,每個樣本均也需要有n個資料
2.每個樣本分別估計引數記作
θ
ˉ
(
i
)
,
i
=
1
,
2
,
3..
,
M
\bar \theta^{(i)},i=1,2,3..,M
θˉ(i),i=1,2,3..,M
那么我們便可以做很多事情了,估計我們興趣樣本的偏差,方差,當然了,因為我們有了 θ ˉ ( i ) , i = 1 , 2 , 3.. , M \bar \theta^{(i)},i=1,2,3..,M θˉ(i),i=1,2,3..,M的分布,我自然也可以計算這個分布的置信區間,
大家不要被小弟上述例子從而局限了想象力,自助法的本質就是多次取樣,還記得第八章中的一幅圖么,即如下:
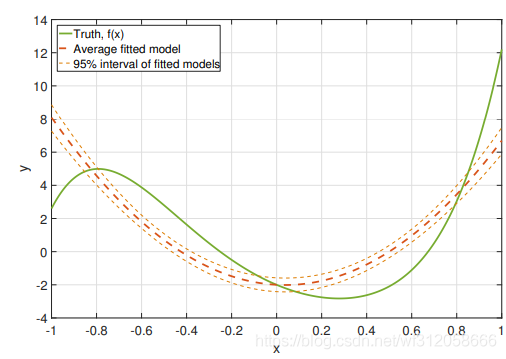
我們不看綠線,就看圖中橘色虛線和線段,即平均擬合模型和95%平均擬合模型,這里95%其實就是95%
θ
ˉ
(
i
)
,
i
=
1
,
2
,
3..
,
M
\bar \theta^{(i)},i=1,2,3..,M
θˉ(i),i=1,2,3..,M的分布置信區間,然后把估計的引數依次帶入到模型里去,然后在把你想預測的資料代入進去,這樣你的預測就會有個范圍即95%,至于橘色線段即平均擬合,則是算的預測值的均值罷了,
在第6章,我們也接觸過簡單線性回歸對于預測的置信區間,還記得么 ( Y ? β ˉ 0 ? β ˉ 1 x 0 ) / [ n + 1 n + ( x 0 ? x ˉ ) 2 ( ∑ i = 1 n x i 2 ? n x ˉ 2 ) R S S n ? 2 ] ~ t n ? 2 ({Y-\bar\beta_0-\bar\beta_1 x_0})/{[\sqrt{\frac{n+1}{n}+\frac{(x_0-\bar x)^2}{(\sum_{i=1}^{n}x^2_i-n\bar x^2)}} \sqrt{\frac{RSS}{n-2}}}]~t_{n-2} (Y?βˉ?0??βˉ?1?x0?)/[nn+1?+(∑i=1n?xi2??nxˉ2)(x0??xˉ)2? ?n?2RSS? ?]~tn?2?, x 0 x_0 x0?則是測驗資料,對沒錯,有了分布我們便可以得到關于簡單線性回歸的預測95%置信區間,你可以用純數學的方式來找到關于某個模型的分布,但現實很殘酷,有些模型過于復雜,利用純數學的方式我們是很難做的,旦旦一個簡單線性回歸的分布都如此復雜,就不要說比簡單新型回歸更復雜的模型了,還是以上圖為例,該圖其實是多項式分布模型,綠色線為真多項式分布,并且有5項,要想用數學找到該模型的分布是很困難的,所以才會有蒙特塔羅的思想,就是多做實驗,多抽樣,用簡單粗暴的方式,
總之一句話,多做實驗,多動手,多取樣,再看分布,有時候你覺得能用數學推,到最后你會發現現實很殘酷,
自助法的優點:
簡單粗暴,很容易做,也很容易理解,
估計準確度會隨著樣本的增加而增加
自助法經常用在計算偏差,方差,預測差,置信區間,
自助法缺點:
算起來太慢了,
對于某些問題需要轉換,例如拉索
排列檢驗(Permutation tests)
在最后,小弟介紹一個另一個統計方法,即排列檢驗,經常用在樣本分布上面,其實大家早就知道了,它就是p值,
簡單回顧下
H
0
:
β
=
0
,
H
1
≠
0
H_0:\beta=0, H_1≠0
H0?:β=0,H1??=0
計算p值,看是否拒絕原假設,
那么如何利用p值用在多次抽樣上面呢?
我們用例子來解釋:
我們要用排列檢驗計算p值,來看是否 β ˉ = 1.4310 \bar\beta=1.4310 βˉ?=1.4310
現在我們從這些資料(總體)里取樣,取個m次,分別估計引數
β
ˉ
(
i
)
\bar\beta^{(i)}
βˉ?(i).
此時我們計算p值:
p
≈
1
m
∑
i
=
1
m
I
(
∣
β
ˉ
(
i
)
∣
>
∣
β
ˉ
∣
)
p≈\frac{1}{m}\sum_{i=1}^{m}I(|\bar\beta^{(i)}|>|\bar\beta|)
p≈m1?i=1∑m?I(∣βˉ?(i)∣>∣βˉ?∣)
I
(
?
)
I(·)
I(?)符合條件為1,不符合條件為0
我們來張圖:
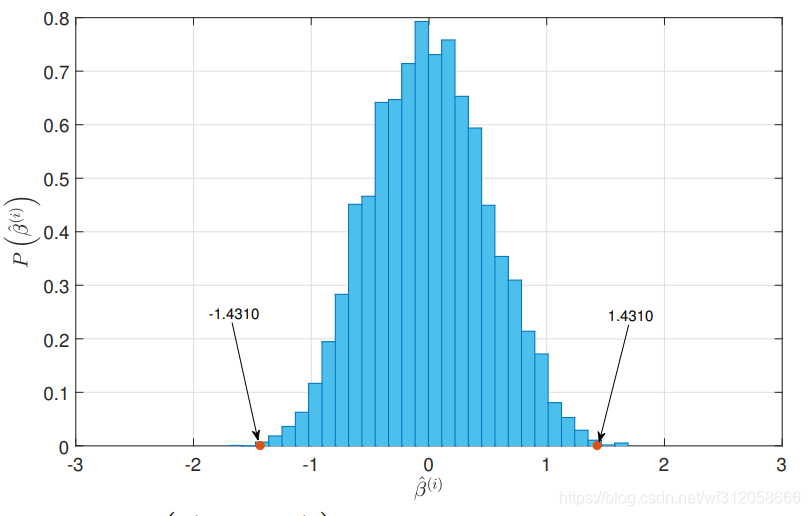
經過m=10000次的抽樣,我們估計10000個
β
ˉ
(
i
)
\bar\beta^{(i)}
βˉ?(i)即我們的x軸.計算頻率,則有了y軸,我們利用所有資料估計的
β
ˉ
\bar\beta
βˉ?=1.4310.可以看到
P
(
∣
β
ˉ
(
i
)
∣
>
∣
β
ˉ
∣
)
P(|\bar\beta^{(i)}|>|\bar\beta|)
P(∣βˉ?(i)∣>∣βˉ?∣)即上圖±1.4310的兩個外端概率是很小的約為0.0013(p值太小)拒絕原假設,我們其實能夠清楚看到,也側面說明了,
β
ˉ
≠
1.4310
\bar\beta≠1.4310
βˉ??=1.4310,
排列檢驗與我們之間的假設檢驗區別在于,排列檢驗不需要基于原假設,但假設檢驗需要基于原假設去計算,
在排列檢驗里,其實它更注重的是多次取樣后的資料分布,然后根據條件,計算最小概率即p值來進行觀察原假設或者備擇假設,
排列檢驗的優點:
對于非正態分布的模型計算p值更準確
好寫代碼,很好應用
排列檢驗的缺點
結果很容易受到采樣的次數影響,
可能會運行很慢
三. 結語
有公式推導錯誤的或理論有謬誤的,請大家指出,我好及時更正,感謝,
感謝大家來閱讀小弟我分享的一些關于基礎統計的知識,如果將來有時間,小弟會陸續分享更多知識,例如高等資料分析,機器學習,計算機視覺,神經網路,優化等幾門課的知識分享,也希望小弟可以堅持分享下來吧,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/261723.html
標籤:其他
上一篇:哥德巴赫分解