文章目錄
- 資訊的表示與處理
- 1 資訊存盤
- 1.1 尋址與位元組順序
- 1.2 字資料大小
- 1.3 位運算、邏輯運算與移位運算
- 2 整數表示與計算
- 2.1 無符號整型
- 2.2 有符號整型
- 2.3 整型計算
- 3 浮點數表示與計算
- 3.1 浮點型的編碼規則
- 3.2 浮點數的分類表示
- 3.3 浮點數的舍入
- 3.4 浮點數的計算
資訊的表示與處理
眾所周知,計算機采用二進制,因此一切計算機中的資訊本質上都是01串,只是它們的編碼與解碼協議不同,同樣的01串,經過不同的解碼協議其含義是不同的,比如說LSP可以表示Language Server Protocol,也可以被解釋成Old Sex Pi(大霧 ? \ ^\bullet ? v ? \ ^\bullet ? )
那么為什么計算機采用二進制(binary),而不是我們熟悉的十進制(decimal)或者十六進制(hexadecimal)呢?因為二進制在信號的表達上有天然的優勢,比如說我讓低電勢表示0高點勢表示1,這里的低和高又有一個容錯,因為現實世界是肯定有噪聲的,所以高電勢和低電勢分別表示為一個范圍,而如果要應用10進制的話那么得切分很多個閾值,而且容錯性還不強,故二進制是最優選,
上面都是扯談,下面開始正文,
1 資訊存盤
1.1 尋址與位元組順序
計算機中的最小資訊存盤單位為bit,而最小尋址單位為byte,也即每一個指標指向一個byte,而指標的大小則由計算機的字長(word size)決定,字長決定的最重要的系統引數就是虛擬地址空間的最大大小,一個字長為 w w w的機器的尋址空間為0~ 2 w ? 1 2^w-1 2w?1,故32位機器的最大尋址空間為 2 32 B y t e = 4 G 2^{32}\mathrm{Byte}=4\mathrm{G} 232Byte=4G,這顯然跟不上現代人民對計算機性能的要求,因此現在大多數計算機都是64位的,
確定了地址的大小,也要確定其編碼與解碼協議,地址實際上也就是由幾個位元組拼起來的,所以接下來我們介紹位元組內部的順序,位元組順序分為兩種,小端法(little endian)和大端法(big endian),這兩個起源于《格列佛游記》的說法,被人們廣泛且頗具偏好的接受,一方面大多數Intel兼容機都只采用小端法,另一方面IBM和Oracle的大多數機器則是按打斷模式操作,
小端法指最低有效位元組排在最前面,大端法指最高有效位元組排在前面,舉個栗子, 54 1 ( 10 ) 541_{(10)} 541(10)?,根據大端法我們讀作“五百四十一”,根據小端法我們讀作“一百四十五”,我本人更傾向大端法,因此本文后續非特別宣告一般默認大端法,
1.2 字資料大小
計算機中的資料型別有許多,下面介紹一些比較基礎的型別的資料大小,
short與long兩個限定符的引入可以為我們提供滿足實際需要的不同長度的整形數,int通常代表特定機器中證書的自然長度,short型別通常為16位,long型別通常為32位,int型別可以為16位或32位,各編譯器可以根據硬體特性自主選擇合適的型別長度,但要遵循下列限制:short與int型別至少為16位,long型別至少為32位,并且short型別不得長于int型別,而int型別不得長于long型別,————《C程式設計語言》
也就是說對于short、int、long,C并沒有規范其型別大小,因此在不同的編譯器上分配的大小可以不一樣,指標型資料由機器的為而定,而float和double表示的浮點數,其標準由IEEE規定了,故在各個機器上都是一樣的,下面列舉各個機器上的gcc為他們分配的大小
| 有符號 | 無符號 | 32位機器 | 64位機器 |
|---|---|---|---|
| [signed] char | unsigned char | 1 | 1 |
| short | unsigned short | 2 | 2 |
| int | unsigned int | 4 | 4 |
| long | unsigned long | 4 | 8 |
| long long | unsigned long long | 8 | 8 |
| int8_t | uint8_t | 1 | 1 |
| int16_t | uint16_t | 2 | 2 |
| int32_t | uint32_t | 4 | 4 |
| int64_t | uint64_t | 8 | 8 |
| char * | 4 | 8 | |
| float | 4 | 4 | |
| double | 8 | 8 |
對關鍵字的順序以及是否包括“signed”,C語言允許多種存在形式,比如unsigned long = unsigned long int = long unsigned = long unsigned int,
1.3 位運算、邏輯運算與移位運算
位運算指&與、|或、^異或、~取反,前三個是雙目運算子,最后一個是單目運算子,異或也叫半加運算,其運演算法則相當于不帶進位的二進制加法,輸入相同輸出為0,輸入不同輸出為1,
邏輯運算子與位運算子比較類似,不過邏輯運算子是作用于整個資料型別上而不是位上,&&于、||或、!非,前兩個雙目運算,最后一個單目運算,
移位運算分為<<左移、>>右移,其中右移分為邏輯右移和算術右移,左移表示原來的二進制串一起向左移動,剩余的地方補0,顯然這有可能導致溢位,溢位的部分我們舍棄掉,邏輯右移表示原來的二進制串一起向右移動,空出的地方補0,溢位的地方舍棄,算術右移表示原來的二進制串一起向右移動,空出的地方按最高位補齊,溢位的地方舍棄,
在Java中>>表示邏輯右移,>>>表示算術右移,在C中沒有限定這兩種右移在使用域上的區別,然而一般來說對有符號用算術右移,對無符號用邏輯右移,很顯然算術右移可以保持有符號int的正負,在下一節整數計算時我們也會提到,
另外一個要注意的就是當移位運算的移位特別大時,一位由 w w w位組成的資料型別,如果要移動 k ≥ w k\ge w k≥w位,會得到移動 k m o d w k\quad mod\quad w kmodw位,
2 整數表示與計算
2.1 無符號整型
無符號 w w w位整型,其權重向量為 [ 2 w ? 1 , 2 w ? 2 , . . . . . . , 2 1 , 2 0 ] [2^{w-1},2^{w-2},......,2^1,2^0] [2w?1,2w?2,......,21,20],它只能表示自然數,不能表示負整數,
2.2 有符號整型
有符號 w w w位整型,其權重向量為 [ ? 2 w ? 1 , 2 w ? 2 , . . . . . . , 2 1 , 2 0 ] [-2^{w-1},2^{w-2},......,2^1,2^0] [?2w?1,2w?2,......,21,20],第一位是符號位,顯然第一位為0時該整型表示自然數,第一位為1時該整型表示負整數,這種方式叫補碼(two complement),
這里我們可以理解為啥對有符號整型的移位運算要用算術右移,因為只有這樣才能保證第一位不變,從而保持其符號不變,補碼與邏輯右移的精巧性在于其能恰好使得有符號整型的乘除法的移位運算表達形式,能與簡單的無符號整型統一起來,共用一種簡單的模式,
2.3 整型計算
顯然整數是一個交換環,其加法乘法運算滿足交換律和結合律,且乘法對加法有分配律,但是在整型中要注意,由于我們的整型是由有限記憶體表示的,故其加減乘除實際上都有取模運算的程序,稍不留神就會溢位,由于溢位的存在,整型中的大小關系變得不可傳遞,即若$>b,而ac不一定大于bc,
對于w位的無符號資訊x和y的加法, x + y ≤ 2 w x+y\le 2^w x+y≤2w時不會溢位,否則會溢位,可以發現,隨機情況下,溢位的概率是1/2,對于w位的有符號資訊x和y的加法, x + y ≤ ? 2 w ? 1 x+y\le -2^{w-1} x+y≤?2w?1時會負溢位, x + y > 2 w ? 1 x+y> 2^{w-1} x+y>2w?1時會正溢位,對于乘法的溢位則更為普遍,在計算中我們應該先估算,謹防溢位,
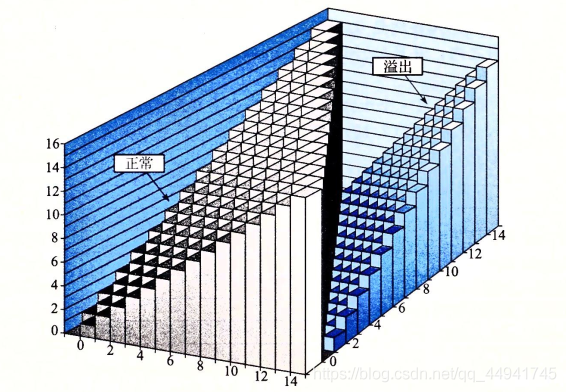
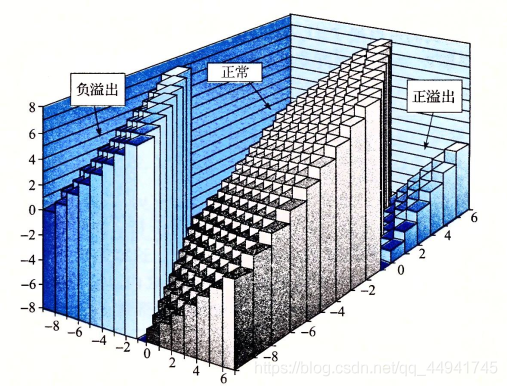
上面兩張圖來自CSAPP,表示無符號整型加法和補碼加法的溢位域,
另一方面,由于整數計算中乘法的耗時比較久,加法和移位運算比較快,于是我們希望能夠用加法和移位運算代替變數對常數的乘除法,
首先我們考慮 V = X × 2 k V=X\times 2^k V=X×2k,其實V就相當于X左移k位,于是我們可以計算X左移后的,在減去原來的若干倍,也就相當于X乘以某非2的冪的積,
而對于除法我們依據上述的辦法則只能處理除以 2 k 2^k 2k的情形,即對于無符號整型邏輯右移k位,溢位部分作為小數部分舍掉;對于有符號整型算術右移k位,
3 浮點數表示與計算
3.1 浮點型的編碼規則
IEEE制定了浮點型的編碼規則,使得浮點數能夠更加精確的表示實數,該標準使用 V = ( ? 1 ) s × M × 2 E V=(-1)^s\times M\times 2^E V=(?1)s×M×2E的形式來表示一個數,你可以理解為二進制的科學計數法的一種變體:
-
符號(sign): s s s決定了這個數是正數( s = 0 s=0 s=0)還是負數( s = 1 s=1 s=1)
-
階碼(exponet):E表示階數,這里E是一個有符號整型,但是并不采用補碼編碼,而是另外一種方式,這里 E = e x p ? B a i s E=exp-Bais E=exp?Bais 或者 E = 1 ? B i a s E=1-Bias E=1?Bias,具體哪一種由下一節介紹,其中 e x p = e k ? 1 e k ? 2 . . . e 1 e 0 exp=e_{k-1}e_{k-2}...e_1e_0 exp=ek?1?ek?2?...e1?e0?代表無符號數, B i a s Bias Bias表示偏置,是一個值為 2 k ? 1 ? 1 2^{k-1}-1 2k?1?1的數(在float中k=9,Bais等于127,double中k=11,Bais為1023),
-
尾數(significand):M是一個二進制小數,它的范圍是1~2- ? \epsilon ?或者0~1- ? \epsilon ?,具體是哪一種范圍由下一節介紹,M由原實數化為科學計數法的二進制的小數部分編碼(frac欄位)
下面用CSAPP中的圖直觀地表示浮點型的構成

浮點數的編碼由三部分構成,即s、exp和frac,它們分別編碼符號、階碼和尾數,
3.2 浮點數的分類表示
下面我們僅以float型別為例,介紹浮點數的分類表示,浮點數分為3種,其中第三種又分為兩種型別,
- 規格化的值:表示絕對值比較大的浮點數(絕大部分數,我們可以認為正常的數都在這個范圍),在這一部分,我們的 E = e x p ? B i a s E=exp-Bias E=exp?Bias,而尾數M的范圍1~2- ? \epsilon ?,而frac欄位則實際上是M的小數部分,即 M = 1 + f r a c M=1+frac M=1+frac,故 0 ≤ f r a c < 1 0\le frac<1 0≤frac<1
- 非規格化的值:表示趨于零的實數,在這一部分,我們的 E = 1 ? B i a s E=1-Bias E=1?Bias,而尾數的范圍是0~1- ? \epsilon ?,此時frac欄位依然表示M的小數部分,但是由于M的整數部分為0,故 M = f r a c M=frac M=frac
- 特殊值:這一類是指階碼全部為1的時候,可以分為兩類,無窮大和NAN(Not A Number),當階碼全部為1,小數部分(frac欄位)全部為0時,表示正無窮,我們可以感性地理解為浮點數表示不了這么大的數字,所以它是正無窮,當階碼全部為1,小數部分(frac欄位)不為0時,則表示NAN,我們可以感性地認為由于這個數的小數部分沒有確定,所以可以有很多取值的可能性,因此是Not A Number,
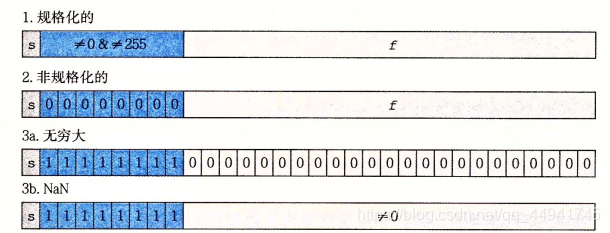
下面舉幾個栗子,首先我們看規格化的值:
設 V = 10.62 5 ( 10 ) V=10.625_{(10)} V=10.625(10)?,我們先將其化為而二進制,則 V = 1010.10 1 ( 2 ) V=1010.101_{(2)} V=1010.101(2)?,寫成IEEE標準則是 V = ( ? 1 ) 0 × 1.010101 × 2 3 V=(-1)^0\times 1.010101\times 2^3 V=(?1)0×1.010101×23,顯然 s = 0 , e x p = 3 ( 10 ) + B i a s ( f l o a t ) = 1000001 0 ( 2 ) , f r a c = 010101 s=0,exp=3_{(10)}+Bias_{(float)}=10000010_{(2)},frac=010101 s=0,exp=3(10)?+Bias(float)?=10000010(2)?,frac=010101,這里要注意,frac去掉了整數部分的1為了最大限度的表示小數,
再來一個規格化的值
設 U = 0.937 5 ( 10 ) U=0.9375_{(10)} U=0.9375(10)?,我們先將其轉化為二進制,則 U = 0.111 1 ( 2 ) U=0.1111_{(2)} U=0.1111(2)?,寫成IEEE標準則是 U = ( ? 1 ) 0 × 1.111 × 2 ? 1 U=(-1)^0\times 1.111\times 2^{-1} U=(?1)0×1.111×2?1,顯然 s = 0 , e x p = ? 1 ( 10 ) + B i a s ( f l o a t ) = 12 6 ( 10 ) = 111111 0 ( 2 ) , f r a c = 111 s=0,exp=-1_{(10)}+Bias_{(float)}=126_{(10)}=111 1110_{(2)},frac=111 s=0,exp=?1(10)?+Bias(float)?=126(10)?=1111110(2)?,frac=111,
如果值再小下去,我們會發現,由于float表示的極限,最小的規格化值應該是 e x p = 0 exp=0 exp=0,即E=126,在往下小那么float就無法表示這種小了,于是此時就需要采用非規格化的編碼,事實上這種編碼就是為了表示趨于零的實數的,
我們用一個表格簡單的描述一下浮點數
| 描述 | exp | frac | ||
|---|---|---|---|---|
| 0 | 00…00 | 0…00 | ||
| 最小的非規格化數 | 00…00 | 0…01 | ||
| 最大的非規格化數 | 00…00 | 1…11 | ||
| 最小規格化數 | 00…01 | 0…00 | ||
| 1 | 01…11 | 0…00 | ||
| 最大的非規格數 | 11…10 | 1…11 | ||
| 無窮 | 11…11 | 0…00 |
下面來自CSAPP的圖大致的表示了浮點數的分類(注:這個不是float也不是double,而是六位浮點數)
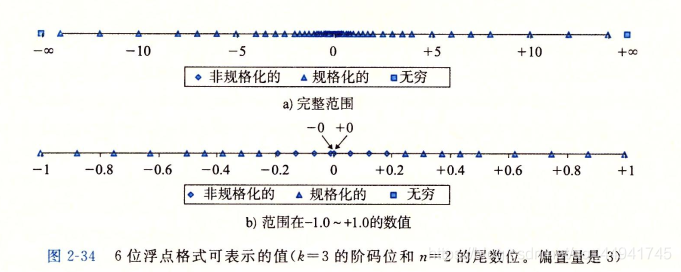
我們可以看到,浮點數能精確表示的數越靠近0分布越密集,
3.3 浮點數的舍入
我們假設 X , Y , k X,Y,k X,Y,k表示整型,則浮點型用來表示形如 V = ∑ X × 2 k V=\sum X\times 2^k V=∑X×2k的實數,而我們常用的基于10進制的有限小數都是形如 U = ∑ Y × 1 0 k U=\sum Y\times 10^k U=∑Y×10k的,所以計算機中的浮點數在很多情況下只是對現實世界資料的模擬,而無法做到恰好精確,顯然,形如 V = ∑ X × 2 k V=\sum X\times 2^k V=∑X×2k的數構成的集合的勢為 ? 0 \aleph_0 ?0?,故其測度為0,于是我們可以認為在實數范圍內幾乎所有的數都無法用浮點型來精確表示,于是一般的實數用浮點數來近似就顯得尤為重要,在計算機中,我們采用向偶數舍入法,在二進制中,我們定義如果最低位為0則該數位偶數,向偶數舍入法就是將該數舍入到最近的偶數,
3.4 浮點數的計算
浮點數的計算中一個很重要的點就是它只滿足交換律不滿足結合律,滿足交換律在數域中是必然的,結合律則是由于舍入誤差,在浮點數的加減運算中,是先將兩數加減,然后再做一次舍入,的到最后的結果,這樣很容易“大數吃小數”, 比如在float型別下3.14+(1e20-1e20)=3.14,而(3.14+1e20)-1e20=1e20-1e20=0.0,因此我們應該盡量避免這種情況,類似的情況還有大數除以小數等,都很容易使得浮點數溢位從而帶來較大的誤差,
另一方面,浮點型比整型的好處不僅在于它能表示更大范圍的數,也在于s單獨控制了它的正負性,它不會無緣無故從正數溢位為負數,而整型中則有可能,如果 a ≥ b , c > 0 a\ge b,c>0 a≥b,c>0則 a c ≥ b c ac\ge bc ac≥bc,這也更符合我們的代數學中的知識,
情況還有大數除以小數等,都很容易使得浮點數溢位從而帶來較大的誤差,
另一方面,浮點型比整型的好處不僅在于它能表示更大范圍的數,也在于s單獨控制了它的正負性,它不會無緣無故從正數溢位為負數,而整型中則有可能,如果 a ≥ b , c > 0 a\ge b,c>0 a≥b,c>0則 a c ≥ b c ac\ge bc ac≥bc,這也更符合我們的代數學中的知識,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/261729.html
標籤:其他
上一篇:哥德巴赫分解(藍橋)
下一篇:圖結構練習——最短路徑