文章目錄
- 上一章
- 一、Redis事務
- 示例1 正常執行:
- 示例2 放棄事務:
- 示例3 事務佇列中存在命令性錯誤則所有命令都不會執行
- 示例4 事務佇列中存在語法性錯誤則其他正確命令會被執行,錯誤命令拋出例外,
- 示例5 使用watch
- 示例6 使用watch被打斷
- 二、分布式鎖
- 2.1 INCR方法
- 2.2 SETNX方法
- 2.2.1 加鎖SETNX
- 2.2.2 獲取鎖SETNX
- 2.2.3 釋放鎖
- 2.3 SET 方法
- 2.4 注意分布式鎖中的問題
- 2.5 定時任務重復執行
- 2.6 避免用戶重復下單
- 三、分布式自增 ID
- 四、Redis 實作訊息佇列
- 五、Redis 實作延時佇列
- 下一章
上一章
深入學習Redis_(一)五種基本資料型別、RedisTemplate、RedisCache、快取雪崩等
深入學習Redis_(二)淘汰策略、持久化機制、主從復制、哨兵模式等
一、Redis事務
Redis 通過 MULTI、EXEC、WATCH 等命令來實作事務(transaction)功能,事務提供了一種將多個命令請求打包,然后 一次性、按順序地執行多個命令的機制,并且在事務執行期間,服務器不會中斷事務而改去執行其他客戶端的命令請求,它會將事務中的所有命令都執行完畢,然后才去處理其他客戶端的命令請求,
在傳統的關系式資料庫中,常常用 ACID 性質來檢驗事務功能的可靠性和安全性,原子性 (Atomicity)、一致性(Consistency)、隔離性(Isolation)和持久性(Durability),
Redis事務沒有隔離級別的概念,
Redis不保證原子性:
Redis中,單條命令是原子性執行的,但事務不保證原子性,且沒有回滾,事務中任意命令執行失敗,其余的命令仍會被執行,
watch key1 key2 ...: 監視一或多個key,如果在事務執行之前,被監視的key被其他命令改動,則事務被打斷 ( 類似樂觀鎖 )multi: 標記一個事務塊的開始( queued )exec: 執行所有事務塊的命令 ( 一旦執行exec后,之前加的監控鎖都會被取消掉 )discard: 取消事務,放棄事務塊中的所有命令unwatch: 取消watch對所有key的監控
示例1 正常執行:
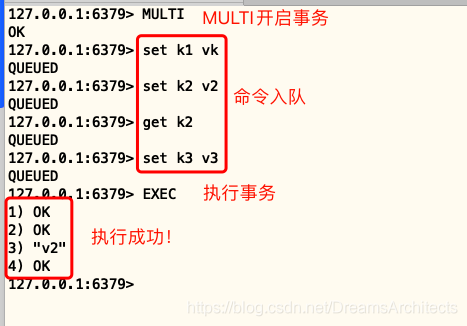
示例2 放棄事務:

示例3 事務佇列中存在命令性錯誤則所有命令都不會執行
如果在事務佇列中存在命令性錯誤則執行EXEC命令時,所有命令都不會執行

示例4 事務佇列中存在語法性錯誤則其他正確命令會被執行,錯誤命令拋出例外,
如果事務佇列中存在語法性錯誤,則執行EXEC命令時,其他正確命令會被執行,錯誤命令拋出例外,

示例5 使用watch

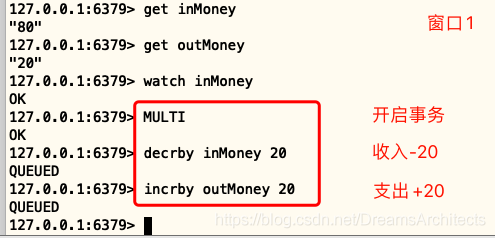
示例6 使用watch被打斷
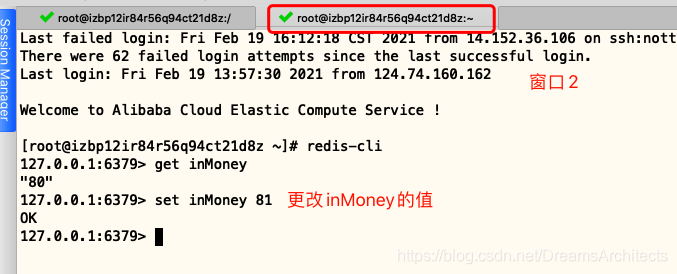
使用watch檢測inMoney,在開啟事務后,在新視窗執行更改inMoney值的操作,,模擬其他客戶端在事務執行期間更改watch監控的資料,然后再執行EXEC后,事務未成功執行,
步驟一:
步驟二:
步驟三:

二、分布式鎖
2.1 INCR方法
這種是比較簡單的加鎖方式:
key 不存在,那么 key 的值會先被初始化為 0 ,然后再執行 INCR 操作進行加一, 然后其它用戶在執行 INCR 操作進行加一時,如果回傳的數大于 1 ,說明這個鎖正在被使用當中,
INCR key方法:
將鍵存盤的數字增加1,如果該鍵不存在,則在執行操作前將其設定為0,
回傳值
整數回復:自增后的key值
EXPIRE key seconds方法:
設定鍵的超時時間,超時后,將被自動洗掉,
1、 客戶端A請求服務器獲取key的值為1表示獲取了鎖
2、 客戶端B也去請求服務器獲取key的值為2表示獲取鎖失敗
3、 客戶端A執行代碼完成,洗掉鎖
4、 客戶端B在等待一段時間后在去請求的時候獲取key的值為1表示獲取鎖成功
5、 客戶端B執行代碼完成,洗掉鎖
$redis->incr($key);
$redis->expire($key, $ttl); //設定生成時間為1秒

2.2 SETNX方法
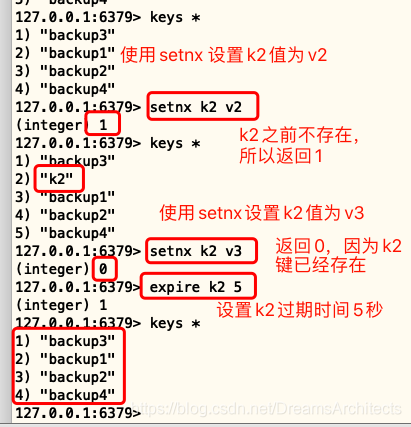
SETNX是“SET if Not eXists”的縮寫,
SETNX key val 方法:
Set key to hold string value if key does not exist. In that case, it is equal to SET. When key already holds a value, no operation is performed. SETNX is short for “SET if Not eXists”.
Return value
Integer reply, specifically:
1 if the key was set
0 if the key was not set
如果key不存在,則將key設定為指定值,在這種情況下,它等于SET,當key已經保存一個值時,不執行任何操作,
如果回傳1說明set成功,即原來是沒有這個key的;回傳0說明set失敗,key是存在的,
示例:
redis> SETNX mykey "Hello"
(integer) 1
redis> SETNX mykey "World"
(integer) 0
redis> GET mykey
"Hello"
redis>
2.2.1 加鎖SETNX
獲取鎖的時候,使用 setnx加鎖,鎖的 value 值為一個隨機生成的 UUID,在釋放鎖的時候進行判斷,并使用 expire 命令為鎖添加一個超時時間,超過該時間則自動釋放鎖,
2.2.2 獲取鎖SETNX
獲取鎖的時候呼叫 setnx,如果回傳 0,則該鎖正在被別人使用,回傳 1 則成功獲取鎖, 還設定一個獲取的超時時間,若超過這個時間則放棄獲取鎖,
2.2.3 釋放鎖
釋放鎖的時候,通過 UUID 判斷是不是該鎖,若是該鎖,則執行 DEL 進行鎖釋放,
2.3 SET 方法
上面兩種方法都有一個問題,會發現,都需要設定 key 過期,那么為什么要設定key過期呢?如果請求執行因為某些原因意外退出了,導致創建了鎖但是沒有洗掉鎖,那么這個鎖將一直存在,以至于以后快取再也得不到更新,于是乎我們需要給鎖加一個過期時間以防以外,
但是借助 Expire 來設定就不是原子性操作了,所以還可以通過事務來確保原子性,但是還是有些問題,所以官方就參考了另外一個,使用 SET 命令本身已經從版本 2.6.12 開始包含了設定過期時間的功能,
SET key value [EX seconds|PX milliseconds|KEEPTTL] [NX|XX] [GET] 方法:
設定key以保存字串值,如果key已經保存了一個值,那么不管它的型別是什么,它都會被覆寫,如果SET操作成功,與該鍵關聯的任何以前的生存時間都將被丟棄,
其他引數:
EX seconds——設定指定的過期時間,以秒為單位,
PX milliseconds——設定指定的過期時間,以毫秒為單位,
NX——只在鍵不存在時設定它,
XX——只設定已經存在的鍵,
KEEPTTL——保留與該鍵相關聯的生存時間,
GET——回傳存盤在key處的舊值,如果key不存在則回傳nil,
>= 2.6.12: Added the EX, PX, NX and XX options.
>= 6.0: Added the KEEPTTL option.
>= 6.2: Added the GET option.
使用命令SET resource-name anystring NX EX max-lock-time是Redis實作鎖定系統的一個簡單方法,
如果上面的命令回傳OK(或者如果命令回傳Nil,則在一段時間后重試),客戶端就可以獲得鎖,并使用DEL洗掉鎖,
到達過期時間后,鎖將自動釋放,
使用只在值匹配時洗掉鍵的Lua腳本:
if redis.call("get",KEYS[1]) == ARGV[1]
then
return redis.call("del",KEYS[1])
else
return 0
end
2.4 注意分布式鎖中的問題
場景:
設定鎖過期時間為 N 秒,A 執行緒拿到鎖,業務執行時間超過 N 秒時,鎖過期被釋放,B 執行緒拿到鎖,A 執行緒執行完畢釋放掉鎖,C 執行緒又拿到鎖
這里有兩個問題,一是加鎖與釋放鎖混亂,二是未執行完畢邏輯鎖被過期釋放
解決方法:
第一個問題:
解鈴還須系鈴人,解決加鎖與釋放混亂,可以采用將 value 設定為亂數(UUID)的方式,A 執行緒設定的鎖,只能由 A 執行緒釋放,釋放鎖時先判斷 value 是否一致,
第二個問題:
我們加鎖的程序是 加鎖—執行業務代碼—釋放鎖,如果加入業務代碼的執行時間超時了,是不是業務代碼還沒有執行完,鎖就已經釋放了,放在購票場景中,第一位旅客還沒有完成購票,第二位旅客就開始購票,顯然不合理,
可以在業務代碼中開辟一個“續命”的操作:
這里我們需要估計業務代碼的執行時間,加入預估出來的時間是10秒
加鎖 set key value ex 10 nx
每過3秒,把該鎖的時間重新設定為 10秒
執行業務代碼
釋放鎖 del lock
這里的續命時間間隔 = 過期時間 10S / 3
分布式鎖可以避免不同行程重復相同的作業,減少資源浪費, 同時分布式鎖可以避免破壞資料正確性的發生, 例如多個行程對同一個訂單操作,可能導致訂單狀態錯誤覆寫,應用場景如下,
2.5 定時任務重復執行
如果我們需要一個定時任務來進行訂單狀
態的統計,比如每 15 分鐘統計一下所有未支付的訂單數量,那么我們啟動定時任務的時候,肯定不能同一時刻多個業務后臺服務都去執行定時任務, 這樣就會帶來重復計算以及業務邏輯混亂的問題,
這時候,就需要使用分布式鎖,進行資源的鎖定,那么在執行定時任務的函式中,首先進行分布式鎖的獲取,如果可以獲取的到,那么這臺機器就執行正常的業務資料統計邏輯計算,如果獲取不到則證明目前已有其他的服務行程執行這個定時任務,就不用自己操作執行了,只需要回傳就行了,
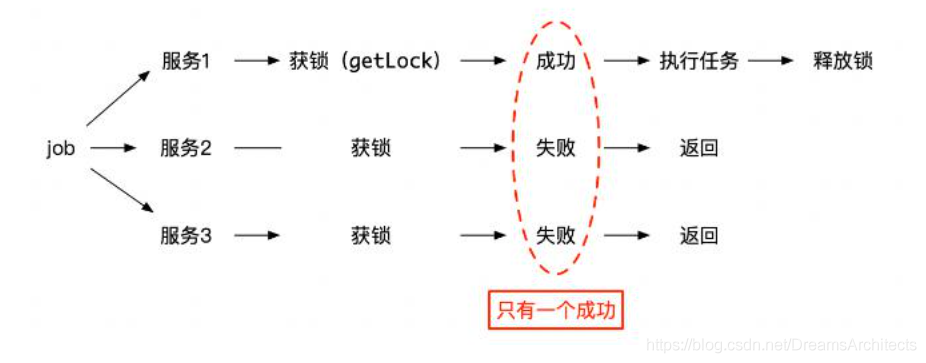
2.6 避免用戶重復下單
分布式實作方式有很多種:
- 資料庫樂觀鎖方式
- 基于 Redis 的分布式鎖
- 基于 ZK 的分布式鎖
分布式鎖實作要保證幾個基本點,
4. 互斥性:任意時刻,只有一個資源能夠獲取到鎖,
5. 容災性:能夠在未成功釋放鎖的的情況下,一定時限內能夠恢復鎖的正常功能,
6. 統一性:加鎖和解鎖保證同一資源來進行操作,
三、分布式自增 ID
通常對于分布式自增 ID 的實作方式有下面幾種:
- 利用資料庫自增 ID 的屬性
- 通過 UUID 來實作唯一 ID 生成
- Twitter 的 SnowFlake 演算法(雪花演算法)
- 利用 Redis 生成唯一 ID
使用 Redis 的 INCR 命令來實作唯一ID,Redis 是單行程單執行緒架構,不會因為多個取號方的 INCR 命令導致取號重復,因此,基于 Redis
的 INCR 命令實作序列號的生成基本能滿足全域唯一與單調遞增的特性,
四、Redis 實作訊息佇列
使用 list 型別保存資料資訊,rpush 生產訊息,lpop 消費訊息,當 lpop 沒有訊息時,可 以 sleep 一段時間,然后再檢查有沒有資訊,如果不想 sleep 的話,可以使用 blpop, 在沒 有資訊的時候,會一直阻塞,直到資訊的到來,redis 可以通過 pub/sub 主題訂閱模式實作 一個生產者,多個消費者,當然也存在一定的缺點,當消費者下線時,生產的訊息會丟失,
RPUSH key element [element …] 方法:
在存盤在key的串列尾部插入所有指定的值,如果key不存在,則在執行推操作之前將其創建為空串列,當key保存的值不是串列時,回傳一個錯誤,
使用時,在命令的末尾指定多個引數,就可以推入多個元素,元素一個接一個地插入到串列的尾部,從最左邊的元素到最右邊的元素,例如,命令RPUSH mylist a b c將生成一個包含a作為第一個元素、b作為第二個元素、c作為第三個元素的串列,
LPOP key [count] 方法:
洗掉并回傳存盤在key中的串列的第一個元素,
默認情況下,該命令從串列的開頭彈出單個元素,當提供了可選的count引數時,將回傳多個的元素,這取決于串列的長度,
五、Redis 實作延時佇列
使用 SortedSet(ZSet),使用時間戳做 score, 訊息內容作為 key,呼叫 zadd 來生產訊息,消費者 使用 zrangbyscore 獲取 n 秒之前的資料做輪詢處理,
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]方法的解釋:
Returns all the elements in the sorted set at key with a score between min and max (including elements with score equal to min or max). The elements are considered to be ordered from low to high scores.
The elements having the same score are returned in lexicographical order (this follows from a property of the sorted set implementation in Redis and does not involve further computation).
As per Redis 6.2.0, this command is considered deprecated. Please prefer using the ZRANGE command with the BYSCORE argument in new code.
The optional LIMIT argument can be used to only get a range of the matching elements (similar to SELECT LIMIT offset, count in SQL). A negative count returns all elements from the offset. Keep in mind that if offset is large, the sorted set needs to be traversed for offset elements before getting to the elements to return, which can add up to O(N) time complexity.
The optional WITHSCORES argument makes the command return both the element and its score, instead of the element alone. This option is available since Redis 2.0.
回傳key中分數在min和max之間的排序集合中的所有元素(包括分數等于min或max的元素),元素被認為是從低到高的分數排序,
具有相同分數的元素按字典順序回傳(這遵循Redis中排序集實作的一個屬性,不涉及進一步的計算),
根據Redis 6.2.0,這個命令被認為已棄用,請在新代碼中使用帶BYSCORE引數的ZRANGE命令,
可選的LIMIT引數只能用于獲取一個范圍內的匹配元素(類似于SQL中的SELECT LIMIT offset, count),負數的計數將從偏移量中回傳所有元素,請記住,如果偏移量很大,在獲得要回傳的元素之前,需要遍歷排序集的偏移量元素,這可能會增加O(N)的時間復雜度,
可選的WITHSCORES引數使該命令同時回傳元素及其分數,而不僅僅是元素本身,這個選項從Redis 2.0開始就可用了,
簡單來說就是:使用ZSet型別,在存入的時候分數使用當時的時間戳,查詢的時候以現在的時間戳減去延時的時間(比如五分鐘)的時間戳為分數輪詢即可,
下一章
深入學習Redis_(四)Redis與Lua腳本
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/261870.html
標籤:其他
上一篇:初探Vite