在做text2image GAN時候做文獻閱讀時看到的SAGAN,這里做一個簡要得學習筆記,歡迎糾錯討論,
Self-Attention Generative Adversarial Networks (SAGAN)
SAGAN在ImageNet可到達36.8的Inception Score 和 18.65的Frechet Inception Distance,也是BIG-GAN的原型,
傳統卷積GAN問題:
受區域感受野限制(Local Receptive Field),無法提取全域資訊,只能提取local neighborhood(比如狗的毛色不匹配,人臉位置不協調這些全域結構強的任務中),
- 模型太小無法描述
- 優化演算法很難發現引數
SA-GAN采用 self-attention(全域特征) 機制和傳統 convolution(區域特征)結合,能對長范圍多層次的影像區域建模,提供一種利用全域資訊方法,
使每個位置的精細細節與遠處進行協調,也能解決復雜的幾何約束,
使用Spectral Normalization 在Generator上,
Self-Attention
附上原論文self-attention module圖,?是矩陣乘法,每一行都進行softmax,
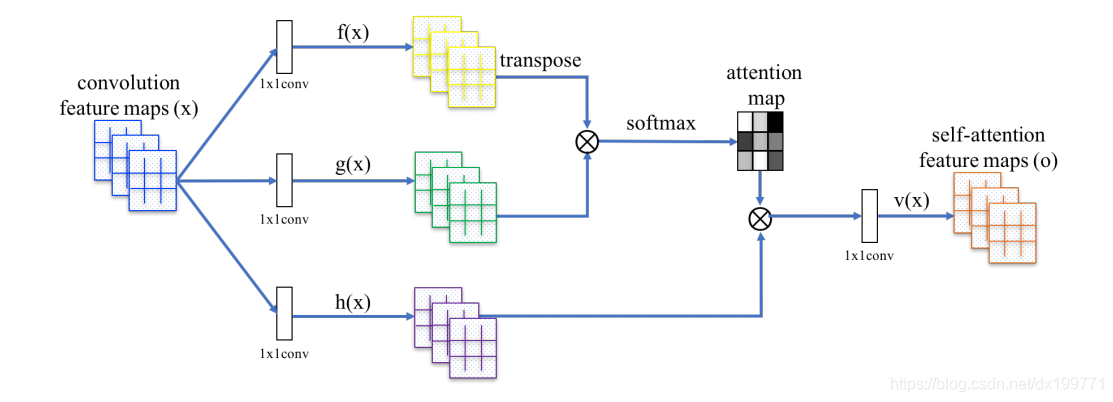
結合這張圖簡單看一下程序:
從上一層卷積層輸入進來的x首先進入兩個特征空間 f(x) 和 g(x) 去計算attention
這里,
然后計算,
是合成第j個區域時,模型位于第i個位置的程度(有點繞),就是圖里的softmax之后生成的attention map
公式是:
最后生成attention layer:o(v(x)那里)
公式是:
最后在通過一個, γ是學習引數,初始為0,意義是首先從local特征開始逐漸分配更多權重給non-local特征,(progressively)
Attention機制運用在generator和discriminator上,使用hinge adversarial loss function,
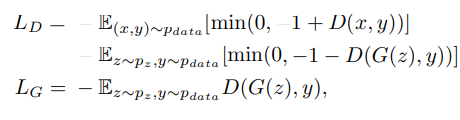
穩定GAN的方法
- 使用了Spectral Normalization在generator和discriminator上
Spectral Normalization接下來文章會做筆記
- Generator和Discriminator有不同的學習速率lr(TTUR)
想讀原文和具體引數實驗資料的小伙伴點這里:https://arxiv.org/abs/1805.08318
感謝閱讀歡迎糾錯探討!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/262034.html
標籤:其他
上一篇:洛谷P1138 第k小整數
下一篇:再難回我少年時代