Merging Pose Estimates Across Space and Time論文決議
- 簡介
- 1 引言
- 1.1相關作業
- 2 提出方法
- 2.1單幀
- 2.2多幀
- 2.2變數K
- 3.結果
- 3.1 Buffy stickmen資料集
- 3.1.1 Original Buffy 資料集沒有時間資訊
- 3.1.2 Video Buffy資料集
- 3.2 Faces
- 3.3 Mice
- 4.總結
簡介
Merging Pose Estimates Across Space and Time字面意思:在空間和時間上合并姿態估計,文章的主要貢獻是提出了Pose-NMS框架,基本思想是通過聚類得到最終姿態,下面將按照論文的順序進行詳細介紹,(注:本文只供學習討論,不做商業用途,建議大家去官網下載原文閱讀,本文觀點只是個人學習中的感悟,如果您有更好的想法或者發現錯誤請私信我交流,或在評論區分享您的觀點)

合并目標檢測框采用多種NMS作為目標檢測的后處理方案,我們提出了一種NMS的泛化方法,可以在單幀中合并多個姿態估計,在 standard NMS中最后的估計不是medoids而是centroids,因此比任何單獨的候選區都精確,采用相同的數學框架,我們將我們的方法擴展到多幀設定,合并跨空間和時間的多個獨立姿勢估計,并輸出場景中物件的數量和姿勢,我們的方法避開了與完全跟蹤相關的許多固有挑戰(例如,物體進入/離開場景、長時間遮擋等),為了證明方法的通用性,我們將其應用于人體、人臉和小鼠三個領域的兩種最新姿態估計演算法,我們的方法提高了檢測精度(通過消除相似)和姿態估計質量,并且計算效率高
- 思想來源:目標檢測中的 NMS ;
- 創新: standard NMS ,最后估計出的是centroids,精確度提高,可以跨空間和時間合并,輸出場景中物件的數量和姿勢;
- 不足:避開了許多固有挑戰物體進入/離開場景、長時間遮擋 等;
- 優點:通用性強,檢測更精確,提高了姿態估計質量,計算效率高 功能;
1 引言

精確的視頻姿態估計是動作識別【6,23】、運動捕捉【20】、與人機互動【21】等應用的關鍵,這里的姿勢是指模型的引數,它描述了影像中物體的結構,或影像中物體的坐標位置,
資料驅動的姿態估計方法越來越成熟,在許多識別任務中取得了令人驚嘆的效果【7, 13, 25, 26】,這些方法輸出一組姿勢估計,通過“非極大值抑制”(NMS)技術來合并相似目標檢測,NMS是可以有效合并目標檢測產生的多余邊界框【9,11】,然而,目前還不能將其應用到姿態估計,如【25,26】中所述,只是將標準NMS單獨應用于每個關節位置,效果并不理想,
大意:NMS不能直接用于姿估計


第一個貢獻:提出在單幀中合并多姿態估計的框架,是目標檢測NMS的衍生物,該框架適用于大部分姿態估計方法而且可以提高精度,比較通用,通過魯棒平均來實作,解決多目標姿態估計之間的對應問題,
第二個貢獻:用相同的數學框架把我們的方法應用到多幀連續檢測,進一步提高姿態估計,該方法受到了“‘tracking by detection”方法的啟發,但回避了許多固有挑戰(例如,物體進入或離開場景,長時間的遮擋等),我們的方法可以跨空間和時間合并多姿態估計,輸出場景中物件的數量和姿態,參見圖1,
大意:本文兩個貢獻,第一:單幀合并姿態的框架,第二:多幀合并姿態
 利用統一的優化框架,我們得到了一個高效的方法,可以有效估計短視頻(每幀具有相同物件且連續)的姿態,Pose-NMS不依賴選取的姿態估計方法,任何逐幀的姿態估計方法都可以使用Pose-NMS,
利用統一的優化框架,我們得到了一個高效的方法,可以有效估計短視頻(每幀具有相同物件且連續)的姿態,Pose-NMS不依賴選取的姿態估計方法,任何逐幀的姿態估計方法都可以使用Pose-NMS,
我們將姿勢NMS應用于兩種不同的最新姿勢估計方法來展示姿勢NMS的普適性:DPM[25]和CPR[7,13],我們從包含三種不同物件型別的場景中收集了1000多個視頻短片,用三個任務檢測我們的方法,三個任務:人體姿態估計,人臉定位估計和動物姿態估計,與標準技術相比,Pose-NMS在三種情況下都提高了檢測精度和姿態估計質量,我們的方法代碼可以在線上獲得,
大意:將Pose-NMS應用于DPM和CPR姿態檢測,利用人體姿態估計,人臉定位估計和動物姿態估計驗證Pose-NMS的效果,簡單說就是想讓你知道Pose-NMS為啥牛逼,
1.1相關作業
 之前的視頻估計可以劃分為兩大類:(1) 將跟蹤和姿態估計直接耦合在一起, (2)先逐幀估計姿態和隨后在幀之間執行時間平滑,
之前的視頻估計可以劃分為兩大類:(1) 將跟蹤和姿態估計直接耦合在一起, (2)先逐幀估計姿態和隨后在幀之間執行時間平滑,

第一類方法,主要用于無標記人體運動捕捉和多個攝像機的三維姿態估計[20],例入參考文獻[22]通過a factored-state Hierarchical HMM同時執行跟蹤和姿勢估計,或[18]通過Viterbi-style maximum likelihood方法結合運動模型和觀察物件,來集成單幀姿勢恢復和時間積分的方法,這些方法不易推廣到其他姿態估計任務,
第二類方法,使用于單目視頻的標準二維姿態估計,通過加強幀間的時間連續性,將單幀影像檢測方法擴展到視頻,通過單幀檢測計算出在一段時間內連續的物體軌跡[1,2,3,5,8],檢測跟蹤是一種非常有效的跟蹤方法,但無法擴展到姿態引數化,
大意:兩類方法都有缺陷
2 提出方法
 現在詳細描述我們的方法,給定一個包含T幀的視頻,將姿態檢測應用于從第一幀到第T幀的每一幀,并回傳姿態估計
X
t
=
{
x
1
t
,
.
.
.
,
x
n
t
t
∣
x
i
t
∈
R
D
}
\Chi^t=\{x_1^t,...,x_{n^t}^t|x_i^t \in\R^D\}
Xt={x1t?,...,xntt?∣xit?∈RD}和相應的置信度
S
t
=
{
s
1
t
,
.
.
.
,
s
n
t
t
∣
s
i
t
∈
R
D
}
S^t=\{s_1^t,...,s_{n^t}^t|s_i^t \in\R^D\}
St={s1t?,...,sntt?∣sit?∈RD},
n
t
n^t
nt是在第t幀估計出的目標數,
x
i
t
x_i^t
xit?用D維引數化,D維度因任務而異,可能包括角度值,我們的目標是計算出每一幀中原始姿態的軌跡
Y
t
=
{
y
1
t
,
.
.
.
,
y
K
t
∣
y
k
t
∈
R
D
}
Y^t=\{y_1^t,...,y_K^t|y_k^t \in\R^D\}
Yt={y1t?,...,yKt?∣ykt?∈RD},并且進行時間平滑,K是需要估計的物件數,
現在詳細描述我們的方法,給定一個包含T幀的視頻,將姿態檢測應用于從第一幀到第T幀的每一幀,并回傳姿態估計
X
t
=
{
x
1
t
,
.
.
.
,
x
n
t
t
∣
x
i
t
∈
R
D
}
\Chi^t=\{x_1^t,...,x_{n^t}^t|x_i^t \in\R^D\}
Xt={x1t?,...,xntt?∣xit?∈RD}和相應的置信度
S
t
=
{
s
1
t
,
.
.
.
,
s
n
t
t
∣
s
i
t
∈
R
D
}
S^t=\{s_1^t,...,s_{n^t}^t|s_i^t \in\R^D\}
St={s1t?,...,sntt?∣sit?∈RD},
n
t
n^t
nt是在第t幀估計出的目標數,
x
i
t
x_i^t
xit?用D維引數化,D維度因任務而異,可能包括角度值,我們的目標是計算出每一幀中原始姿態的軌跡
Y
t
=
{
y
1
t
,
.
.
.
,
y
K
t
∣
y
k
t
∈
R
D
}
Y^t=\{y_1^t,...,y_K^t|y_k^t \in\R^D\}
Yt={y1t?,...,yKt?∣ykt?∈RD},并且進行時間平滑,K是需要估計的物件數,
大意:介紹各個引數的含義 X t \Chi^t Xt就是t幀畫面中經過目標檢測出的邊界框,同一個目標會有許多邊界框, n t n^t nt是邊界框的總數, S t S^t St是每個邊界框的置信度,置信度越高的框越準確, Y t Y^t Yt是畫面中每個物件的最后姿態,
2.1單幀
 我們開始討論如何合并t幀內的多個姿態,假設目標總數K是已知的,該方法的核心是將問題看作原始姿態的魯棒聚類,對每個物體的姿態進行更精確的估計,
我們開始討論如何合并t幀內的多個姿態,假設目標總數K是已知的,該方法的核心是將問題看作原始姿態的魯棒聚類,對每個物體的姿態進行更精確的估計,
設d(x,y)=||x-y||
2
2
_2^2
22?為歐氏距離的平方,在t幀中給定
X
t
\Chi^t
Xt和
S
t
S^t
St,定義
Y
t
Y^t
Yt的損失函式為:
L
s
p
a
c
e
(
Y
t
)
=
1
S
t
∑
i
=
1
n
t
min
?
k
d
(
x
i
t
,
y
k
t
)
s
i
t
L_{space}(Y^t)=\frac{1}{S^t}\displaystyle\sum_{i=1}^{n^t}\min\limits_kd(x_i^t,y_k^t)s_i^t
Lspace?(Yt)=St1?i=1∑nt?kmin?d(xit?,ykt?)sit?,
w
h
e
r
e
S
t
=
∑
i
=
1
n
t
s
i
t
\quad where S^t=\displaystyle\sum_{i=1}^{n^t}s_i^t
whereSt=i=1∑nt?sit?
大意:提出損失函式
L
s
p
a
c
e
L_{space}
Lspace?
 L
s
p
a
c
e
L_{space}
Lspace?使
y
k
t
接
近
x
i
t
y_k^t接近x_i^t
ykt?接近xit?,損失函式
L
s
p
a
c
e
L_{space}
Lspace?的缺點是:
y
k
t
y_k^t
ykt?可以體現相距較遠的姿態
x
i
t
x_i^t
xit?(換句話說,相距較遠的
x
i
t
x_i^t
xit?會影響
y
k
t
y_k^t
ykt?),
y
k
t
y_k^t
ykt?應該體現與目標相近的大部分檢測結果,而不是相距較遠的某幾個姿態,通過定義有界距離度量我們將損失函式優化為
d
b
d
(
x
,
y
)
=
m
i
n
(
z
,
∣
∣
x
?
y
∣
∣
2
2
)
d_{bd}(x,y)=min(z,||x-y||_2^2)
dbd?(x,y)=min(z,∣∣x?y∣∣22?),
d
b
d
d_{bd}
dbd?是平方歐氏距離的變形,不同點是它有最大值z,最后損失函式為:
L
s
p
a
c
e
L_{space}
Lspace?使
y
k
t
接
近
x
i
t
y_k^t接近x_i^t
ykt?接近xit?,損失函式
L
s
p
a
c
e
L_{space}
Lspace?的缺點是:
y
k
t
y_k^t
ykt?可以體現相距較遠的姿態
x
i
t
x_i^t
xit?(換句話說,相距較遠的
x
i
t
x_i^t
xit?會影響
y
k
t
y_k^t
ykt?),
y
k
t
y_k^t
ykt?應該體現與目標相近的大部分檢測結果,而不是相距較遠的某幾個姿態,通過定義有界距離度量我們將損失函式優化為
d
b
d
(
x
,
y
)
=
m
i
n
(
z
,
∣
∣
x
?
y
∣
∣
2
2
)
d_{bd}(x,y)=min(z,||x-y||_2^2)
dbd?(x,y)=min(z,∣∣x?y∣∣22?),
d
b
d
d_{bd}
dbd?是平方歐氏距離的變形,不同點是它有最大值z,最后損失函式為:
L
s
p
a
c
e
(
Y
t
)
=
1
S
t
∑
i
=
1
n
t
min
?
k
d
b
d
(
x
i
t
,
y
k
t
)
s
i
t
L_{space}(Y^t)=\frac{1}{S^t}\displaystyle\sum_{i=1}^{n^t}\min\limits_kd_{bd}(x_i^t,y_k^t)s_i^t
Lspace?(Yt)=St1?i=1∑nt?kmin?dbd?(xit?,ykt?)sit?
這個函式跟上面的很像,唯一的不同在于是
d
d
b
d_{db}
ddb?不是d,現在,一旦
x
i
t
x_i^t
xit?離
y
t
y^t
yt特別遠,它只會得到最大懲罰z而不會影響
y
k
t
y_k^t
ykt?,常數z取決于實際應用,實際上我們總是將z設為以像素為單位的物件平均寬度,
大意:歐式距離的平方d的缺點是會考慮一些細枝末節的東西,就像是修剪樹枝,只需要留下來主干,剪掉細枝末節不影響樹的形狀,但是留下它們會影響模型樹干的泛化能力,也就是來年春天的樹還是只能和今年一摸一樣,限制了樹的發展,所以為了更好的提取樹干姿態,提出了
d
d
b
d_{db}
ddb?,它把樹干的范圍限制在z內,不考慮超出z的細枝末節,

我們現在直觀的感受一下
L
s
p
a
c
e
L_{space}
Lspace?的優化程序,我們首先看式(1)中損失,這是當k=K并且
Y
t
Y^t
Yt為中心時(加權)k-均值聚類的損失,如果K已知,可以用加權k-均值為第t幀提供合理的解決方案,但是如果用
d
d
b
d_{db}
ddb?代替d,k-均值就不再適用了,
我們為式(2)定義了一個k-均值的簡單變形——有界k-均值,為了下面的討論,我們去掉了上標,在k-means演算法的每個階段,首先確定類的成員關系,然后將每個類中心設定為該類的點的平均值,在標準k-均值中,如果
d
(
x
i
,
y
k
)
<
d
(
x
i
,
y
j
)
,
?
j
=?
k
d(x_i,y_k)<d(x_i,y_j),\forall j\not =k
d(xi?,yk?)<d(xi?,yj?),?j?=k,則點
x
i
x_i
xi?屬于k類,在有界k-均值中,我們用相似的方法,如果
d
(
x
i
,
y
k
)
<
d
(
x
i
,
y
j
)
,
?
j
=?
k
d(x_i,y_k)<d(x_i,y_j),\forall j\not =k
d(xi?,yk?)<d(xi?,yj?),?j?=k and
d
(
x
i
,
y
k
)
d(x_i,y_k)
d(xi?,yk?),則點
x
i
x_i
xi?屬于k類,
大意:提出了有界k-均值,目的是為了優化損失,我的直觀理解是,它的核心思想就是x離某個聚類y近,就把它歸給該聚類y,
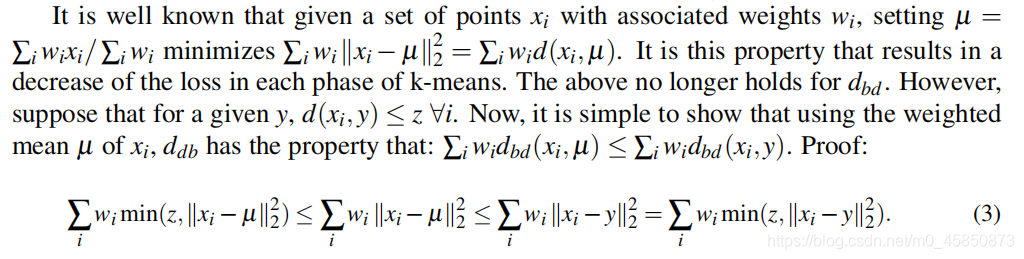
已知一組權重為
w
i
w_i
wi?的點
x
i
x_i
xi?,當
μ
=
∑
i
w
i
x
i
/
∑
i
w
i
μ=\sum_iw_ix_i/\sum_iw_i
μ=∑i?wi?xi?/∑i?wi?時
∑
i
w
i
∣
∣
x
i
?
μ
∣
∣
2
2
=
∑
i
w
i
d
(
x
i
,
μ
)
\sum_iw_i||x_i-μ||_2^2=\sum_iw_id(x_i,μ)
∑i?wi?∣∣xi??μ∣∣22?=∑i?wi?d(xi?,μ)取的最小值,減少了k-均值每個階段的損失,但
d
d
b
d_{db}
ddb?不能用這種方法優化,假設y,且
d
(
x
i
,
y
)
?
z
,
?
i
d(x_i,y)\leqslant z,\forall i
d(xi?,y)?z,?i,μ是
x
i
x_i
xi?的加權平均值,對于
d
b
d
d_{bd}
dbd?有:
∑
i
w
i
d
d
b
(
x
i
,
μ
)
?
∑
i
w
i
d
d
b
(
x
i
,
y
)
\sum_iw_id_{db}(x_i,μ)\leqslant\sum_iw_id_{db}(x_i,y)
∑i?wi?ddb?(xi?,μ)?∑i?wi?ddb?(xi?,y),證明:
∑
i
w
i
m
i
n
(
z
,
∣
∣
x
i
?
μ
∣
∣
2
2
)
?
∑
i
w
i
∣
∣
x
i
?
μ
∣
∣
2
2
?
∑
i
w
i
∣
∣
x
i
?
y
∣
∣
2
2
=
∑
i
w
i
m
i
n
(
z
,
∣
∣
x
i
?
y
∣
∣
2
2
)
\sum_iw_imin(z,||x_i-μ||_2^2)\leqslant\sum_iw_i||x_i-μ||_2^2\leqslant\sum_iw_i||x_i-y||_2^2=\sum_iw_imin(z,||x_i-y||_2^2)
∑i?wi?min(z,∣∣xi??μ∣∣22?)?∑i?wi?∣∣xi??μ∣∣22??∑i?wi?∣∣xi??y∣∣22?=∑i?wi?min(z,∣∣xi??y∣∣22?)
注意:
∑
i
w
i
∣
∣
x
i
?
y
∣
∣
2
2
=
∑
i
w
i
m
i
n
(
z
,
∣
∣
x
i
?
y
∣
∣
2
2
)
\sum_iw_i||x_i-y||_2^2=\sum_iw_imin(z,||x_i-y||_2^2)
∑i?wi?∣∣xi??y∣∣22?=∑i?wi?min(z,∣∣xi??y∣∣22?)是相等的,因為y的取值限定在
d
(
x
i
,
y
)
?
z
d(x_i,y)\leqslant z
d(xi?,y)?z
大意:歐式距離平方d有最優解,很容易就可以求解,但是它的變形 d d b d_{db} ddb?不能按照這種方法求最優解,只能一步步優化,逐漸逼近最優解,可能會取到最優,但大部分情況都不能取到最優,這種情況可以選擇不同的初始值,多次嘗試逼近最優,
 也就是將y換成在z距離內
x
i
x_i
xi?的加權平均值μ,用這樣的替換減小每個階段的損失(或保持其恒定),但是μ不是
∑
i
w
i
d
d
b
(
x
i
,
μ
)
\sum_iw_id_{db}(x_i,μ)
∑i?wi?ddb?(xi?,μ)的最小值;只是優于
d
(
x
i
,
y
)
?
z
,
?
i
d(x_i,y)\leqslant z,\forall i
d(xi?,y)?z,?i的任何y,因此,雖然有界k-均值在一步步減少損失,但不能保證是最優的(在標準k-均值演算法中,雖然交替優化程序不是最優的,但每一步都是最優的),不同的初始化可以改善這個問題,
也就是將y換成在z距離內
x
i
x_i
xi?的加權平均值μ,用這樣的替換減小每個階段的損失(或保持其恒定),但是μ不是
∑
i
w
i
d
d
b
(
x
i
,
μ
)
\sum_iw_id_{db}(x_i,μ)
∑i?wi?ddb?(xi?,μ)的最小值;只是優于
d
(
x
i
,
y
)
?
z
,
?
i
d(x_i,y)\leqslant z,\forall i
d(xi?,y)?z,?i的任何y,因此,雖然有界k-均值在一步步減少損失,但不能保證是最優的(在標準k-均值演算法中,雖然交替優化程序不是最優的,但每一步都是最優的),不同的初始化可以改善這個問題,
如果姿態包含角度,則距離函式和優化程序需要修改,有關詳細資訊,請參閱補充資料,
大意:使用不同初始化,爭取逼近到最優解,以上的優化沒有考慮角度資訊,
2.2多幀
 在視頻中,需要保證跨幀的姿態預測是一致的,為了將上面討論的方法擴展到多個幀,我們在損失中添加了第二項,使相同物件
y
k
t
y_k^t
ykt?的預測在相鄰幀之間保持緊密
在視頻中,需要保證跨幀的姿態預測是一致的,為了將上面討論的方法擴展到多個幀,我們在損失中添加了第二項,使相同物件
y
k
t
y_k^t
ykt?的預測在相鄰幀之間保持緊密
L
t
i
m
e
(
Y
t
?
1
,
Y
t
)
=
1
K
∑
k
=
1
K
d
(
y
k
t
?
1
,
y
k
t
)
,
L_{time}(Y^{t-1},Y^t)=\frac{1}{K}\displaystyle\sum_{k=1}^{K}d(y_k^{t-1},y_k^t),
Ltime?(Yt?1,Yt)=K1?k=1∑K?d(ykt?1?,ykt?),
d是歐氏距離的平方,總的來說,損失:
L
(
Y
)
=
∑
t
=
1
T
L
s
p
a
c
e
(
Y
t
)
+
λ
∑
t
=
2
T
L
t
i
m
e
(
Y
t
?
1
,
Y
t
)
L(Y)=\displaystyle\sum_{t=1}^{T}L_{space}(Y^t)+\lambda\displaystyle\sum_{t=2}^{T}L_{time}(Y^{t-1},Y^t)
L(Y)=t=1∑T?Lspace?(Yt)+λt=2∑T?Ltime?(Yt?1,Yt)
λ是自己設定的,控制時間項在損失中所占的比例,λ=1說明空間項和時間項的重要性相等,
大意:之前都是單幀,所以只用考慮空間資訊,多幀則需要考慮時間資訊, L t i m e L_{time} Ltime?的意思是要使相鄰兩幀的姿態y緊密相鄰(原因也很簡單,相鄰幀的同一個物件不可能出現較大的移動),這里有一個 λ \lambda λ,控制時間項的比例,如果你想讓視頻中的姿態流暢,就增加 λ \lambda λ就對了
 現在看一下公式(5)的優化程序,給定初始Y,在t幀迭代細化Y,損失
L
(
Y
)
L(Y)
L(Y)將減小,假設1<t<T,重寫公式(5),只包含依賴于
Y
t
Y^t
Yt的項,同時保持Y的其余部分不變,如下所示:
現在看一下公式(5)的優化程序,給定初始Y,在t幀迭代細化Y,損失
L
(
Y
)
L(Y)
L(Y)將減小,假設1<t<T,重寫公式(5),只包含依賴于
Y
t
Y^t
Yt的項,同時保持Y的其余部分不變,如下所示:
L
(
Y
t
)
=
1
S
t
∑
i
=
1
n
t
min
?
k
d
b
d
(
x
i
t
,
y
k
t
)
s
i
t
+
λ
1
K
∑
k
=
1
K
(
d
(
y
k
t
,
y
k
t
?
1
)
+
d
(
y
k
t
,
y
k
t
+
1
)
)
L(Y^t)=\frac{1}{S^t}\displaystyle\sum_{i=1}^{n^t}\min\limits_kd_{bd}(x_i^t,y_k^t)s_i^t+\lambda\frac{1}{K}\displaystyle\sum_{k=1}^{K}(d(y_k^{t},y_k^{t-1})+d(y_k^{t},y_k^{t+1}))
L(Yt)=St1?i=1∑nt?kmin?dbd?(xit?,ykt?)sit?+λK1?k=1∑K?(d(ykt?,ykt?1?)+d(ykt?,ykt+1?))
用
a
i
k
t
a_{ik}^t
aikt?替換
min
?
k
\min\limits_k
kmin?,用
d
b
d
d_{bd}
dbd?替換d:
L
′
(
Y
t
)
=
S
?
t
S
t
z
+
1
S
t
∑
i
=
1
n
t
a
i
k
t
d
b
d
(
x
i
t
,
y
k
t
)
s
i
t
+
λ
1
K
∑
k
=
1
K
(
d
(
y
k
t
,
y
k
t
?
1
)
+
d
(
y
k
t
,
y
k
t
+
1
)
)
L'(Y^t)=\frac{\stackrel{-t}{S}}{S^t}z+\frac{1}{S^t}\displaystyle\sum_{i=1}^{n^t}a_{ik}^td_{bd}(x_i^t,y_k^t)s_i^t+\lambda\frac{1}{K}\displaystyle\sum_{k=1}^{K}(d(y_k^{t},y_k^{t-1})+d(y_k^{t},y_k^{t+1}))
L′(Yt)=StS?t??z+St1?i=1∑nt?aikt?dbd?(xit?,ykt?)sit?+λK1?k=1∑K?(d(ykt?,ykt?1?)+d(ykt?,ykt+1?))
w
h
e
r
e
a
i
k
t
=
1
[
d
(
x
i
t
,
y
k
t
)
?
d
(
x
i
t
,
y
j
t
)
?
j
a
n
d
d
(
x
i
t
,
y
k
t
)
<
z
]
where\quad a_{ik}^t=1[d(x_i^t,y_k^t)\leqslant d(x_i^t,y_j^t)\forall j \quad and\quad d(x_i^t,y_k^t)<z]
whereaikt?=1[d(xit?,ykt?)?d(xit?,yjt?)?jandd(xit?,ykt?)<z]
大意:這些公式就變形,仔細看看前面的公式,無非就是替換,或者換一個定義,where條件中的1翻譯的是指標函式,我也不太清楚,不過我之前看的論文里面提到過,如果[ ]里面的內容成立,那這個1指標函式的值就是1,我的理解就是,把x限制在一個范圍內,就可以用歐氏距離的平方d代替 d d b d_{db} ddb?,目的就是好計算嘛,因為 d d b d_{db} ddb?這里面有非線性的min,不好逆推呀,
 其中1為指標函式,
s
?
t
\stackrel{-t}{s}
s?t為未分配到任何聚類的所有
x
i
t
x_i^t
xit?的得分之和,因為賦值
a
i
k
t
a_{ik}^t
aikt?是固定的,L’是L的上界,也就是
L
(
Y
t
)
?
L
′
(
Y
t
)
L(Y^t)\leqslant L'(Y^t)
L(Yt)?L′(Yt).
L
(
Y
t
)
L(Y^t)
L(Yt),min是非線性計算,所以直接計算
L
(
Y
t
)
L(Y^t)
L(Yt)是非常困難的,我們用
L
′
(
Y
t
)
L'(Y^t)
L′(Yt)來替代,
其中1為指標函式,
s
?
t
\stackrel{-t}{s}
s?t為未分配到任何聚類的所有
x
i
t
x_i^t
xit?的得分之和,因為賦值
a
i
k
t
a_{ik}^t
aikt?是固定的,L’是L的上界,也就是
L
(
Y
t
)
?
L
′
(
Y
t
)
L(Y^t)\leqslant L'(Y^t)
L(Yt)?L′(Yt).
L
(
Y
t
)
L(Y^t)
L(Yt),min是非線性計算,所以直接計算
L
(
Y
t
)
L(Y^t)
L(Yt)是非常困難的,我們用
L
′
(
Y
t
)
L'(Y^t)
L′(Yt)來替代,
L
′
(
Y
t
)
L'(Y^t)
L′(Yt)可以簡寫成:
L
′
(
Y
t
)
=
∑
k
∑
j
s
?
k
j
d
(
y
k
t
,
x
?
k
j
)
,
L'(Y^t)=\displaystyle\sum_{k}\displaystyle\sum_{j}\stackrel{-k}{s}_jd(y_k^{t},\stackrel{-k}{x}_j),
L′(Yt)=k∑?j∑?s?kj?d(ykt?,x?kj?),
s
?
k
j
\stackrel{-k}{s}_j
s?kj?和
x
?
k
j
\stackrel{-k}{x}_j
x?kj?一旦被寫成這種形式,我們就可以計算:
y
k
t
=
∑
j
s
?
k
j
x
?
k
j
/
∑
j
s
?
k
j
y_k^{t}=\displaystyle\sum_{j}\stackrel{-k}{s}_j\stackrel{-k}{x}_j/\sum_{j}\stackrel{-k}{s}_j
ykt?=j∑?s?kj?x?kj?/j∑?s?kj?
大意:這個部分我不懂,我的理解是化簡 L ′ ( Y t ) L'(Y^t) L′(Yt),規定了 s ? k j \stackrel{-k}{s}_j s?kj?和 x ? k j \stackrel{-k}{x}_j x?kj?,但是我不知道這兩個是什么含義,知道的小伙伴可以在評論區分享一下,
L ′ ( Y t ) L'(Y^t) L′(Yt)的優化方法請參考2.1節,這里不再贅述, 前面給出了一種從任意Y開始,一幀一幀優化的方法,我們交替向前迭代(從t=1到t=t進行優化)和向后迭代(從t=t到t=1),直到收斂(通常幾次就足夠了),為了避免區域極小值,與標準k-均值類似,執行了多次隨機初始化,
大意:優化是迭代程序,
2.2變數K
我們的方法可以通過一次迭代估計一個軌跡來自動估計影像或視頻中的物件數量K,我們設K=1,用2.2中的方法找到給定X和S的最佳姿勢軌跡,去除回傳軌跡Y附近的所有估計值
x
i
t
x_i^t
xit?和相應的分數
s
i
t
s_i^t
sit?,直到每幀只剩一個估計姿態(或者沒有姿態,這種就是畫面中沒有出現物件)停止迭代,如果
d
(
x
i
t
,
y
t
)
<
z
d(x_i^t,y^t)<z
d(xit?,yt)<z,則洗掉估計值
x
i
t
x_i^t
xit?,我們將我們的完整方法稱為Pose_NMS,我們的Matlab代碼在標準的3.4Ghz CPU上運行速度為10-25fps,這取決于K和D,源代碼可以在線獲得,
Pose_NMS是一種多功能方法,可以合并單個影像或短序列中的姿態,通過引數λ控制時間項所占比例,如果長時間物體數量固定(例如籠子里的動物),可以使K>1進行聯合優化,生成一種高效的“重復姿態估計跟蹤”方法,可用于跟蹤場景(進入/離開場景的物件數量可變),用Pose_NMS在短序列中查找相關軌跡,
大意:說明變數K的含義,就是物件數目,K=1說明圖片中只有一個物件,只用估計一個姿態,Pose_NMS的用途廣泛,厲害,
以上就是我認為這篇文章中最重要的部分,下面就是實驗方法和實驗結果,不會逐句翻譯,我只講一下大概,感興趣的小伙伴可以仔細看原文,它的實驗還是非常有技巧性的,而且很全面,為了體現效果,特意選取和自制了一些資料,
3.結果

大意:用到的資料和三個檢測任務,對資料進性預處理,確定檢測框

大意:四種方法,分別使用這幾種方法,對比最后效果
3.1 Buffy stickmen資料集

大意:介紹Buffy stickmen資料集
3.1.1 Original Buffy 資料集沒有時間資訊

大意:Original Buffy 資料集沒有時間資訊,Pose_NMS方法比NMS方法效果好
3.1.2 Video Buffy資料集

大意:制作資料集,驗證Pose_NMS方法效果
3.2 Faces

大意:臉部資料集,檢測人臉,驗證Pose_NMS方法效果
3.3 Mice

大意:老鼠資料集,檢測老鼠,驗證Pose_NMS方法效果
4.總結

大意:最后總結
ps:這篇文章是我學習人體姿態估計看的第二篇論文,目前是小白階段,決議有很多不足和不專業的地方,請大家多多擔待,歡迎感興趣的朋友一起交流,我會繼續分享和記錄自己的學習程序,請大家多多支持,為我第一篇博文點個贊,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/262127.html
標籤:其他
下一篇:Linux常用命令操作【入門級】