面試官聽我講完HashMap直呼要為我點贊
前言
這是Homer與面試官系列第一篇,在一個周末陽光明媚的午后,Homer拿起他的電腦,便開始了一頓知識的輸出,HashMap作為面試必問重點,也是必須非常清晰掌握的,
開場
面試開始,一個還剩少量稀疏頭發的大叔,踏著輕快的步伐走過來,喃喃道:又來一個不怕死,開口說道:“用過Hashmap吧?”,
心里想:這不是廢話嘛!當然用過,這也是問題?然后回到道:嗯,用過的,
那你跟我講講他的結構吧
在JDK1.7中HashMap是由陣列加鏈表構成的資料結構,
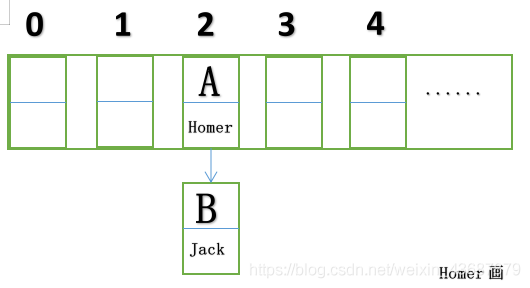 陣列的每一個地方存盤有key-value的資料節點,在1.7中稱為Entry,1.8中為Node,
陣列的每一個地方存盤有key-value的資料節點,在1.7中稱為Entry,1.8中為Node,
當執行put(“A”,“Homer”)方法時,會先將key值的hash值進行計算得到一個存盤地址,如hash(“A”)得到2,就將其存入陣列2的位置,繼續執行put(“B”,“Jack”),在某些情況之下,如果hash(“B”)得到又是2,會通過equal()比較key值是否相等,如果相等覆寫,如果不相等就會形成鏈表,(Hash相等,值不一定相等)
那JDK1.8呢?
在JDK1.8中添加了紅黑樹,變成了陣列+鏈表/紅黑樹的結構,
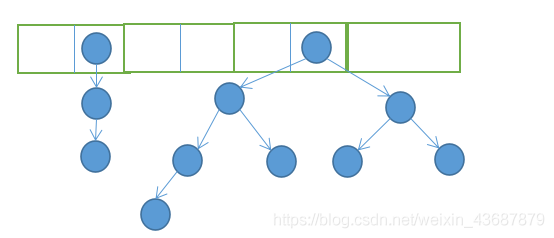 當鏈表的長度大于8時,鏈表會轉換成紅黑樹,
當鏈表的長度大于8時,鏈表會轉換成紅黑樹,
小伙子,那你跟我講講Node是啥樣呢?插入流程呢?
每一個Node節點都會保存自身的hash、key、value、以及下個節點,

1.當第一Node節點插入時,判斷陣列是否為空,為空則進行初始化,
2.若不為空,通過key的hash值進行計算得到陣列存盤下標index,
3.查看陣列index位置是否有資料,如果為空則初始化一個node節點放入,
4.若陣列index位置不為空,則判斷key值是否相等,相等則覆寫掉原有value值,
5.key值不等(發生hash沖突),判斷是否是樹型節點,如果是則插入紅黑樹中,
6.不是樹型節點,創建Node加入鏈表,判斷鏈表長度是否大于 8并且陣列長度大于64, 大于的話鏈表轉換為紅黑樹
7.插入完畢后判斷節點個數是否大于閾值(容量*裝載因子),大于(沒有等于)則進行擴容,
你說的還是比較清楚,你剛才提到容量,那是怎么設計的呢?
我這臭嘴,咦!多說啥呢,跪著也得繼續講清楚啊,當進行new HashMap()時不傳入值,則初始化容量為16,如果傳入值,初始化大小為 大于值的 2的整數次方,如傳入17,初始化為32,
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
cap為傳入值,減1操作后,進行初始二進制右移1,2,4,8,16位,分別與自己位或,把高位第一個為1的數通過不斷右移,把高位為1的后面全變為1,最后再進行+1操作,就變成 大于值的 2的整數次方,
如傳入14,為1110,進行-1,就為1101,
>>>1 = 0110,進行或操作:1101 | 0110 = 1111.
后面操作同理,最后如果不大于Integer最大值,則加1回傳,1111+1 = 10000,也就是16.
那為啥要減一呢?
咦!這也問?當然要減一,如果傳入16,不減一,則10000變成11111,最后加一則回傳了32.
嗯,小伙子不錯,那裝載因子是怎么回事呢?
裝載因子用于表示HashMap滿的程度,默認值為0.75f,設定成0.75,因為0.75正好是3/4,而capacity又是2的冪,所以,兩個數的乘積都是整數,
之所以設定為0.75,因為可以盡可能提高查詢效率和降低空間利用的成本,滿足泊松分布,碰撞最小,如果加載因子過高如1,如第16個元素插入時,碰撞概率非常高了,導致查詢效率降低,加載因子過低如0.5則擴容的頻率加大,對空間使用效率很低,
你剛才提到容量初始化為16,那為啥是16呢?
因為容量過大可能空間浪費,過小頻繁擴容影響效率,這應該一種經驗值,

為了位運算的方便,位與運算比算數計算的效率高了很多,是為了在生成陣列下標index時更高的效率,
前面都講的很nice,你在說hash碰撞,那你說是怎么樣hash的?
先拿到key的hashcode,是一位32位的int數值,然后讓hashcode的高16位和低16位進行異或操作,此為擾動函式:盡量降低hash碰撞概率,同時采用位運算提高效率,
static final int hash(Object key) {
int h;
//可以看出key可以為null,但也只能插入一個null,
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
為什么需要高16位和低16位異或可以降低碰撞呢?
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
陣列的位置index = hash&(n - 1),在這里也解釋了為什么需要容量為2的n次方,Length-1的值是所有二進制位全為1,“與”操作的結果就是散列值的高位全部歸零,只保留低位值,用來做陣列下標訪問,以初始長度16為例,16-1=15,2進制表示是00000000 00000000 00001111,和某散列值做“與”操作如下,結果就是截取了最低的四位值,

這時候問題就來了,這樣就算我的散列值分布再松散,要是只取最后幾位的話,碰撞也會很嚴重,更要命的是如果散列本身做得不好,分布上成等引數列的漏洞,恰好使最后幾個低位呈現規律性重復,
這時候“擾動函式”的價值就體現出來了:

右移16位,正好是32位的一半,自己的高半區和低半區做異或,就是為了混合原始哈希碼的高位和低位,以此來加大低位的隨機性,
1.7做了四次移位和四次異或,但明顯Java 8覺得擾動做一次就夠了,做4次的話,多了可能邊際效用也不大,所謂為了效率考慮就改成一次了,
下面是1.7的hash代碼:
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
為啥需要將鏈表轉為紅黑樹呢?
防止發生hash沖突,鏈表長度過長,將時間復雜度由O(n)降為O(logn);
嗯!!不錯不錯,看來我是低估你了呀?那我們繼續吧!談談HashMap怎么擴容的?
在插入時,1.7先判斷是否需要擴容,再插入,1.7采用頭插法,也就是將新元素放到陣列中,原始節點作為新節點的后繼節點,新節點到了頭部,因為寫這個代碼的作者認為后來的值被查找的可能性更大一點,提升查找的效率,
你提到頭插法,頭插法會面臨什么問題?
頭插法在多執行緒的條件下可能會導致產生環,陣列的容量是有限的,當超過了陣列所能裝載的節點個數,就會擴容,
擴容分為兩步:
- 擴容:創建一個新的Entry空陣列,長度是原陣列的2倍,
- ReHash:遍歷原Entry陣列,把所有的Entry重新Hash到新陣列,
為啥需要重新hash呢?
是因為長度擴大以后,Hash的規則也隨之改變,
Hash的公式—> index = HashCode(Key) & (Length - 1)
繼續你的產生環問題吧!
1.7的擴容代碼
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
現在往一個容量大小為2的put兩個值,負載因子是0.75是不是我們在put第二個的時候就會進行transfer,現在我們要在容量為2的容器里面用不同執行緒插入3,7,5,假如我們在transfer之前打個斷點,那意味著資料都插入了但是還沒擴容前可能是這樣的,
可以看到鏈表的指向3->7->5:

單鏈表的頭插入方式,同一位置上新元素總會被放在鏈表的頭部位置,在舊陣列中同一條Entry鏈上的元素,通過重新計算索引位置后,有可能被放到了新陣列的不同位置上,
在單執行緒條件下:
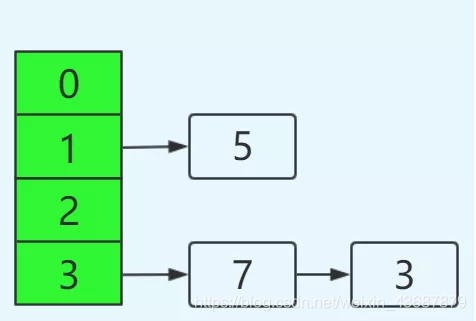
然后在多執行緒環境下,假設有兩個執行緒A和B都在進行put操作,執行緒A在執行到transfer函式中newTable[i] = e;處掛起
Entry<K,V> next = e.next;
e.next = newTable[i];
newTable[i] = e;
e = next;
此時執行緒A中運行結果如下:
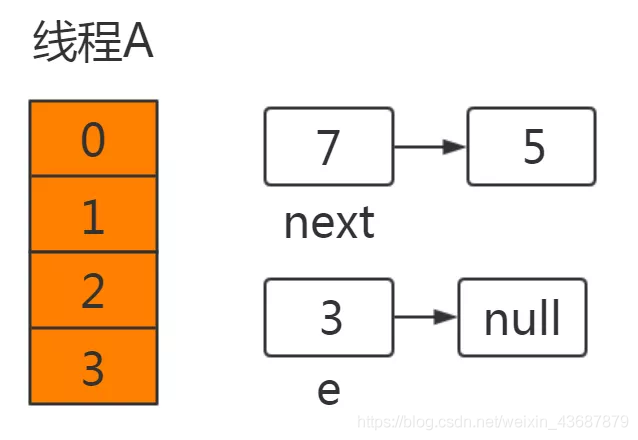 此為擴容關鍵代碼,e為原陣列的頭一個元素,也就是3,此時還未在newTable完成賦值,此時快取中e=3,e.next = null,next = 7,7.next = 5;
此為擴容關鍵代碼,e為原陣列的頭一個元素,也就是3,此時還未在newTable完成賦值,此時快取中e=3,e.next = null,next = 7,7.next = 5;
此時執行緒B前來擴容,執行緒A、B是共享一個table,也就是共享資料,執行緒B完成Transfer:
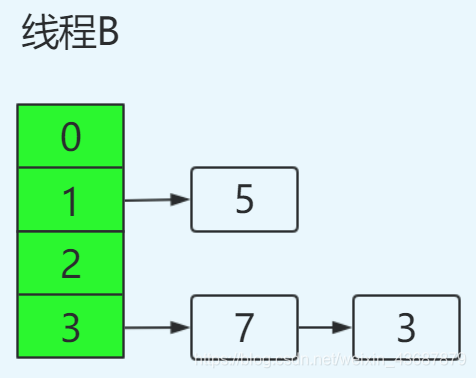
此時,執行緒A繼續執行,但是由于共享資料,此時的7.next = 3,3.next =null,
再次貼出擴容代碼,因為核心就在這里:
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;// newTable[3] = 3
e = next;// e = 7
}
}
}
執行緒A再執行時,如下:
newTable[i] = e;// newTable[3] = 3
e = next;// e = 7
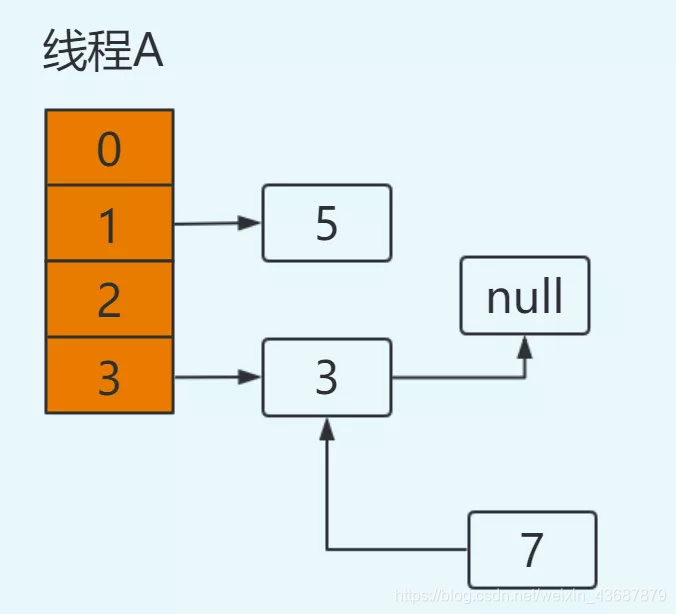 繼續回圈:此時的e為A執行緒阻塞時next = 7(此為執行緒私有資料,不會改變)
繼續回圈:此時的e為A執行緒阻塞時next = 7(此為執行緒私有資料,不會改變)
e=7
next=e.next ----> next=3【從主存中取值】
e.next=newTable[3] ----> e.next=3【從主存中取值】
newTable[3]=e ----> newTable[3]=7
e=next ----> e=3
再次進行回圈:在正常情況這里就應該為null終止回圈了
e=3
next=e.next ----> next=null
e.next=newTable[3] ----> e.next=7 即:3.next=7
newTable[3]=e ----> newTable[3]=3
e=next ----> e=null
此次回圈:e.next=7,而在上次回圈中7.next=3,出現環形鏈表,并且此時e=null回圈結束,
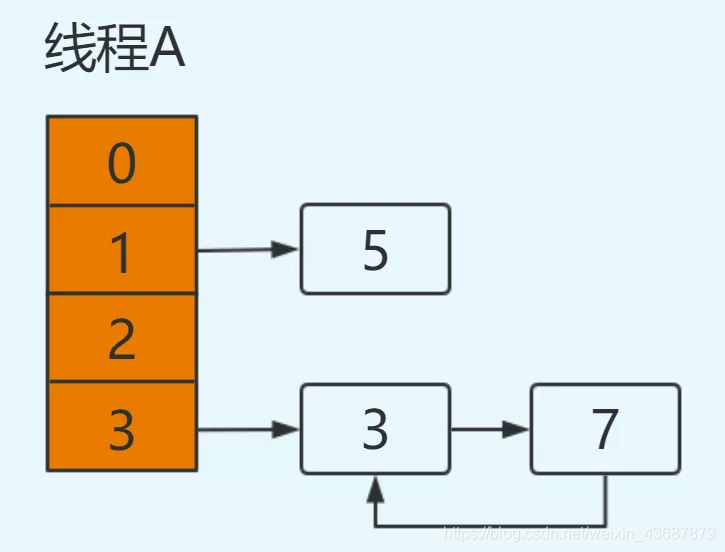 只要涉及輪詢hashmap的資料結構,就會在這里發生死回圈,
只要涉及輪詢hashmap的資料結構,就會在這里發生死回圈,
嗯!你真是天生神人啊!知道這么多,不過你以為就完了?天真,1.8尾插就沒有問題了?
依然執行緒不安全,
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
2 boolean evict) {
3 Node<K,V>[] tab; Node<K,V> p; int n, i;
4 if ((tab = table) == null || (n = tab.length) == 0)
5 n = (tab = resize()).length;
6 if ((p = tab[i = (n - 1) & hash]) == null) // 如果沒有hash碰撞則直接插入元素
7 tab[i] = newNode(hash, key, value, null);
第6行代碼,如果沒有hash碰撞則會直接插入元素,如果執行緒A和執行緒B同時進行put操作,剛好這兩條不同的資料hash值一樣,并且該位置資料為null,所以這執行緒A、B都會進入第6行代碼中,假設一種情況,執行緒A進入后還未進行資料插入時掛起,而執行緒B正常執行,從而正常插入資料,然后執行緒A獲取CPU時間片,此時執行緒A不用再進行hash判斷了,問題出現:執行緒A會把執行緒B插入的資料給覆寫,發生執行緒不安全,
那怎么解決執行緒安全問題呢?
Java中有HashTable、Collections.synchronizedMap、以及ConcurrentHashMap可以實作執行緒安全的Map,
HashTable是直接在操作方法上加synchronized關鍵字,鎖住整個陣列,粒度比較大,Collections.synchronizedMap是使用Collections集合工具的內部類,通過傳入Map封裝出一個SynchronizedMap物件,內部定義了一個物件鎖,方法內通過物件鎖實作;ConcurrentHashMap使用分段鎖,降低了鎖粒度,讓并發度大大提高,
嗯,我還想繼續問一下關于執行緒安全問題,以及鎖粒度等,不過今天已經不早了,咋們下次再約吧!
嗯嗯嗯,好的,我們下一次再見
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/262154.html
標籤:其他
上一篇:隱私合規--42--企業資料保護合規體系建設經驗總結(一)
下一篇:form表單