腦瓜子嗡嗡的小劉煉丹之路—YOLOV2 paper Analysis
? ? 嘿嘿嘿,相信大家都已經開始上班搬磚了吧,哈哈哈!腦瓜子嗡嗡的小劉,初七就開始上班了,真的難受,說好的假期計劃也如期泡湯,唯一做的就是將kitti部分資料進行了可視化如下視頻: ,
? ?果然在家里面啥也不想做,不想動,這一篇是簡單的說一下YOLOV2,感覺V2完全拋棄了YOLOV1的所有做法,下面我們來嘮嗑一下V2(比較篇的話還是放在V4之后吧,這一篇也是論文的分析),如果有什么不對的地方請大哥們指正出來![]() !下一期出一個嵌入式開發的專案:車內空氣檢測分析系統(沒啥技術含量,由STM32F4和氣體檢測傳感器搭建而成!),這篇論文說出了兩個模型一個是V2,一個是9000!
!下一期出一個嵌入式開發的專案:車內空氣檢測分析系統(沒啥技術含量,由STM32F4和氣體檢測傳感器搭建而成!),這篇論文說出了兩個模型一個是V2,一個是9000!
一、能檢測9000多個類的-YOLO9000
??大哥們都知道資料的重要性,當然深度學習中目標檢測這一塊資料也是非常重要的,然而隨著目標檢測的發展,資料這一塊也是緊缺的,因此作者在文中提出了一種新的資料聯合訓練的方式(目標檢測資料集和分類資料集),將COCO資料集和ImageNet資料集,采用wordNet的思想利用WordTree進行聯合訓練得到YOLO9000,YOLO9000名字的由來就是可以檢測9000多個類別,YOLO9000在結構上并沒大動V2的主體,只更改了anchor box由5調整到了3個,以及在誤差計算的時候進行了調整和分類誤差上,overall,較大的保留了V2的特性,當網路檢測影像的時候,其進行反向傳播,對于分類的損失僅僅只在標簽的反向傳播損失上,YOLO9000在動物的檢測效果顯著,其他較次,
? ?1.1、什么是WordTree(what’s means Word Tree?)
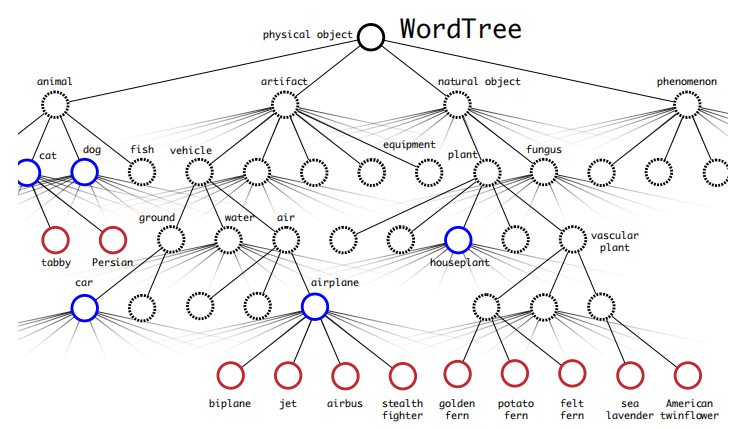
??作者為了擴大檢測的能力,而不受資料集的制約,因此提出了這種方法-聯合訓練,在檢測資料集上學習檢測的相關資訊,然后再去拓展到分類資料集上檢測,將ImageNet和COCO中的名詞物件一起構建了一個WordTree,以physical object為根節點,各名詞依據相互間的關系構建樹枝、樹葉,節點間的連接表達了物件概念之間的蘊含關系(上位/下位關系),其中的物件不是互斥的關系,而是統一類別,比如:dog和Norfolk terrier,這樣解決了9000個類別所需要的9000個softmax的問題,
??1.2、如何構建WordTree呢?
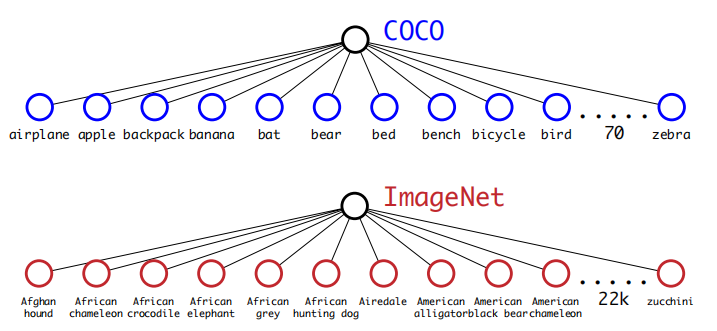
??ImgaeNet的標簽是再WordNet中所得到的,而其結構是有向圖,而YOLO2的作者希望用樹結構來簡化問題(樹肯定比圖好理解啦),首先通過遍歷的ImageNet的所有視覺名詞,對于每一個名詞,在WordNet找到其的physical object為根結點,如果該節點到WordTree根節點(physical object)的路徑只有一條,就將該路徑添加到WrodTre,如果該節點有兩條路徑到根節點,則其中一條需要添加3個邊到層次樹,另一條僅需添加一條邊,那么就選擇添加邊數少且較短的那條路徑,添加到WordTree中,如圖一、二為WordTree將多個資料集結合,
|
|
??1.3、WordTree如何表達 & 預測物件呢?
??WordTree中存在著9418個節點(物件),即有9418維的向量,如果每個去做softmax顯然是不可能的,一個WordTree對應且僅對應一個物件,不過該物件節點到根節點的所有節點概率都是1,
體現出物件之間的蘊含關系,而其它節點概率是0,WordTree預測的各個節點都是條件概率,那么一個節點的絕對值概率就是他到根節點路徑上所有條件概率的乘積,在實際的計算中而是采用了一種類似于貪婪演算法,從根節點向下遍歷,對于每一個節點,選擇概率最大的,一直遍歷到某個節點的子節點概率低于所設的閾值,因為ImageNet樣本比COCO多得多,所以對COCO樣本會多做一些采樣(oversampling),適當平衡一下樣本數量,使兩者樣本數量比為4:1,
??YOLO9000本人感覺用得比較少了,不過作者也是較早的提出了聯合訓練的方法,來彌補資料集的問題,使得object detection能夠拓展到缺乏檢測樣本的物件中,
二、更改頗多的YOLOV2
??YOLOV2在YOLOV1基礎上變動是非常得到大的,網路的backbone以及匹配機制都進行了更改,YOLOV2的召回率是大大的提升了(如圖3),并且取消了dorpout layer 添加了Batch Normlization(BN)來提高收斂效果,同時消除了其他形式的正則影響,下面小弟來嘮嗑一下,雖然有點炒冷飯的嫌疑,哈哈哈哈,

??2.1、批歸一化(Batch Normlization)
??Batch Normlization能偶加快模型得收斂速度,而且在一定的程度上緩解了深層的梯度彌散,梯度消失和爆炸等問題,其主要是對每一層的資料進行歸一化處理,隨著網路的層數的增加資料離散和變化會越來越大,因此引入了BN層,其一定程度的防止了過擬合,可以減少懲罰項系數的添加和dropout層等處理方法,Batch Normlization一般添加咱激活函式的前面,神經網路里面使用大大多數ReLU或Leaky ReLU,YOLO里面采用的是Leaky ReLU,
??BN演算法基本上的處理方法為:
- 輸入:mini batch
- 輸出:規范后的網路回應:
1、計算資料的均值,
2計算批處理資料方差(均值和方差是為了獲得0-1分布)
3、規范化
4、尺度變換和偏移
5、放回學習的γ和β引數,歸一化的時候資料會呈正態分布,而引入的γ和β就良好解決了網路的表達能力下降的效果,
??2.2、使用高解析度影像微調分類模型(High Resolution Classififier )
??YOLO先用224 × 224的解析度來訓練分類網路,然后再將分辨增加到了448 × 448來對模型進10個epochs的微調,這個程序讓網路有足夠的時間調整filter去適應高解析度的輸入,然后finetune為檢測網路,這樣使得整個網路的mAP獲得了4%左右的提升,
??2.3、先驗框的使用(Convolutional With Anchor Boxes)
??YOLOV1中其將圖片劃分為
S
?
S
S*S
S?S的網格,然后每一個Grid Cell 只能預測兩個bbox,如果object落入中心網格,則該Grid Cell就負責檢測它,YOLO一張圖最多可以產生98個bbox,并且用全連接層來預測bbox中心點的坐標,后再reshape輸出,這樣導致了空間資訊的定位不準,因此,YOLOV2采用Fast-RCNN先驗框(anchor box)的思想,添加進入anchor 可以將其視為一個訓練樣本,因此為了訓練目標模型,需要標記預測每個anchor box 的類別標簽和偏移量,而非坐標,所以簡化了問題的復雜度,YOLOV2的卷積層將影像進行了32倍的下采樣,因此輸入為416的影像,則會得到13 * 13的特征圖,而先驗框的數目可以如此計算13 * 13 * 5,相對YOLO1的
81%的召回率,YOLO2的召回率大幅提升到88%,同時mAP有0.2%的輕微下降,

??2.4、Dimension Clusters
???2.4.1、如何解決人工挑選anchor box ?
??Fast R-CNN 中是采用的人工經驗篩選anchor box,人工挑選這個問題的嚴重性大家都知道,不說了,YOLOV2中作者使用k-means去聚類得到anchor box ,這個的code 在darknet中寫好了,V2中采用的不是傳統的歐氏距離,而是自己設定了一個距離度量,從而得到了更好的anchor box,
d
(
b
o
x
,
c
e
n
t
r
o
i
d
)
=
1
?
I
O
U
(
b
o
x
,
c
e
n
t
r
o
i
d
)
d(box,centroid)=1-IOU(box,centroid)
d(box,centroid)=1?IOU(box,centroid)??anchor box 具有不同的大小和不同的尺度,與識別的大小相近,與資料集標注很大關系,而在Fast R-CNN為超常數來進行手動設定,上述公式box 為其的邊框,centroid 為其聚類被選做為中心的邊框,損失函式也有這一部分的損失.
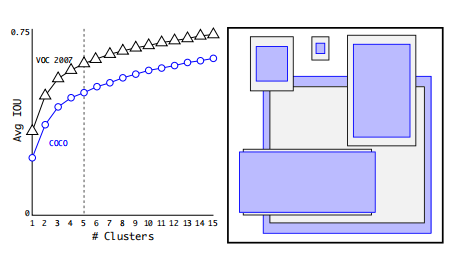
??為什么選擇IOU來做距離度量?——首先iou就是兩個框的交并集,作者希望自己選出來的anchor box 能夠盡可能的覆寫住自己的物理類別,而iou就很好的解決了這一點,因此改成了1-IOU ,就是IOU的損失,作者在這個地方做了變換意思,從下圖5中我們可以看見作者做了折中所以選擇了K=5,而YOLOV2和V3的anchor box生成的是有區別的V3中有3個不同的尺度,每一個尺度有3個框,因此的到的是9個anchor box,
???2.4.2、如何解決anchor box 帶來的模型不穩定性?
??YOLOV2在早期迭代的時候會出現模型不穩定的題,這些不穩定的因素來源于預測box的
(
x
,
y
)
(x,y)
(x,y)坐標,在區域建議網路(RPN)中會預測坐標就是預測
t
x
,
t
y
t_x,t_y
tx?,ty?,對應的中心
(
x
,
y
)
(x,y)
(x,y)按如下公式計算:
x
=
(
t
x
?
t
y
)
?
x
a
y
=
(
t
y
?
h
a
)
?
y
a
x = (t_x*t_y)-x_a\\ y=(t_y*h_a)-y_a
x=(tx??ty?)?xa?y=(ty??ha?)?ya???
x
,
y
x,y
x,y為預測框的中心,
x
a
,
y
a
x_a,y_a
xa?,ya?是先驗證框(anchor)的中心點坐標,
w
a
,
h
a
w_a,ha
wa?,ha是anchor的寬和高,
t
x
,
t
y
t_x,t_y
tx?,ty?是學習的引數,如果
t
x
t_x
tx?預測為1 則將移動到右邊錨框寬度,為-1則向左移動錨框寬度,因為
t
x
,
t
y
t_x,t_y
tx?,ty?沒有約束,因此初始的時候predicate box 的中心可以在任何位置,作者這里沿用了YOLO1的方法,直接預測Grid Cell的坐標位置,并且將ground truth通過邏輯回歸函式限制在0-1之間,
??這個網路最侄訓預測出feature map中每個grid cell的5個bbox,每個bbox包括
t
x
,
t
y
,
t
w
,
t
h
,
t
o
tx,ty,tw,th,to
tx,ty,tw,th,to(這幾個都是要學習而得到的,分別為預測的中心坐標,寬高,和置信度),如果單元格被
(
C
x
,
C
y
)
(C_x,C_y)
(Cx?,Cy?)從影像的左上角偏移(需要歸一化得到,其為單元網格1*1),并且前面的邊框具有寬度和高度
P
w
,
p
h
P_w,p_h
Pw?,ph?,則預測對應于:
b
x
=
σ
(
t
x
)
+
c
x
b
y
=
σ
(
t
y
)
+
c
y
b
w
=
p
w
e
w
t
b
h
=
p
h
e
h
t
p
r
(
o
b
j
e
c
t
)
?
I
O
U
(
b
,
o
b
j
e
c
t
)
=
σ
(
t
σ
)
b_x = σ(t_x) + c_x \\ b_y = σ(t_y) + c_y\\ b_w = p_we^t_w \\ b_h = p_he^t_h\\ p_r(object)*IOU(b,object)=σ(t_σ)
bx?=σ(tx?)+cx?by?=σ(ty?)+cy?bw?=pw?ewt?bh?=ph?eht?pr?(object)?IOU(b,object)=σ(tσ?)
??
b
x
,
b
y
,
b
w
,
b
h
b_x,b_y,b_w,b_h
bx?,by?,bw?,bh?是預測邊框的中心和寬高,
p
r
(
o
b
j
e
c
t
)
?
I
O
U
(
b
,
o
b
j
e
c
t
)
=
σ
(
t
σ
)
p_r(object)*IOU(b,object)=σ(t_σ)
pr?(object)?IOU(b,object)=σ(tσ?)為預測邊框的置信度,
σ
σ
σ為sigmoid函式,
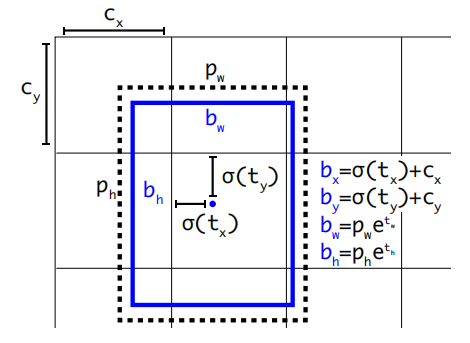
??圖6藍色的框為prediction box,預測得到的是 t x , t y , t w , t h t_x,t_y,t_w,t_h tx?,ty?,tw?,th? 最后計算得到 b x , b y , b w , b h b_x,b_y,b_w,b_h bx?,by?,bw?,bh? 而,YOLOV1中預測的沒有做限制,可以是整張圖,采用sigmoid函式將 t x , t y t_x,t_y tx?,ty? 壓縮到0-1中,因此預測的值在cell中,而不是其他地方, c y , c x c_y,c_x cy?,cx?為cell的大小,而中心的點預測是相對于整個影像的, p w , p h p_w,p_h pw?,ph?為anchor box的高寬,預測的框即為anchor box的變形,這一部分也存在這損失,都沒有直接預測縮放的尺度,
??2.5、細粒度(淺層)特征(Fine-Grained Features.)
??這個最重要的就是passthrough layer,模型在預測的時候,輸出的是13 ? 13的feature map,對大的object 是足夠的,但是對較小的物體后繼不足,因此作者添加了一層passthrough layer在最后一個pooling之前,其本質就是一種特征重排,將26 ? 26 ? 512的feature map按照隔點采樣的方式,拆分成4個13 ? 13 ? 512,后再將這寫按照channel疊加起來與原生的深層特征圖相連接(即:加深channel的conv1與conv3 concat后作為conv4的輸入),可以理解為其抽取前面層的每個2 ? 2的區域區域,然后將其轉化為channel維度,最后得到13 ? 13 ? 2048的特征圖,passthrough layer本身是不學習引數的,直接用前面的層的特征重排后拼接到后面的層,越在網路前面的層,感受野越小,有利于小目標的檢測,passthrough layer很類似于ResNet的shortcut,其不直接對高解析度的特征圖處理,而是添加了一個中間層卷積,這樣經過擴展后的的特征圖,它可以使用細粒度(淺層)特征,使得模型的性能獲得了1%的提升,

??2.6、多尺度訓練(Multi-Scale Training)
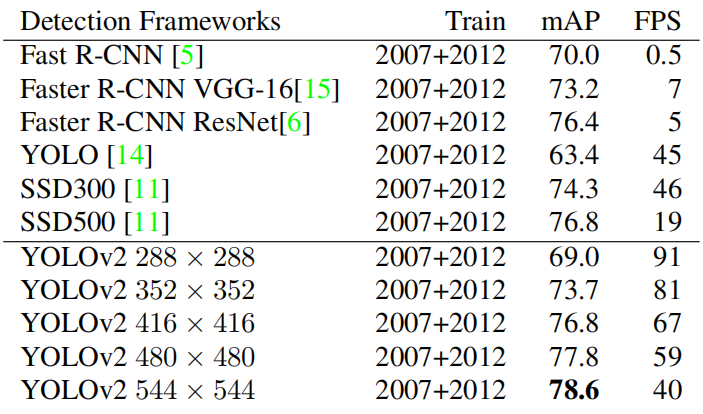
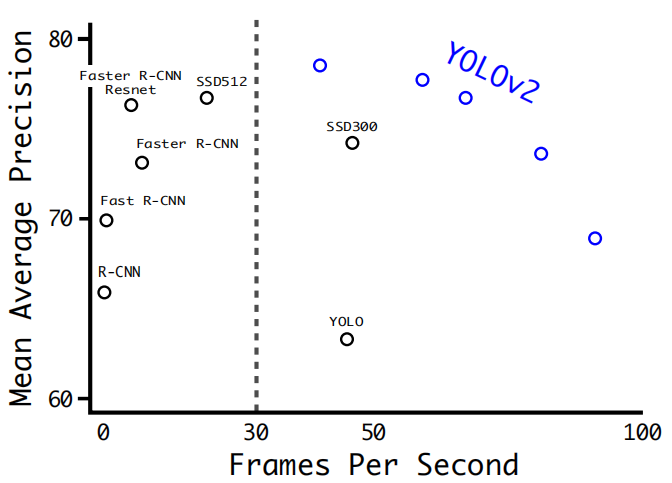
??YOLOV2的輸入不是固定的影像大小,而是每隔幾次迭代就更改一下網路,epoch10次就選擇一個新的影像尺寸,因為進行了下采樣所以提取:{320,352,…,608}, 因此,最小的選項是320×320,最大的選項是608×608,這樣使得網路具有魯棒性,這種機制迫使網路學會在各種輸入維度上很好地預測, 這意味著同一網路可以預測不同解析度的檢測,能夠在速度和精度之間進行權衡,在高解析度圖片檢測中,YOLOV2達到了先進水平(state-of-the-art),VOC2007 上mAP為78.6%,而且超過實時速度要求,圖8和圖9是YOLOV2和其他網路在VOC2007上的對比:
|
|
??2.7、YOLO 的目標: Faster(backbone)
??作者希望檢測是準確的也足夠快,大多數機器人和自動駕駛汽車都依賴于低延遲,為了最大限度的提示性能,設計了YOLOV2,YOLOV2沒有采用VGG為backbone ,而是采用了darknet19,YOLO1采用的GoogleNet為backbone ,采用Googlenet 為88%,而VGG的為90%,darknet19(如圖10)精度不弱于VGG,并且浮點運算量減少到原來的1/5,速度更快,這個都是為了提取出特征,
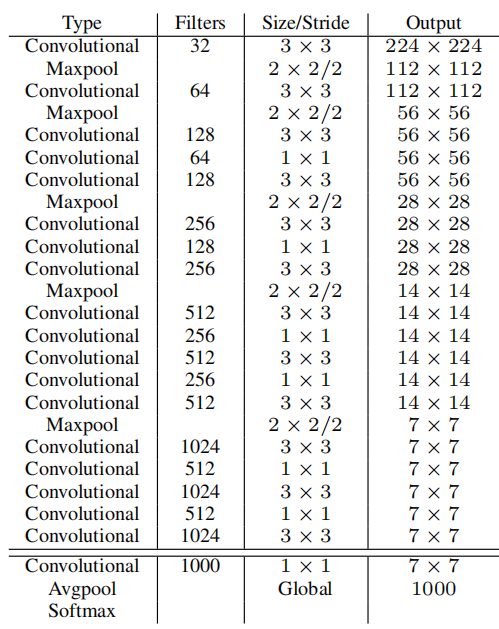
??Darknet-19是一個卷積神經網路,用作YOLOV2的主干,與它主要使用的VGG模型相似3 ? 3在每個合并步驟之后,過濾并加倍通道數量,遵循網路中網路(NIN)的作業之后,它使用全域平均池進行預測以及1 ? 1的過濾器以壓縮之間的特征表示3 ? 3卷積,批歸一化(BN)用于穩定訓練,加快收斂速度并規范化模型批次,最后的模型稱為Darknet-19 總共有19層的卷積層和5層的最大池化層Darknet-19只需要55.8億個操作來處理影像,但是在Image Net上達到72.9%的top-1精度和91.2%的top-5精度,YOLOV3里面采用的是darknet-53為backbone,
??2.8、訓練(Training for classifification & detection.)
??分類:其在Imagenet1000上分類資料上進行了160次epoch 訓練,使用darknet神經網路框架,開始學習率為0.1,多項式速度衰減為4,權重衰減為0.0005,動量為0.9,在訓練的程序中使用標準的資料增強技巧,包括隨機作物、旋轉和色調、飽和度和曝光移位(資料增強的操作,V4,V5的增強操作比這些還是多了一點),對224的影像進行初步訓練后,對網路進行了微調,使得輸入為448, 對于這種微調,我們用上述引數進行訓練,但只訓練了10個eopchs,并以 1 0 ? 3 10^{-3} 10?3的學習率開始, 在這種高解析度下,我們的網路達到了76.5%的top1精度和93.3%的top5精度,
??檢測:YOLOV2洗掉了最后一個卷積層,在3個3 * 3的卷積層添加了1024個濾波器,最后添加了1 * 1個卷積層,檢測所需要的輸出數,對于voc資料輸出5個box,每個box有20個類,因此有126個過濾器,還從最后的3×3 * 512層添加了一個passthrough layer第二到最后的卷積層,這樣我們的模型就可以使用精細的晶粒特征,我們訓練網路160個時代,起始學習率為10^-3,在60和90個時代除以10,我們使用的重量衰減為0.0005,動量為0.9, 使用類似的資料增強YOLO和SSD與隨機作物,顏色移動等, 我們在COCO和VOC上使用相同的策略,
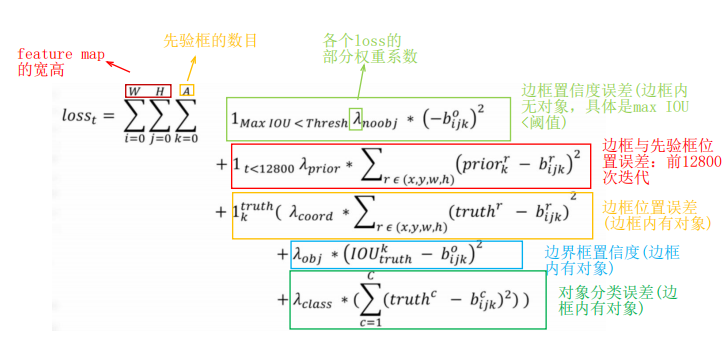
??2.9、損失函式(YOLOV2 Loss Function)
??
1
M
a
x
I
O
U
<
T
h
r
e
s
h
1_{MaxIOU}<Thresh
1MaxIOU?<Thresh 意思是預測邊框中,與真實物件邊框IOU最大的那個,其IOU<閾值Thresh,此系數為1,即計入誤差,否則為0,不計入誤差,YOLO2使用Thresh=0.6,
??
1
t
<
128000
1_t<128000
1t?<128000 意思是前128000次迭代計入誤差,注意這里是與先驗框的誤差,而不是與真實物件邊框的誤差,可能是為了在訓練早期使模型更快學會先預測先驗框的位置,
??
1
t
r
u
t
h
k
1^truth_k
1truthk? 意思是該邊框負責預測一個真實物件(邊框內有物件)
??盡管YOLOV2和YOLOv1計算loss處理上有不同,但都是采用均方差來計算loss,在計算boxes的 w w w和 h h h誤差時還是有所不同的,YOLOv1中采用的是平方根以降低boxes的大小對誤差的影響,而YOLOV2是直接計算,但是V2中的 w w w和 h h h都歸一化到(0,1),其實和YOLOV1也差不多,
三、YOLOV2的小小終結(summary)
??V2&9000中存蠻多創新點的:
- V2采用了多尺度的訓練方式:可以運行在各種影像大小,從而提供了一個平滑的權衡之間的速度和準確性,主要是采用了passthrough layer,
- 9000采用了一種聯合訓練的方式,使用WordTree將來自各種來源的資料和我們的聯合優化技術結合起來,在Image Net和COCO上同時進行訓練,從而縮小了檢測和分類之間資料集大小差距,具有很高的拓展性,
- V2采用了Batch Normlization來代替dropout,極大的收斂了整個網路,減少了梯度彌散等問題,
- V2利用了anchor box的思想,并且提出了一種新的距離度量,利用k-means來篩選,為什么使用anchor box?——目的很簡單,傳統的滑動串口無法滿足較大物體的檢測,視窗固定,并且運算量大,區域提案,為先篩選出ROI區域,在輸入到RPN網路中進行分類出候選區域,不太好,違背了one stage的原則,哈哈哈哈,因此V2采用了SSD與Fast R-CNN中的anchor機制,解決了多尺度和一個視窗檢測一個目標的問題,
??簡而言之,V2采用了一種新的特征提取網路darknet-19,并去除了FC層,采用了邊框聚類,兩層組合,多尺度訓練,損失函式還是要看代碼,哈哈哈哈,over!
??emmmm,論文是讀完了,那么接下來就要開始肝代碼了,一日不肝,很難受了!腦瓜子嗡嗡的小劉最近還看了一下國外的學校研究生 申請,果然學費勸退,哈哈哈哈哈!還是收拾好心態,準備復習考研!大哥到時候可以指點我一下,比如學校,試題等等,上述文章如果有不對的地方,記得說出來了,都是白嫖知識,一起進步嘛!ヾ(?ω?`)o
申請,果然學費勸退,哈哈哈哈哈!還是收拾好心態,準備復習考研!大哥到時候可以指點我一下,比如學校,試題等等,上述文章如果有不對的地方,記得說出來了,都是白嫖知識,一起進步嘛!ヾ(?ω?`)o

部分參考文獻:
- YOLO2
<機器愛學習>YOLOV2 / YOLO9000 深入理解
[YOLO9000:Better, Faster, Stronger(YOLOV2)(https://arxiv.org/pdf/1612.08242.pdf)
部分Star較多的code:
- keras-yolo2
yolo2-pytorch
腦瓜子嗡嗡的小劉,是某造車新勢力🚗的一名自動駕駛影像演算法實習生🐱?🏍,同時小劉也是一枚熱衷于人工智能技術的萌新小白🌏,小劉在校期間也參加過許許多多的國內比賽(主要是嵌入式與物聯網相關的),要是大哥們有什么問題,可以隨時Call me,希望能和大哥們共同進步!!!同時也希望大哥們看文章的時候也能抽空點個贊!謝謝大哥們了!!!(づ ̄ 3 ̄)づ
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/262506.html
標籤:AI
上一篇:從頭開始訓練BERT語言模型
下一篇:網路工程師和網路運維工程師的區別