概述
Velero(以前稱為Heptio Ark)是一個開源工具,可以安全地備份和還原,執行災難恢復以及遷移 Kubernetes 群集資源和持久卷,可以在 TKE 集群或自建 Kubernetes 集群中部署 Velero 用于:
- 備份集群并在丟失的情況下進行還原,
- 將集群資源遷移到其他集群,
- 將生產集群復制到開發和測驗集群,
更多關于 Velero 介紹,請參閱 Velero 官網,本文將介紹使用 Velero 實作 TKE 集群間的無縫遷移復制集群資源的操作步驟,
遷移原理
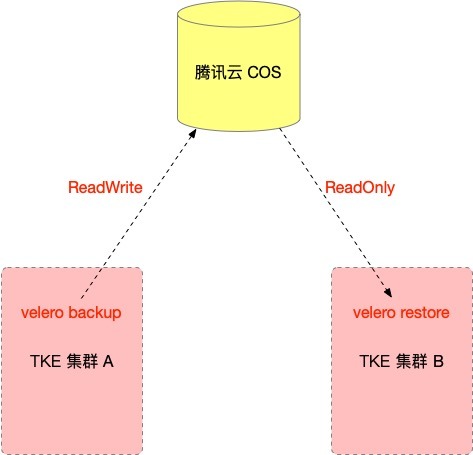
在需要被遷移的集群和目標集群上都安裝 Velero 實體,并且兩個集群的 Velero 實體指向相同的騰訊云 COS 物件存盤位置,使用 Velero 在需要被遷移的集群執行備份操作生成備份資料存盤到騰訊云 COS ,然后在目標集群上使用 Velero 執行資料的還原操作實作遷移,遷移原理如下:
前提條件
- 已 注冊騰訊云賬戶,
- 已開通騰訊云 COS 服務,
- 已有需要被遷移的 TKE 集群(以下稱作集群 A),已創建遷移目標的 TKE 集群(以下稱作集群 B),創建 TKE 集群請參閱 創建集群,
- 集群 A 和 集群 B 都需要安裝 Velero 實體(1.5版本以上),并且共用同一個騰訊云 COS 存盤桶作為 Velero 后端存盤,安裝步驟請參閱 配置存盤和安裝 Velero ,
注意事項
-
從 1.5 版本開始,Velero 可以使用 Restic 備份所有pod卷,而不必單獨注釋每個 pod,默認情況下,此功能允許用戶使用 restic 備份所有 pod 卷,但以下卷情況除外:
- 掛載默認
Service Account Secret的卷 - 掛載的
hostPath型別卷 - 掛載 Kubernetes
secrets和configmaps的卷
本示例需要 Velero 1.5 以上版本且啟用 restic 來備份持久卷資料,請確保在安裝 Velero 階段開啟
--use-restic和--default-volumes-to-restic引數,安裝步驟請參閱 配置存盤和安裝 Velero , - 掛載默認
-
在執行遷移程序中,請不要對兩邊集群資源做任何 CRUD 操作,以免在遷移程序中造成資料差異,最終導致遷移后的資料不一致,
-
盡量保證集群 B 和集群 A 作業節點的CPU、記憶體等規格配置相同或不要相差太大,以免出現遷移后的 Pods 因資源原因無法調度導致 Pending 的情況,
操作步驟
在集群 A 創建備份
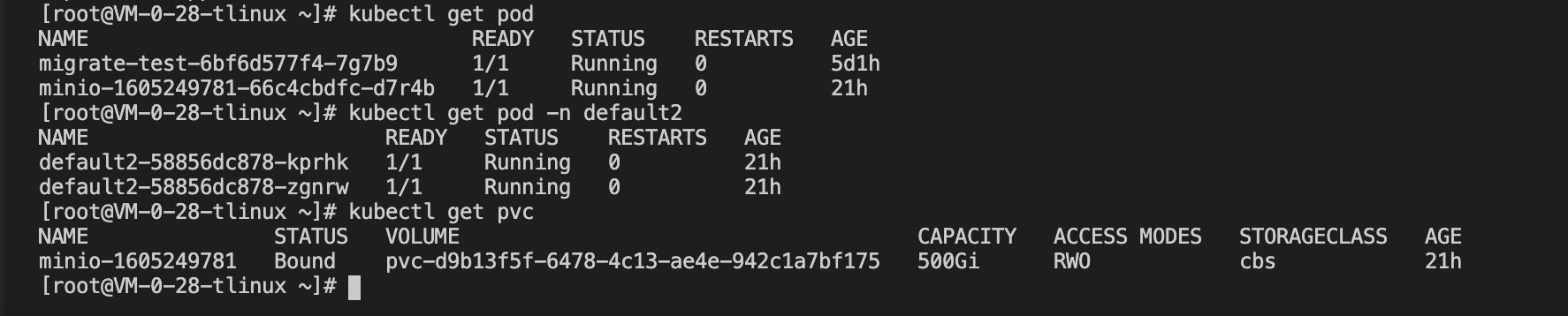
可以手動執行備份操作,也可以給 velero 設定定期自動備份,設定方法可以使用 velero schedule -h 查看,本示例將以 default 、default2 命名空間的資源情況作比較驗證,下圖可以看到集群 A 中兩個命名空間下的 Pods 和 PVC 資源情況:
提示:可以指定在備份期間執行一些自定義 Hook 操作,比如,需要在備份之前將運行應用程式的記憶體中的資料持久化到磁盤, 有關備份 Hook 的更多資訊請參閱 備份 Hook ,
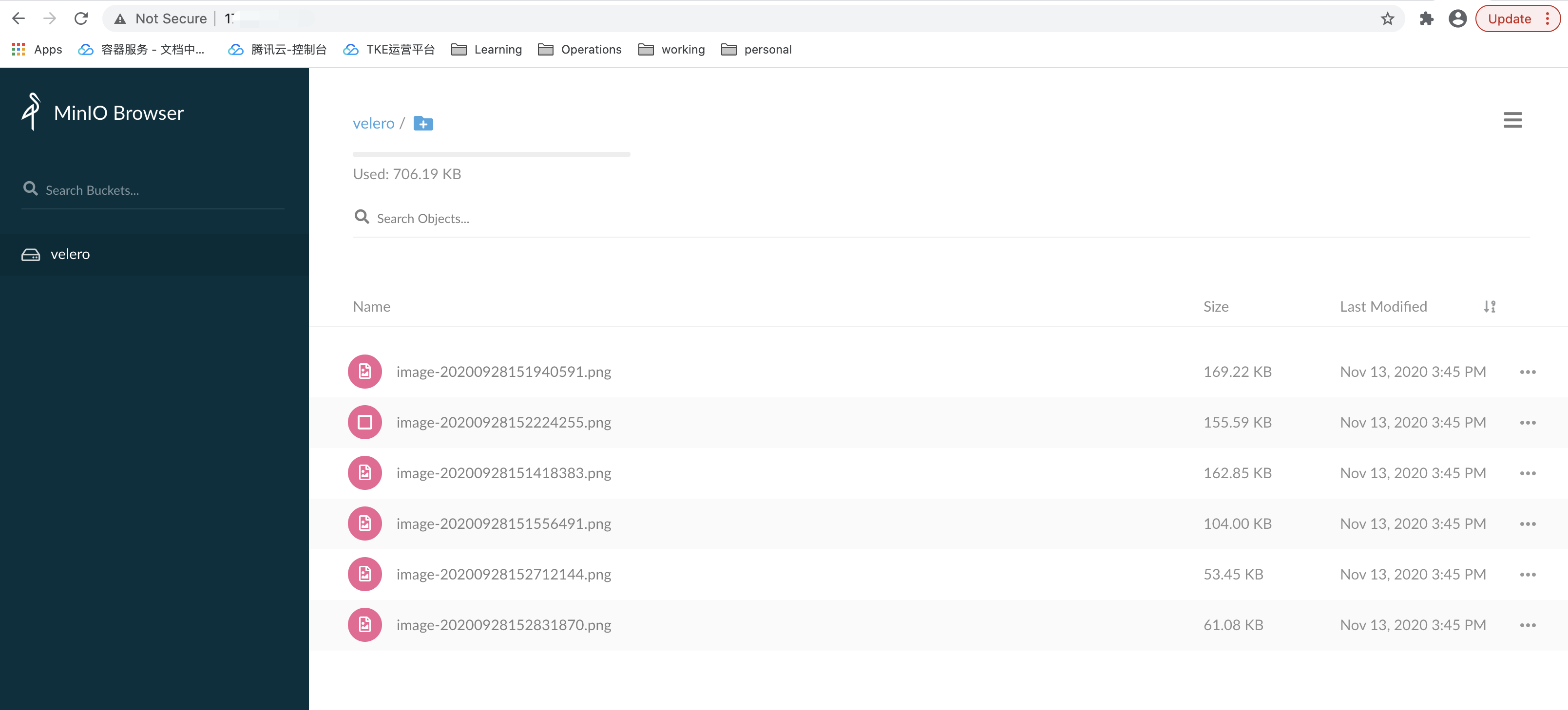
其中,集群中的 minio 物件存盤服務使用了持久卷,并且已經上傳了一些圖片資料,如下圖所示:
執行下面命令來備份集群中不包含 velero 命名空間(velero 安裝的默認命名空間)資源的其他所有資源,如果想自定義需要備份的集群資源范圍,可使用 velero create backup -h 查看支持的資源篩選引數,
velero backup create <BACKUP-NAME> --exclude-namespaces <NAMESPACE>
本示例我們創建一個 “default-all” 的集群備份,備份程序如下圖所示:

備份任務狀態顯示是 “Completed” 時,說明備份任務完成,可以通過 velero backup logs | grep error 命令檢查是否有備份操作發生錯誤,沒有輸出則說明備份程序無錯誤發生,如下圖所示:
注意:請確保備份程序未發生任何錯誤,假如 velero 在執行備份程序中發生錯誤,請排查解決后重新執行備份,

備份完成后,臨時將備份存盤位置更新為只讀模式(非必須,這可以防止在還原程序中 Velero 在備份存盤位置中創建或洗掉備份物件):
kubectl patch backupstoragelocation default --namespace velero \
--type merge \
--patch '{"spec":{"accessMode":"ReadOnly"}}'
在集群 B 執行還原
在執行還原操作前集群 B 中 default 、default2 命名空間下沒有任何作業負載資源,查看結果如下圖:

臨時將集群 B 中 Velero 備份存盤位置也更新為只讀模式(非必須,這可以防止在還原程序中 Velero 在備份存盤位置中創建或洗掉備份物件):
kubectl patch backupstoragelocation default --namespace velero \
--type merge \
--patch '{"spec":{"accessMode":"ReadOnly"}}'
提示:可以選擇指定在還原期間或還原資源后執行自定義 Hook 操作,例如,可能需要在資料庫應用程式容器啟動之前執行自定義資料庫還原操作, 有關還原 Hook 的更多資訊請參閱 還原 Hook,
在還原操作之前,需確保集群 B 中 的 Velero 資源與云存盤中的備份檔案同步,默認同步間隔是1分鐘,可以使用--backup-sync-period 來配置同步間隔,可以使用下面命令查看集群 A 的備份是否已同步:
velero backup get <BACKUP-NAME>
獲取備份成功檢查無誤后,執行下面命令還原所有內容到集群 B 中:
velero restore create --from-backup <BACKUP-NAME>
本示例執行還原程序如下圖:

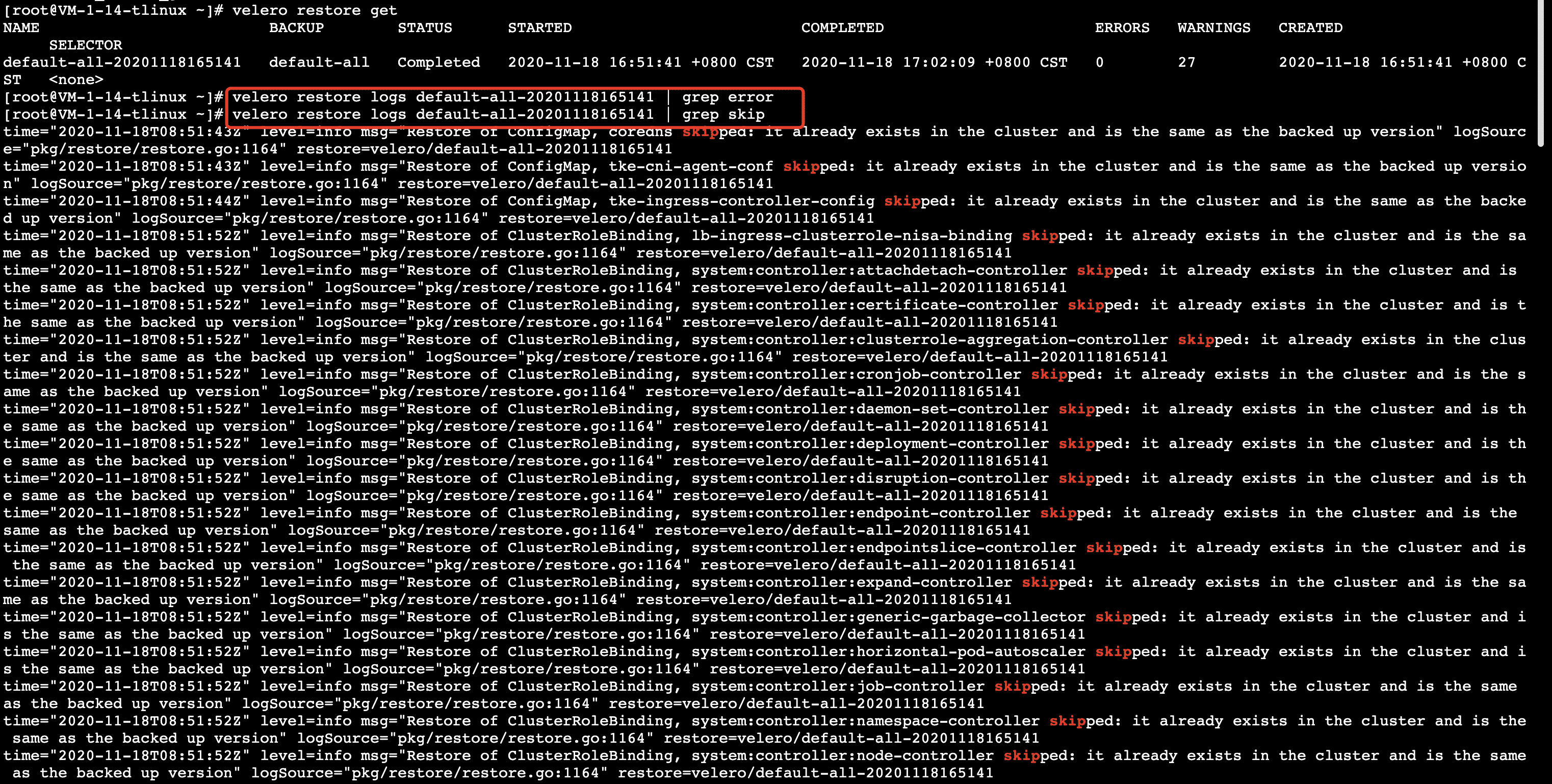
等待還原任務完成后查看還原日志, 可以使用下面命令查看還原是否有報錯和跳過資訊:
# 查看遷移時是否有錯誤的還原資訊
velero restore logs <BACKUP-NAME> | grep error
# 查看遷移時跳過的還原操作
velero restore logs <BACKUP-NAME> | grep skip
從下圖可以看出沒有發生錯誤的還原步驟,但是有很多 “skipped” 步驟,是因為我們在備份集群資源時備份了不包含 velero 命名空間的所有集群資源,有一些同型別同名的集群資源已經存在了,如 kube-system下的集群資源,當還原程序中有資源沖突時,velero 會跳過還原的操作步驟,所以實際上還原程序是正常的,可以忽略這些 “skipped” 日志,假如有特殊情況可以分析下日志看看,
遷移結果核驗
查看校驗集群 B 執行遷移操作后的集群資源,可以看到 default 、default2 命名空間下的 pods 和 PVC 資源已按預期遷移成功:

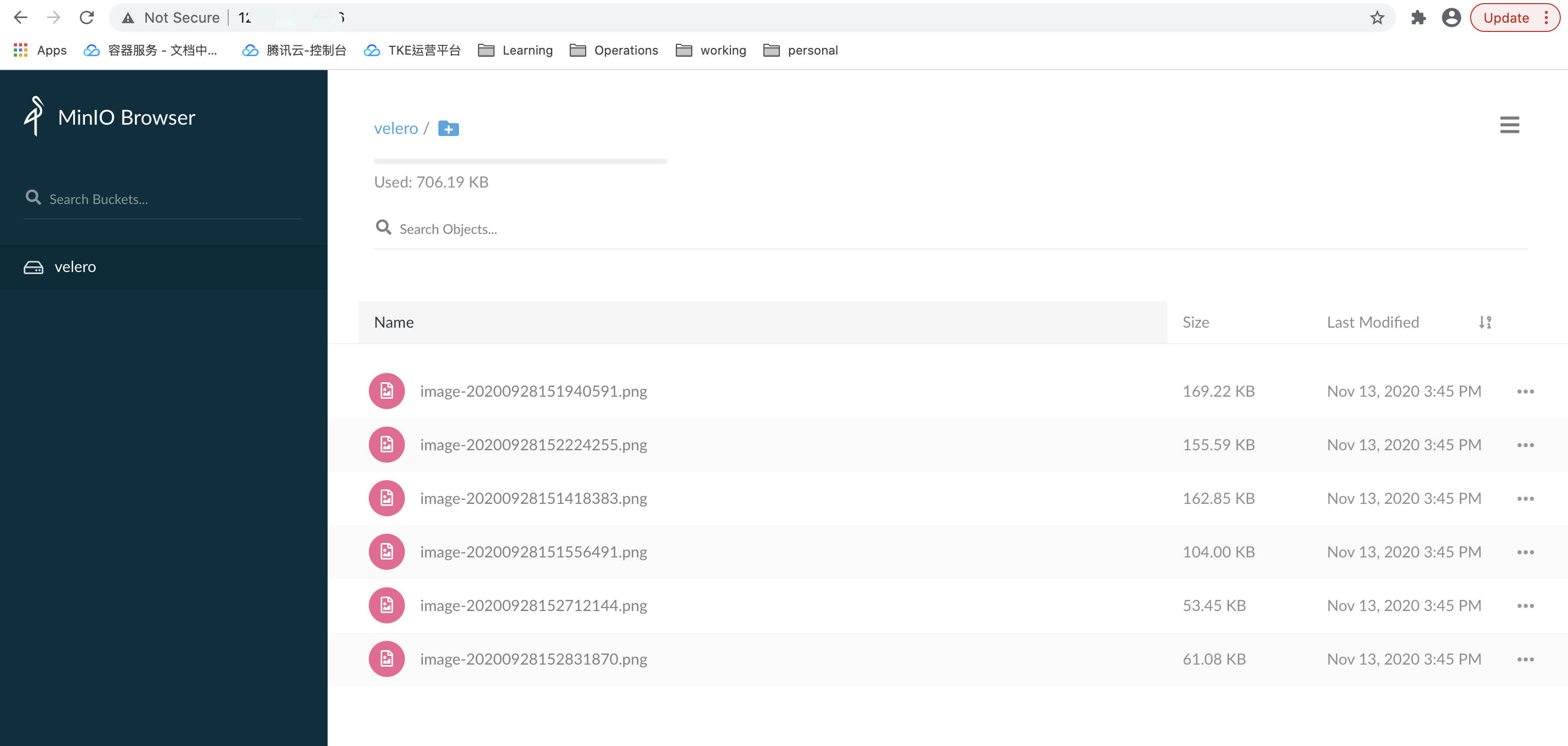
再通過 Web 管理頁面登錄集群 B 中的 monio 服務,可以看到 minio 服務中的圖片資料沒有丟失,說明持久卷資料也已按預期遷移成功,
至此,我們完成了 TKE 集群間資源的遷移,遷移操作完成后,請不要忘記把備份存盤位置恢復為讀寫模式(集群 A 和 集群B),以便下次備份任務可以成功使用:
kubectl patch backupstoragelocation default --namespace velero \
--type merge \
--patch '{"spec":{"accessMode":"ReadWrite"}}'
總結
本文主要介紹了在 TKE 集群間使用 Velero 遷移集群資源的原理、注意事項和操作方法,成功的將示例集群 A 中的集群資源無縫遷移到集群 B 中,整個遷移程序非常簡單方便,是一種非常友好的集群資源遷移方案,
【騰訊云原生】云說新品、云研新術、云游新活、云賞資訊,掃碼關注同名公眾號,及時獲取更多干貨!!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/262837.html
標籤:其他