一、起 因
**
那是一個深夜,隨著手機螢屏的熄滅,這本應該是一個溫暖而甜美的睡夢的開始,突然一聲“叮咚”的提示音劃破了這靜謐,隨之而來的是“叮咚、叮咚、叮叮叮叮咚…”借著手機螢屏的亮光,我模糊的看見了那仿佛怪笑著的綠色人頭標識上的字“你收到了20條微信訊息”…
言歸正傳,事情的起因是由于近日客戶反饋錄信資料庫LSQL突然性能變差,之前秒級回應的資料查詢與檢索,現在卻總是在“轉圈”,卡住不動了,因為是突然發生的現象,已經在現場的同事先排除了業務變動,但是并未發現問題,作為自己創立公司后第一個接到的萬億資料體量的大專案,我自身也非常重視,馬上第一時間奔赴現場,
這里先容介紹一下該平臺架構,底層采用hadoop進行分布式存盤,中間資料庫采用的錄信LSQL,資料實時匯入采用kafka進行,每天的資料規模是500億,資料存盤周期為90天,一共有4000多張資料表,其中最大的單表資料規模近2萬億條記錄,總資料規模將近5萬億,存盤空間占8PB,
資料平臺支撐的基本使用主要包括資料的全文檢索、多維查詢,以及地理位置檢索、資料碰撞等操作,也會有部分業務涉及資料的統計和分析,會有極少量的資料匯出與多表關聯操作,
二、經過
1.Before the day :初步定位問題
出發的前一天,晴空萬里,萬里無云,一如我的心情,
話說我在創業之前在騰訊做Hermes系統,每日接入的實時資料量就已經達到了3600億/天,之后更是達到了每日近萬億條資料的實時匯入,為了不顯得那么凡爾賽,我只想說,我和梁啟超在北大演講時的心情一樣:我對超大集群沒什么了解,但是還是有那么一點嘍!面對當前每日500-1000億規模的系統,我在考慮是不是買票的時候把當天的回程票也買了…
為了快速定位問題,還沒出發之前我就跟現場要了一些日志和jstack,初步定位是hadoop NameNode的瓶頸,而NN的優化我們此前也做了很多次,別無其他,唯手熟爾,
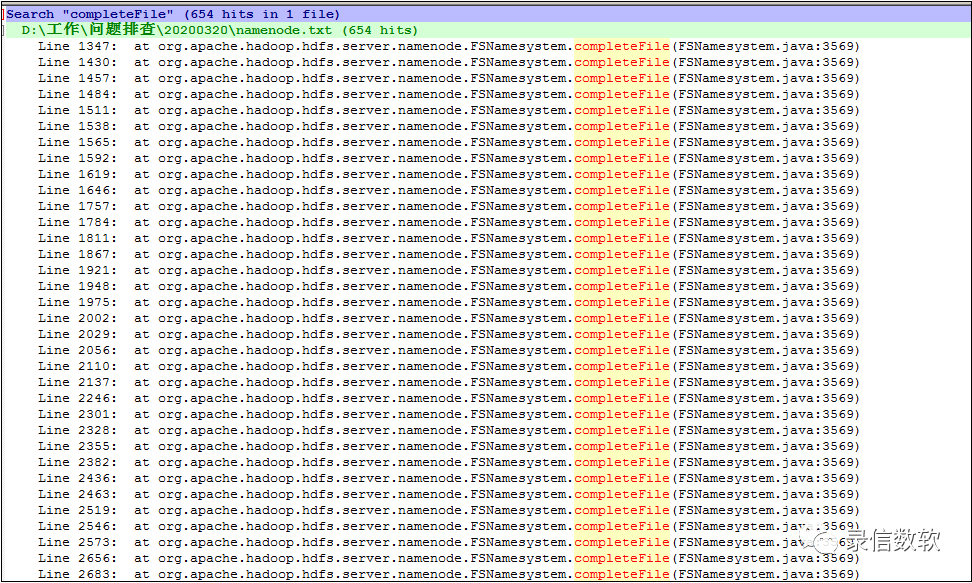
下圖為當時堆疊的分析情況,估計在座諸位看了都會信心滿滿,這很明顯就是hadoop卡頓,
2.First Day:嘗試調整log4j
到現場的第一天,依然是風和日麗,心情繼續保持美麗,
我到現場后第一件事情就是不斷的抓hadoop Namenode的堆疊Jstack,從中得到的結論是問題確實是卡頓在NN上,此處NN是一個全域鎖,所有的讀寫操作都在排序等待,詳情如下圖所示:
(1)卡在哪里
這個鎖的等待個數竟然長達1000多個,不卡才怪呢,我們再細看一下,當前擁有這個鎖的執行緒在做什么?
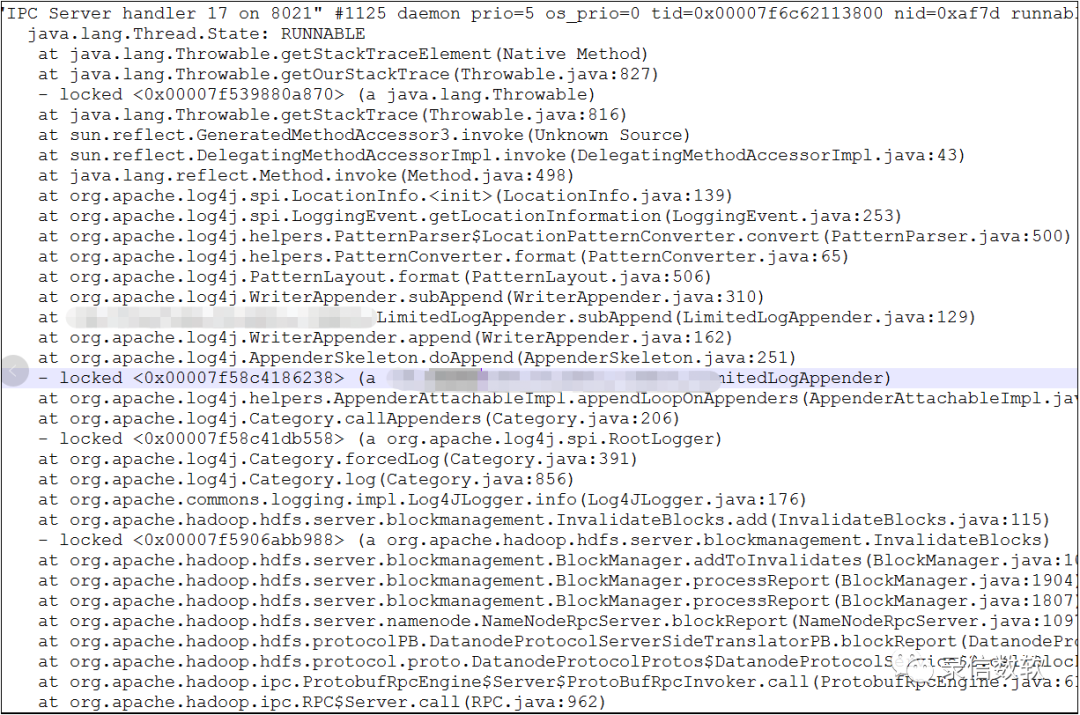
(2) 問題分析
很明顯,在記錄log上存在瓶頸,阻塞的時間太久,
-
記錄的log4j不應該加【%L】,它會創建Throwable物件,而這個在java里是一個重物件,
-
日志記錄太頻繁,刷盤刷不動,
-
log4j有全域鎖,會影響吞吐量,
(3)調整方案
- 客戶的hadoop版本采用的是2.6.0版本,該版本的hadoop,在日志處理上存在諸多問題,故我們將官方明確表示存在問題的patch打了進來
https://issues.apache.org/jira/browse/HDFS-8245 因日志原因導致nn慢
https://issues.apache.org/jira/browse/HDFS-7503 將日志記錄到鎖外,避免卡鎖
https://issues.apache.org/jira/browse/HDFS-7213 processIncrementalBlockReport 導致的記錄日志問題,嚴重影響NN性能
- 禁用namenode所有info級別的日志
觀察發現當有大量日志輸出的時候,全域鎖會阻塞NN,
目前修改方式是屏蔽到log4j的日志輸出,禁用namenode所有info級別的日志,
- log4j 的日志輸出去掉【%L】引數
這個引數會為了得到行號而創建new Throwable物件,這個物件對性能影響很大,大量創建會影響吞吐量,
- 啟用異步審計日志
dfs.namenode.audit.log.async 設定為true,將審計日志改為異步,
(4)優化效果
優化之后,確實因log4j導致的卡頓問題不存在了,但hadoop的吞吐量依然卡,仍舊卡在lock上,
3.Second Day:優化du,排查解決所有卡頓
在現場的第二天,晴空依然萬里,心情不算美麗,
接著昨天的作業:
(1)在解決了log4j的問題后,繼續抓jstack發現了如下位置:
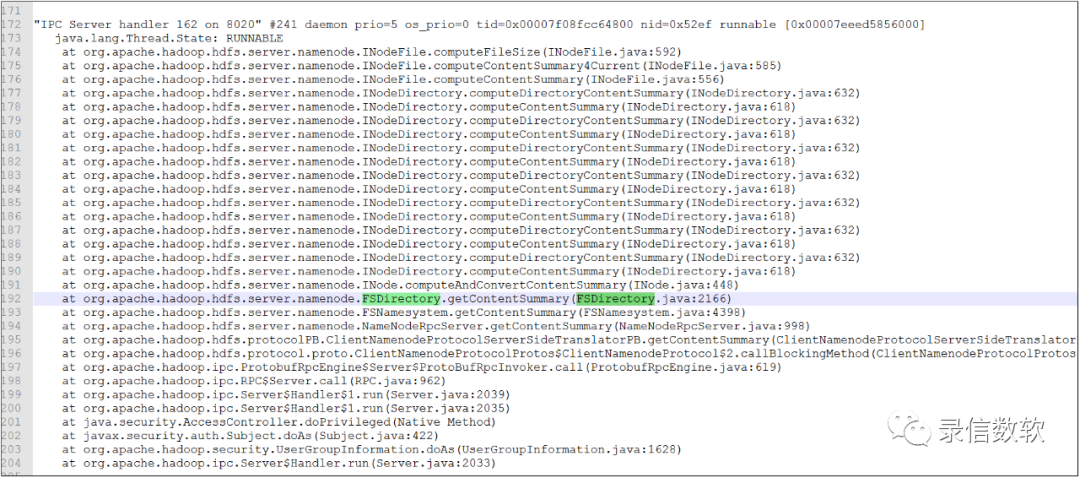
(2)通過代碼進行分析,發現確實此處有鎖,證實此處會引起所有訪問阻塞:
(3)繼續深入研讀代碼,發現受如下引數控制:
(2.6.5版本這個默認值是5000,已經不存在這個問題了)
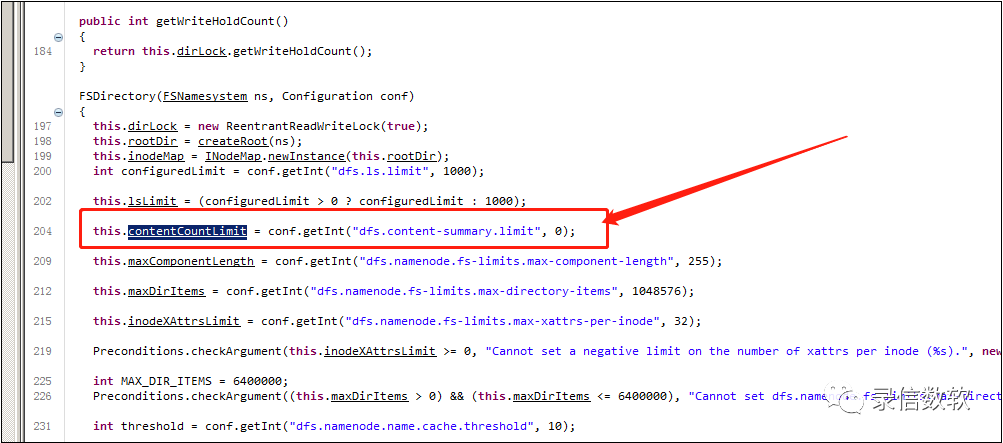
這個引數的核心邏輯是,如果配置上大于零的值,它會間隔一定檔案數量,釋放鎖,讓別的程式得以繼續執行,該問題只會在hadoop2.6.0的版本里存在,之后的版本里已經對此做了修復,
(4)解決辦法
打上官方patch:
https://issues.apache.org/jira/browse/HDFS-8046
lsql內部移除所有關于hadoop du的使用
(5)為什么要打patch
2.6.5版本中,可以自己定義休眠時間,默認休眠時間為500ms,而2.6.0休眠時間為1ms,我擔心太短,會出現問題,
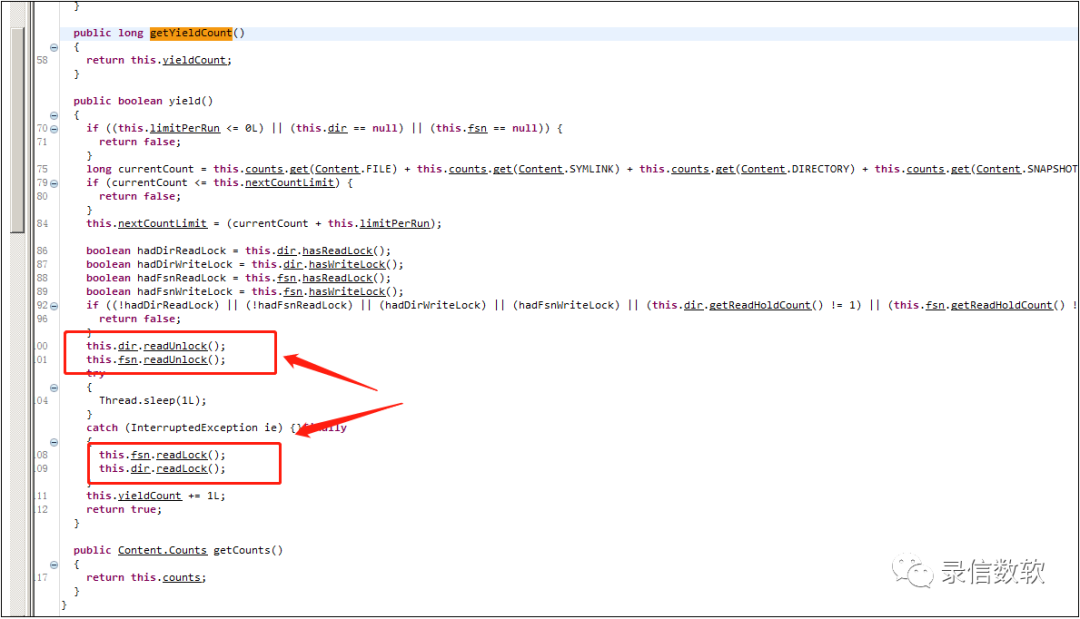
繼續按照原先思路,排查所有的jstack ,將所有涉及卡頓的地方都一一解決掉,至此hadoop通過jstack已經抓不到任何的活動執行緒,但是依然卡頓在讀寫鎖的切換上,這說明:
(1)namenode內部的每個函式已經最優,jstack基本抓不到了;
(2)堆疊呼叫只能看到近1000個讀寫鎖在不斷切換,說明nn的請求并發非常高,多執行緒之間鎖的背景關系切換已經成為了主要瓶頸,
所以當下主要思路應該落在如何減少NN的呼叫頻率上面,
4.Third Day:盡可能減少NN請求頻率
在現場的第三天,突然下起了暴雨,“愛就像藍天白云,晴空萬里,突然暴風雨”…一如我的心情,
為了減少NN的請求頻率,嘗試了多個方法:
(1)啟用錄信資料庫lsql的不同表不同分片功能
考慮到現場有4000多張表,每張表有1000多個并發寫入分片,有可能是同時寫入的檔案數太多,導致的nn請求頻率太高,故考慮將那些小表,進行分片合并,寫入的檔案數量少了,請求頻率自然而然就降低了,
(2)與現場人員配合,清理不必要的資料,減少hadoop集群的壓力,清理后hadoop集群的檔案塊數由將近2億,降低到1.3億,清理力度足夠大,
(3)調整一系列與NN有關互動的心跳的頻率:如blockmanager等相關引數,
(4)調整NN內部鎖的型別:由公平鎖調整為非公平鎖,
本次調整涉及的引數有:
dfs.blockreport.intervalMsec 由21600000L調整為259200000L (3天),全量心跳
dfs.blockreport.incremental.intervalMsec 增量資料心跳由0改為300,盡量批量一次上報 (老版本無該引數)
dfs.namenode.replication.interval 由3秒調整為60秒,減少心跳頻率
dfs.heartbeat.interval 心跳時間由默認3秒調整為60秒,減少心跳頻率
dfs.namenode.invalidate.work.pct.per.iteration 由0.32調整為0.15 (15%個節點),減少掃描節點數量
本次調整涉及的堆疊:
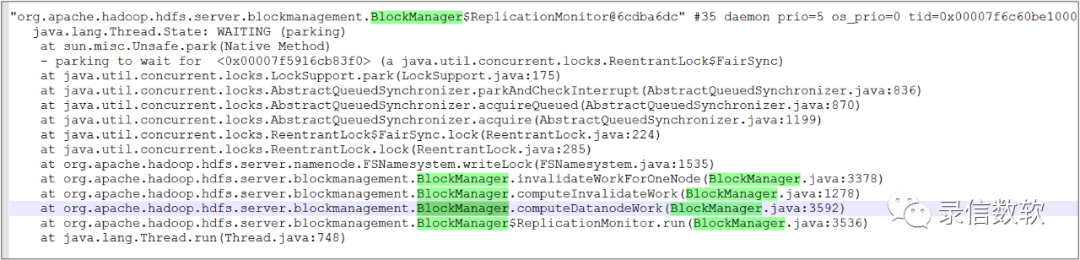
最終結果卡頓問題依然存在,本人已經黔驢技窮,人已經懵了,不知道該如何處理,
5.Fourth Day:無計可施,考慮建立分流機制
在現場的第四天,黑云壓城,暴雨臨門,當然這是當時的心里環境,實話實說當天天氣還是不錯滴,
拖著已經連續熬了三個晚上的疲憊身軀,第四天一早就跟公司和客戶匯報排查具體情況,也直接說了已經沒有任何的思路,希望能啟用B方案:
(1)啟用hadoop聯邦方案,靠多個namenode解決當下問題;
(2)立即修改錄信lsql資料庫,在一個lsql資料庫內適配hadoop多集群方案,也就是搭建兩個完全一樣的集群,錄信資料庫啟動600個行程,300個行程請求舊集群,300個行程分流到新集群,以達到減輕壓力的目的,
家里(公司)的意見是先回去睡覺,頭腦清醒時再做決定,
客戶這邊建議繼續排查,因為系統已經穩定運行一年多了,沒道理突然就不行了,還是希望深入研究一下,
就像是系統故障大部分一次重啟就能解決,我決定先睡會,期待醒了之后問題能夠迎刃而解,在我睡著的半夢半醒之中,我仿佛看見阿拉斯加的鱈魚正躍出水面,梅里雪山的金絲猴剛好爬上樹尖…還有那個站在hadoop之巔的男人——高高!
隨著高高出現在我的夢里(實際上并沒有…),我一個機靈趕緊起身,立馬給高高打了個電話,高高是我以前在騰訊時專門負責HDFS的大牛,他對hadoop的精通程度堪比我熟知各類防脫發竅門,而且上萬臺大集群的優化經驗,可遇而不可求,我想如果他也不能點播一二,恐怕就沒人搞得定了,我也不必白費力氣,
高高首先詢問了集群的基本情況,并給我多項有效建議,最讓我振奮的是根據高高的分析,我們的集群絕對沒有達到性能的上限,
6.The last day:對呼叫NN的鎖的每個函式進行分析
在現場的最后一天,白光萬道,紅霞滿天,終于有了解決方案的我心里暗爽,
這次沒有直接看jmx資訊,擔心結果不準確,采用的是btrace這個工具,排查具體是哪個執行緒頻繁給NN加鎖,導致NN負載如此之高,
花費了3個小時分析,最終令人驚喜的是發現processIncrementalBlockReport這個執行緒請求頻率非常高,遠遠高于其他執行緒,而這個執行緒不是datanode (dn)節點增量心跳的邏輯嗎?為什么頻率如此之高?心跳頻率我不是都改掉了嗎?難道都沒生效么?
仔細查看hadoop代碼,發現這個邏輯確實有問題,每次寫資料和刪資料都會立即呼叫,而我設定的那些心跳引數在客戶的這個版本的hadoop集群里并沒有這方面優化,設定了也沒用,于是緊急在網上尋找patch的方法,最終找到了這個,它不僅僅解決了心跳頻率的問題,還解決了加鎖頻率問題,通過減少鎖的使用次數,從而減少背景關系切換的次數,進而提升nn的吞吐量,
迅速打上此patch, 明顯發現NN吞吐量上來了,而且不僅僅是訪問NN不卡了,實時kafka的消費速度也一下子由原先的每小時處理40億,上升至每小時處理100億,入庫性能也跟著翻倍,打上patch后,此問題得到了根本的解決,
究其根本原因在于HDFS NameNode內部的單一鎖設計,使得這個鎖顯得極為的“重”,持有這個鎖需要付出的代價很高,每個請求需要拿到這個鎖,然后讓NN 去處理這個請求,這里面就包含了很激烈的鎖競爭,因此一旦NN的這個鎖被一些大規模的匯入/洗掉操作,容易使NameNode一下子處理大量請求,其它用戶的任務會馬上受到影響,這次patch的主要作用就是增量匯報的鎖修改為異步的鎖——讓洗掉、上報等操作不影響查詢,
具體詳細描述與改法參考這里:
https://blog.csdn.net/androidlushangderen/article/details/101643921
三、總 結:
最后,針對于這次性能故障的排查,我從問題成因和解決建議兩個方面總結一下:
1.問題成因
系統之前一直運行平穩,突然出現的問題的原因主要是因為以下幾個:
(1)用戶洗掉了大量檔案,造成hadoop壓力增大
近期硬碟快要滿了,集中清理了一批資料
最近hadoop不穩定,集中釋放了一大批檔案
(2)近期明顯的日常資料量暴增對hadoop調優后,重入資料,按日志進行資料條數統計,最近的資料規模增加很多
(3)消費資料積壓
本次調優程序中,由于資料積壓了很多天,導致kafka一直在滿速消費資料,而在滿速消費的情況下,會對nn造成較大的沖擊,
(4)快照和mover對hadoop造成的沖擊
清理快照的時候,釋放了大量的資料塊,造成資料的洗掉
mover新增了大量的資料塊,致使系統洗掉了大量的ssd上的檔案塊,且因節點數增多,心跳頻繁,瞬時都進行processIncrementalBlockReport對nn造成較大的壓力
2.我的幾點建議
(1)Never give up easily!
在排查的第四天,在嘗試過多種解決方案之后,我也想過要放棄,并且認為這次的性能故障是無解的,在這種時候我們不妨多與同事,哪怕是以前的同事領導討論討論,也許會帶來不一樣的思路和啟發,要相信群體的智慧!
(2)一定要了解的hadoop原理,這也是本次hadoop調優的關鍵點
1) 當我們在HDFS中洗掉檔案時:namenode只是把目錄入口刪掉,然后把需要洗掉的資料塊記錄到pending deletion blocks串列,當下一次datanode向namenode發送心跳時,namenode再把洗掉命令和這個串列發送到datanode端,所以這個pending deletion blocks串列很長很長,導致了timeout,
2)當我們匯入資料時:客戶端會將資料寫入到datanode里,而datanode在接到資料塊后,會立即調processIncrementalBlockReport給NN匯報,寫入資料量越多,越頻繁,機器數量越多,行程越多,呼叫NN就會越頻繁,所以本次的異步鎖patch,在這里才會有效果,
(3)最關鍵的一點:千萬不要使用hadoop2.6.0這個版本!!!
用hadoop官方的話來講,別的版本都是存在a few of bug,而這個版本存在a lot of bug,所以回去后第一件事要督促客戶盡快升級換版本,
PS:如果你還想讓你的Hadoop性能更上一層樓,建議選擇更新至Hadoop3.2.1版本,且啟用聯邦模式,為此我們已經整理好了可能會遇到的問題及注意事項,
如果你還想再一次突破性能瓶頸,我們也準備好了教你如何提升router的性能瓶頸的實踐文章,
歡迎關注,期待后續的內容更新,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/262884.html
標籤:其他
下一篇:Flink常用操作命令