本文主要介紹Transwarp的etl工具——Transporter,本文依托于星環的官方檔案,通過一個簡單的實體來讓大家熟悉Transporter的使用,關注專欄《Transwarp系列》了解更多Transwarp的技術知識~
目錄
一、Transporter簡介
1.1 簡介
1.2 Transporter的特點
二、Transporter實體
2.1 案例一
2.1.1 業務需求
2.1.2 業務實作
2.2 案例二
2.2.1 業務需求
2.2.2 業務實作
一、Transporter簡介
1.1 簡介
Transporter是一個資料etl工具,支持從不同資料源獲取資料,對資料的復雜轉換操作,并最終將資料落地成不同格式,Transporter左側連接資料源,如關系型資料庫,右側連接目標系統,如Inceptor,支持用戶將資料從RDBMS遷移到Hadoop,再進行資料分析和挖掘作業,
1.2 Transporter的特點
1、支持豐富的資料源
Transporter支持跨集群的資料匯入,并且可直接從Oracle/DB2等傳統關系資料庫將資料匯入至TDH,同Sqoop相比,可以在不失效率的情況下簡化繁瑣的資料流定義步驟以及復雜的型別轉換等問題,支持匯入CSV、定長檔案、JSON、XML等檔案,同時支持匯入OGG、Shareplex、DataStage產生的增量檔案,實作準實時的資料同步,此外,還支持通過Kafka等方式讀入流資料,
2、支持豐富的匯出格式
用戶可以通過Transporter直接匯出資料至傳統關系資料庫、ElasticSearch,以及實作跨集群匯出,Transporter支持多種資料匯出格式,如CSV、JSON、XML,并且支持Inceptor中所有型別的表:普通ORC、ORC交易表、Holodesk、Hbase、Hyperdrive,
3、支持多種資料轉換操作
提供多種常見的資料轉換操作,幫助實作資料的清洗,加工,其中的關鍵操作有:欄位映射功能、資料關聯、集合操作、聚合操作、過濾、去重,
4、輕量的應用
采用Web互動的方式,實作資料流的設計,Transporter只是用于資料流設計和調度作業流的服務平臺,本身不包含執行引擎,不負責任務實作,而是將作業任務提交到Inceptor或者其他計算引擎來完成,因此是極為輕量的應用,
5、高度并發
利用分布式集群進行資料流的并行計算,自動分析資料流依賴,實作資料流作業中最大可能的并行化,
6、高吞吐
擅長大資料量的同步,峰值資料吞吐率可達到40M/秒/節點,
7、資料質量和安全保障
提供事務級別的資料同步,確保目標表與原表擁有相同的資料一致性,另外還提供了完整的權限控制機制,用于保證資料的安全,
二、Transporter實體
2.1 案例一
2.1.1 業務需求
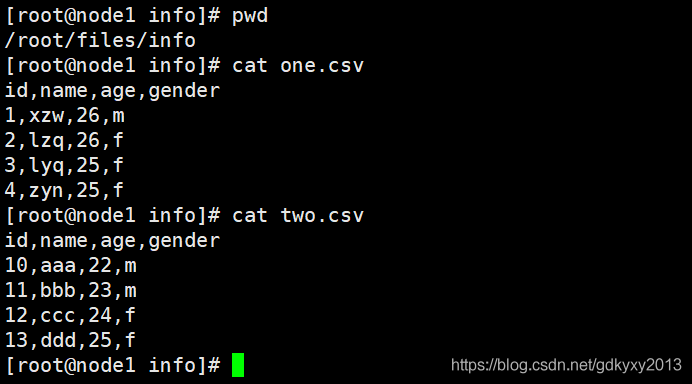
現在有兩份人員名單,需要將其合并后寫入Inceptor,
2.1.2 業務實作
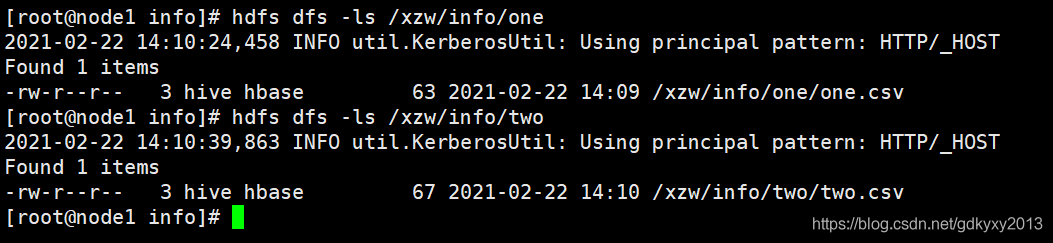
1、為了方便測驗,首先將兩份資料上傳到hdfs的目錄下,如下所示 :
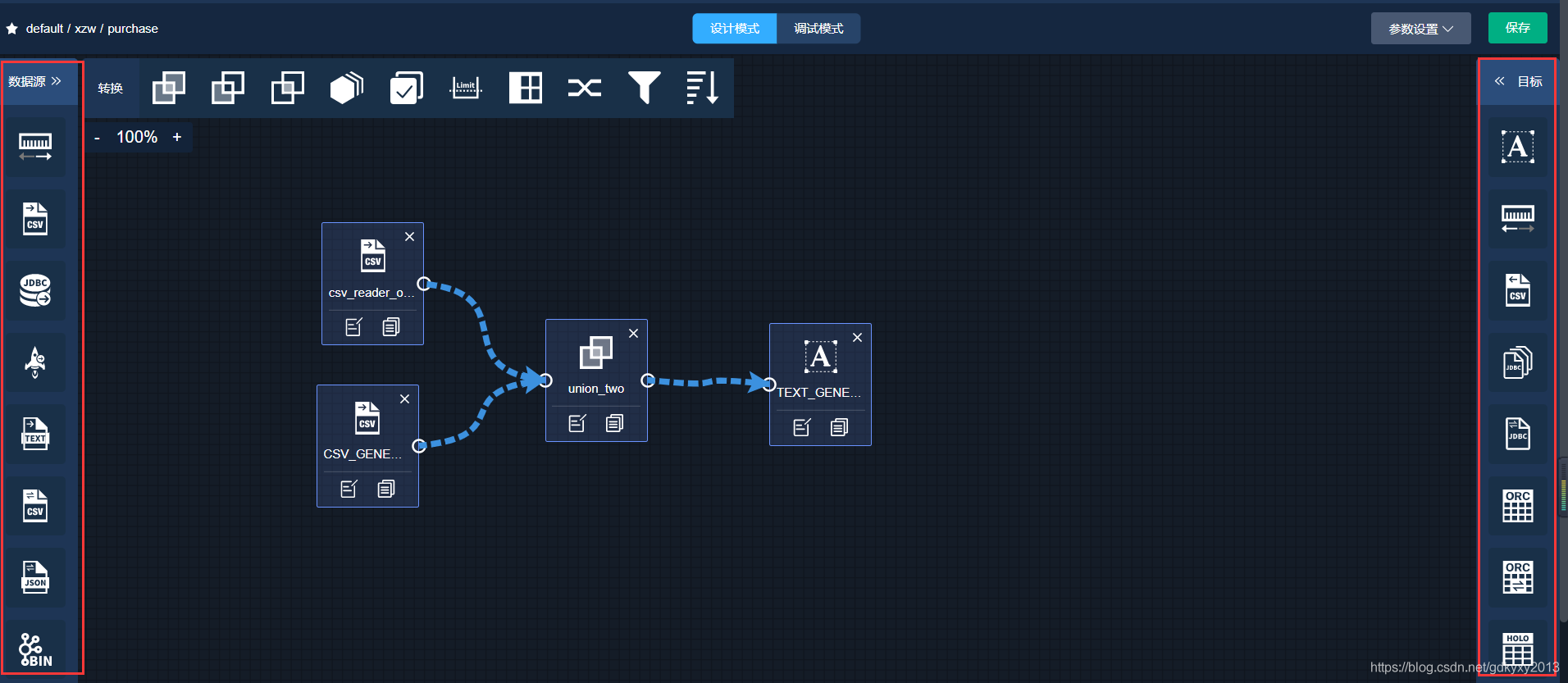
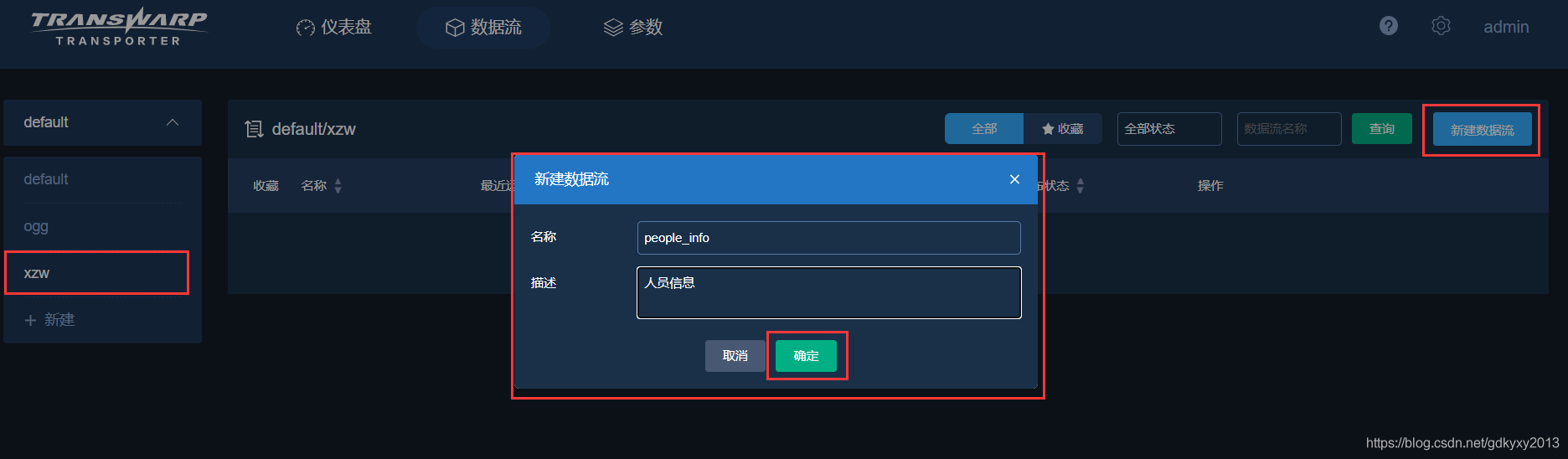
2、新建資料流,進入設計模式,
3、選擇并拖出CSVReader模塊并修改Reader引數,
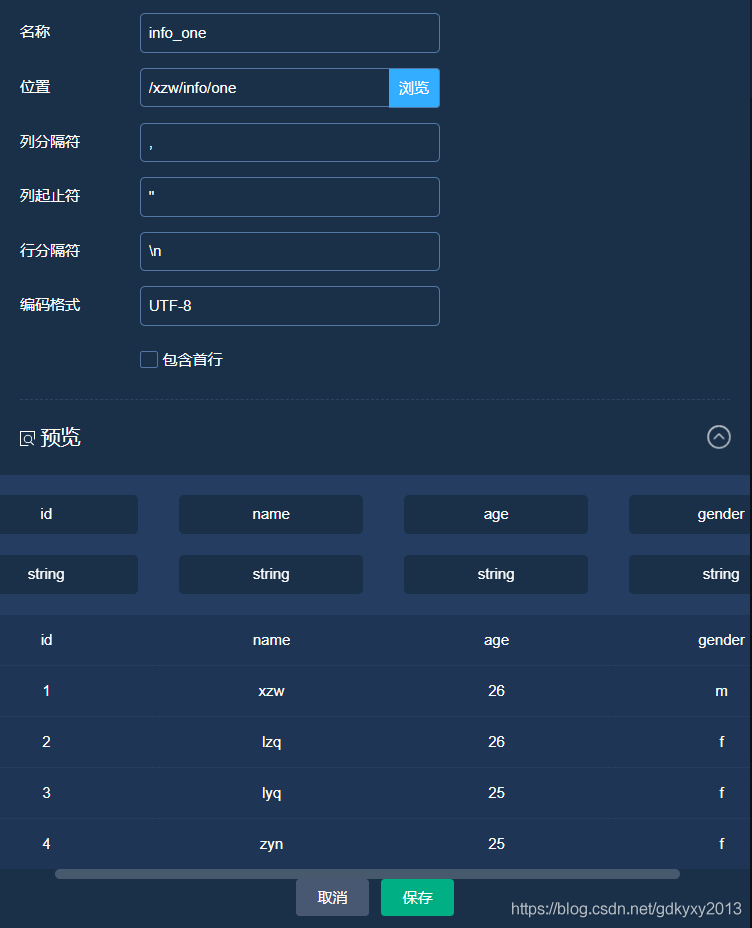
同樣的方法將two.csv檔案讀進來,如下:
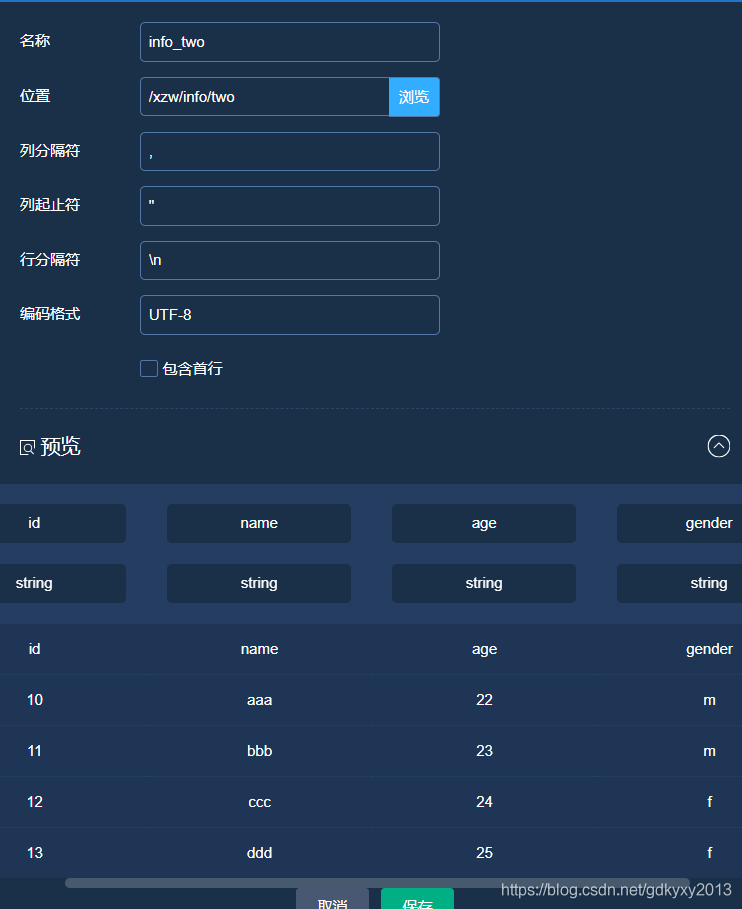
4、選中轉換模塊中的union模塊,并連接資料源模塊與union模塊,
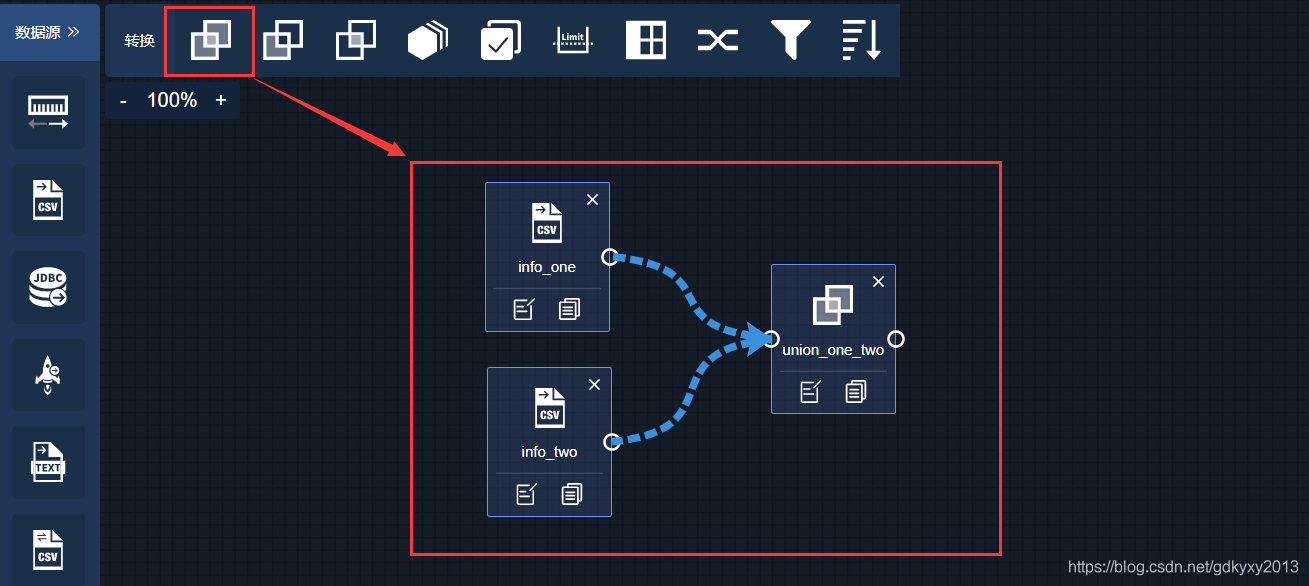
5、拖出TextWriter,并連接轉換模塊與目標模塊
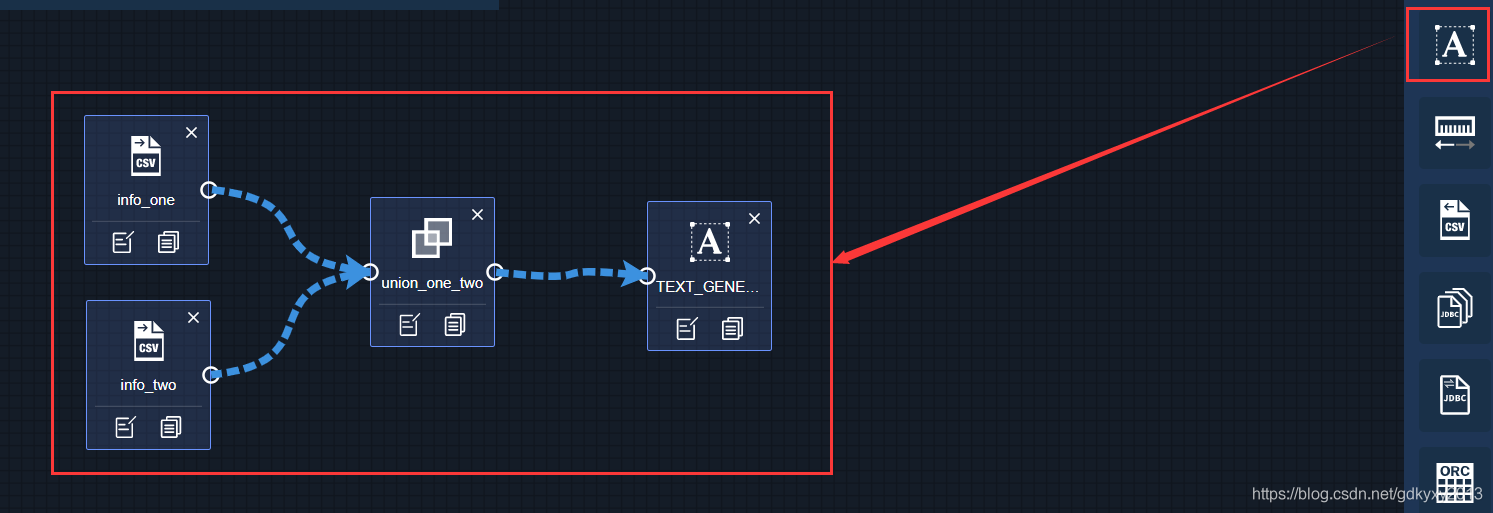
6、修改TextWriter的引數
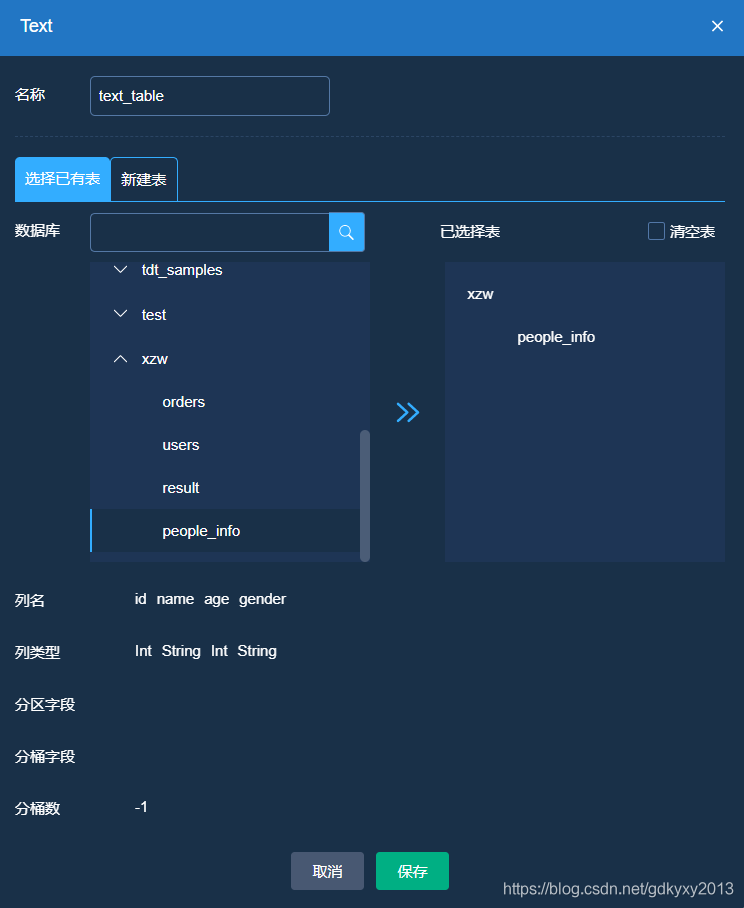
7、完成后,點擊右上角的保存按鈕進行保存,并進入除錯模式,
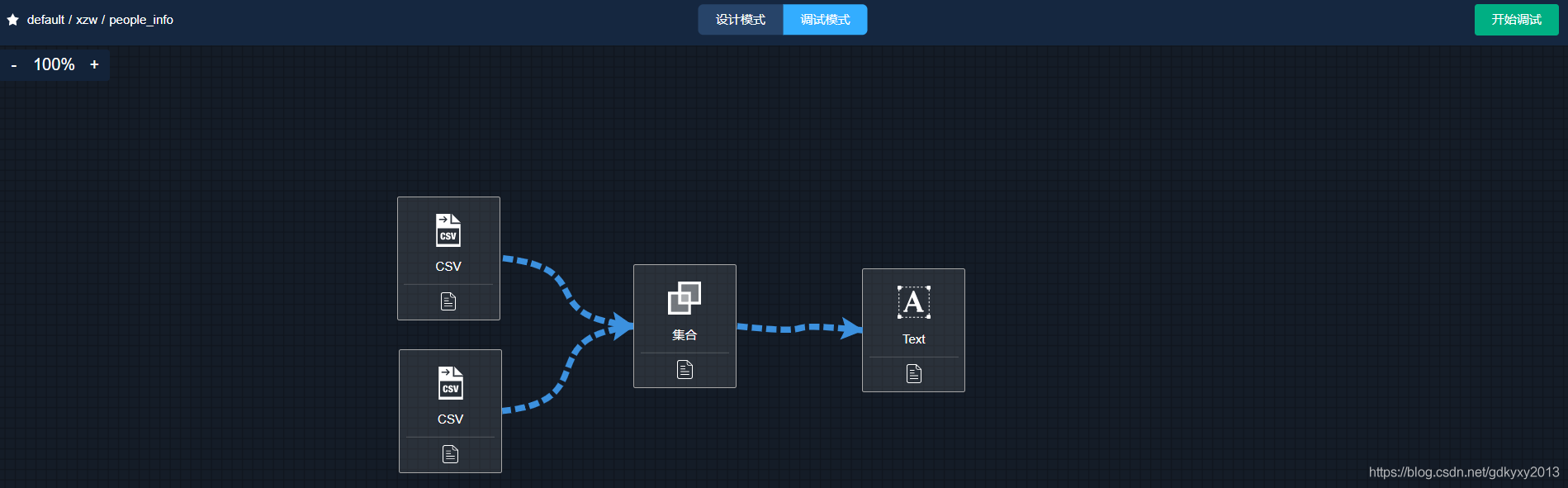
如果除錯沒有問題,此處所有組件圖表均為綠色,
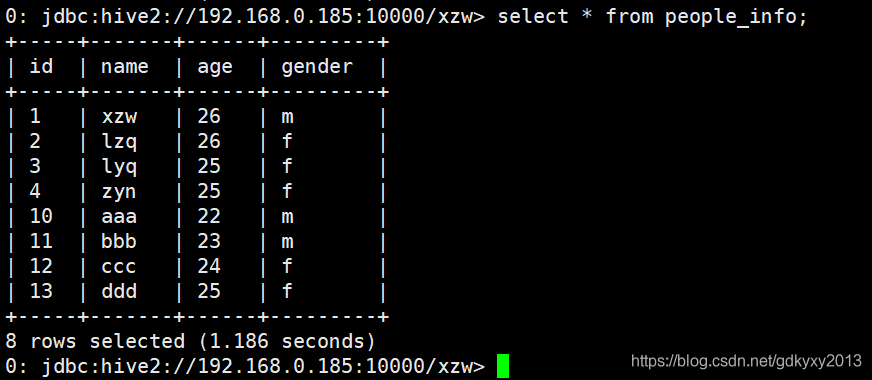
查詢資料庫中的資料可以發現資料已經入庫到對應的表中:
8、除錯無誤后點擊下面的圖表進行發布,
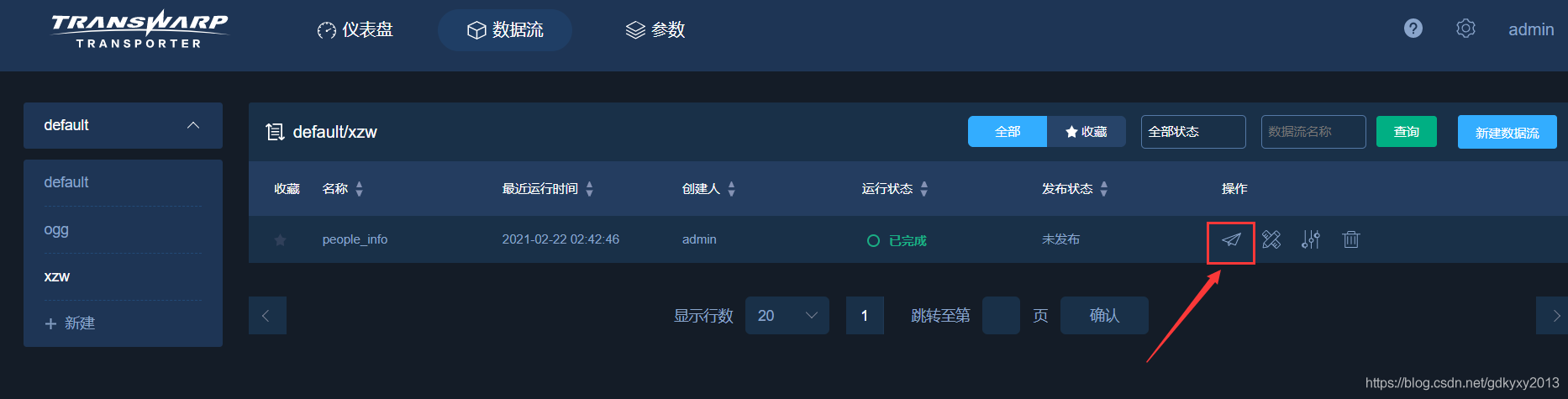
2.2 案例二
2.2.1 業務需求
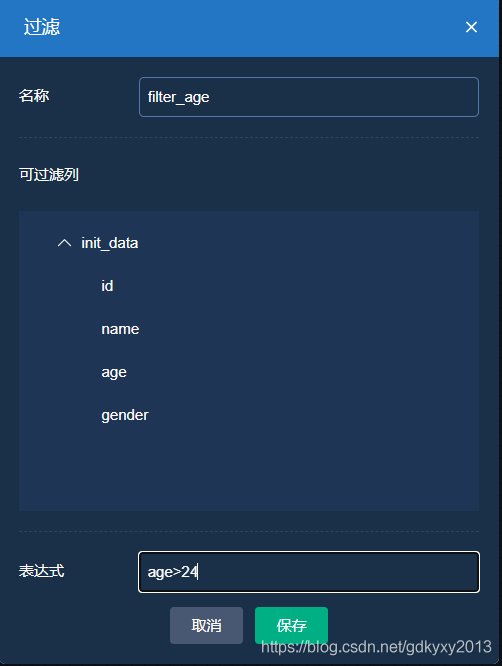
查詢得到年齡大于24歲的人員名單并將資料匯出到csv檔案,
2.2.2 業務實作
1、同樣的,新建資料源
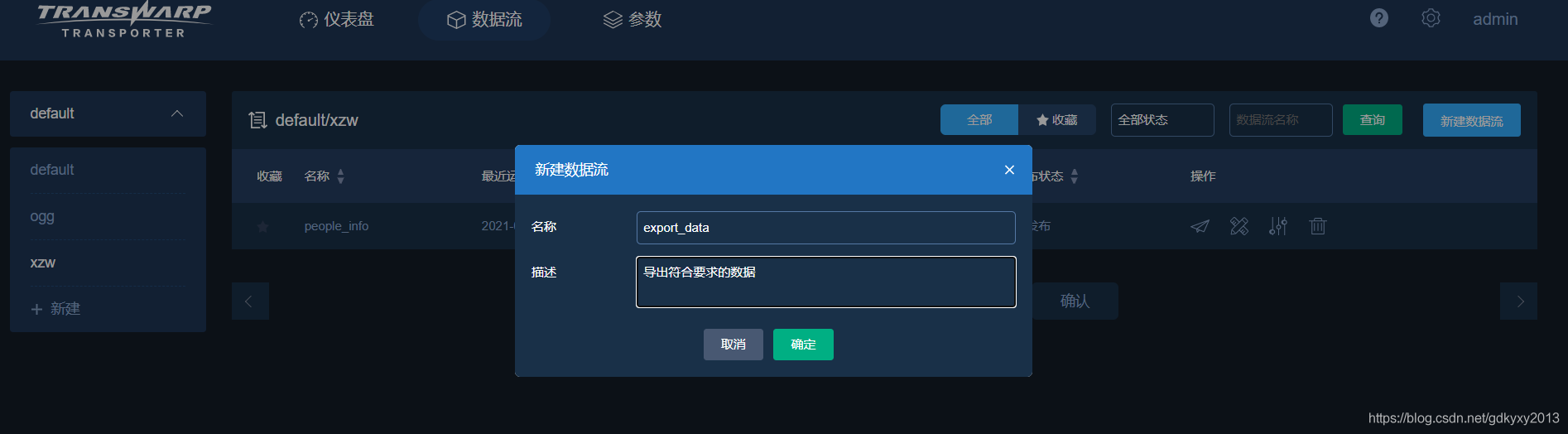
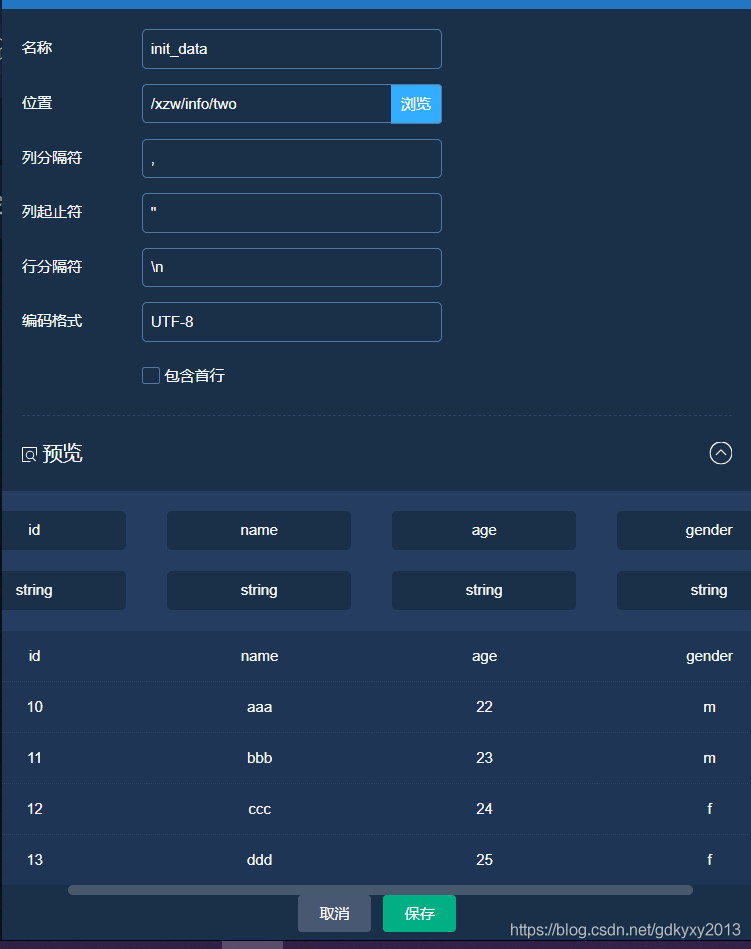
2、選擇CSVWriter模塊并修改引數,如下:
3、選擇過濾模塊并編輯引數
4、選擇CSVWriter目標模塊并編輯引數
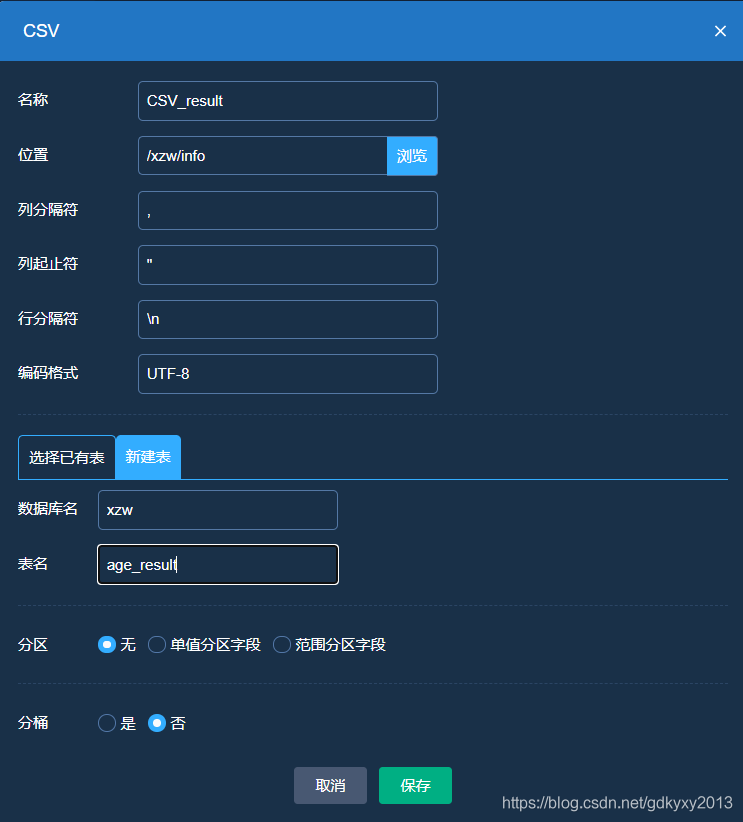
5、保存并除錯,發現資料已經匯出到對應的目錄中

以上就是本文的所有內容了,通過兩個簡單的實體,大家一定對Transporter有了一個初步的認識,本文到此已經接近尾聲了,你們在此程序中遇到了什么問題,歡迎留言,讓我看看你們都遇到了哪些問題~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/262894.html
標籤:其他
上一篇:綜合練習
下一篇:JQuery 選擇器重點內容