前言
博主去年參加了一系列比賽,取得了還可以的成績,拿了幾個國內比賽的top10,也拿到了kaggle的銀牌,博主的夢想是有一天能夠成就kaggle GM,成為一流的Data Scientist,有個遺憾的事是參加完這些比賽以后并沒有好好的分析、學習其中出現的各種優秀的思路和技巧,博主并不想錯過這種吸前排"歐氣"的機會,所以打算寫一個系列,記錄我們能從這種競賽前排選手的作品中,學到哪些內容,畢竟學到了就是自己的了,
博主只記錄和學習很新的trick和模型,這些競賽也都是20年的,所以很多trick和method都很新,比如模型涉及yolov5、efficientdet、doubleunet、HRnet、vision transformer,trick涉及自適應anchor、nosiy student、auto augmentation等等,有沒有引起愛學習的你的興趣?希望大家看完也有所識訓,

第一篇帶來的是20年參加的第一個競賽是違法廣告的目標檢測類競賽,違法廣告分為一店多招、遮窗、非合法交通標志三類,需要我們用目標檢測技術去識別出來,
首先貼上競賽地址,沒有參加的小伙伴可以先了解下賽題,再看分享會比較好:
賽題傳送門
我們最終取得了top10的成績,用了yolov5+efficientdet的ensemble,當時限于水平用的trick都比較中規中矩,值得一提的創新點我會放在最后提一下,我們先看看前排選手值得學習的內容,
第六名 (吸到1點歐氣)
1.目標檢測=>multi-head
目標檢測任務可以拆分為分類+目標檢測,二分類模型判斷是否是純背景,目標檢測模型則在分類結構的基礎上去具體定位前景框的位置,(寫到這里突然想到這樣做不就是把任意模型強行改成two-stage么,不就是faster rcnn的思路么,可見這些思路都是互相融匯貫通的),在具體實踐上可以使用單模型做multi-head也可以單獨訓練分類模型+檢測模型,具體哪種思路好要看實驗結果,在這個比賽中獲勝選手是采取了multi-head的思路,
multi-head的位置:選手采用了efficientdet的模型,在BiFPN Layer的后面接了二分類的head,最終成績第六名,這個比賽的評判結果是0.2ACC + 0.8MAP,ACC只考慮前景背景的判斷精度,所以在這個標準的基礎上,我覺得二分類的head剛好加強了這個部分,應該是有一定積極作用的,這種multi-head的思路我在kaggle比賽中也經常見到,值得研究的是如何更好的獨立訓練各個部分還是端到端的訓練整個網路,這里我覺得可以參考faster-RCNN論文里的訓練技巧,反復迭代訓練(這部分未詳細驗證),
專家對這個選手的點評是遮窗廣告,廣告位置一變就可能從違法變為不違法,和窗戶的位置有很大關系,如何把localization做的更好呢?大家也可以思考下,
第五名 (吸到3點歐氣)
1.架構分析
這個選手的架構如下所示:
| backbone | neck | RPN | header |
|---|---|---|---|
| resnet101+deformable conv | fpn | rpn | cascade RCNN |
這個架構中可以學習的是在backbone的最后兩層采用deformable convolution,這個我認為和使用dilated concvolution有異曲同工之妙,dilated convolution的作用就是增大感受野,在使用dilated convolution的時候要注意使用HPC設計,避免棋盤效應,比如resnet系列最后采用125,125的疊加,使用deformable convolution可以自適應感受野,避免使用dilated convolution不好控制或者說找到最佳的感受野的復雜性,FPN可以有效在多尺度上進行預測,尤其是增加小目標的識別能力,cascade RCNN在很多比賽中都表現良好是一個必備的值得測驗的baseline之一,
2.類間不平衡
對于類間不平衡,選手是在loss上進行了加權,這塊沒有詳細說明,但是從效果看提升很大,我在競賽中也發現,如果不進行類別不平衡的處理,那么基本上數量占比很小的類別的AP是非常低的,我們隊伍采用了另一種思路,最后會提到,加權的比例可以觀測loss或者是計算GT中類別的比例來決定,是可調引數,
3.全域資訊的提取
這里參賽選手講的不是很細,但是思路是這樣的:因為two-stage的model會先通過RPN獲取ROI,再在ROI上進行detection,這樣就會忽略掉一些全域的資訊,對這個賽題來講,很明顯的是背景的影響是巨大的,比如說遮窗廣告,很明顯的會受到窗戶位置影響,multisigns的廣告之間互相作用,
所以在這里選手對于全域feature map進行提取(這里號稱是用dilated conv提取了一下)疊加到ROI上面,增強了ROI中對于全域資訊的能力,
4.其他idea
- 選手通過EDA分析,發現框的比例多種多樣,于是增加了base anchor的數量,
- 使用了OHEM:OHEM的思路很簡單,就是在計算loss后,對于batch內的樣本進行排序,最不準的樣本要繼續加入訓練,這樣使得模型多“看”困難樣本,從而增強對于這些樣本的識別能力,
專家大佬點評:一直在問訓練集和測驗集分布不同,如何進行分布補償的問題,選手沒有考慮,這塊我也不是很了解,有讀者懂這個點的可以留言交流一下,
另外專家建議先區分非交通性的指示牌和其他的廣告型別,
第四名 (吸到4點歐氣)
1.類間不平衡
對于類間不平衡,選手是采用了在線的類別重采樣,從sample的角度去解決類別資料不平衡的問題,
2.ATSS 自適應anchor assign演算法
關于使用這個trick的思路是這樣的:首先選手觀察了GT的資訊,發現存在很多類的anchor比例,所以第一個思路是增加更多的anchor,但是選手認為這種做法有幾個壞處:
- 進一步的增加了負樣本的比例,加劇了正負樣本的不平衡問題,
- 增加了模型的復雜度,
- 如果采用傳統的kmeans聚類出anchor的話,很容易產生過擬合的風險,因此選手采用了ATSS的演算法來取代聚類anchor的方法,
ATSS是一種基于retinanet(anchor based代表)和FCOS(anchor free中center point的代表)來驗證的自適應anchor演算法,目的是縮小anchor based和anchor free演算法之間的精度差距,作者通過進行消融實驗逐步減少兩類演算法的差距,最終確定了正負樣本的定義不同是導致anchor based和anchor free之間效果差異的主要問題,
ATSS從每個尺度的feature map上通過不同anchor與GT box的中心點距離來選擇一批最近的anchor,然后通過計算IOU的均值和方差來“自動”生成閾值,再根據這個閾值來判斷是正樣本還是負樣本,整個程序中的均值和方差都是一直在變化的,比如一批anchor的IOU均值比較大的時候,就說明這批樣本和GT的重疊度普遍較高,那么閾值自然也要增加來獲取更好的正樣本,ATSS只有一個引數k,就是每個level上預置的anchor數量,實驗證明這個k是比較魯棒的(意味著其實是超引數free的東東),在作者的實驗中最佳值是9,
下面是這種方法的論文和一篇不錯的分析,
1.ATSS論文地址
2.知乎分析推薦
3.ATSS原始碼實作
推薦大家閱讀下論文和知乎的中文決議,
這里就很有討論點,比如two stage和one stage,anchor based和anchor free之間的區別、聯系和共通性,作者寫到這里突然想到如果使用ATSS+multihead,既通過ATSS來彌補了anchor free和anchor based的gap,又通過multi-head去汲取two stage的優勢,是否能進一步提升模型精度?
3.腦洞大開的multi-signs留一半策略
這個點就是選手通過認真觀察資料,提出的腦洞大開的一種策略了,我個人非常佩服這種腦洞,我們都知道multi-signs是一店多招的違法廣告型別,這些廣告牌都是成對或者更多以一組組的形式一起出現的,這些成對出現的multi-signs的廣告牌在內容上具備一定的相似性,但是很難去使用到這種相似性,所以經常會出現其他類別的違法廣告或者未違法的店鋪招牌被錯誤的分類識別為了multi-signs類別,
這個選手在此基礎上進行了一種非常有創意的訓練思路,就是把multisigns成對出現的招牌中的其中一個用純色去填充,這樣可以迫使模型去學習multi-signs內容上的細節關聯,減少把正常店招或者不相干的廣告牌識別成multi-signs的概率,
4.SAC:可切換的空洞卷積
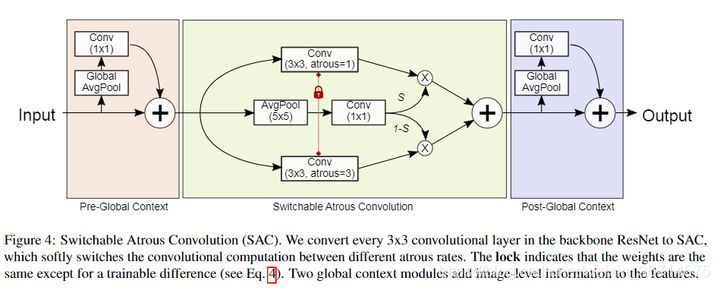
這個模塊是DetectoRS中提出來的,我看了下就是通過不同dilation rate的空洞卷積提取多尺度的特征,再進行融合,有點像googlenet那種并行結構,然后又加了一個平均池化的注意力機制,注意力做了個“分叉”,先上論文地址和知乎上的推薦分析:
論文地址
知乎分析推薦
5.其他idea
- 加入了正常的(純背景圖片)進行訓練,來進一步提升有無違法廣告的判斷,這點實際上幫助這個team漲了很多個點,
- 針對GT的多尺度復雜問題使用了疊加的BiFPN結構來增大不同尺度之間的features的融合,
專家點評:問有沒有進一步研究訓練集和測驗集的資料分布之間的不平衡的問題,選手表示未考慮這方面,
第三名 (吸到2點歐氣)
1.資料增強
這個選手做了大量的資料增強,涉及到的有:
- grid mask
grid mask是一種基于分析cutout存在的問題而提出的資料增強手段,因為cutout容易出現把整個樣本切掉或者是一點樣本都沒有切掉的現象出現,作者認為避免過度洗掉或保持連續區域是之前類似演算法存在的核心問題,如果洗掉了過多資訊,可能破壞掉原始資料,造成noisy data;如果洗掉過少資訊,可能沒有起到資料增強,改善模型魯棒性的目的,
grid mask通過形成與原圖解析度一致的gird(0,1)網格與原圖進行相乘,達到類似正則化的目的,
憑借grid mask演算法,作者在imagenet上獲得了超過auto-augment的提升(1.4個點),
下面是知乎上一篇關于gird mask演算法的推薦,大家可以查看,
知乎分析推薦
這個選手進一步借鑒了gird mask的初衷,在這個比賽中統計了最小GT框的長寬,避免出現grid mask遮蓋了整個GT的情況出現,
2.auto augment
選手使用了google在coco資料集上搜索出的auto augment策略,涉及到強化學習,能夠有效的訓練集和測驗集之間的樣本分布漂移問題,
這個點博大精深,我還不是很了解,在此不過多的評論,但是現場專家很重視強化學習帶來的優勢,
2.其他idea
- 使用了cascade RCNN作為baseline,backbone是resnest101,
- 使用了Deformable Convolution來自適應提取感受野,這個不少選手采用了,
- 因為樣本間難以區分,所以使用注意力機制去增強細粒度的特征提取:SE、CBAM等,值得注意的是選手沒有在backbone的位置去增加注意力機制,而是在ROI之后增加,起到了對feature進行refine的作用,
- 針對一店多招的目標之間的相似性,引入了一個Feature Similarity Check模塊,這塊選手沒有詳細解釋,大概就是目標feature之間進行余弦距離的計算,保留大的confidence,其余的與大目標進行相似度計算,去除小于閾值的,(個人感覺很難實際操作,評委也說了這個問題,因為一店多招未必絕對的在內容上具備高相似度,)
第二名 (吸到2點歐氣)
1.類間不平衡
發現不同組選手對于類別不平衡的問題采取的方案都是各式各樣的,前面已經提到了有loss加權、線上重采樣的方案,第二名的方案里是只針對數量少的影像類別進行離線的資料增強,擴充樣本,最后我還會提到我們組發明的一種新的資料平衡方案,
2.其他idea
- 發現資料集中部分目標是有重疊的,因而引入了mixup策略來緩解重疊的問題,(這是一般使用mixup的借口,哦不對,初衷,whatever)
- res2net作為backbone,res2net在一眾比賽中都表現比較出色,可以作為重點測驗的backbone之一,另一個是senet,
- 沿用了FCOS的架構+GCnet的注意力機制+Deformable Convolution,
- 使用了基于邊框融合的非極大值抑制的手段(WBF),
專家點評探討了接入OCR網路的可能性,推薦了一篇論文,用以解決形變下的文字識別,下面附上論文地址,我對于OCR了解較淺,就不盲目分析了:
Mask TextSpotter: An End-to-End Trainable Neural Network for Spotting Text with Arbitrary Shapes
第一名 (吸到3點歐氣)
筆者是邊重新聽譯答辯現場錄像邊寫下這篇博客,邊回顧各種論文和材料,到這里已經持續寫了六七個小時了,碼了7k個字了,但是despite the tiresome,我們下面來振作一下精神,重點看下這個比賽的關于會給我們帶來什么知識吧:
1.難點分析
這個選手對于賽題難點的剖析做的非常不錯,這種思路值得借鑒,
首先這組選手剖析了這個賽題的一個難點,就是目前的目標檢測網路,對于類別的判斷,更多是focus框內的特征,而較少的收到背景影響,這就和一般的分類任務有了明顯的區別,一般的分類任務對于背景的變化是魯棒的,比如一只貓不會因為從桌子上變到草地上就變成了一只狗,但是這個比賽最致命的點就在于,它的前背景的類別(違法還是不違法)、類別間(一店多招、遮窗、非交通指示牌)都是嚴重依賴背景的,
比如遮窗廣告依賴背景是窗戶;multisigns在位置上有互相關聯,屬于框與框的關系;非交通性指示牌更多的是在道路上等等,這些顯然都不能單純的依賴框內的特征進行判斷,
我覺得這個思路是非常有道理的,
對于上面這個問題,選手做的嘗試是在提取ROI 之后,那這個ROI的size擴大1.5x,以融合到更多的背景資訊輔助判斷,
2.類間不平衡
這里只是提一下,選手解決類別不平衡的手段是Focal loss,這是很常見的思路,
但是大家可以總結下僅僅這個比賽前六名就有三種不同的解決類別不平衡的思路,我覺得復盤起來非常過癮,
3.其他idea
- multi-head/分類+檢測雙模型處理區分分類任務和檢測任務,選手最后選擇了multi-head的思路,
- atss+resnet50+FPN
- SEPC(尺度均衡空間金字塔結構)
- 采用了GIOU loss
最后附上冠軍的CSDN博客總結:
冠軍總結傳送門
放一張冠軍的漲點圖:
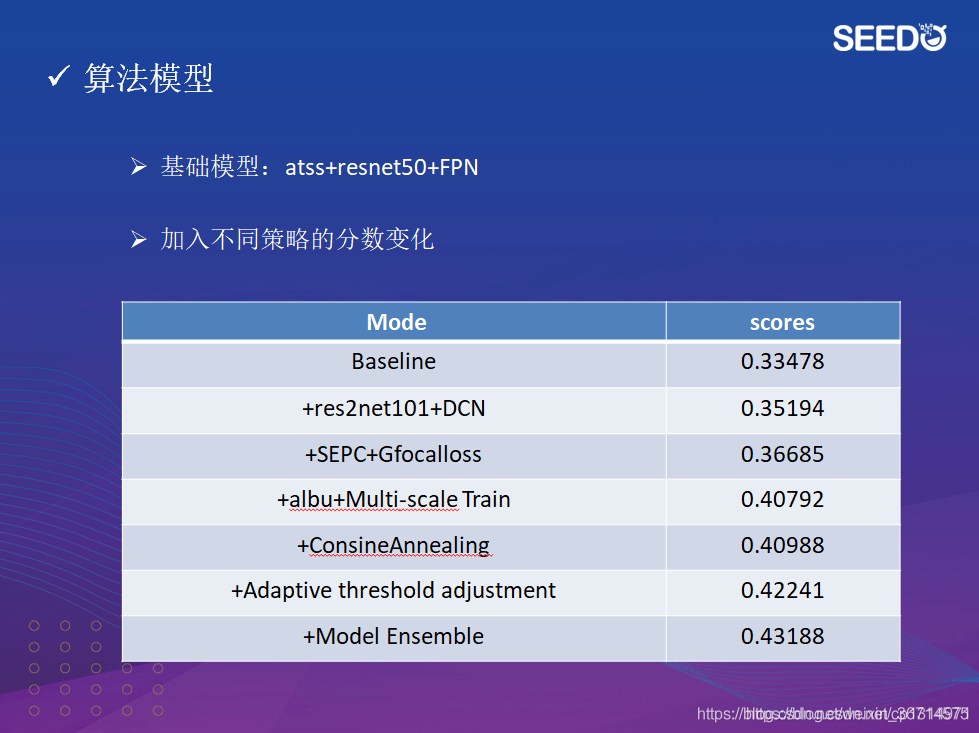
對于還有幾個點沒有展開,比如auto augment、SEPC、SAC等等,今天持續寫了七八千字,實在是寫不動了,后續會展開詳細敘述,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/263021.html
標籤:AI
上一篇:IIC驅動XFS5152CE模塊