背景:本文起源于我的碩士畢業論文,主要研究新能源汽車供應鏈主體之間的博弈問題,其中一個關鍵內容是制造商和經銷商之間的演化博弈,具體來說,是兩個博弈成員,每位成員有兩個策略,是典型的非對稱博弈,
因此,寫下這篇文章的目標是:1、整理演化博弈的研究思路 2、熟悉Matlab的使用 3、簡介演化博弈代碼包
一、演化博弈的介紹
1.1 演化博弈與傳統博弈的區別
演化博弈區別于傳統博弈的地方是,關于博弈主體的假設條件不同,
a)演化博弈:博弈主體是有限理性的,需要在博弈的程序中學習/模仿不斷調整策略,最后達到均衡,
b)傳統博弈:博弈主體是完全理性的,在博弈程序中能一次性做出最佳決策,即達到均衡,
因此,演化博弈在分析實際問題時,具備更強的解釋性,也更加貼近現實情況,
1.2 演化博弈的基本內容
根據學習群體的大小和學習速率的不同,主要將演化博弈分為了兩種:
a) 基于最佳反應動態(Best Response Dynamics)的演化博弈
b) 基于復制動態(Replicator Dynamics)的演化博弈,
由于我的研究問題涉及的是大群體間的博弈問題,因此我使用的是第二種基于復制動態的演化博弈模型(以下簡稱RD),對實際問題進行刻畫,通過復制動態方程描述采取不同策略的群體比例的變化,
1.3 基于復制動態的演化博弈模型的例子
下面以對稱博弈為例,簡述RD,
通常,有兩個因素影響博弈方的學習進化速度:1)模仿物件的數量,即博弈方對應的比例情況;2)模仿物件的策略收益超過平均收益的大小,上述兩點分別決定了進化的難易程度和模仿的激勵大小,
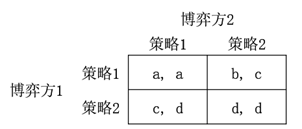
假設在一個足夠大的群體間進行博弈,采用策略1的群體比例為x,采用策略2的群體比例為1-x,采用兩種策略博弈方的期望收益和群體平均收益分別是:
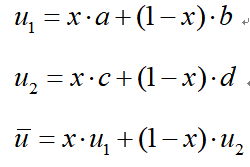
因此復制動態方程可以用下面的動態微分方程表示:
![]()
接下來研究的問題是關于非對稱博弈問題,因此,涉及兩個復制動態方程,會稍微復雜一點,但演化博弈的基本原理相同,
二、Matlab的基本使用
我對于Matlb的接觸是從大四開始的,但是研究生階段基本沒有使用Matlab這個強大的工具,現重新撿起來發現,這個軟體的功能確實強大,因此,對Matlab編程并不熟練的同學,也可以直接使用第三部分的演化博弈代碼,
這個演化博弈的工具是一個名為PDToolbox_matlab-master的程式套組,大致包含這些檔案:
第一步:下載PDToolbox_matlab-master壓縮包,并解壓到你的熟悉的位置,
第二步:打開Matlab,將上述壓縮包添加到路徑,如圖
至此,關于Matlab的操作就算告一段落了,
三、演化博弈工具包PDToolbox_matlab-master的使用
據上,我研究的是雙主體雙策略的博弈問題,對應使用test2.m檔案,下面是關于test.2中的一些代碼解讀:
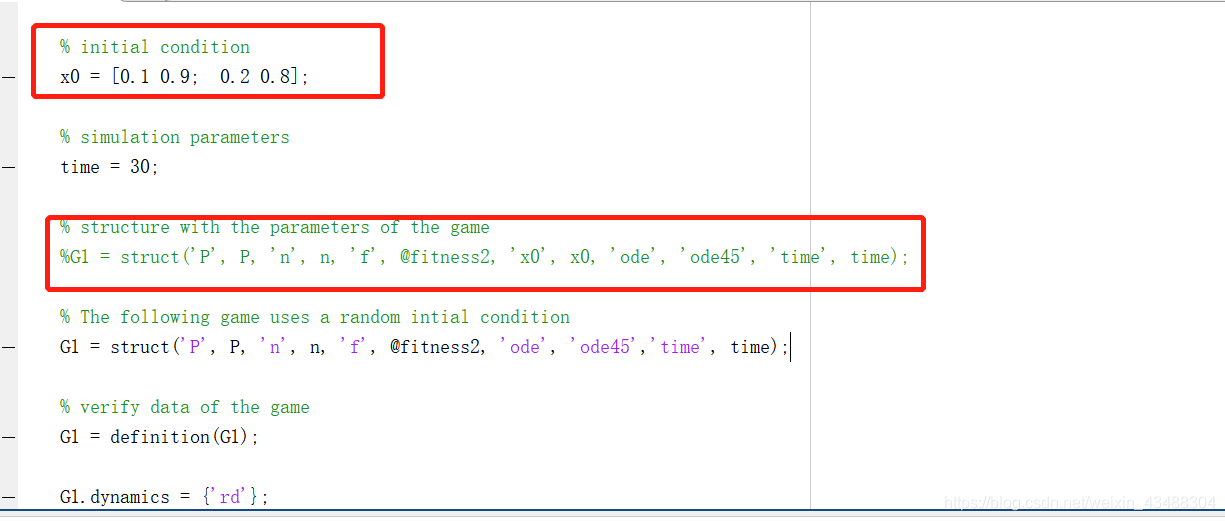
上述紅框中的代碼是演化博弈中的關鍵引數,X0是一個2*2的矩陣,是演化博弈群體的初始比例,
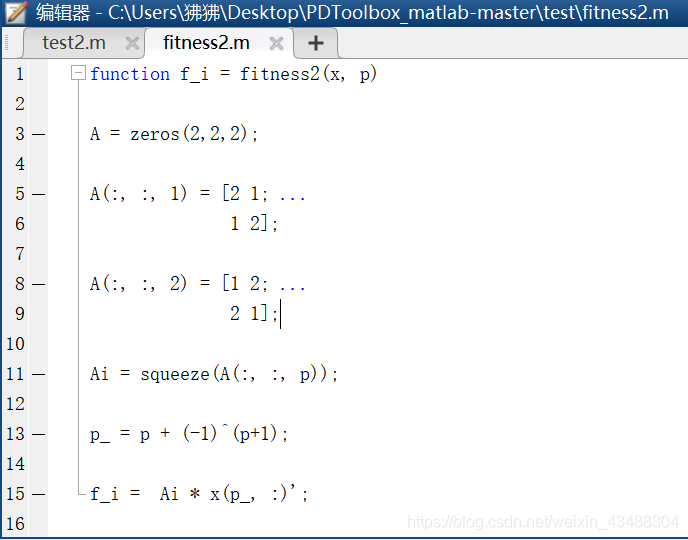
關于支付矩陣的設定,如上代碼是使用的fitness2.m檔案,
對應使用RD之后的演化軌跡如下:
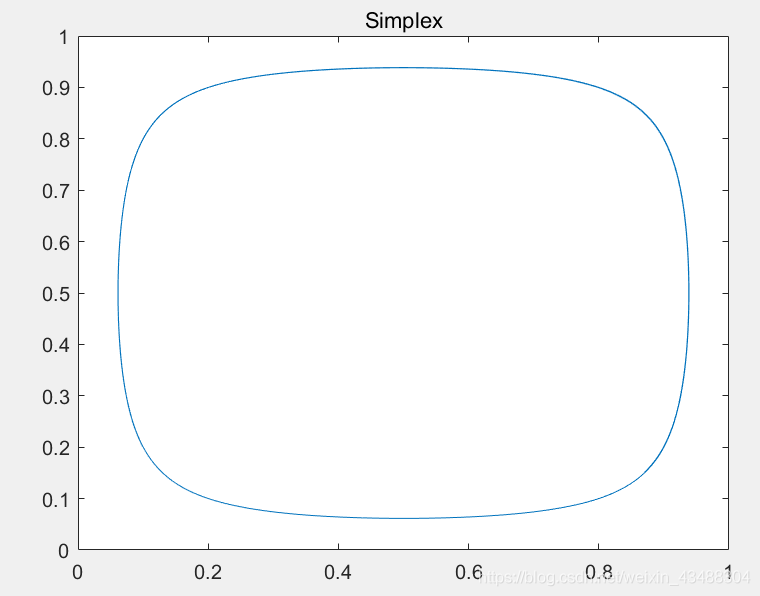
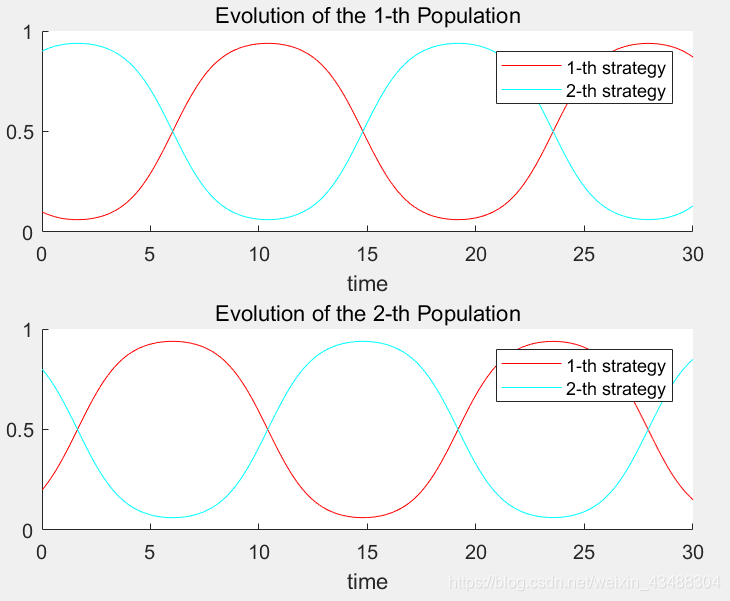
上述影像的意思是博弈雙方隨演化的進行,未能達到均衡狀態,采取策略的群體比例會一直呈現規律波動,
使用bnn dynamics(Brown-von Neumann-Nash Dynamics )之后的演化軌跡如下:
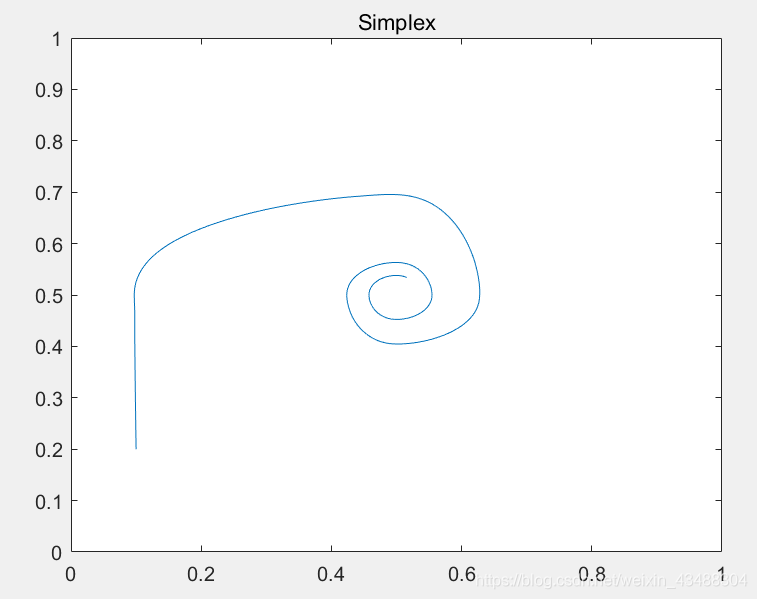
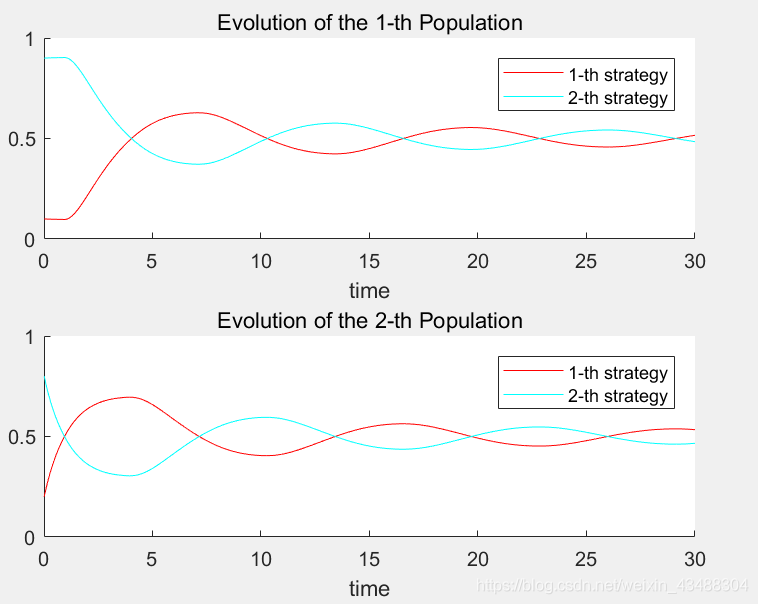
說明兩博弈群體由最初的0.1和0.2的比例,逐步收斂于0.5和0.5,最終達到均衡,
結束!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/263023.html
標籤:AI