編譯原理與技術-知識點整理(自用)
概念:把源程式轉換成等價的目標程式,這個程序就是所謂的編譯,編譯程式是現代計算機系統的基本組成部分之一,
編譯原理考試版-混子速成期末保過:https://www.bilibili.com/video/BV1ft4y1X7p6?p=1 (小姐姐聲音也可好聽,哈哈)不想看的可以直接看視頻(純題目講解)
第一章 編譯概述
1.1翻譯程式:
編譯程式
- 匯編程式:匯編語言->機器語言
- 編譯程式:高級語言->匯編語言|機器語言
解釋程式
- 解釋程式是一個一個的獲取、分析并執行源程式陳述句,一旦一個陳述句分析完成,解釋程式便開始運行并生成結果,語言程式的除錯就可以用解釋器來實作
1.2編譯的階段和任務:
- 分析階段(詞法分析、語法分析、語意分析)
- 綜合階段(中間代碼生成、代碼優化、代碼生成)
1.3編譯有關的其他概念
- 前端:主要由與元語言有關而與目標機器無關的那些部分組成,通常包括詞法分析、語法分析、語意分析和中間代碼生成、符號表的建立,以及機器無關的代碼優化作業,還包括相應的錯誤處理作業和符號表操作,
- 后端:由編譯程式中與目標機器有關的部分組成,一般來講,這些部分與源語言無關而僅僅依賴于中間語言,包括目標代碼的生成、與機器有關的代碼優化,以及相應的錯誤處理和符號表操作,
- “遍”的概念:一“遍”是指對源程式或其中間表示形式從頭到尾掃描一遍,并做相關的加工處理,生成新的中間表示形式或目標程式,每一遍完成一個或相連幾個邏輯部分的作業,eg:第一遍進行詞法分析,第二遍進行語法分析,第三遍進行語意分析諸如此類,
前處理器/匯編程式:略,
第二章 形式語言語言與自動機基礎
2.1 字母表和符號串
- 字母表:符號的非空有限集合,典型的符號是字母、數字、各種標點和運算子等,eg:{0,1}是二進制數的字母表,計算機使用的字母表常見的由ASCII字符集和EBCDIC字符集,
- 符號串:定義在某一字母表上的符號串是由該字母表中的符號組成的有限符號序列,eg:010011、0101等是字母表{0,1}上的符號串,aa、ab、abababab等是定義在字母表{a,b}上的符號串,
- 符號串長度:串中出現符號的個數,
2.2 語言
- 語言定義:在某一確定字母表上的符號串的集合,----語言也可以進行運算,eg:并、交、閉包運算等,
2.3 文法
- 文法定義:文法就是描述語言的語法結構的形式規則,任何一個文法都可以表示為一個四元組G=(
,
,S,
)
- S是一個特殊的非終結符號,稱為文法的開始符號,開始符號S至少必須在某個產生式的左部出現一次,
- 文法分類:
- 0型文法:
- 1型文法:背景關系有關文法,
- 2型文法:背景關系無關文法,
- 3型文法:正規文法(線性文法)
- 文法書寫約定:
- 常做終結符(次序靠前的小寫字母,eg:abc等、運算子號,eg:+-*/等,標點,eg:括號、逗號、冒號、等于號等、數字等)
- 常做非終結符(大寫字母ABCD、S、小寫斜體)
2.4.1 文法二義性消除
消除文法二義的兩種方法:
① 改寫二義文法為非二義文法;
② 規定二義文法中符號的優先級和結合性,使僅產生一棵分析樹,左結合性:
對于A→αAβ,若A(左右都有的非終結符)在終結符(即終結符在β中)左邊出現,則A產生式具有左結合性質,
如:
E → E + T是左結合(E即A,+是終結符),F → (E) | -F是右結合(F即A,-是終結符)
2.4.2 左遞回消除,(略)-后期補充
- 目的:由于自頂向下的語法分析方法不能處理左遞回文法,所以對左遞回文法進行消除左遞回是必須的,
- 例:

2.5 有限自動機(略)-后期補充
定義:有限自動機是具有離散輸入與輸出的系統的一種數學模型,
重點:狀態轉換圖,
第三章、詞法分析
詞法分析主要是分析輸入的源程式(字串),輸出該字串中出現的所有的合法的單詞,例如:int a = 3 + 5;經過詞法分析會輸出 int,a,=,3,+,5和;這七個單詞,實作詞法分析器的官方做法是:
1.寫出各個單詞的正規式(正則運算式);
2.根據正規式構造NFA(不確定的有限自動機);
3.將NFA轉換DFA(確定的有限自動機);
4.根據DFA就可以實作詞法分析器,寫出程式,
第四章、語法分析
4.1 常用的語法分析
- 語法分析任務:按照語法從源程式幾號序列中識別出各種語法成分,同時進行語法檢查,為語意分析和代碼生成做準備,
- 自頂向下的分析方法:從頂部(根部)到底部(葉子)為輸入的記號序列建立分析樹,eg:預測分析程式采用的就是自頂向下的分析方法,
- 自底向上的分析方法:自下而上地為輸入的記號序列建立分析樹,eg:LR分析程式采用的就是自底向上的分析方法,
4.2 語法錯誤的處理
- 詞法錯誤:非法符號等,
- 語法錯誤:括號不匹配,缺少運算物件等,
- 語意錯誤:運算量的型別不相容、實參與形參不匹配等,
- 邏輯錯誤:無窮的遞回呼叫等,
4.3 自頂向下分析方法 - 后期補充
- 遞回下降分析(理論上成立):設法尋找一個最左推導序列,以便通過一步步推導將輸入符號串推匯出來,
- 遞回呼叫預測分析:適用于LL(1)型文法,再遞回下降分析中,
- 首先消除文法左遞回--然后找到文法的first集和follow集,判斷是否為LL1型文法,--
這只是準備條件(判斷是否能為LL1型文法,
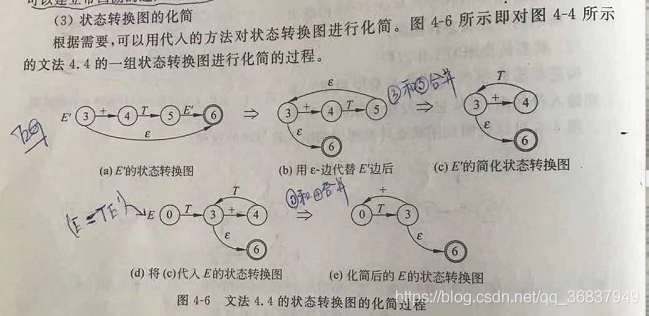
利用狀態轉換圖識別輸入符號串,(預測分析程式狀態轉換圖的化簡)
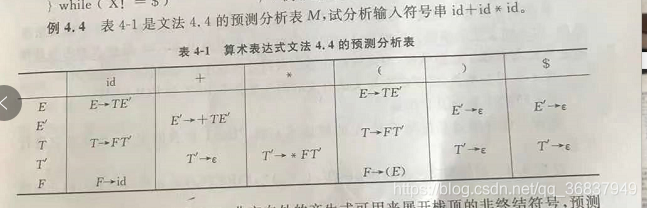
非遞回預測分析:需要構造預測分析表,根據預測分析表進行產生式的選擇,
預測分析表的構造程序:(略)
例子:
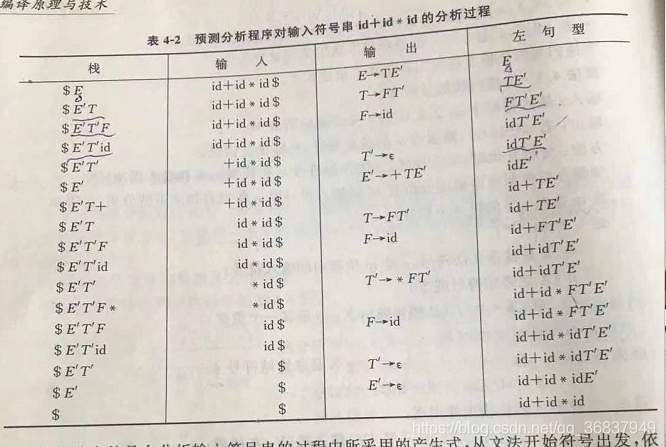
根據預測分析表對符號串的分析程序:








4.4 自底向上分析方法 (不需要消除左遞回)-關鍵在于找出“可歸約串”,然后根據規則判別將它歸約為哪個非終結符-(規范歸約方法=重點=尋找句柄)
- 程序:試圖自下而上地為輸入串構造一棵分析樹,從樹葉開始向上構造,直到樹根,采用自左向右掃描,從輸入串開始,查找當前句型的“可歸約串”,并使用規則把它歸約為相應的非終結符號,得到一個新的句型,重復這個程序,直到最后歸約到文法開始符號為止,(類似于利用堆疊實作運算式的計算-中綴、后綴的轉換等演算法)
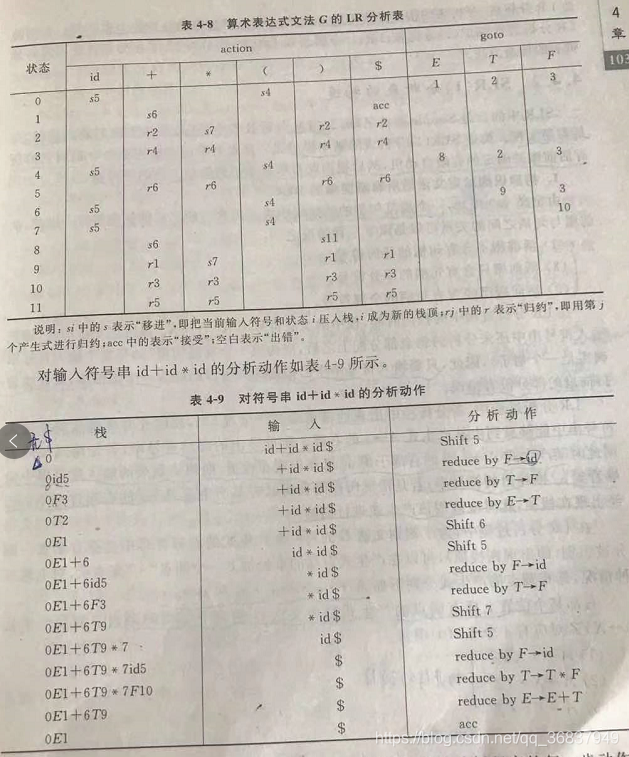
- LR分析法(背景關系無關文法):
字符 含義 L 表示 從左到右 掃描輸入串 R 表示利用 最右分析方法 來識別句子,即構造一個 最右推導的逆程序 k 表示向右查看輸入串符號的個數
- 部分:輸入、輸出、堆疊、分析控制程式、分析表,
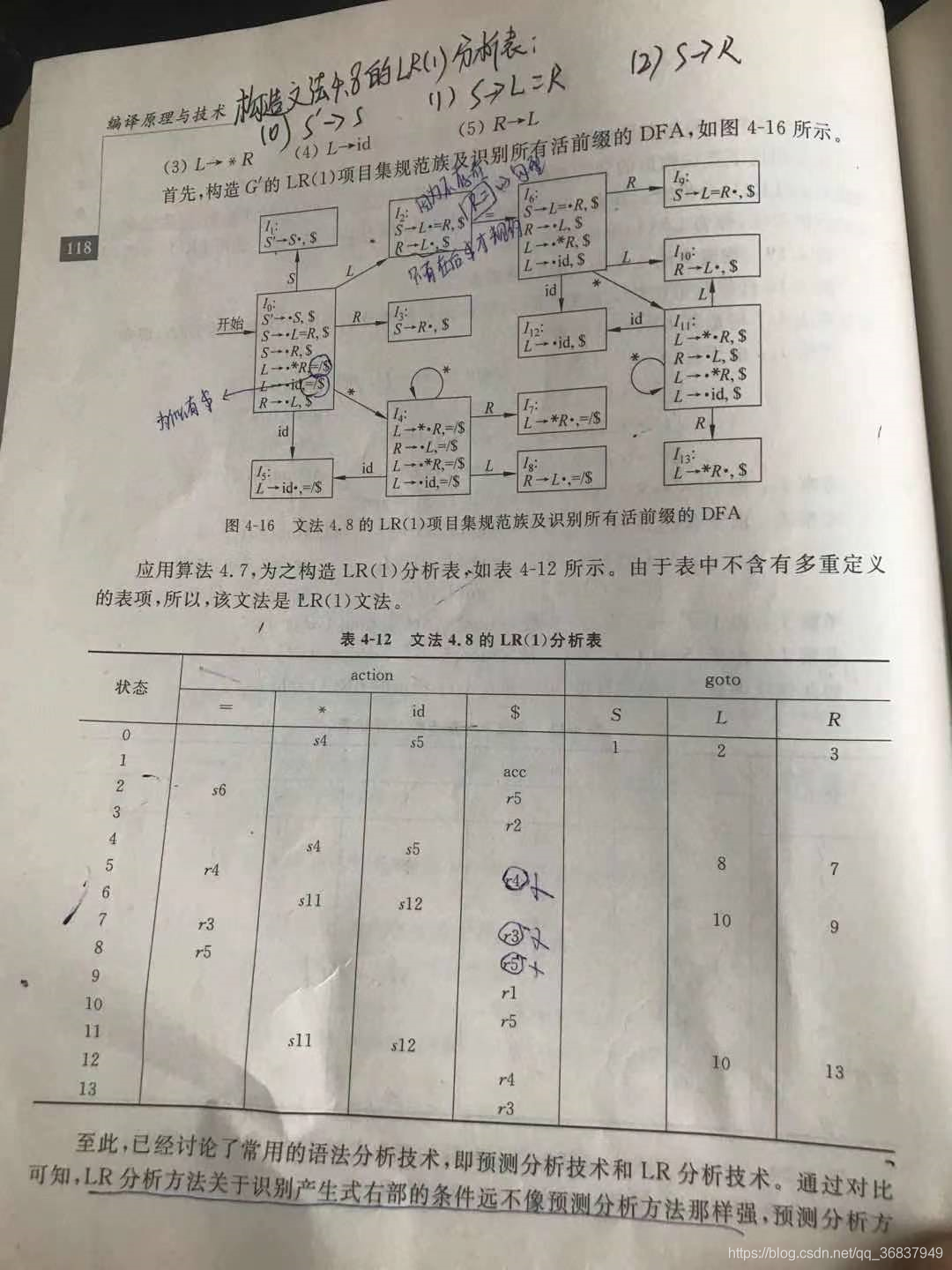
- 分析表的構造:
- 首先為給點文法構造一個識別它的所有活前綴的確定的有限自動機,然后根據此有限自動機構造該文法的分析表,
- 注:點的左邊表示已經在堆疊內的內容,點的右邊表示未進堆疊的內容,(這種寫法,表示了當前的狀態,)
- 分析程序:

第五章、語法翻譯
5.1 任務+步驟
- 把源程式轉換成等價的目標程式,即目標程式必須和源程式具有同樣的語意,
- 步驟:首先需要根據翻譯目標的要求確實每個產生式所包含的語意,進而分析文法中每個富豪的語意,并把這些語意以屬性的形式附加到相應的文法符號上(把語意和語言結構聯系起來),然后再根據產生式的語意給出符號屬性的求職規則(即語意規則),從而形成語法制導定義,這樣,當在語法分析程序中使用該產生式時,就可以根據相應的語意規則對屬性求值,從而完成翻譯,(翻譯目標決定了產生式的含義,文法符號應具有的屬性,產生是的語意規則)
- 任務:對單詞符號串進行語法分析,構造語法分析樹,然后根據需要構造屬性依賴圖,遍歷語法樹并在語法樹的各結點處按語意規則進行計算,
- 如何表示語意資訊?
- 為CFG中的文法符號設定語意屬性,用來表示語法成分對應的語意資訊,
- 例如對于一個變數,它的語意屬性可以有變數的值,變數的型別等等,
- 如何計算語意屬性?
- 文法符號的語意屬性值使用與文法符號所在產生式(即語法規則)相關聯的語意規則來計算的,
- 對于給定的輸入串
x,構建x的語法分析樹,病利用與產生式(語法規則)相關聯的語意規則來計算分析樹中個節點對應的語意屬性值,語法制導定義(Syntax-Directed Definitions,SDD)
- SDD是對背景關系無關文法(CFG)的推廣
- 將每個文法符號和一個語意屬性集合相關聯
- 將每個產生式和一組語意規則相關聯,這些規則用于計算該產生式中各文法符號的屬性值,
- 如果
X是一個文法符號,a是X的一個屬性,則用X.a來表示屬性a在某個標號為X的分析樹節點上的值,(X可以為終結符或非終結符)


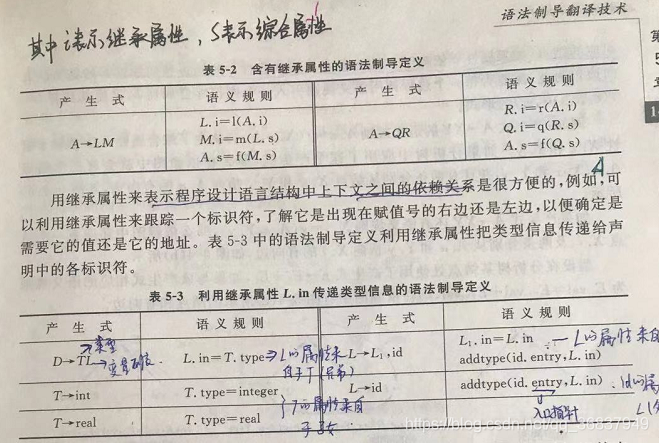
語法制導定義:對應于每一個文法產生式A->a都有與之相聯系的一套語意規則,其形式為b=f(c,d,...)這里,f是一個函式,且-1)如果b是A的一個綜合屬性,則c,d..是產生式右部文法符號的一個繼承屬性,-2)如果b是產生式右部某個文法符號的一個繼承屬性,則cd是A或產生式右部任何文法符號的屬性,
綜合屬性:在分析樹中,一個節點的綜合屬性是由其子節點的屬性值決定的,用于自下而上傳遞資訊
繼承屬性:產生式右部某文法符號的繼承屬性值由左部符號的繼承屬性和/或右部任何文法符號的屬性值決定的,用于自上而下傳遞資訊,(類似于變數的值)
1)終結符只有綜合屬性,由詞法分析器提供,非終結符可有綜合屬性,也可有繼承屬性,文法開始符號的所有繼承屬性作為屬性計算前的初始值,(類似于變數的型別)


5.2 語意制導定義-背景關系無關文法的一種擴展形式
5.2.1 依賴圖-略
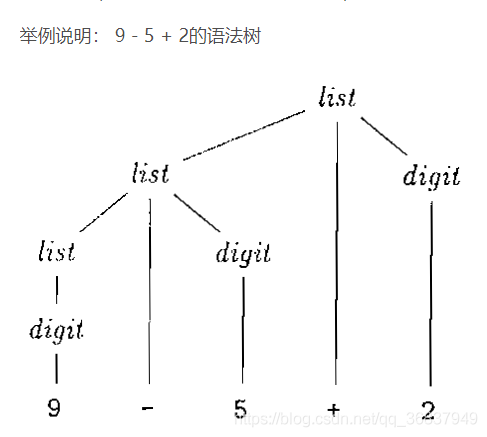
5.2.2 語法生成樹-重點-參照LR語法分析的歸約構建,
第六章、語意分析
6.1 任務
- 將變數的定義與它們各個使用聯系起來,對陳述句的含義進行檢查,檢查每一個語法成分是否具有正確的語意,
- 任務:對結構上正確的源程式進行背景關系有關性質的審查,進行型別審查,語意分析是審查源程式有無語意錯誤,為代碼生成階段收集型別資訊,
6.2 符號表
符號表是第一次遍歷,詞法分析的時候生成的,
符號表的內容(變數名、資料型別、目標地址、維數或引數個數、宣告行、參考行、鏈域)
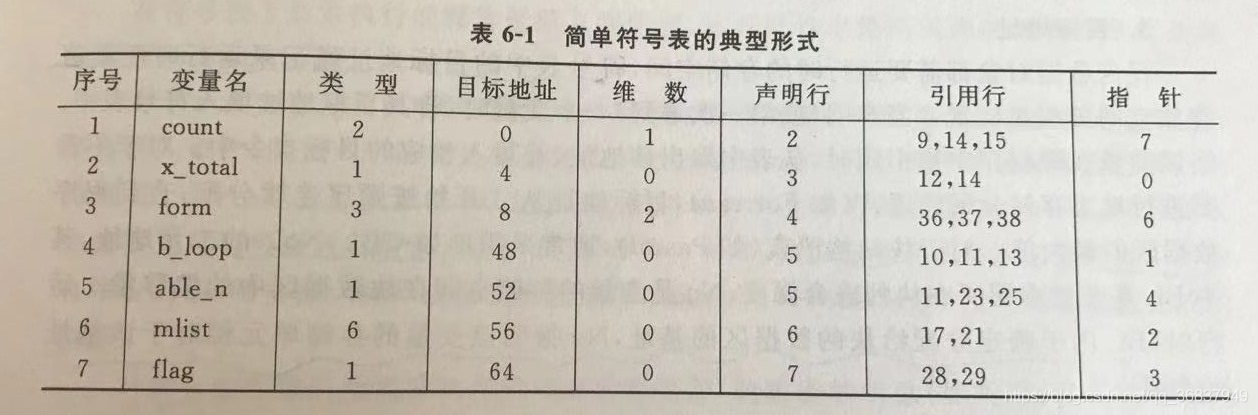
6.3 符號表操作
最常用的操作就是插入和檢索,這些操作根據所編譯的源語言是否具有顯式宣告而稍有不同,對所有的變數參考都將執行符號表檢索操作,檢索出的資訊(如型別,目標地址和維數等)將被用于型別檢查和代碼生成,在該階段進行的檢索操作可檢查出未定義而使用的變數,并給出相應的錯誤或警告資訊,
第八章、中間代碼生成
8.1 中間代碼形式(后綴表示、語法樹、dag、三地址代碼)
任務:中間代碼生成程式的任務就是把經過分析階段所獲得的源程式的中間表示翻譯成中間代碼表示,便于編譯程式的建立和移植,便于進行獨立與機器的代碼優化,
本章使用四元式表示(考試要求)
例題:


愿今年多吃不胖,積極向上!!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/263442.html
標籤:其他
上一篇:資料結構概述