前言
這是去年博主參加的一個語意分割競賽,最終取得了top3%(13/377),這是博主第一次參加遙感影像語意分割競賽,借著這次機會博主開始了語意分割的學習旅程,比起最終名次,博主更在意的是在這個程序中能學到什么,在上次復盤了違法廣告目標檢測競賽之后,博主充分意識到了復盤的重要性,因此迫不及待地對這次遙感分割競賽進行復盤,
沒看過之前違法廣告的目標檢測競賽復盤的朋友可以也關注下檢測賽,因為是2020年的競賽里面很多的model和trick都是最新的,也涉及很多cvpr2020的論文,下面是傳送門:
違法廣告目標檢測賽傳送門
回到本篇文章,這次遙感分割賽主要是根據高清遙感衛星影響圖來對各種道路進行分割,這些道路有的是“通天大道”,有的是“羊腸小道”,充滿了細節部分,最終博主團隊的模型是0.833,冠軍是0.841,所以相差不是很多,博主認為主要的難點是如何平衡模型既看到大的整體大的目標,又看到非常微小的小路,博主復盤的時候感覺自己在沖刺階段的思路出現了問題,我當時有三種思路,都是基于訓練好大模型(對于大的道路分割效果優秀)的基礎上通過finetune迫使模型學習細節,第一種是通過使用Focal loss/OHEM做finetune去強迫模型去學習細節;第二種是通過微小的學習率和batchsize去finetune迫使模型關注每張圖片的細節;第三種是在多尺度的輸入上進行finetune,
事實證明這三種finetune的思路都不是那么的work,也導致博主最后遺憾的以微弱劣勢沒能沖進top10,
現在如果重新再來我可能更多會考慮:
- FPN/BiFPN
- 再在remain high resoluton上做一些嘗試,比如deformable convoluton之類的,
- 使用多個大model蒸餾小model,這些大model會被設定成有的關注細節有點會更關注整體,
- 一種基于OCRNet和large kernel matters論文博主發現的漲點技巧,我最后會提到,
另一個難點是這場比賽對于模型的推理時間和顯存占用非常的約束,我沒有具體去測驗flops,但是ensmble大引數量的模型是幾乎不可能的,后來又傳出TTA會被扣分,所以我們也沒用TTA(太老實了),但是同樣也讓我認識到了要多關注模型的輕量化,關注inference time/flops才有實用的價值,
好了,以上的博主的一些murmur,下面我們還是重點來看我們能從前排大佬里吸到多少歐氣吧!
在開始學習之前,請沒參加過這場大賽的朋友先瀏覽下大賽的賽題:
2020華為人工智能大賽傳送門
第八名(吸到1點歐氣)
1.LinkNet (loss:dice+bce 1:1)
選手采用了LinkNet34(backbone是Resnet34),linknet我之前關注的較少,但是聽說這次好幾個前排都用了,說明這個網路效果還是不錯的,如果把backbone進一步的提升比如senet或者res2net之類的應該這個選手還能提升,
在做競賽的時候backbone還是要多試一下比較保險,我們這次是deeplabv3+/unet兩個支線,大把精力都花在了魔改和EDA上面,再比如后面一個kaggle競賽中,基于vision transformer的模型在分類上霸榜了,在kaggle 小麥檢測中yolov5也完成了霸榜(雖然后來被禁用了),所以針對不同的資料集,最佳的baseline也是完全不一樣的,反思這點,我覺得應該至少熟悉準備4-5個比較靠譜的baseline才能有效地避免一開始就輸在起跑線,對于分割賽很顯然unet/deeplabv3+/hrnet+ocr/linknet/senet+fpn之類的都應該出現在list上,
說到這里突然想到前幾天和一個kaggler聊天,他說他們團隊都是專人負責model設計的,也有人專門復雜augmentation,也有人負責train等等,這種團隊分配明顯是更合理的,我們團隊都是端到端的搞,每人負責一個路線,在前期為了多學知識這種思路是可取的,但是后面應該還是更好的分配人力,這些和技術無關了,只是我們的一點反思,
LinkNet的架構非常簡單,比Unet還簡單,主要focus在flops和推理速度上,致力于實時的語意分割,它有一個變種D-linknet,值得學習,尤其是這個論文就是base在遙感道路分割上的,附上論文的傳送門:
D-LinkNet :LinkNet with Pretrained Encoder and Dilated Convolution for High Resolution Sate
D-linknet知乎推薦文章
D-linknet是專門為了遙感道路分割設計出來的網路,在論文里主要提到了這類問題的三大難點:
- 遙感影像具備高解析度,道路有些會跨度極大,需要很大的感受野,覆寫全圖,
- 部分道路很細長狹小,需要保留精準的定位資訊才能恢復這類細小道路,
- 道路具備自然連通性,
回想這個比賽中,我們也是基本focus在了這些問題上,分別用了空洞卷積/可變形卷積來適配感受野,嘗試了膨脹腐蝕和去除孔洞的后處理來保障連通性,但是對于問題二細小道路的定位做的不好,
D-linknet使用的空洞卷積在模型的中間,使用的是串聯的方式疊加感受野,同時maintain resoution,空洞卷積無論是串聯還是并聯都能表現出很好的性能,
D-linknet的架構如下圖:
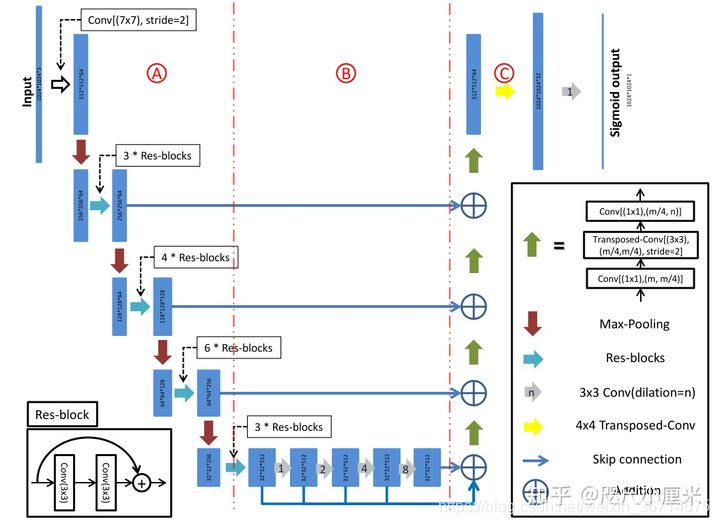
D-linknet的空洞卷積疊加沒有使用圖森組論文中提到的HDC設計,而是1,2,4,8,16這樣疊加,可能會導致棋盤效應,影響分割精度,
HDC可以參考下面這個知乎分析:
關于空洞卷積的HDC
同時大家仔細看這個圖,中間的部分很像unet的bridge結構,一定程度上能夠指導我們如何設計unet的bridge結構,我在部分比賽中發現unet的bridge結構也是會對最終的結果產生很大的影響,在這里它是dilation的堆疊+skip connection,值得注意的是它的原圖是1024的輸入,解析度還是蠻高的,所以才使用32倍下采樣,如果輸入圖片是512或者更小,32倍下采樣丟失的位置資訊就比較難恢復了,
最終的輸出這組選手使用了8倍的TTA,也是說明了linknet系列的輕量化,
第七名(吸到1點歐氣)
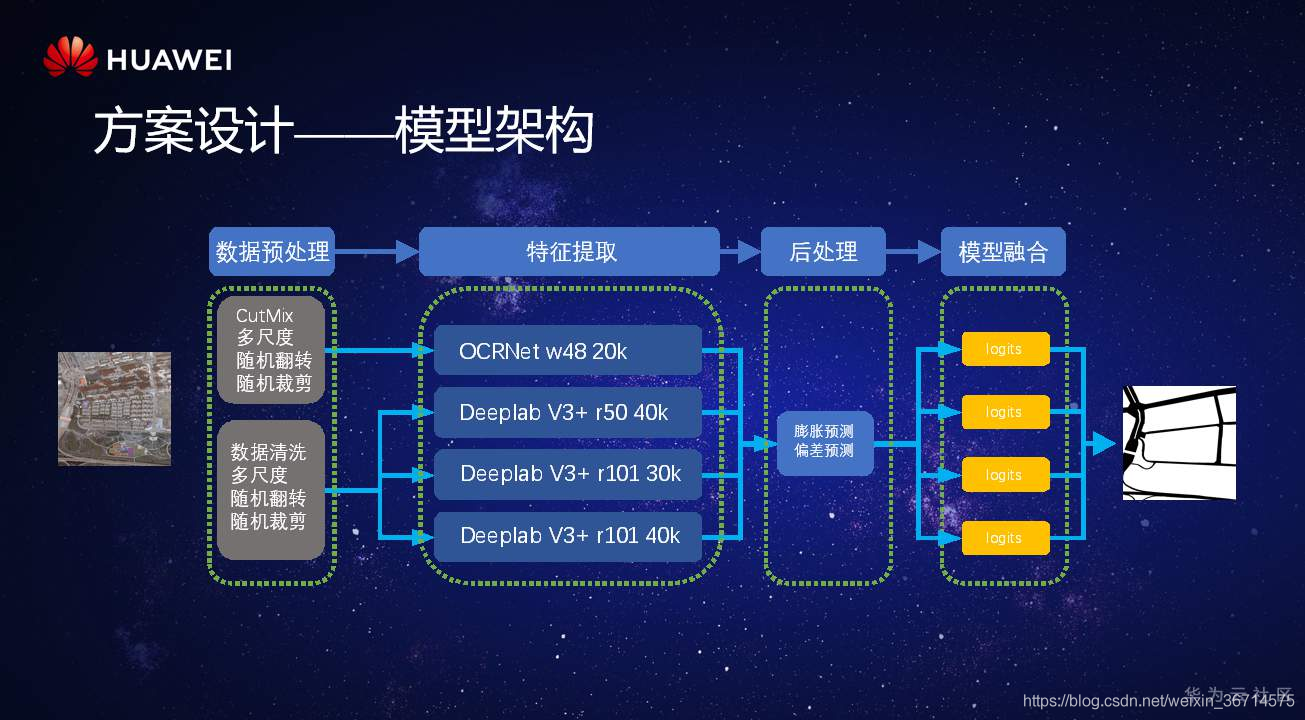
先放個架構設計圖,是四模融合,也足以說明deeplabv3+是比較輕量的,值得學習的部分是OCRnet的使用算是新的技術,
1.OCRNet
OCRnet的和核心思想是在構建背景關系資訊時顯式地增強了來自于同一類物體的像素的貢獻,是從語意分割的本質思考得來的思路,
微軟亞研院分析了當前語意分割model的三個最大問題:
- 多層下采樣導致的定位資訊丟失,
- 像素級特征的感受野不夠,且物體具有多尺度,
- 邊界錯誤,邊界的feature的表達能力比較低,很多語意分割的錯誤都來自于邊界,
從而針對性的提出了:
- HRnet:用于maintain high resolution
- OCRnet:用于增強像素背景關系語意資訊
- SegFix:用于解決邊界錯誤的問題,
下圖是OCRnet的架構:
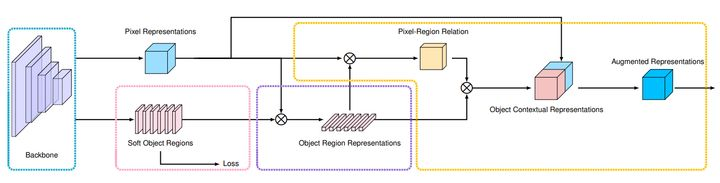
HRnet/ OCRNet的這部分我打算專門寫一個原始碼決議系列,在這里就不贅述了,
第六名(吸到1點歐氣)
1.模型選擇
使用了HRnet+OCR,關于為什么使用這個模型的思路較好,這里直接收錄選手的思路:
低分辨的特征包含豐富的語意資訊,但由于下采樣操作,導致它丟失了部分位置資訊,而高解析度的特征相反,它的語意資訊相對較少,但位置資訊保留較多,定位相對準確,有利于檢測小目標,由于道路大多都是長且窄的形狀,就要求模型必須定位準確,也就是說道路的檢測依賴于高解析度的特征,現有的大多數網路都是由高解析度特征下采樣到低解析度特征,再從低解析度特征中恢復高解析度特征,但是丟失的位置資訊不能完全恢復,而HRNet在整個階段都保持高解析度的特征,有利于道路的檢測,此外,HRNet的不同分支產生不同解析度的特征,這些特征之間互動獲取資訊,最后得到包含多尺度資訊的高解析度特征,因此選擇HRNet作為我們backbone,此外,我們認為道路分割不依賴于非常高級的語意資訊,因此就不需要非常深的網路,而且在訓練資料量有限的情況下,大網路有龐大的引數量,會有過擬合的風險,因此我們選擇的是HRNet系列中的小模型:HRNet18,分割頭選擇OCR注意力模塊,利用目標背景關系增強特征表示,整個網路結構小,訓練速度和推理速度都較快,在實驗中,發現HRNet18在速度和精度上都優于hrnet32、hrnet48和deeplabv3+(resnest50),
這里能學到的就是從問題中選擇模型的一種思路(至于信不信的哈哈哈…),
HRnet/ OCRNet的這部分我打算專門寫一個原始碼決議系列,在這里就不贅述了,
2.loss的設計
這里學習到的也是loss設計的思路:
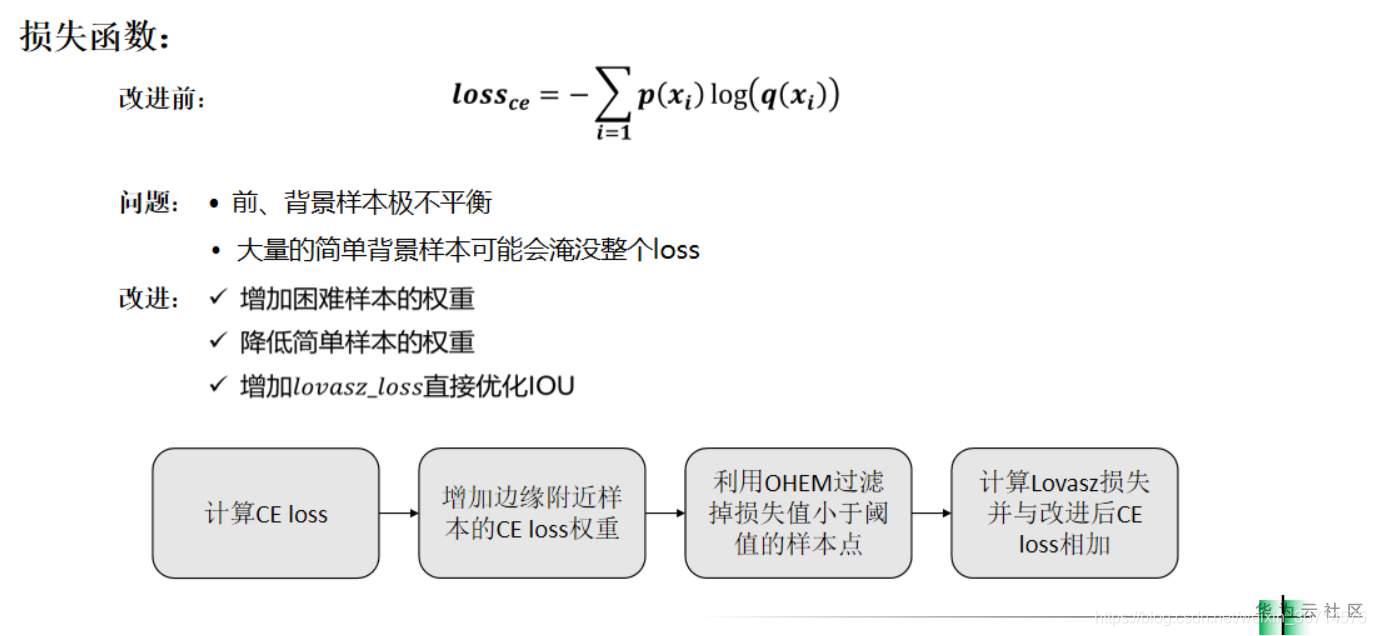
交叉熵損失的問題在于無法解決前景和背景之間的資料不均衡問題,在比賽結束的階段,大部分的model都能比較好的預測出主體的道路部分,但是會存在細小的道路還有困難的樣本識別不好,選手為了解決以上的問題對于邊緣附近的pixel進行了損失加權,然后使用了OHEM對于簡單樣本進行了過濾,最后的loss是lovasz+bce,lovasz是IOU的可導替代形式,可以優化IOU,在部分比賽中有良好效果,
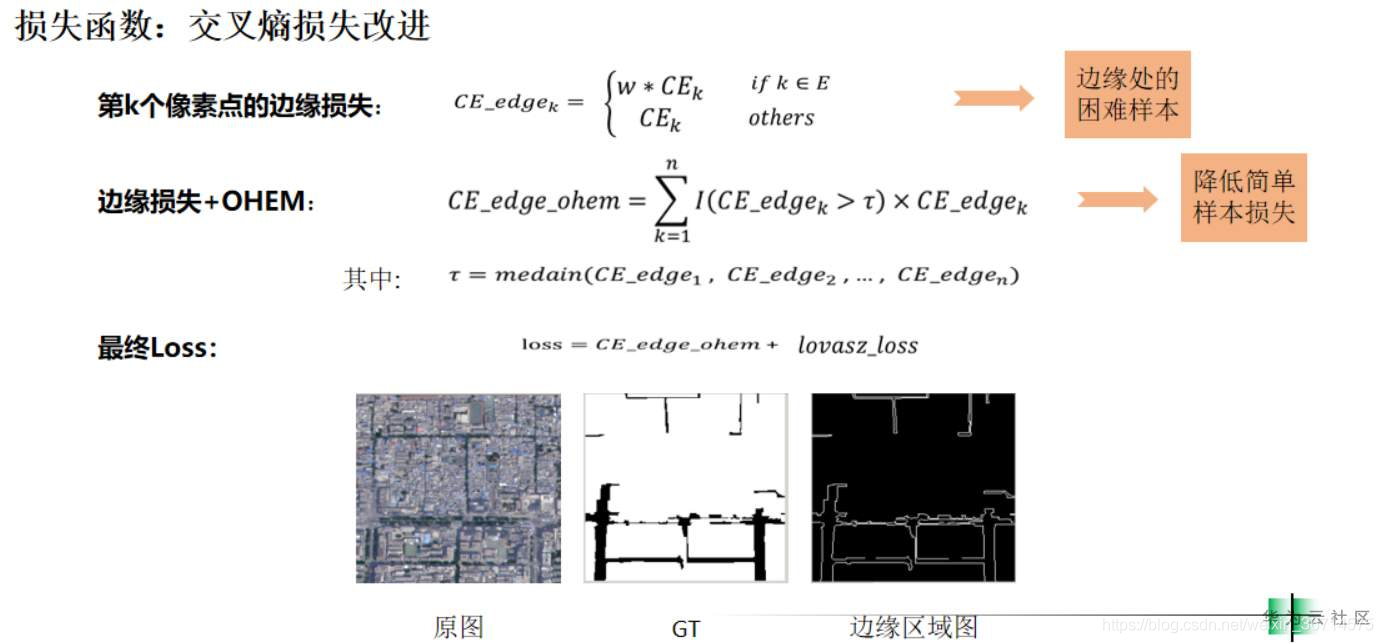
參考上圖,選手對于邊緣進行了提取,對于邊緣的ce loss進行了增加,然后對loss進行了閾值設定,小于閾值的部分被看作簡單樣本不參與反向傳播,最后使用了bce+lovasz softmax,
3.指數滑動平均(EMA)
沒用過,暫時保留,回來一定補上,
第五名(吸到一口華子)
1.一些小點
- RandomGridShuffle:把影像裁成四個塊,然后打亂順序,一個不是很常見的augmentation,
- BCE Loss+余弦模擬退火做訓練,找到最佳模型后用Lovasz Hinge Loss + StepLR 做微調(也是Lovasz的作者推薦的使用方式),微調的時候使用了線性啟動,
- FPN/Unet + EfficientNetB5
第四名(吸到2點歐氣)
首先作者分享了原始碼,掌聲~~
原始碼傳送門
1.前景背景不平衡
選手通過計算,得到前景和背景的像素占比約為12.2%和87.8%,像素類別極度不平衡,故我們在loss中加入權重(3: 1),以減輕類別不平衡帶來的影響,
說明加權這種方法雖然簡單,但是不一定弱,在解決不平衡的問題也要測驗這個笨辦法,
2.忽略邊緣預測
感覺是個騷操作,沒有詳細說明,回來看看原始碼一定補上,
第三名(吸到一桿大煙槍)
1.一些小點
- unet+efficientnetB5
- lovasz+focal loss
- Radam+LookAhead 優化器 + 余弦模擬退火
- 多尺度訓練,不同batch間圖片尺寸進行調整,
- 膨脹預測
以上都是較為常見的技巧,說明用好了也能拿前三,
第一名(吸到1點歐氣)
首先,開源了代碼,掌聲鼓勵,傳送門如下:
比賽原始碼傳送門
1.方案設計
編碼模塊選用ImageNet預訓練的ResNeXt200網路,在E-D架構的基礎上,提出一種通道注意力增強的特征自適應融合方法,并設計基于梯度的邊緣約束模塊,在增強空間細節和語意特征的同時,提高道路邊緣的特征回應,實作多尺度道路準確提取,架構如下:
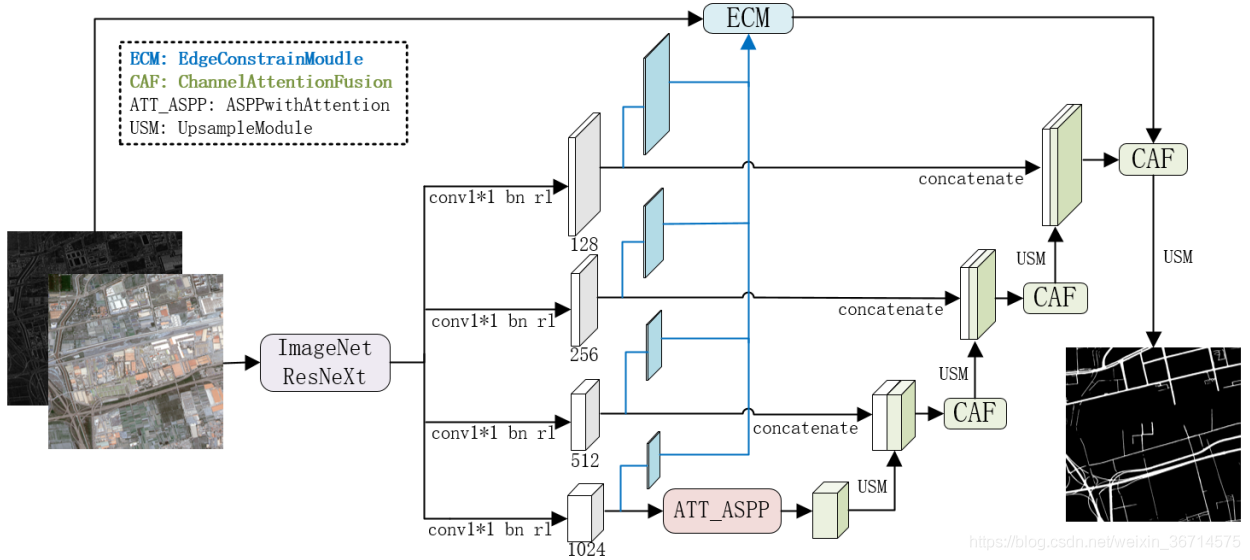
這個架構的特點:
- 輸入是四通道,加了一個通道是Sobel算子算出來的梯度資訊,這樣保證邊緣的提取更為準確,
- backbone選擇了非常深的Resnext200,可以提取到更深的語意資訊,說明有了梯度資訊的輸入,可以使用較深的網路而還能獲得良好的定位資訊的恢復,
- 中間的結構有點像D-linknet,只是串聯的空洞卷積變成了ASPP結構,
- 上采樣融合之后加了CAF,類似channel維度的注意力機制,我在多個比賽中也發現上采樣融合之后是比較好的加入注意力的位置,可以理解為channel concat之后需要通道注意力平衡各通道權重的重要性,
- ECM這條路線是一個類似FPN的結構,可以彌補定位的資訊,
我在這個比賽結束后,就征得選手的同意,復現了這個網路并且在kaggle的另一場比賽中去校驗,可惜的是在病理分割上表現不佳,可能是這個設計思路更適合依賴邊緣精度的遙感道路分割,
總結
寫完前十名的方案復盤后,我發現并沒有我想象的或者說之前參加目標檢測比賽的招數層出不窮,雖然也是八仙過海,各顯神通,但是整體來說沒有特別亮點的地方,
在這個榜單中HRnet+OCRnet也算是占據了半壁江山,說明確實泛化性也是不錯的,我后面打算做一期原始碼的分析,好好整理一下這兩個框架,或許再加上Segfix一起吧,
在這次復盤中,識訓最大的也不是這些trick,而是如何在比賽中進行思路上調整,一切都要回歸到資料中,EDA的探索,發現了什么問題再對癥下藥,而不是亂做一起,魔改到底,
比如發現了小目標識別不行:就要考慮多尺度訓練、FPN、增大resolution…
比如發現了邊緣識別不行:就要考慮增加邊緣loss、增加梯度資訊
比如發現了某類識別不行:就要考慮是不是資料平衡問題?是不是要單獨對這個類進行離線資料增強?又或者是這個類不需要很深的語意特征從而考慮maintain resolution?
比如發現了資料不平衡:就要考慮資料增強、loss加權、在線重采樣、focal loss、或者是之前目標檢測文章提到的留一半?
比如發現了整體效果都不行:就要考慮是不是類別語意資訊很差,考慮用OCRnet? 做更多的feature間的融合?等等,
…
…
你們想象吧,我先休息去了…
[本篇完]
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/263760.html
標籤:AI
上一篇:文本資料增強方法