一、準備環境
1.ubuntu16(使用虛擬機實作集群搭建)
2.jdk1.8
二、安裝包準備
由于不同版本之間存在兼容問題,本次搭建使用的是hadoop2.7.1+hbase2.1.4+zookeeper3.6.2
安裝包見云盤:鏈接: 安裝包 提取碼: 2b5a
三、安裝前準備
1、節點主機名-IP映射
(1)修改主機名(三臺都需要修改)
vim /etc/hostname
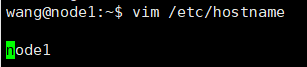
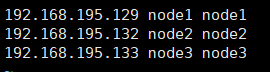
這里對三臺主機的名字進行修改:node1、node2、node3,修改后可使用如下圖命令查看主機的名字是否修改成功
(2)ip映射(三臺機器均需操作)
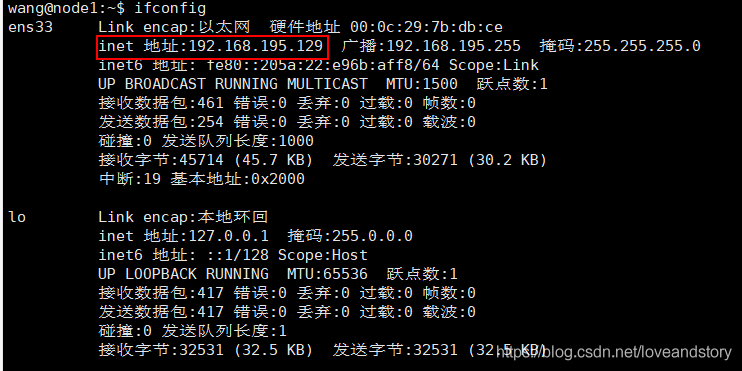
使用ifconfig查看各主機的ip地址:
ifconfig
vim /etc/hosts
2、關閉防火墻+ssh免密登錄
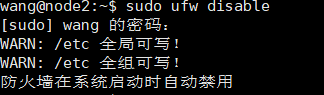
如果你之前開啟過防火墻,要先關閉
sudo ufw disable
接下來要實作3臺機器之間的免密登錄:不過一般只需要實作node1->node1|node2|node3之間的通道就可以了
ssh-keygen #生成公鑰、私鑰,每臺機器上執行
#只需在node1上執行
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
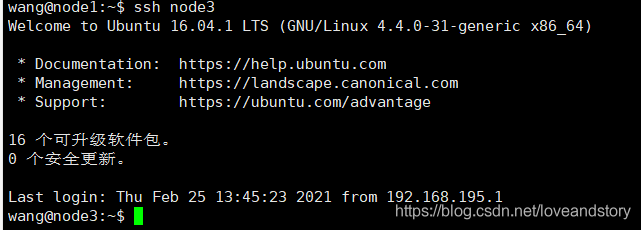
免密登錄成功后,使用ssh node3即可無需密碼登錄!
(3)集群時間同步
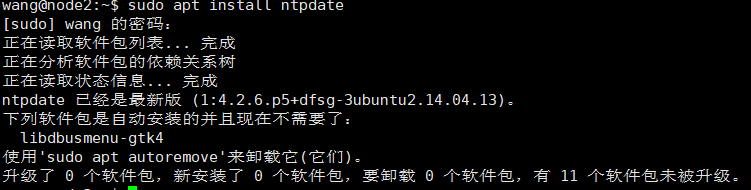
sudo apt install ntpdate
ntpdate ntp4.aliyun.com
(4)java安裝
tar -zxvf jdk安裝包
sudo mv jdk /usr/jdk1.8
#環境變數配置命令
sudo vim /etc/profile
source /etc/profile
環境變數配置:
export JAVA_HOME=/usr/local/jdk1.8
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=.:${JAVA_HOME}/bin:$PATH

四、安裝hadoop
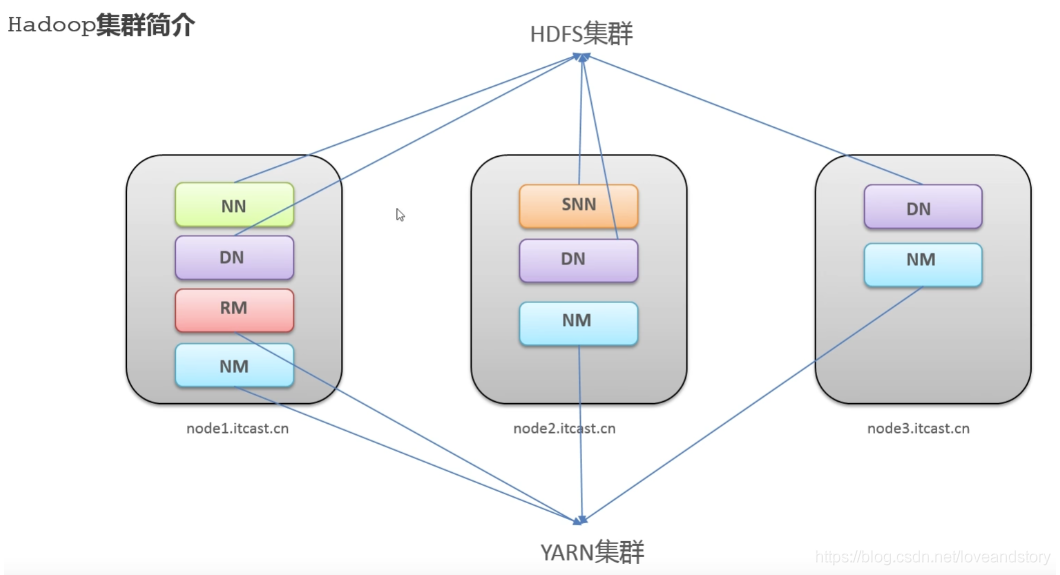
本次搭建以三臺機器為例,各個節點的分布情況如下:
1.新建作業目錄
mkdir -p /export/server/
mkdir -p /export/data/
mkdir -p /export/software
sudo chmod -R 777 /export/
2.上傳、解壓安裝包
上傳安裝包到software目錄,解壓到/export/server目錄下
tar -zxvf hadoop-2.7.1.tar.gz -C /export/server/
3.組態檔
在hadoop-2.7.1/etc/hadoop/里修改組態檔,使用vim命令
(1)hadoop-env.sh
root指用戶名,依據你自己的機器的用戶名而定
#配置JAVA_HOME
export JAVA_HOME=/usr/local/jdk1.8
#設定用戶以執行對應角色shell命令,root指用戶名
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMAMANAGER_USER=root
(2)core-site.xml
<configuration>
<!--默認檔案系統的名稱,通過URI中的schema區分不同檔案系統-->
<!--file://本地檔案系統 hdfs://hadoop分布式檔案系統-->
<!--hdfs檔案系統訪問地址:http://nn_host:8020-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<!--hadoop本地資料存盤目錄format時自動生成-->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop-3.1.4</value>
</property>
<!--在Web UI訪問HDFS的用戶名-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
(3)hdfs-site.xml
<!--設定SNN運行主機埠-->
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:9868<value>
</property>
</configuration>
(4)mapred-site.xml
copy一份mapred-site.xml.template 命名為mapred-site.xml檔案
<configuration>
<!--mr程式默認運行方式,yarn集群模式local本地模式-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--MR App Master環境變數-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!--MR Map Task環境變數-->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!--MR Reduce Task環境變數-->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
(5)yarn-site.xml
<configuration>
<!--yarn集群主角色RM運行機器-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<!--NodeManager上運行的附屬服務,需配置成mapreduce_shuffle,才能運行MR程式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--每個容器請求的最小記憶體資源(以MB為單位)-->
<property>
<name>yarn.scheduler.minimun-allocation-mb</name>
<value>512</value>
</property>
<!--每個容器請求的最大記憶體資源(以MB為單位)-->
<property>
<name>yarn.scheduler.maximun-allocation-mb</name>
<value>2048</value>
</property>
<!--容器虛擬記憶體與物理記憶體之間的比率-->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>
</configuration>
(6)slaves
編輯該檔案,每個主機用回車隔開

4. hadoop環境變數配置
vim /etc/profile
source /etc/profile
在/etc/profile檔案添加如下:
export HADOOP_HOME=/export/server/hadoop-3.1.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
注意:每臺機器均要配置
4.將安裝包分發到其他主機
scp -r /export/server/hadoop-2.7.1 wang@node2:/export/server
scp -r /export/server/hadoop-2.7.1 wang@node3:/export/server
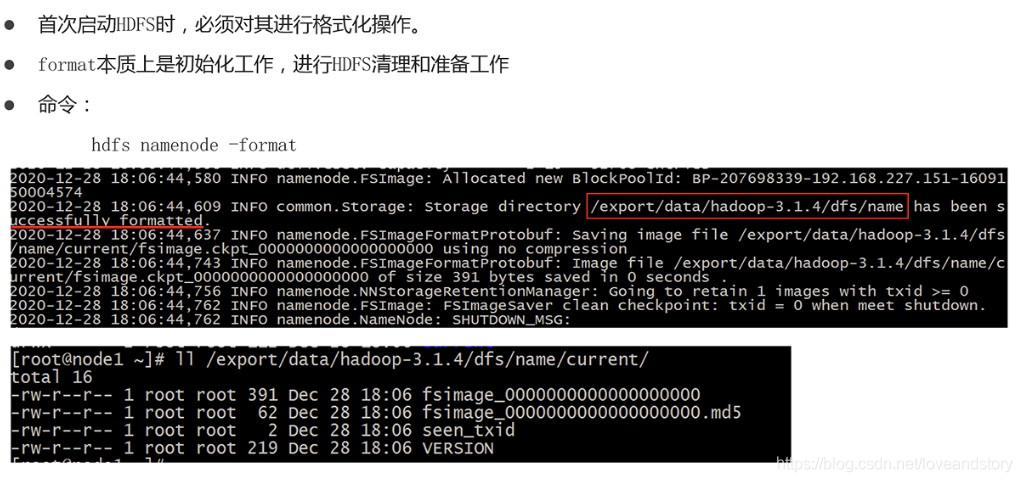
5.格式化
使用這個命令在node1上運行即可
hdfs namenode -format
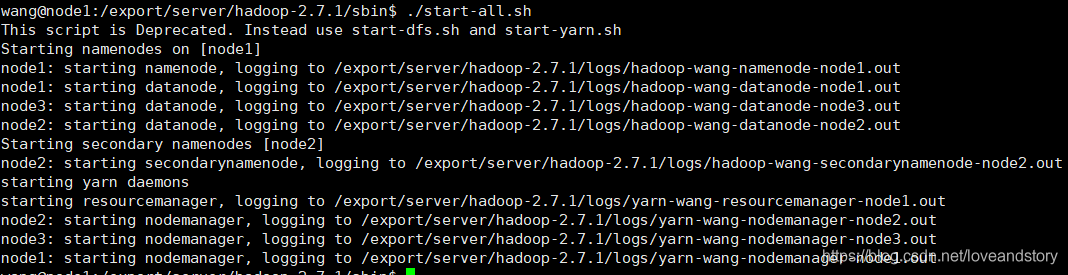
6.啟動
cd /export/server/hadoop-2.7.1/sbin
./start-all.sh
使用jps查看行程,如出現下面行程,則代表啟動成功
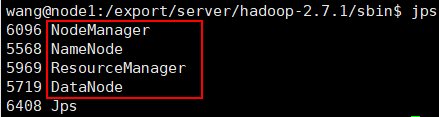
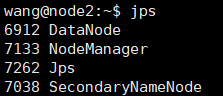
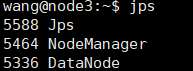
若上述執行緒均存在,即可訪問:http://node1:8088/,hadoop安裝完成,可以使用./stop-all.sh先關閉,
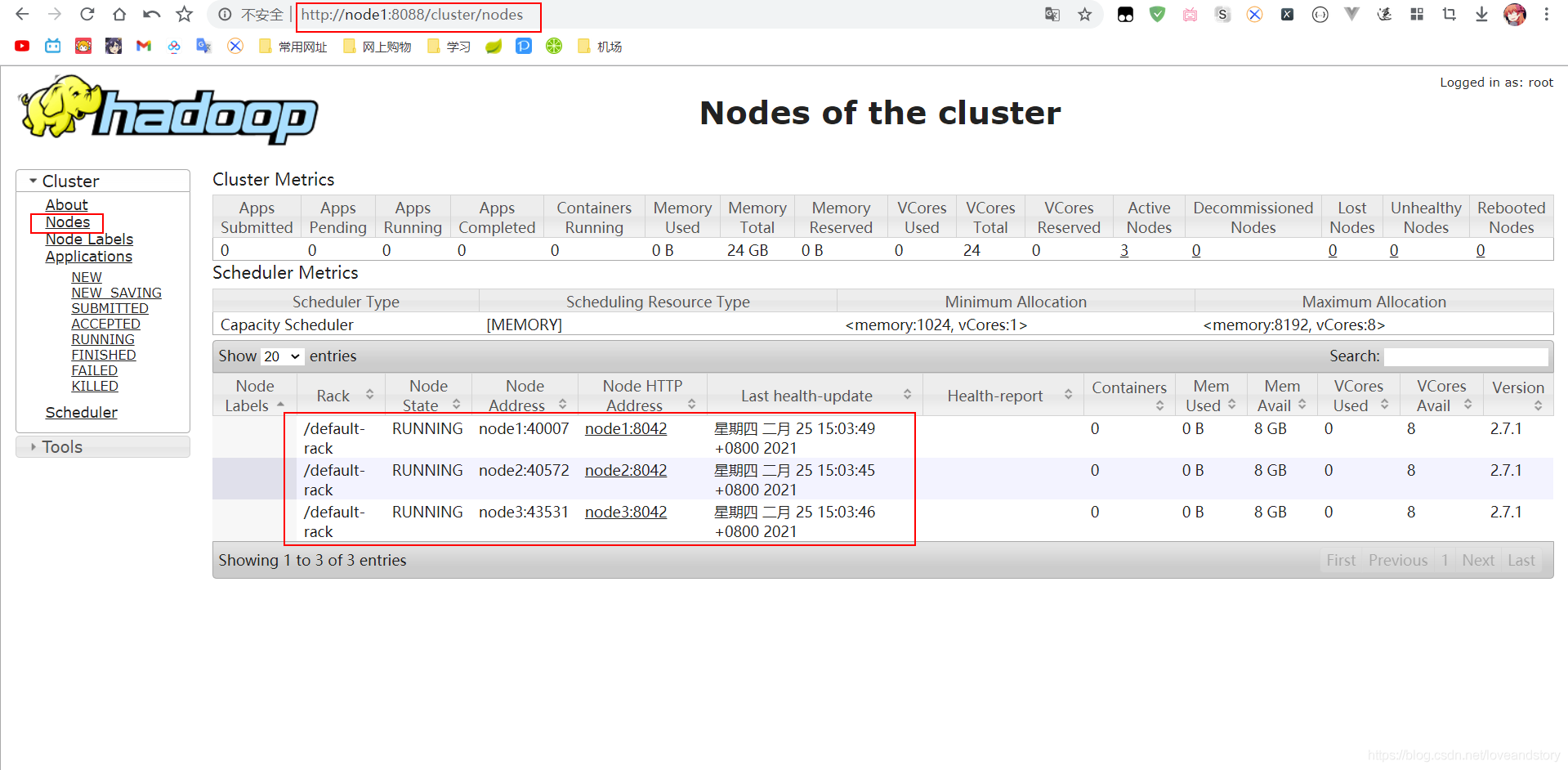
五、安裝zookeeper3.6.2
1.上傳、解壓安裝包
tar -zxvf apache-zookeeper-3.6.2-bin.tar.gz
2. 創建作業目錄
創建快照日志存放目錄:
mkdir -p dataDir
創建事務日志存放目錄:
mkdir -p dataLogDir
注意:如果不配置dataLogDir,那么事務日志也會寫在dataDir目錄中,這樣會嚴重影響zk的性能,因為在zk吞吐量很高的時候,產生的事務日志和快照日志太多,
3.修改組態檔
(1)在/zookeeper3.6.2/conf里復制一份zoo_sample.cfg重命名為 zoo.cfg
dataDir=/export/software/zookeeper3.6.2/dataDir
dataLogDir=/export/software/zookeeper3.6.2/dataLogDir
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
(2)在我們配置的dataDir指定的目錄下面,創建一個myid檔案,里面內容為一個數字,用來標識當前主機,conf/zoo.cfg檔案中配置的server.X中X為什么數字,則myid檔案中就輸入這個數字:
echo "1" > /usr/local/zookeeper-3.4.6/dataDir/myid
(3)遠程復制第一臺的zk到另外兩臺上,并修改myid檔案為2和3
scp -rp zookeeper-3.4.6 wang@node1:/export/software
scp -rp zookeeper-3.4.6 wang@node2:/export/software
4.添加環境變數
vim /etc/profile
export ZOOKEEPER_HOME=/usr/local/zookeeper-3.4.6
export PATH=$ZOOKEEPER_HOME/bin:$PATH export PATH
source /etc/profile
5.啟動
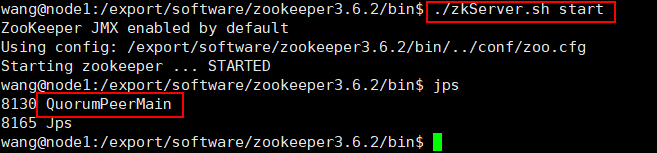
在ZooKeeper集群的每個結點上,執行啟動ZooKeeper服務的腳本:./zkServer.sh start,啟動后執行jps若有執行緒QuorumPeerMain則執行成功,
六、安裝hbase
1.上傳、解壓檔案
tar -zxvf hbase-2.0.4-bin.tar.gz
2.修改組態檔
(1)hbase-env.sh
export JAVA_HOME=/usr/local/jdk1.8
#使用自己安裝的zookeeper
export HBASE_MANAGES_ZK=false
(2)hbase-site.xml
<configuration>
<!--hbase.root.dir 將資料寫入哪個目錄 如果是單機版只要配置此屬性就可以,
value中file:/絕對路徑,如果是分布式則配置與hadoop的core-site.sh服務器、埠以及zookeeper中事先創建的目錄一致-->
<property>
<name>hbase.root.dir</name>
<value>hdfs://node1:9000/hbase</value>
</property>
<!--單機模式不需要配置,分布式配置此項,value值為true,多節點分布-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--單機模式不需要配置 分布式配置此項,value為zookeeper的conf下的zoo.cfg檔案下指定的物理路徑dataDir=/export/software/zookeeper3.6.2/dataDir-->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/export/software/zookeeper3.6.2/dataDir</value>
</property>
<!--埠默認60000-->
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<!--zookooper 服務啟動的節點,只能為奇數個-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>node1,node2,node3</value>
</property>
</configuration>
(3)regionservers

3.分配到其他機器
scp -rp /export/server/hbase-2.0.4 wang@node2:/export/server/
scp -rp /export/server/hbase-2.0.4 wang@node3:/export/server/
4.添加環境變數
vim /etc/profile
source /etc/profile
export HBASE_HOME=/export/server/hbase-2.0.4
export PATH=$PATH:$HBASE_HOME/bin
并更新到其他機器
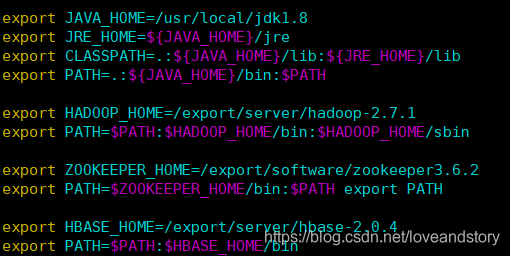
最后/etc/profile中的變數有:
5.啟動
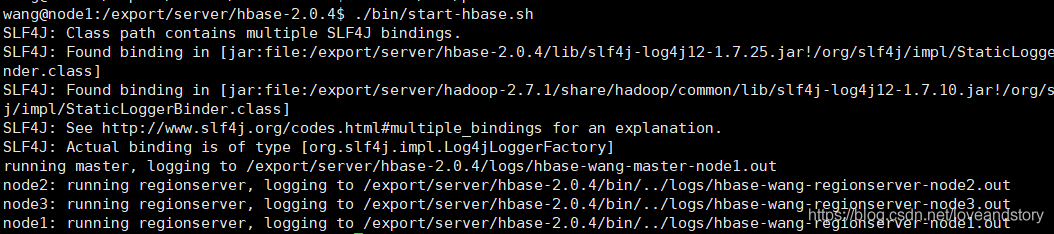
先啟動zookeeper、hadoop,最后在啟動hbase:./start-hbase.sh,
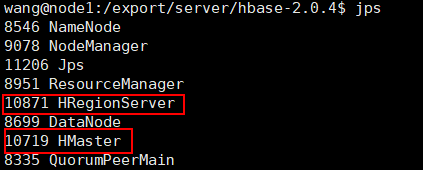
hbase shell啟動hbase客戶端
成功啟動后訪問:http://node1:16010
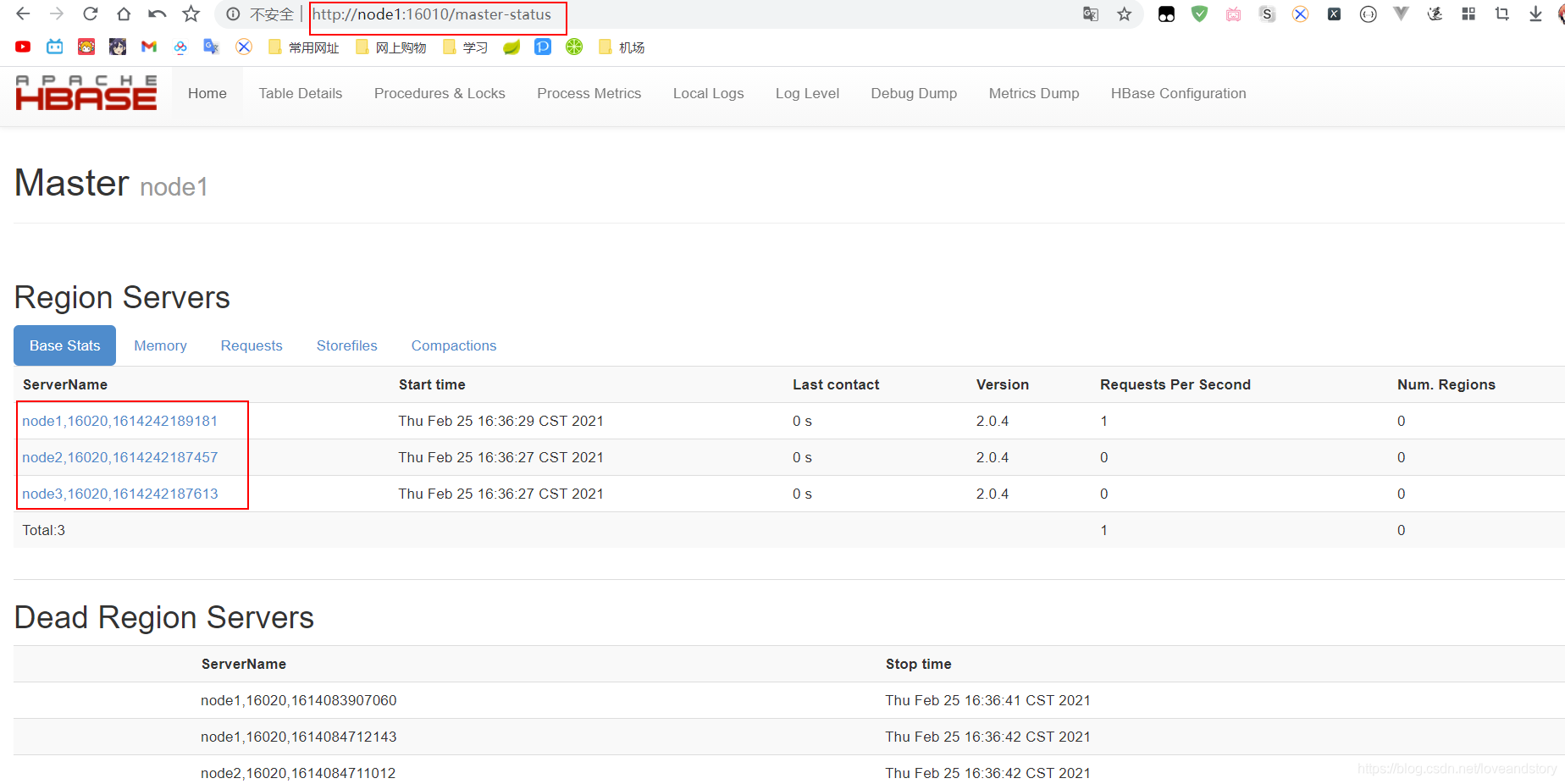
至此搭建成功!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/263778.html
標籤:其他