Spark3.0版本--chapter2.7--RDD持久化
- RDD持久化知識總結:
- 2.7.1RDD Cache 快取
- 2.7.2RDD CheckPoint檢查點
- 面試題:
RDD持久化知識總結:
RDD Cache總結知識要點:
一.RDD cache快取有兩個方法:cache和persist;persist更底層,因名字不好記,因此使用cache包一下
在使用時,默認會序列化形式快取在JVM中(堆記憶體中),但是兩個方法被呼叫不會立即快取,需要有action算子才會執行快取
簡記:cache底層呼叫persist(),并且快取級別默認選用MEMORY_ONLY,且cache()方法不支持快取方式,persist支持改快取級別,
二.為什么兩個方法被呼叫時不會立即快取?
因為spark中,這兩個方法特性:懶加載,因此我們在使用時,建議放在action算子之前,
三.RDD快取方式
記憶體 磁盤 記憶體和磁盤
優先存記憶體,記憶體存不下考慮是否能存磁盤,因實際代碼而定,
四.算子涉及到Shuffle自帶快取功能,
2.7.1RDD Cache 快取
RDD通過Cache或者Persist方法將前面的計算結果快取,默認情況下會把資料以序列化的形式快取在JVM的堆記憶體中,但是并不是這兩個方法被呼叫時立即快取,而是觸發后面的action算子時,該RDD將會被快取在計算節點的記憶體中,并供后面重用,
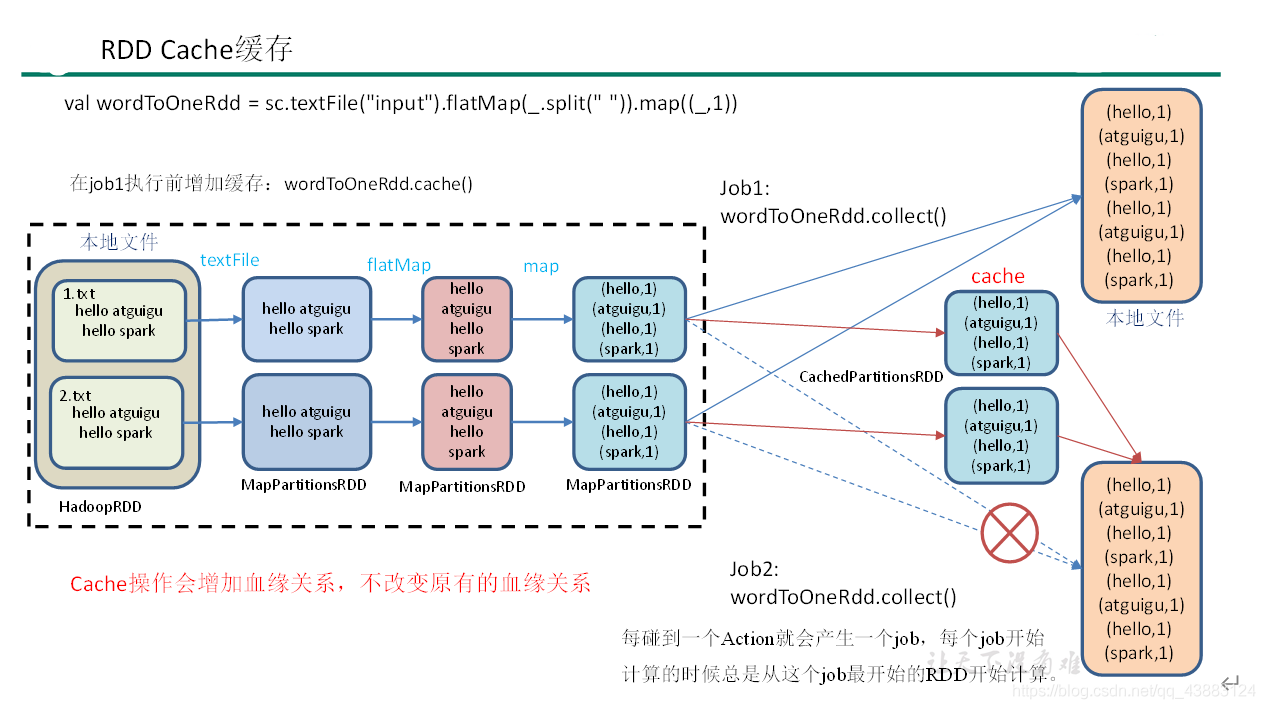
說明:
0)創建包名:com.atguigu.cache
1)代碼實作
準備檔案1.txt
hello spark
hello spark
hello scala
package com.atguigu.cache
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author dxy
* @date 2021/2/24 10:19
*/
object cache01 {
def main(args: Array[String]): Unit = {
//TODO 1.創建SparkConf并設定App名稱
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//TODO 2.創建SparkContext,該物件是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
val lineRDD: RDD[String] = sc.textFile("D:\\DevelopmentTools\\spark\\SparkCoreTest1109\\input\\1.txt")
val wordRDD: RDD[String] = lineRDD.flatMap(_.split(" "))
val word2OneRDD: RDD[(String, Int)] = wordRDD.map(
word => {
println("******************************")
(word, 1)
}
)
//word2OneRDD在快取前 查看血緣關系
println(word2OneRDD.toDebugString)
/**
* spark快取方法有兩個
* 1.cache 底層呼叫的就是persist(),并且快取級別默認選用的是MEMORY_ONLY
* 2.persist 更底層 更靈活 支持人為的修改快取級別 persisit(StorageLevel.快取級別)
*/
word2OneRDD.cache()
//word2OneRDD.persist(StorageLevel.MEMORY_AND_DISK_SER_2)
word2OneRDD.collect().foreach(println)
println("=======================")
//word2OneRDD在快取后,查看血緣關系
println(word2OneRDD.toDebugString)
word2OneRDD.collect().foreach(println)
//如果word2OneRDD用完以后,可以釋放快取
word2OneRDD.unpersist()
//TODO 3.關閉連接
sc.stop()
}
}
代碼說明:toDebugString查看血緣關系的
unpersist()使用說明:
下面有其他代碼,如果有影響的話,最好把快取釋放掉,
運行結果:
(2) MapPartitionsRDD[3] at map at cache01.scala:23 []
| MapPartitionsRDD[2] at flatMap at cache01.scala:21 []
| D:\DevelopmentTools\spark\SparkCoreTest1109\input\1.txt MapPartitionsRDD[1] at textFile at cache01.scala:19 []
| D:\DevelopmentTools\spark\SparkCoreTest1109\input\1.txt HadoopRDD[0] at textFile at cache01.scala:19 []
******************************
******************************
******************************
******************************
******************************
******************************
(hello,1)
(spark,1)
(hello,1)
(spark,1)
(hello,1)
(scala,1)
=======================
(2) MapPartitionsRDD[3] at map at cache01.scala:23 [Memory Deserialized 1x Replicated]
| CachedPartitions: 2; MemorySize: 568.0 B; ExternalBlockStoreSize: 0.0 B; DiskSize: 0.0 B
| MapPartitionsRDD[2] at flatMap at cache01.scala:21 [Memory Deserialized 1x Replicated]
| D:\DevelopmentTools\spark\SparkCoreTest1109\input\1.txt MapPartitionsRDD[1] at textFile at cache01.scala:19 [Memory Deserialized 1x Replicated]
| D:\DevelopmentTools\spark\SparkCoreTest1109\input\1.txt HadoopRDD[0] at textFile at cache01.scala:19 [Memory Deserialized 1x Replicated]
(hello,1)
(spark,1)
(hello,1)
(spark,1)
(hello,1)
(scala,1)
結果說明:
可以看到cache和persist快取比較靈活,可以找到血緣關系parent
2)原始碼決議
點擊流程
第一步:點擊cache()

第二步:點擊persist

第三步:點擊StorageLevel

結果:就是下面代碼
mapRdd.cache()
def cache(): this.type = persist()
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
得出點擊原始碼結論
RDD持久化中:
1.cache底層是persist,cache不支持改快取方式,persist支持改快取級別,cache快取默認選用MEMORY_ONLY
2.persist更底層、更靈活,支持人為修改快取級別
修改方式:
例如
對應RDD.persist(StorageLevel.快取級別)
注意:默認的存盤級別都是僅在記憶體存盤一份,在存盤級別的末尾加上“_2”表示持久化的資料存為兩份,SER:表示序列化,
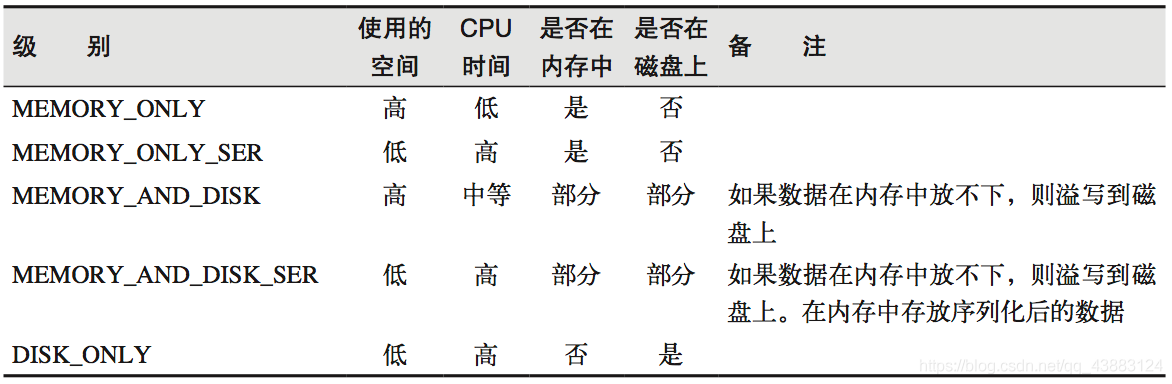
快取有可能丟失,或者存盤于記憶體的資料由于記憶體不足而被洗掉,RDD的快取容錯機制保證了即使快取丟失也能保證計算的正確執行,通過基于RDD的一系列轉換,丟失的資料會被重算,由于RDD的各個Partition是相對獨立的,因此只需要計算丟失的部分即可,并不需要重算全部Partition,
3)自帶快取算子
Spark會自動對一些Shuffle操作的中間資料做持久化操作(比如:reduceByKey),這樣做的目的是為了當一個節點Shuffle失敗了避免重新計算整個輸入,但是,在實際使用的時候,如果想重用資料,仍然建議呼叫persist或cache,
object cache02 {
def main(args: Array[String]): Unit = {
//1.創建SparkConf并設定App名稱
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.創建SparkContext,該物件是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3. 創建一個RDD,讀取指定位置檔案:hello atguigu atguigu
val lineRdd: RDD[String] = sc.textFile("input1")
//3.1.業務邏輯
val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" "))
val wordToOneRdd: RDD[(String, Int)] = wordRdd.map {
word => {
println("************")
(word, 1)
}
}
// 采用reduceByKey,自帶快取
val wordByKeyRDD: RDD[(String, Int)] = wordToOneRdd.reduceByKey(_+_)
//3.5 cache操作會增加血緣關系,不改變原有的血緣關系
println(wordByKeyRDD.toDebugString)
//3.4 資料快取,
//wordByKeyRDD.cache()
//3.2 觸發執行邏輯
wordByKeyRDD.collect()
println("-----------------")
println(wordByKeyRDD.toDebugString)
//3.3 再次觸發執行邏輯
wordByKeyRDD.collect()
Thread.sleep(1000000)
//4.關閉連接
sc.stop()
}
}
訪問http://localhost:4040/jobs/頁面,查看第一個和第二個job的DAG圖,說明:增加快取后血緣依賴關系仍然有,但是,第二個job取的資料是從快取中取的,
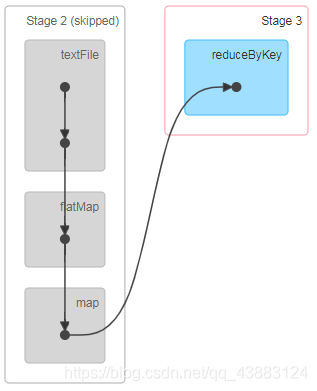
自己在IDEA中測驗:更上面代碼case02類似
我使用正常的wordcount進行測驗,想要實作,需要讓程式睡一會,查看4040web端訪問進行測驗
package com.atguigu.cache
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author dxy
* @date 2021/2/24 10:19
*/
object cache02 {
def main(args: Array[String]): Unit = {
//TODO 1.創建SparkConf并設定App名稱
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//TODO 2.創建SparkContext,該物件是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
val lineRDD: RDD[String] = sc.textFile("D:\\DevelopmentTools\\spark\\SparkCoreTest1109\\input\\1.txt")
val wordRDD: RDD[String] = lineRDD.flatMap(_.split(" "))
val word2OneRDD: RDD[(String, Int)] = wordRDD.map(
word => {
println("******************************")
(word, 1)
}
)
val resultRDD: RDD[(String, Int)] = word2OneRDD.reduceByKey(_+_)
resultRDD.collect().foreach(println)
println("=======================================")
resultRDD.collect().foreach(println)
Thread.sleep(Long.MaxValue)
//TODO 3.關閉連接
sc.stop()
}
}
代碼說明:
reduceByKey()走shuffle,自帶快取
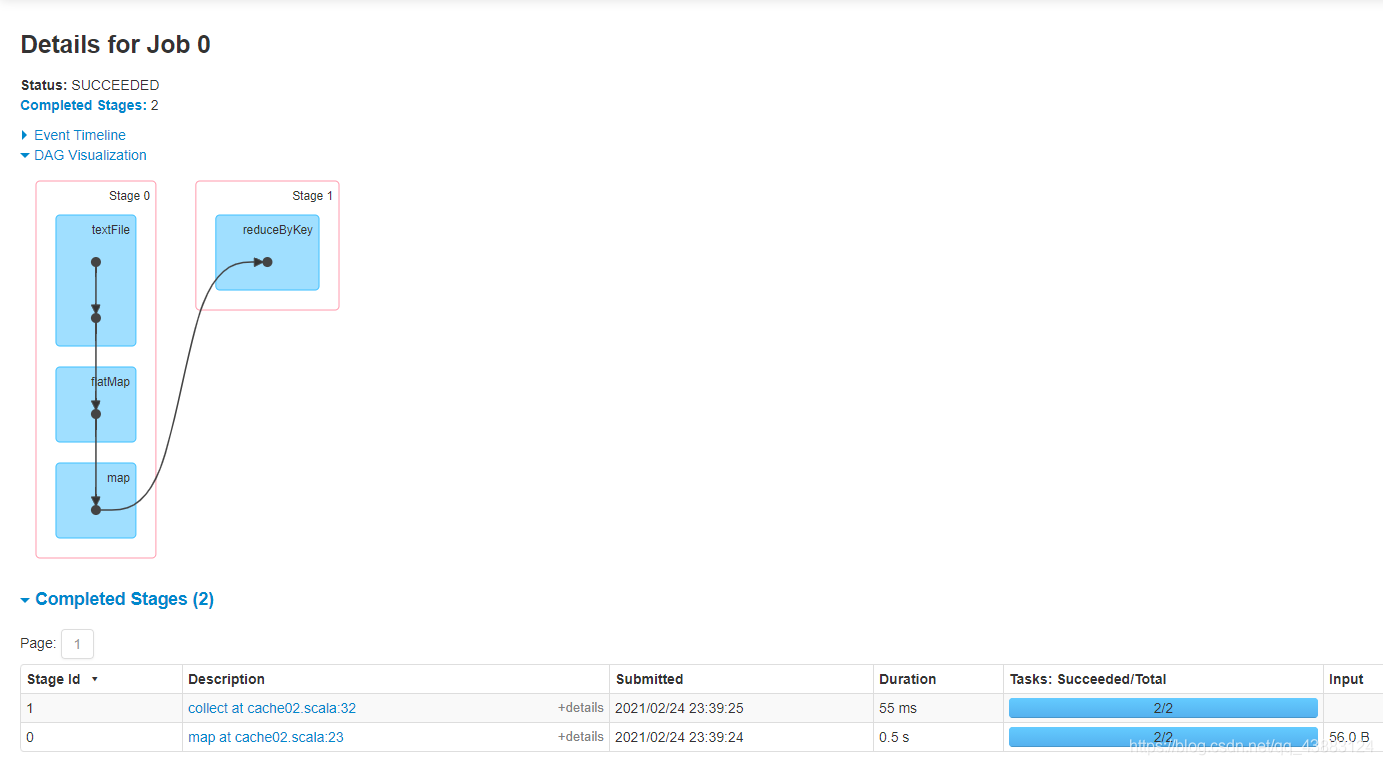
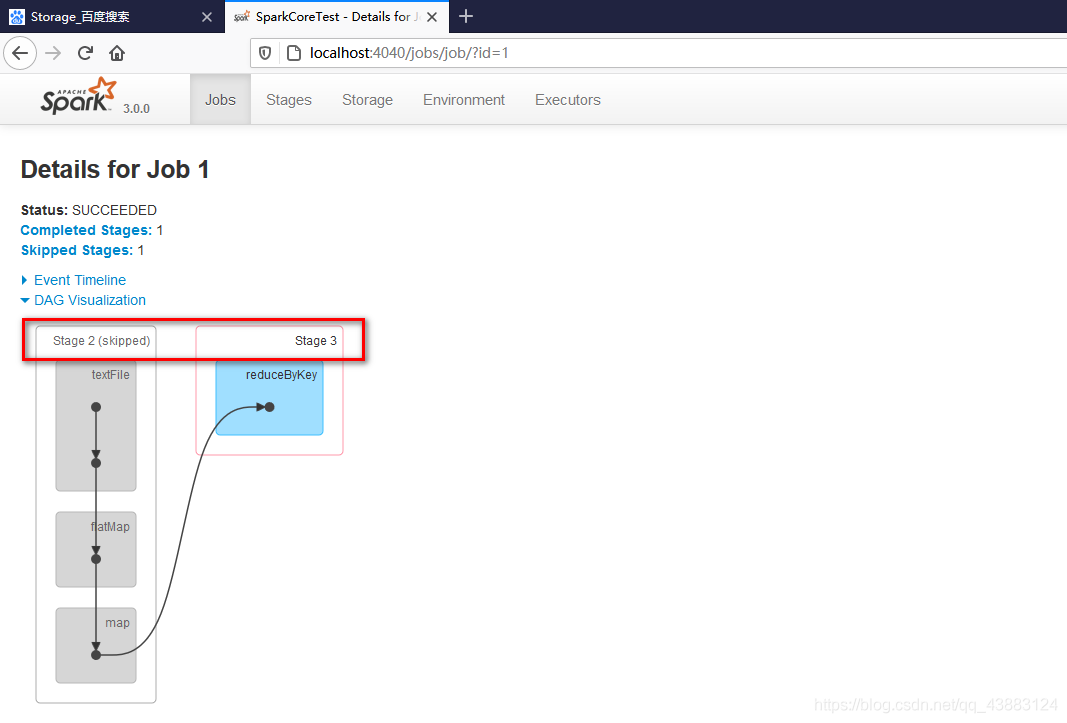
因此得出結論:
Shuffle自帶快取功能,
2.7.2RDD CheckPoint檢查點
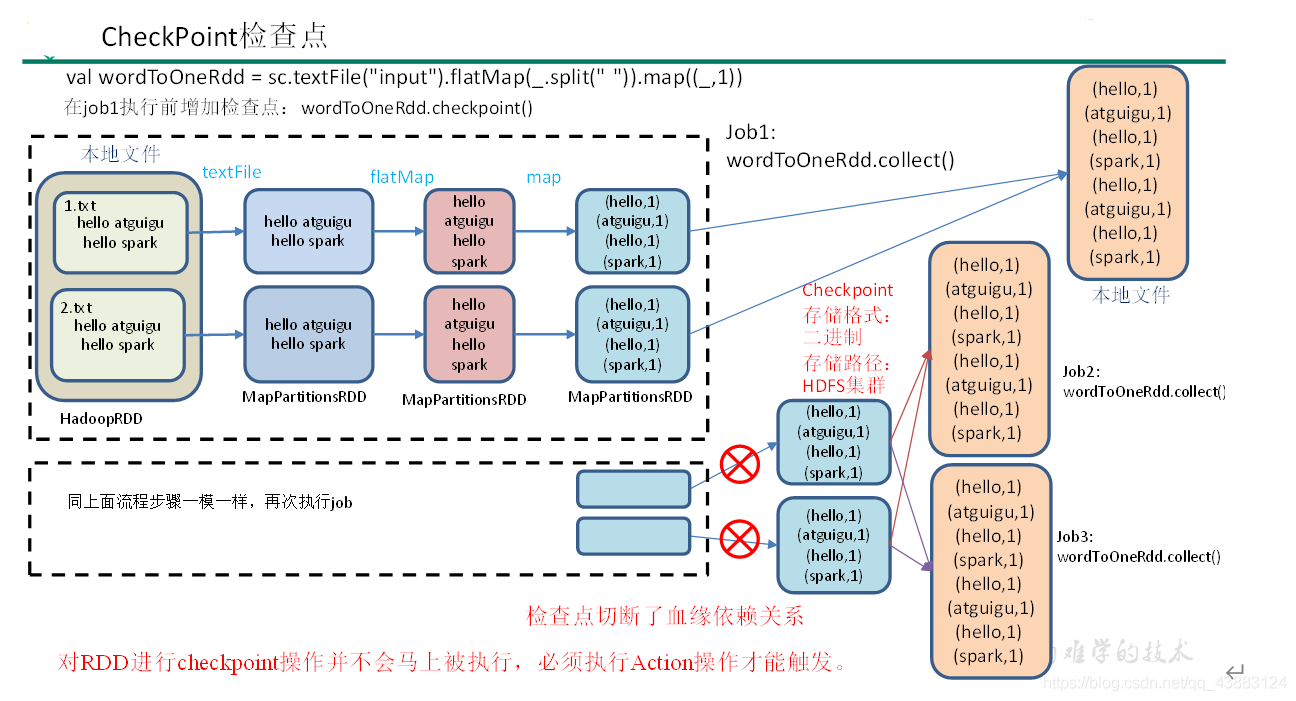
1)檢查點:是通過將RDD中間結果寫入磁盤,
2)為什么要做檢查點?
由于血緣依賴過長會造成容錯成本過高,這樣就不如在中間階段做檢查點容錯,如果檢查點之后有節點出現問題,可以從檢查點開始重做血緣,減少了開銷,
3)檢查點存盤路徑:Checkpoint的資料通常是存盤在HDFS等容錯、高可用的檔案系統
4)檢查點資料存盤格式為:二進制的檔案
5)檢查點切斷血緣:在Checkpoint的程序中,該RDD的所有依賴于父RDD中的資訊將全部被移除,
6)檢查點觸發時間:對RDD進行Checkpoint操作并不會馬上被執行,必須執行Action操作才能觸發,但是檢查點為了資料安全,會從血緣關系的最開始執行一遍,
7)設定檢查點步驟
(1)設定檢查點資料存盤路徑:sc.setCheckpointDir("./checkpoint1")
(2)呼叫檢查點方法:wordToOneRdd.checkpoint()
8)代碼實作
package com.atguigu.cache
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author dxy
* @create 2021-02-24 9:45
*/
object checkpoint01 {
def main(args: Array[String]): Unit = {
//TODO 1 創建SparkConf組態檔,并設定App名稱
val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//TODO 2 利用SparkConf創建sc物件
val sc = new SparkContext(conf)
//使用檢查點之前,一定要先設定檢查點存盤路徑
sc.setCheckpointDir("D:\\IdeaProjects\\SparkCoreTest1109\\ck")
val lineRDD: RDD[String] = sc.textFile("D:\\IdeaProjects\\SparkCoreTest1109\\input\\1.txt")
val wordRDD: RDD[String] = lineRDD.flatMap(_.split(" "))
val word2oneRDD: RDD[(String, Long)] = wordRDD.map(
word => {
(word, System.currentTimeMillis())
}
)
//word2oneRDD在做檢查點前 查看血緣關系
println(word2oneRDD.toDebugString)
//在檢查點之前先做一下快取
word2oneRDD.cache()
word2oneRDD.checkpoint()
word2oneRDD.collect().foreach(println)
println("============================")
//word2oneRDD在做檢查點后 查看血緣關系
println(word2oneRDD.toDebugString)
word2oneRDD.collect().foreach(println)
println("============================")
word2oneRDD.collect().foreach(println)
Thread.sleep(Long.MaxValue)
//TODO 3 關閉資源
sc.stop()
}
}
運行結果:
(2) MapPartitionsRDD[3] at map at checkpoint01.scala:26 []
| MapPartitionsRDD[2] at flatMap at checkpoint01.scala:24 []
| D:\DevelopmentTools\spark\SparkCoreTest1109\input\1.txt MapPartitionsRDD[1] at textFile at checkpoint01.scala:22 []
| D:\DevelopmentTools\spark\SparkCoreTest1109\input\1.txt HadoopRDD[0] at textFile at checkpoint01.scala:22 []
(hello,1614216508492)
(spark,1614216508493)
(hello,1614216508493)
(spark,1614216508493)
(hello,1614216508492)
(scala,1614216508494)
========================
(2) MapPartitionsRDD[3] at map at checkpoint01.scala:26 [Memory Deserialized 1x Replicated]
| CachedPartitions: 2; MemorySize: 680.0 B; ExternalBlockStoreSize: 0.0 B; DiskSize: 0.0 B
| ReliableCheckpointRDD[4] at collect at checkpoint01.scala:40 [Memory Deserialized 1x Replicated]
(hello,1614216508492)
(spark,1614216508493)
(hello,1614216508493)
(spark,1614216508493)
(hello,1614216508492)
(scala,1614216508494)
========================
(hello,1614216508492)
(spark,1614216508493)
(hello,1614216508493)
(spark,1614216508493)
(hello,1614216508492)
(scala,1614216508494)
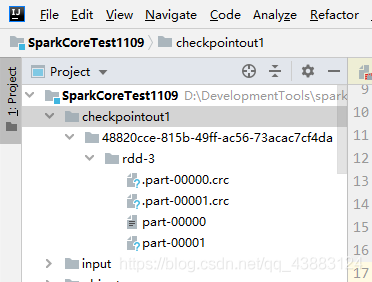
讀檔案,沒有設定磁區默認為2,設定了磁區與2取最小值
執行緒睡一會兒,打開4040埠
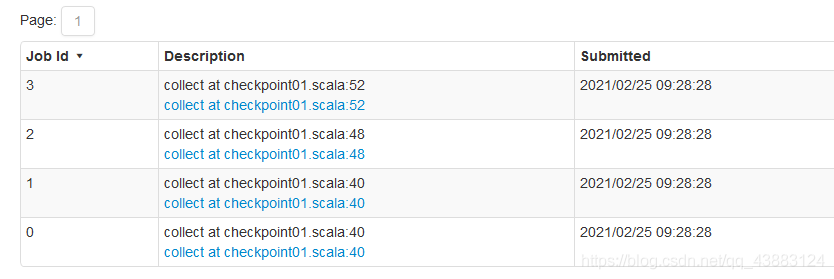
發現有4個job,3個行動算子=3個job,還有一個job在切斷血緣關系之前,最后認一次parent,會從血緣關系開始執行一遍,
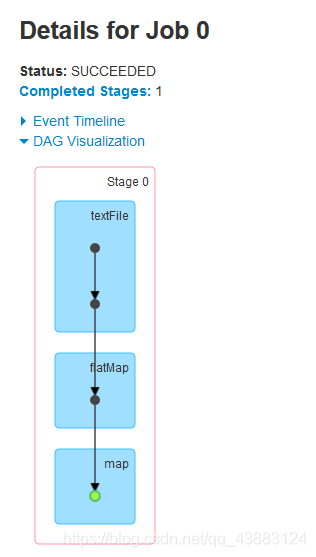
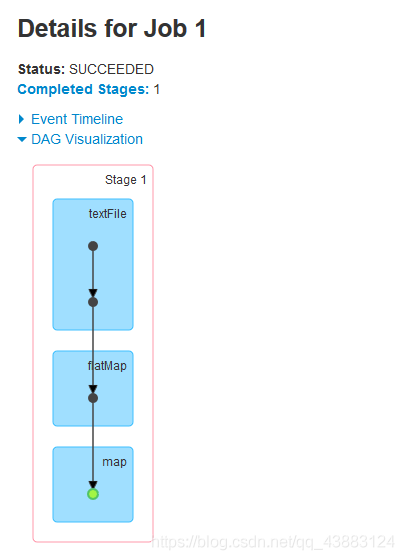
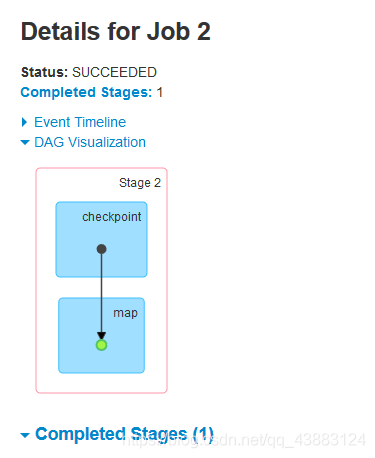
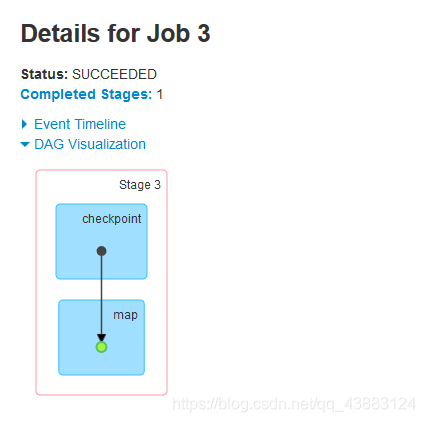
運行結果得出結論:
1.檢查點會切斷血緣關系,父RDD資訊全部被洗掉;
2.只有遇到行動算子才會執行檢查點操作;
3.檢查點存盤按照磁區來存,存盤檔案格式是二進制
4.使用檢查點時需要在使用之前一定要設定存盤路徑,不然運行報錯,
5.檢查點設定方式:
sc.setCheckpointDir(指定路徑)
如果在本地存盤,只需要指定本地路徑即可,
如果指定存盤在HDFS上,需要執行以下操作:
// 1.設定訪問HDFS集群的用戶名
System.setProperty("HADOOP_USER_NAME","atguigu")
// 2.需要設定路徑.需要提前在HDFS集群上創建/checkpoint路徑
sc.setCheckpointDir("hdfs://hadoop102:8020/checkpoint")
面試題:
1.在使用檢查點時,對集群比較自信,不想在切斷血緣關系之前再執行一遍job,怎么處理?
使用檢查點之前先cache或者persist一下,控制臺可以看到效果,但4040埠效果跟之前一下,
如果不設定的話,假如使用3次collect行動算子,第二次和第一次map的value結果不一致,第三次好第二次一致,
如果先快取在檢查點三次map的value是一致的,
value指獲取系統當前時間,(如上面代碼)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/263781.html
標籤:其他