**
大資料生態與spark簡介
**
首先了解一下,大資料是什么呢?
大資料(big data),指無法在一定時間范圍內用常規軟體工具進行捕捉、管理和處理的資料集合,是需要新處理模式才能具有更強的決策力、洞察發現力和流程優化能力的海量、高增長率和多樣化的資訊資產,
大資料的四大V:資料量大(Volume)、速度快(Velocity)、型別多(Variety)、價值密度低(Value)
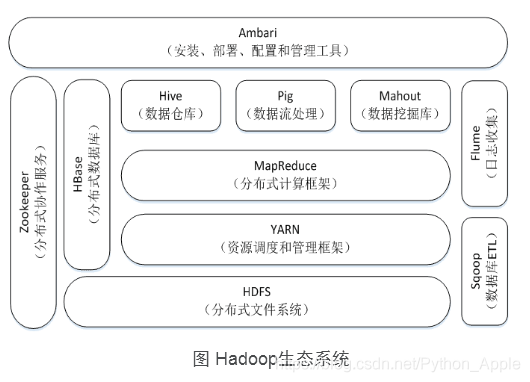
第一代誕生的大資料生態圈是由Google通過各種發表關于Hadoop的相關論文,開源等措施推動的,然后各個成員跟隨,例如Apache等,其標志性的組件為:Hadoop HDFS、Hadoop MapReduce, HBase、Hive,伴隨著上面四個組件的成熟,第一代大資料生態圈逐漸成型,其整體架構見下圖:
spark又是什么呢?
很多的時間場景下,Hadoop的計算速度以及模式已經不能完全的滿足計算分析的需求,所以,在hadoop的基礎上,我們增加了另外一個新的技術===Spark
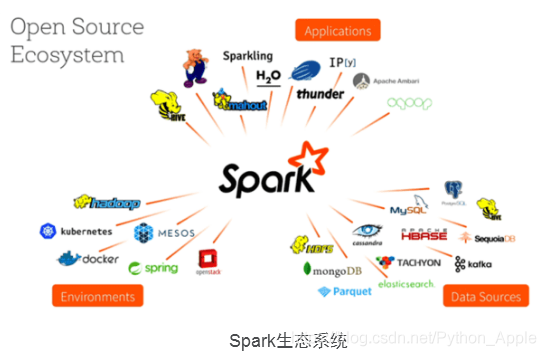
Apache Spark是專為大規模資料處理而設計的快速通用的計算引擎 ,現在形成一個高速發展應用廣泛的生態系統,
Spark最初由美國加州大學伯克利分校(UC Berkeley)的AMP實驗室于2009年開發,是基于記憶體計算的大資料并行計算框架,可用于構建大型的、低延遲的資料分析應用程式
Spark具有如下幾個主要特點:
?運行速度快:使用DAG執行引擎以支持回圈資料流與記憶體計算
?容易使用:支持使用Scala、Java、Python和R語言進行編程,可以通過Spark Shell進行互動式編程
?通用性:Spark提供了完整而強大的技術堆疊,包括SQL查詢、流式計算、機器學習和圖演算法組件
?運行模式多樣:可運行于獨立的集群模式中,可運行于Hadoop中,也可運行于Amazon EC2等云環境中,并且可以訪問HDFS、Cassandra、HBase、Hive等多種資料源
為提高spark的容錯性,引進了分布式彈性資料集(RDD)的抽象
他是分布在節點上的一組只讀資料集合,可以通過不同的算子進行操作,而這些算子主要可以分為三類:
1、transformation類算子:代表的map、flatmap等,是一種延遲操作,提前對資料進行操作
2、Action類算子:觸發transformation類的執行,提交job,并將資料輸出spark
3、持久化類算子:cache、persist算子,將資料持久化到記憶體,提升了計算的效率
Spark好用的地方在于
首先,高級 API 剝離了對集群本身的關注,Spark 應用開發者可以專注于應用所要做的計算本身,
其次,Spark 很快,支持互動式計算和復雜演算法,
最后,Spark 是一個通用引擎,可用它來完成各種各樣的運算,包括 SQL 查詢、文本處理、機器學習等,而在 Spark 出現之前,我們一般需要學習各種各樣的引擎來分別處理這些需求,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/264123.html
標籤:其他
下一篇:大資料服務器環境準備(三臺服務)