文章目錄
- (學習筆記)吳恩達深度學習課程第一課—神經網路與深度學習
- 第一周 深度學習概述
- 一、什么是神經網路
- 二、用神經網路進行監督學習
- 第二周 神經網路基礎
- 一、二分分類
- 二、Logistic回歸
- 三、logistic回歸損失函式
(學習筆記)吳恩達深度學習課程第一課—神經網路與深度學習
視頻鏈接:https://www.bilibili.com/video/BV164411m79z?p=8&spm_id_from=pageDriver
第一周 深度學習概述
一、什么是神經網路
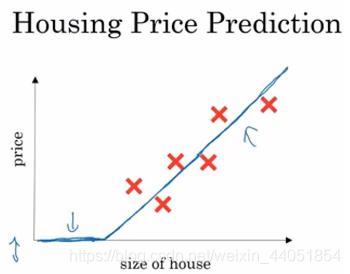
? 在房價預測問題中,我們根據訓練資料訓練出一條如上圖中的曲線,來盡可能擬合這些資料,然后就可以該曲線來根據房屋大小預測房價,這個擬合房價的曲線函式,就可以看成一個非常簡單的神經網路,
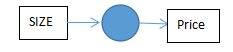
? size作為輸入,price是輸出,而中間的小圓就是一個獨立的神經元,該神經元完成的任務就是輸入size,完成線性計算,取不小于0的值,最后得到輸出的預測price,而復雜一點的神經網路,就是把這樣的單個神經元堆疊起來形成的,
(上面的曲線所表示的函式,起始為0,后面轉變為一條直線,這樣的函式被稱作ReLU函式)
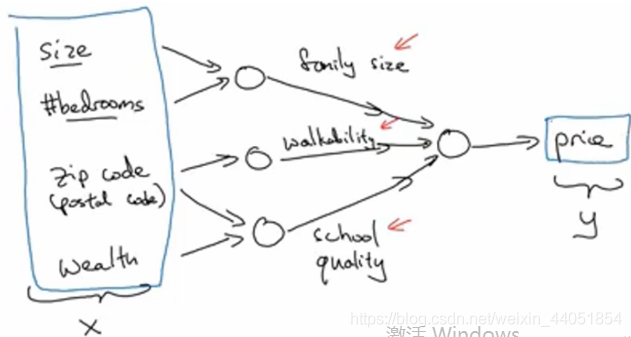
? 上圖的每一個圓可能都表示一個ReLU函式,或是其他非線性的函式(基于房屋面積和臥室數量來估計家庭人口,基于郵編可以估計步行化程度,基于郵編也可以估計附近學校的質量),事實上房價和人們關注什么,有很大關系,在該例中,家庭人口、步行化程度、學校質量都可以幫助我們預測房價,這就是一個使用多神經元的神經網路,
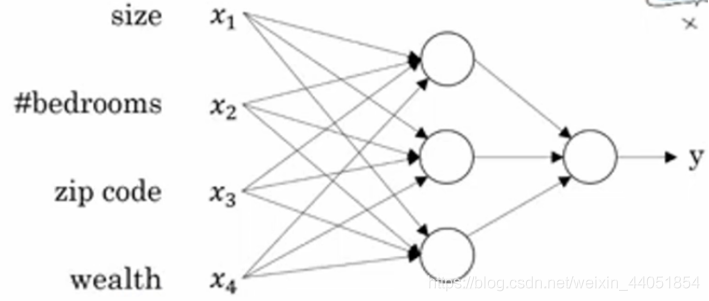
? 在已知這些輸入的特征的前提下,神經網路的作業就是預測對應的房價,而圖中的圈圈也被稱為神經網路的隱藏單元,負責計算輸入進來的資料,最終得到預測房價y,
二、用神經網路進行監督學習
? 監督學習,需要給機器一組含有標簽的訓練集,所謂含有標簽,就是告訴機器,這個輸入屬于哪個類,機器通過在訓練集中訓練,最終得到一個可以用來預測的函式,而無監督學習則沒有這個標簽,以下為神經網路進行監督學習的應用列舉,
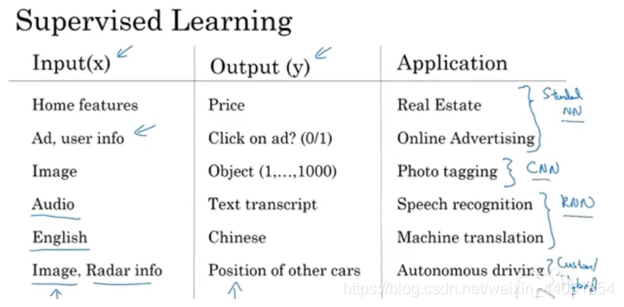
? 下圖中從左到右依次是標準的神經網路,卷積神經網路(CNN)和回圈神經網路(RNN),CNN主要應用于影像處理,而RNN主要應用于處理一維序列資料,
? 機器學習也被應用于結構化資料和非結構化資料,結構化資料是資料的資料庫,例如在房價預測中,你可能有一個資料庫或者資料列,告訴你房間大小、臥室數量…這就是結構化資料,每個特征都有著清晰的定義,與之相反的就是非結構化資料,比如音頻、影像,相比于結構化資料,計算機其實很難理解非結構化資料,而通過深度學習、神經網路,現在的計算機能夠更好地理解和解釋非結構化資料,語音識別、影像識別、自然語言文字處理等技術應運而生,
第二周 神經網路基礎
一、二分分類
二分類問題例如,輸入一張圖片,判斷是不是貓,是則輸出1,不是就輸出0,

計算機是如何表達一張圖片的?
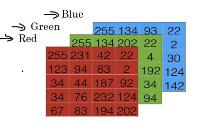
? 計算機保存一張圖片,需要保存三個獨立矩陣,分別對應**紅(R)、綠(G)、藍(B)**三個顏色通道,例如,如果輸入圖片是64×64像素的(長寬各有64個像素),就有三個64×64的矩陣,把這三個矩陣中的所有像素亮度值放進一個特征向量X中,就可以用X來表示這一張圖片:
? x=(255,231,…,255,134,…,255,134,…)T ,如果圖片是64×64的,那么向量X的總維度就是12288(即64×64×3),一般用nx或n來表示輸入的特征向量的維度,
? 在二分類問題中,目標是訓練出一個分類器,它以圖片的特征向量x作為輸入,預測輸出的結果y是1還是0,
以下是課程中需要用到的一些符號:
(x,y):表示一個單獨的樣本,例如x是一個圖片的特征向量,y是1或0;
m:表示訓練集由m個訓練樣本構成;
(x(1),y(1)):表示樣本1的輸入和輸出,依次類推;
X:可以用來表示訓練集中所有x組成的矩陣,X=(x(1),x(2),…,x(m)),該矩陣有nx行m列;
Y:可以用來表示所有y組成的矩陣,Y=(y(1),y(2),…,y(m)),該矩陣有1行m列,
二、Logistic回歸
? Logistic回歸演算法,是一種廣義的線性回歸分析模型,在監督學習問題中用于預測某事發生的概率,在上述的二分類問題中,輸入一張貓圖,用x表示,我們可得到輸出y^ =P(y=1|x),我們希望y^ 告訴我們這是一張貓圖的概率:
- x是一個nx維向量;
- Logistic回歸的引數w也是一個nx維的向量,而b是一個實數;
- 所以,已知x、w、b,我們可以使用線性方程計算出y^ =wTx+b,
以上是我們做線性回歸的常規做法,但這并不是一個很好的二分類演算法,因為我們希望y^ 是y=1的概率,所以y^ 應該介于0和1之間,但是這很難實作,因為wTx+b的值可能比1大,也可能是負值,這樣的概率是沒有意義的 ,所以,在logistic回歸中,我們對wTx+b這個量使用sigmoid函式,即:
? y^ =σ(wTx+b)
sigmoid函式就是下圖這樣從0到1的平滑曲線:
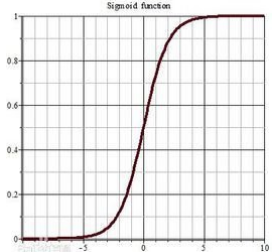
我們用z來表示(wTx+b),上圖的橫坐標表示的就是z,則:y^ =σ(z),事實上σ(z)=1/(1+e-z),可觀察得到,如果z很大,σ的值是很接近1的,與上圖的表達是一致的,
通過sigmoid函式的處理,z值是個遠大于1的數時,得到的概率就接近1,z值是個負數時,得到的概率就接近0,解決了上文的概率無意義的問題,
三、logistic回歸損失函式
為了訓練得出logistic回歸函式的引數w和b,需要定義一個成本函式(也稱代價函式),
給定一個訓練集,我們希望通過訓練,得出w和b,來得到盡可能精確的模型,而通過定義損失函式L,可以用來衡量我們的預測單個樣本的輸出值y^ 和y(實際值)有多接近,在logistic回歸中,我們通常使用這樣的損失函式:
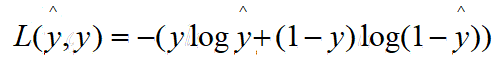
這個損失函式是怎么起作用的呢?
我們假設y=1時,要讓L盡可能小,把1帶進去就是讓 -ylogy^ 盡可能小,也即讓ylogy^ 盡可能大,也就是讓y^ 盡可能大,但是因為y^ 是sigmoid函式得到的,永遠不會比1大,所以只能讓y^ 盡可能接近1,
假設y=0時,損失函式就變為了-log(1-y^ ),同理,想讓該函式盡可能小,就需要(1-y^ )盡可能大,也即讓y^ 盡可能小,也就是讓y^ 盡可能接近0,
綜上,y=1時,我們讓y^ 盡可能接近1,y=0時,我們讓y^ 盡可能接近0,這就是該損失函式所起的作用,
事實上,損失函式是在單個訓練樣本中定義的,它衡量了模型在單個訓練樣本上的表現,下面我們定義一個成本函式J,用來衡量模型在全體訓練樣本的表現:
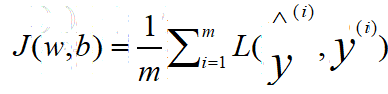
也即是求取了所有樣本的損失函式的值的平均,
也就是說損失函式只適用于單個訓練樣本,而成本函式,是基于引數的總成本,所以在訓練logistic回歸模型時,我們要找到合適的引數w和b,讓成本函式J盡可能地小,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/264275.html
標籤:AI