三、Python資料挖掘(Numpy庫)
目錄:
- 三、Python資料挖掘(Numpy庫)
- 一、Numpy 簡介
- 二、認識N維陣列 ndarray 屬性
- 1.ndarray 屬性
- 陣列名 = np.array(N維陣列)
- 陣列名 = np.array(N維陣列, dtype=np.?)
- 2.ndarray 的形狀 shape(tuple)
- 3.ndarray 的型別 dtype
- 三、基本操作
- 1.生成陣列的方法
- 陣列名 = np.zeros(shape=?, dtype=?)
- 陣列名 = np.ones(shape, dtype=?)
- 新陣列 = np.array(舊陣列)
- 新陣列 = np.copy(舊陣列)
- 陣列名 = np.asarray(舊陣列)
- 陣列名.flatten()
- np.linspace(start, stop, num, endpoint, retstep, dtype)
- np.arange([start, ]stop[, step])
- np.random.rand(d0, d1,...,dn)
- np.random.uniform(low=0.0, high=1.0, size=None)
- np.random.randn(d0, d1,...,dn)
- np.random.normal(loc=0.0, scale=1.0, size=None)
- 2.陣列的索引和切片
- 陣列名[start:stop]
- 陣列名[row, [start:stop]]
- 陣列名[axis[, row][, start:stop]]
- 3.陣列形狀的修改
- 陣列名.reshape(shape)
- 陣列名.resize(shape)
- 陣列名.T
- 3.陣列資料型別的修改
- 陣列名.astype(dtype)
- 陣列名.tobytes()
- 4.陣列的去重
- np.unique(陣列)
- 四、ndarray 運算
- 1.邏輯運算
- 直接使用陣列名的邏輯運算式 ? 布爾陣列
- 陣列名[布爾陣列]
- 陣列名[布爾陣列] = 值
- np.all(布爾陣列)
- np.any(布爾陣列)
- np.where(布爾陣列, data1, data2)
- 2.統計運算
- np.argmax(陣列[, axis=])
- np.argmin(陣列[, axis=])
- 3.陣列間的運算
- 廣播機制 broadcast
- 4.矩陣運算
- 矩陣名 = np.array()
- 矩陣名 = np.mat()
- np.matmul(a, b, out=None)
- np.dot(a, b)
- matrix1 * matrix1
- ndarray1 @ ndarray2
- 5.np.dot() 與 np.matmul() 的區別
- 6.合并與分割
- np.hstack(*args)
- np.vstack(*args)
- np.concatenate(*args, axis=)
- np.split(ndarray, indices_or_sections, axis=0)
- 7.IO操作與資料處理
- np.genfromtxt(fname, delimiter=?)
- np.count_nonzero(ndarray, axis=None, *, keepdims=False)
- np.isnan(ndarray)
- 8.擴展:axis=0或1 的互動方式
一、Numpy 簡介
- 什么是 Numpy?
Numpy 是一個開源的Python科學計算庫,用于快速處理任意維度的陣列
Numpy 支持常見的陣列和矩陣操作,對于同樣的數值計算任務,使用Numpy 比直接使用Python要簡潔得多
Numpy 使用 ndarray 物件來處理多維陣列,該物件是一個快速而靈活的大資料容器
- ndarray 的簡介:
Numpy 提供了一個核心的資料結構——N維陣列型別ndarray ,它描述了相同型別的 “items” 集合
- 什么要使用 ndarray 而不使用Python的原生 list?
ndarray與Python的原生 list 比較,其效率遠遠高于 list
機器學習與深度學習的最大特點就是大量的資料運算,那么如果沒有一個快速的解決方案,那么可能現在Python也在機器學習領域也無法達到好的效果
Numpy 專門針對 ndarray 的操作和運算進行了設計,所以陣列的存盤效率和輸入輸出性能遠優于Python中的嵌套串列,陣列越大,Numpy 的這種優勢就越發明顯
ndarray 支持并行化運算(向量化運算),適合于機器學習
Numpy 底層使用C語言撰寫,內部解除了GIL(全域解釋器鎖),其對陣列的操作速度不受Python解釋器的限制,效率遠高于純Python代碼;并且支持多執行緒
Numpy 中的函式與方法只能作用于 ndarray 物件(重要)
二、認識N維陣列 ndarray 屬性
ndarray 創建的陣列中,要求其各元素的資料型別都是相同的,與Python的原生 list 不同,Python的原生 list 可以存盤不同資料型別的資料(重要)
1.ndarray 屬性
通過呼叫以下方法可以訪問到屬性值
| 屬性名 | 含義 |
|---|---|
| ndarray.shape | 陣列的維度形狀,是一個元組 |
| ndarray.ndim | 陣列維度數 |
| ndarray.size | 陣列中的元素總數量 |
| ndarray.itemsize | 陣列中一個元素的長度(位元組) |
| ndarray.dtype | 陣列元素的型別 |
- 陣列維度的元組,如:(6, 8) 指的是 6 行 8 列 的二維陣列
- 在用 ndarray 創建陣列的時候,如果沒有指定型別,則 dtype 默認是整數 int64 或 浮點數 float64
- shape 和 dtype 是最重要的兩種屬性
匯入模塊:
import numpy as np
陣列名 = np.array(N維陣列)
使用ndarray創建一個N維陣列
陣列名 = np.array(N維陣列, dtype=np.?)
指定資料型別地創建一個N維陣列
dtype=np. 資料型別屬性,如:dtype=np.int64,也可以使用簡寫 dtype=‘i8’,后面會詳細介紹
2.ndarray 的形狀 shape(tuple)
例:創建陣列
import numpy as np
"""創建一個一維陣列(3, )"""
list1 = np.array([1, 2, 3])
"""創建一個三維陣列(2, 2, 3)"""
list2 = np.array([[[1, 2, 3], [4, 5, 6]], [[1, 2, 3], [4, 5, 6]]])
形狀如圖所示:
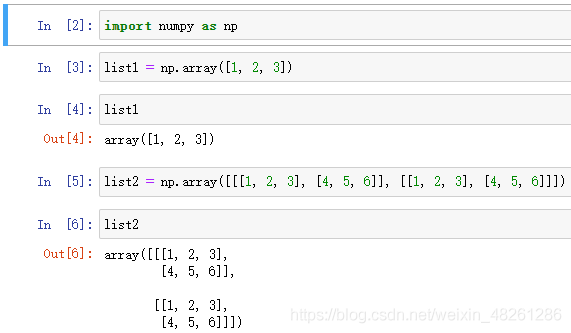
它們的 shape 屬性分別是:(3, ) 和 (2, 2, 3)
維度的觀察應該是從外到內,由大到小——得到形狀 shape:
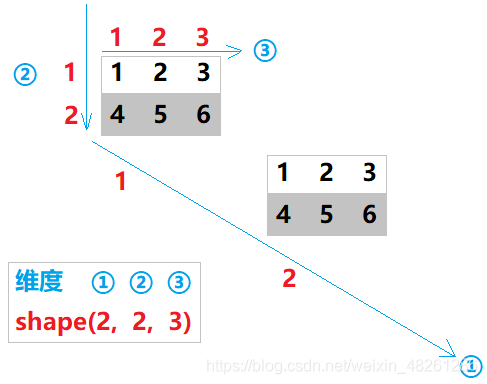
提示:由于 shape 是一個元組,因此可以用 shape 的下標來訪問 shape 中的具體值,如:三維陣列 temp 的元素個數為:sum = temp.shape[0] * temp.shape[1] * temp.shape[2]
3.ndarray 的型別 dtype
| 名稱 | 含義 | 簡寫 |
|---|---|---|
| np.bool | 用一個位元組存盤的布爾型別(Ture或False) | ‘b’ |
| np.int8 | 一個位元組大小,-128~127 | ‘i’ |
| np.int16 | 整數,-32768~32767 | ‘i2’ |
| np.int32 | 整數,-231~231-1 | ‘i4’ |
| np.int64 | 整數,-263~263-1 | ‘i8’ |
| np.unit8 | 無符號整數,0~255 | ‘u’ |
| np.unit16 | 無符號整數,0~65535 | ‘u2’ |
| np.unit32 | 無符號整數,0~232-1 | ‘u4’ |
| np.unit64 | 無符號整數,0~264-1 | ‘u8’ |
| np.float16 | 半精度浮點數,16位,正負號1位,整數5位,精度10位 | ‘f2’ |
| np.float32 | 單精度浮點數,32位,正負號1位,整數8位,精度23位 | ‘f4’ |
| np.float64 | 雙精度浮點數,64位,正負號1位,整數11位,精度52位 | ‘f8’ |
| np.complex64 | 復數,分別用兩個32位浮點數表示實部和虛部 | ‘c8’ |
| np.complex128 | 復數,分別用兩個64位浮點數表示實部和虛部 | ‘c16’ |
| np.object_ | Python物件 | ‘O’ |
| np.string_ | 字串 | ‘S’ |
| np.unicode_ | unicode型別 | ‘U’ |
在通過 dtype=np.? 指定資料型別時,可以使用名稱或簡寫
三、基本操作
1.生成陣列的方法
(1)生成0和1的陣列:
陣列名 = np.zeros(shape=?, dtype=?)
生成元素均為0的陣列
shape 指定陣列的形狀陣列名 = np.ones(shape, dtype=?)
生成元素均為1的陣列
shape 指定陣列的形狀
例:指定為 py.int8 型別
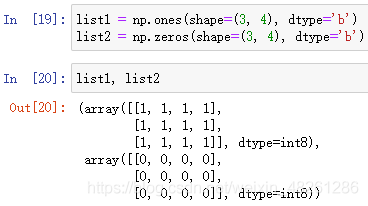
(2)從現有陣列中生成:
新陣列 = np.array(舊陣列)
深拷貝舊陣列
新陣列 = np.copy(舊陣列)
深拷貝舊陣列
陣列名 = np.asarray(舊陣列)
淺拷貝舊陣列
陣列名.flatten()
將多維陣列拍扁成一維陣列,順序不變,并回傳新的陣列
注:只回傳新陣列,不改變原陣列
- 一般可以將 Python 的陣列轉化為 Numpy 的陣列
- 深拷貝:拷貝成新的陣列,和舊陣列沒有關聯
- 淺拷貝:參考舊陣列的參考,當舊陣列發生變化時,它也跟著發生變化
(3)生成固定范圍的有序陣列:
np.linspace(start, stop, num, endpoint, retstep, dtype)
在 [start, stop] 之間生成元素值等間距的陣列,元素個數為sum 個
start 陣列的起始值,該值包含在內
stop 陣列的終止值,該值包含在內
num 要生成的等間距的元素個數,默認為50個(如果 endpoint=True,則該值必須指定)
endpoint 陣列中是否包含 stop 值,默認為 True
retstep 如果為True,則回傳樣例,以及連續數字之間的步長
dtype 輸出 ndarray 的資料型別np.arange([start, ]stop[, step])
在 [start, stop) 之間,用法和Python中的 range() 一樣
例:

(4)生成隨機陣列:
生成隨機陣列,包括兩種分布狀況:均勻分布 和 正態分布
需要使用 np.random 模塊
均勻分布:
np.random.rand(d0, d1,…,dn)
從 [0.0, 1.0) 之間生成一個均勻分布的亂數陣列,d0~dn可以指定其陣列形狀,如:np.random.rand(2, 3),生成 shape=(2, 3) 的二維陣列
rand() 即沒有指定形狀,回傳一個浮點數np.random.uniform(low=0.0, high=1.0, size=None)
從 [low, high) 之間生成一個均勻分布的亂數陣列
low 采樣下界,float 型別,默認值為0.0
high 采樣上界,float 型別,默認值為1.0
size 輸出樣本數目,為 int 或 shape ,例如:size=(m, n, k),則生成 shape=(m, n, k) 的陣列,預設時生成一個元素
例:np.random.rand(…)
np.random.rand() 回傳一個浮點數
np.random.rand(1) 回傳一個包含1個元素的一維陣列
np.random.rand(2) 回傳一個包含2個元素的一維陣列
np.random.rand(5, 8) 回傳一個包含5 × 8 = 40個元素的二維陣列
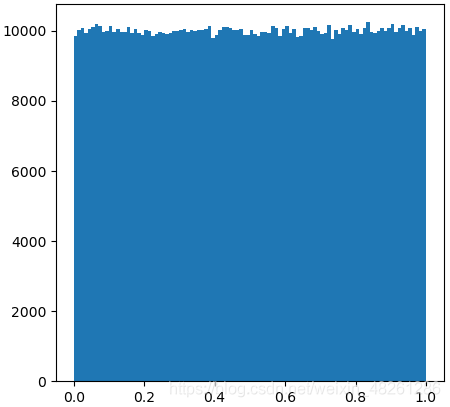
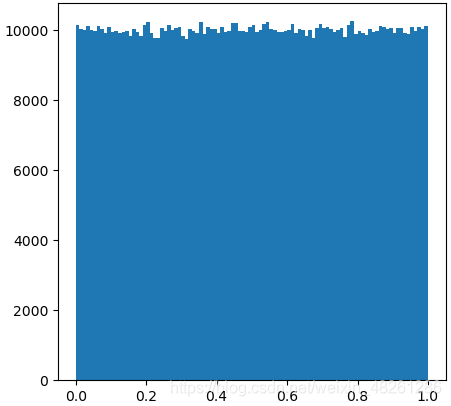
例:np.random.rand(…) 的均勻度驗證
import numpy as np
import matplotlib.pyplot as plt
temp_list = np.random.rand(1000000)
"""繪圖"""
plt.figure(figsize=(5, 5), dpi=100)
plt.hist(temp_list, 100)
plt.show()
例:np.random.uniform(…) 的均勻度驗證
import matplotlib.pyplot as plt
temp_list = np.random.uniform(low=0.0, high=1.0, size=1000000)
plt.figure(figsize=(5, 5), dpi=100)
plt.hist(temp_list, 100)
plt.show()
正態分布:
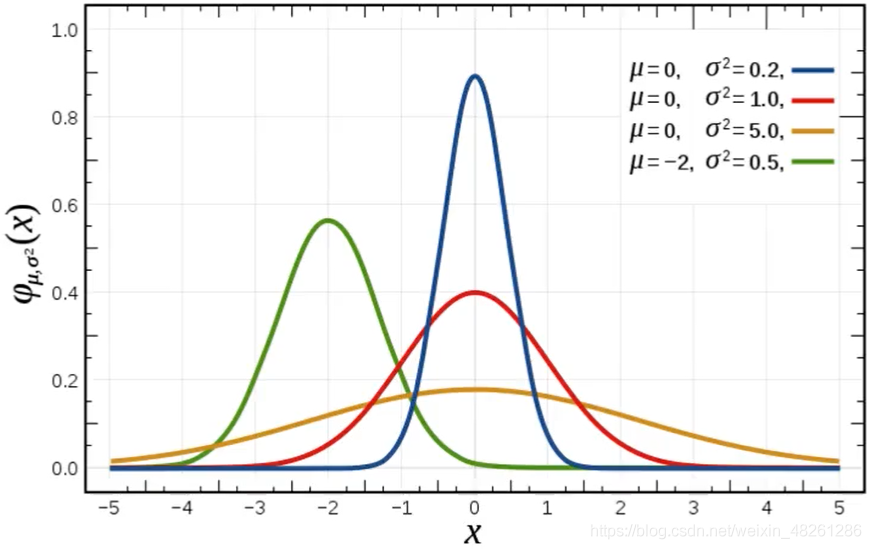
正態分布是一種概率分布,它是具有有兩個引數 μ 和 σ 的連續型隨機變數的分布,其中 μ 是服從正太分布的隨機變數的均值;σ2 是此隨機變數的方差,所以正態分布記作 x~N (μ, σ2)
簡單來說, μ 決定了正態分布圖 對稱軸的位置/最大值點;而 σ 則決定了正態分布圖的 粗細程度 和 最大值
- 當 σ2 越小時,正態分布圖越細高,最大值也越大
- 當 σ2 越大時,正態分布圖越粗扁,最大值也越小
此外,x~N (0, 1) 被稱為標注正態分布
np.random.randn(d0, d1,…,dn)
從標準正態分布中生成一個陣列,d0~dn可以指定其陣列形狀,如:np.random.randn(2, 3),生成 shape=(2, 3) 的二維陣列
randn() 即沒有指定形狀,回傳一個浮點數np.random.normal(loc=0.0, scale=1.0, size=None)
以正態分布的概率生成一個陣列
loc 概率分布的均值 μ,float 型別,默認值為0.0
scale 概率分布的標準差 σ,float 型別,默認值為1.0
size 輸出樣本數目,為 int 或 shape ,例如:size=(m, n, k),則生成 shape=(m, n, k) 的陣列,預設時生成一個元素
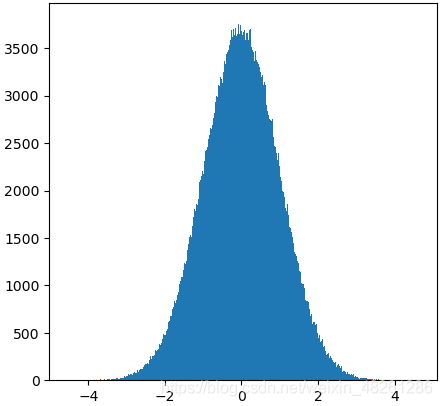
例:np.random.randn(…) 與 np.random.normal(…) 的正態分布驗證
import numpy as np
import matplotlib.pyplot as plt
temp_list = np.random.randn(1000000)
plt.figure(figsize=(5, 5), dpi=100)
plt.hist(list1, 1000)
plt.show()
import numpy as np
import matplotlib.pyplot as plt
temp_list = np.random.normal(loc=0.0, scale=1.0, size=1000000)
plt.figure(figsize=(5, 5), dpi=100)
plt.hist(list1, 1000)
plt.show()
2.陣列的索引和切片
索引陣列中的某一元素:
陣列名[d0, d1,…,dn]
訪問陣列的某一元素
d0, d1,…,dn 按形狀分布的下標選取即可
切片/訪問一維陣列中某一范圍的元素:
陣列名[start:stop]
切片/訪問—→行下標在 [start, stop) 區間內的陣列元素,回傳一個陣列
切片/訪問二維陣列中某一范圍的元素:
陣列名[row, [start:stop]]
切片/訪問二維陣列 中—→行下標為 row ,列下標在 [start, stop) 區間內的陣列元素,回傳一個陣列
當 start:stop 預設時,表示訪問—→行下標為 row 的行
row 也可以寫成 start:stop 的形式,表示行下標在 [start, stop) 區間的范圍內
切片/訪問三維陣列中某一范圍的元素:
陣列名[axis[, row][, start:stop]]
切片/訪問三維陣列中—→軸下標為 axis,行下標為 row,列下標在下標在 [start, stop) 區間內的陣列元素,回傳一個陣列
當 row, start:stop 預設時,表示訪問—→軸下標為 axis 的平面
當 start:stop 預設時,表示訪問—→軸下標為 axis,行下標為 row的行
axis 也可以寫成 start:stop 的形式,表示軸下標在 [start, stop) 區間的范圍內
row 也可以寫成 start:stop 的形式,表示行下標在 [start, stop) 區間的范圍內
- start 均可以預設,默認值為0
- stop 也可以預設,默認訪問到陣列最后
例:
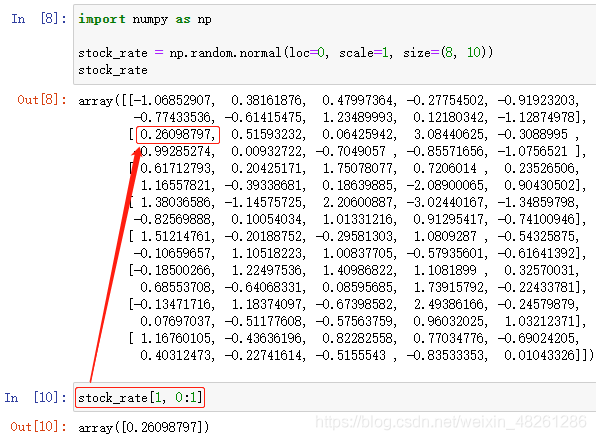
此外,axis 或 row 也可以用 start:stop 代替:
如:陣列名[0:2, 0:5] 表示陣列的第0~1行中的第0~4列的元素

3.陣列形狀的修改
陣列物件呼叫方法:
陣列名.reshape(shape)
把當前陣列回傳為 shape 的形狀,元素的所有順序 [start, stop) 并不發生改變
注:只回傳新陣列,不改變原陣列陣列名.resize(shape)
直接對當前陣列進行修改,改變原陣列,沒有回傳值,元素的所有順序 [start, stop) 并不發生改變
陣列名.T
回傳一個 轉置 后的二維陣列,把行變為列,把列變為行,元素的所有順序 [start, stop) 發生了改變
注:只回傳新陣列,不改變原陣列
例:陣列名.reshape(shape)

例:使用 陣列名.reshape(shape) 時,如果只想指定列數不想計算行數可以用 -1 代替
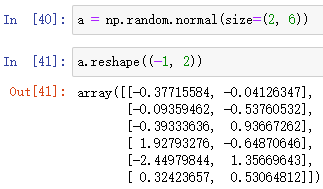
例:陣列名.T

3.陣列資料型別的修改
陣列名.astype(dtype)
將當前陣列的資料型別轉化為 dtype,并回傳
注:只回傳新陣列,不改變原陣列陣列名.tobytes()
把陣列轉化成二進制的 bytes 型別存盤并回傳,序列化到本地時使用
注:只回傳新陣列,不改變原陣列
- 如果遇到 IOPub data rate exceeded 錯誤,原因是:
在 Jupyter Notebook 中對輸出的位元組數有限制,可以修改組態檔
不過這個錯誤僅僅影響顯示出來的內容數,對函式的功能沒有影響,不必理會
4.陣列的去重
np.unique(陣列)
將陣列拍扁為一維陣列(即可以作用于多維陣列),并進行去重,回傳新陣列
注:只回傳新陣列,不改變原陣列
例:

四、ndarray 運算
1.邏輯運算
直接使用陣列名的邏輯運算式 ? 布爾陣列
布爾邏輯運算式 ? 布爾陣列
進行基本的邏輯運算,該運算式記為“布爾陣列”(重要)
布爾陣列:由 True 或 False 組成的陣列
例:
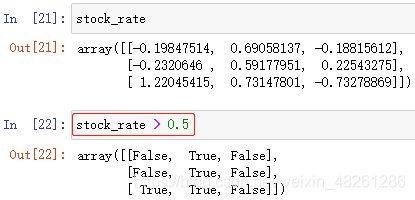
例:
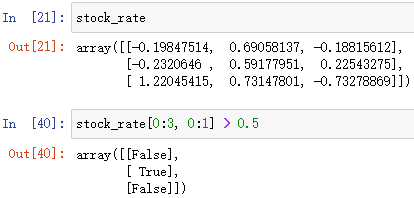
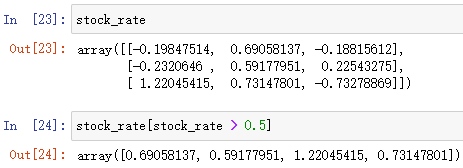
陣列名[布爾陣列]
布爾索引,索引布林值中為 True 的元素,并回傳這些元素組成的陣列
下標訪問陣列的一種辦法——布爾索引陣列名[布爾陣列] = 值
將布爾陣列中為 True 的元素進行統一的賦值,并回傳新陣列(基于布爾陣列中的舊陣列)
例:
例:
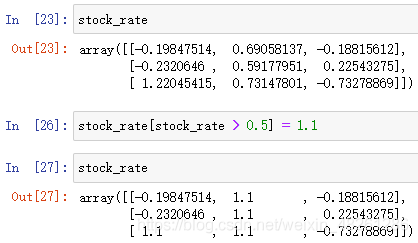
- 其他邏輯運算子均適用
通用判斷函式:
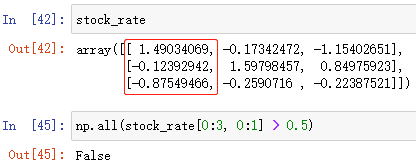
np.all(布爾陣列)
布爾陣列中只要有一個 False 就回傳 False
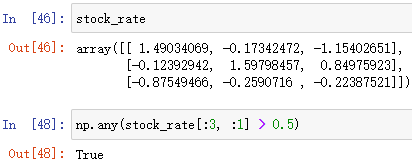
np.any(布爾陣列)
布爾陣列中只要有一個 True 就回傳 True
例:np.all(布爾陣列)
例:np.any(布爾陣列)
三元運算子:
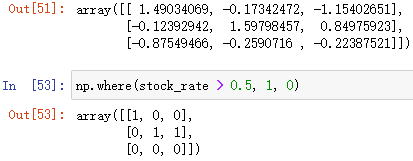
np.where(布爾陣列, data1, data2)
判斷布爾陣列中的內容,True 的元素全部賦值為 data1,False 的元素全部賦值為 data2,,并回傳新陣列(基于布爾陣列中的舊陣列)
例:
想要進行更復雜的運算,需要使用布爾邏輯運算函式:
| 布爾邏輯運算函式 | 含義 |
|---|---|
| np.logical_and(布爾陣列1, 布爾陣列2) | 邏輯與 |
| np.logical_or(布爾陣列1, 布爾陣列2) | 邏輯或 |
| np.logical_not(布爾陣列1, 布爾陣列2) | 邏輯非 |
| np.logical_xor(布爾陣列1, 布爾陣列2) | 邏輯異或 |
例:把陣列中 > 0.5 或 < -0.5 的元素置1,否則置0
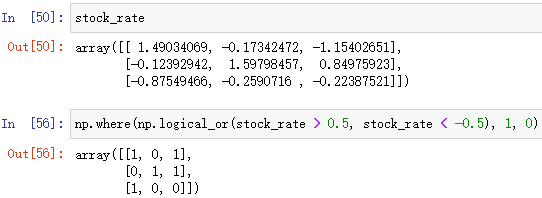
2.統計運算
在資料挖掘/機器學習領域,統計指標的值也是我們分析問題的一種方式,常用的有:最大值max、最小值min、平均值mean、中位數median、方差var、標準差std 等
統計相關函式:
| 統計運算函式 | 含義 |
|---|---|
| np.max(陣列[, axis=]) | 找到陣列中最大值元素 |
| np.min(陣列[, axis=]) | 找到陣列中最小值元素 |
| np.mean(陣列[, axis=]) | 統計陣列的平均值 |
| np.median(陣列[, axis=]) | 找到陣列的中位數 |
| np.var(陣列[, axis=]) | 統計陣列的方差 |
| np.std(陣列[, axis=]) | 統計陣列的標準差 |
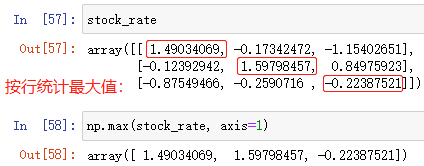
- axis 指定按行或按列運算:
axis=0 表示按列統計,即分別統計每一列中的 ( max 或 min 或 mean…)
axis=1或-1 表示按行統計,即分別統計每一行中的 ( max 或 min 或 mean…)
例:按行統計最大值
尋找最大值、最小值所在位置:
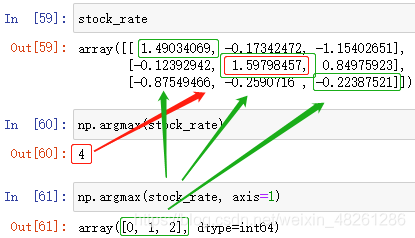
np.argmax(陣列[, axis=])
找到陣列中最大值元素,回傳其所在位置——下標
np.argmin(陣列[, axis=])
找到陣列中最小值元素,回傳其所在位置——下標
- axis 指定按行或按列運算:
axis=0 表示按列統計,即分別統計每一列中的 ( max 或 min 或 mean…)
axis=1或-1 表示按行統計,即分別統計每一行中的 ( max 或 min 或 mean…) - 當有多個最大值或最小值時,回傳首個查找到的最大值/最小值的下標值
例:尋找最大值的位置,分別用 總體 和 按行
3.陣列間的運算
注:Python的原生 list 是沒有這些功能的
陣列與數之間的運算:
例:

例:

陣列與陣列之間的運算:
廣播機制 broadcast
若想要讓兩不同形狀的陣列之間能夠進行運算,它們需要滿足廣播機制
決議——推導(重點):
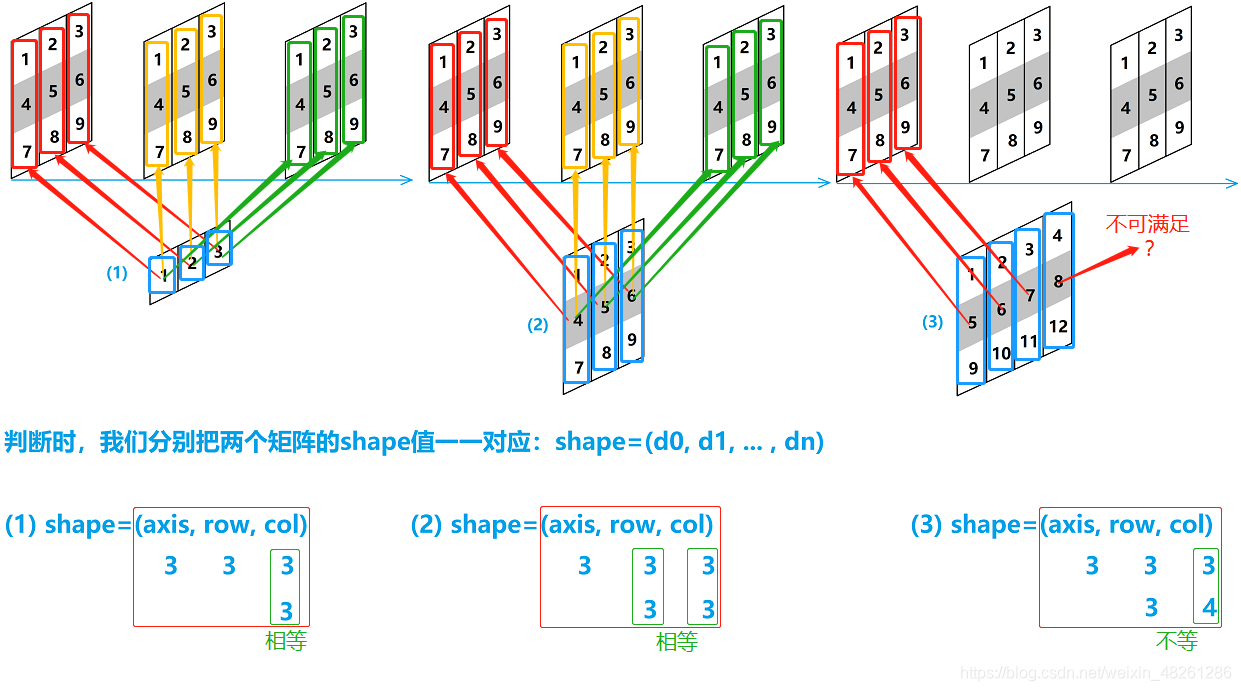
我們發現,不同的陣列之間的運算,不論它們是不是同維陣列,只要它們的 shape 中同一列所對應的值是相等的,那么它們之間就能夠一一對應,那么它們之間就是可運算的
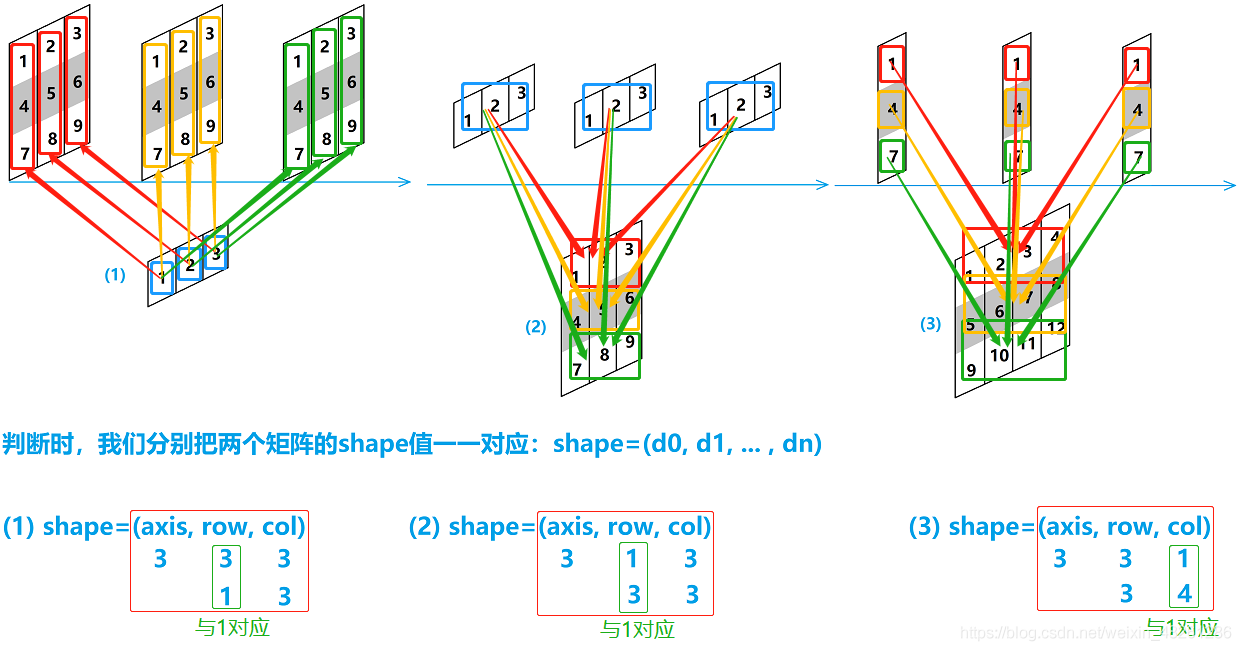
此外,除了 shape 同一列的一一對應之外,我們發現,若 shape 的某一列中其中一個是1,那么這個1就可以對應另一個陣列在該列上的所有元素,稱為一對多,那么這種一對多的對應也是可以運算的
廣播機制:
當操作兩個陣列時,numpy會逐個比較它們的 shape(構成的元組 tuple),只有在 shape 中每一列對應的數 滿足下述所有條件下,兩個陣列之間才能進行陣列與陣列的運算:
- 任一列上的兩數相等,即滿足 “一一對應”
- 任一列上的兩數中,其中一個數是1,即滿足 “一對多”
那么兩陣列之間就是可運算的,滿足廣播機制后,那么陣列之間的運算就是簡單的——對應的元素通過運算子號進行運算即可 (+、-、*、/)
例:
A (256, 256, 3)
B (3, )
在 col(d2) 列上,滿足3對應3,因此A、B之間是可運算的
A (9, 1, 7, 1)
B (8, 1, 5)
在 axis(d0) 列上,滿足1對8;在 row(d1) 列上,滿足1對7;在 col(d2) 列上,滿足1對5,因此A、B之間是可運算的
A (5, 4)
B (1, )
在 col 列上,滿足1對4,因此A、B之間是可運算的
A (15, 3, 5)
B (15, 1, 1)
在 axis(d0) 列上,滿足15對應15;在 row(d1) 列上,滿足1對3;在 col(d2) 列上,滿足1對5,因此A、B之間是可運算的
A (10, )
B(12, )
在 col 列上,10和12無法對應,顯然A、B之間不可運算
A (2, 1)
B (8, 4, 3)
雖然在 col(d1) 列上,滿足1對3;但是在 row(d0) 列上,2和4無法對應,顯然A、B之間不可運算
例:陣列與陣列之間的運算

顯然,運算結果為new_array = [[1 * 10, 2 * 20], [3 * 10, 4 * 20]]
4.矩陣運算
存盤矩陣的兩種方式:
矩陣名 = np.array()
ndarray 存盤矩陣
矩陣名 = np.mat()
matrix 存盤矩陣
矩陣 matrix 是 《線性代數》 中的概念,它必須是2維的,矩陣之間的 乘運算 的幾何意義是 向量積——叉乘
其運算方法為:

np.matmul(a, b, out=None)
兩個numpy矩陣相乘
np.dot(a, b)
可用于兩個numpy矩陣相乘,也可以乘以標量
例:按照平時成績 0.4 和期末成績 0.6 的加權值來計算出最終成績
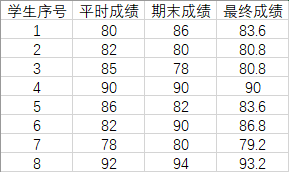
最終成績為 (8, 1) 的矩陣,而學生成績是 (8, 2) 的矩陣,因此,權值應該寫成 (2, 1) 的矩陣,即:
- (8, 2) × (2, 1) = (8, 1)
資料:
grade = np.array([[80, 86], [82, 80], [85, 78], [90, 90], [86, 82], [82, 90], [78, 80], [92, 94]])
import numpy as np
grade = np.array([[80, 86],
[82, 80],
[85, 78],
[90, 90],
[86, 82],
[82, 90],
[78, 80],
[92, 94]])
weighting = np.array([[0.4], [0.6]])
np.matmul(grade, weighting)

擴展:
matrix1 * matrix1
用 matrix 存盤的兩個矩陣可以直接用 * 相乘
ndarray1 @ ndarray2
用 ndarray 存盤的兩個矩陣可以用 @ 相乘
注:如果兩 ndarray 使用 * 來進行運算, ndarray 將被視作陣列,陣列之間的運算需要滿足廣播機制
5.np.dot() 與 np.matmul() 的區別
- 二者都是矩陣乘法
- np.matmul() 不允許矩陣與標量(數)相乘
- 在矢量與矢量的內積運算中,np.dot() 與 np.matmul() 沒有區別
- 在 np.matmul() 中,可以傳入N(N>2)維的陣列
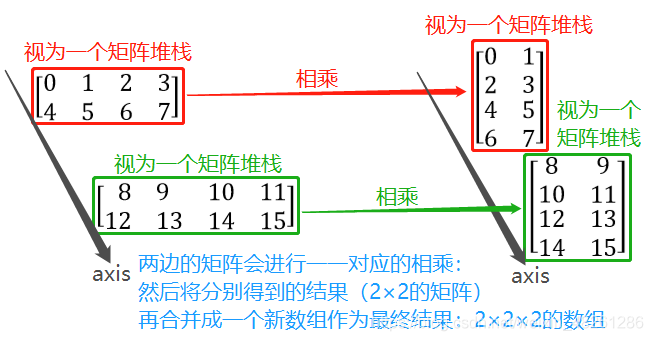
在 np.matmul() 傳入N(N>2)維的陣列時,它會作如下的處理:
- 首先會把N(N>2)維陣列的最后兩個維度作為矩陣堆疊——即把陣列的 shape (d0, d1, d2, … , dn) 的 (dn-1, dn) 視為完整的矩陣——矩陣堆疊,然后再對兩者之間的矩陣進行 “一一對應” 或者 “一對多”(詳見廣播機制) 的矩陣相乘運算,因此N(N>2)維的陣列需要滿足廣播機制
- 簡單來說,它是把N(N>2)維陣列中的 shape (d0, d1, d2, … , dn) 中的 dn-1 和 dn 視為 d’,于是這個N(N>2)維陣列變為 shape (d0, d1, d2, … , dn-2, 矩陣-d’),因此這個陣列要想跟另一個陣列進行運算,就需要滿足陣列運算之間的廣播機制,在滿足廣播機制之后,兩個陣列的 矩陣-d’ 之間就可以進行 “一一對應” 或者 “一對多” 的運算
例:
import numpy as np
a = np.arange(2 * 2 * 4).reshape((2, 2, 4))
b = np.arange(2 * 2 * 4).reshape((2, 4, 2))
c = np.arange(1 * 2 * 4).reshape((1, 4, 2))
np.matmul(a, b)
np.matmul(a, c)
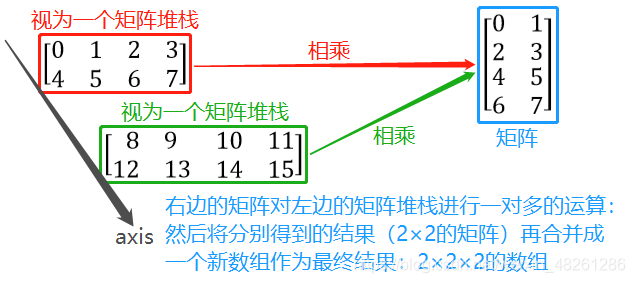
首先是 np.matmul(a, b):
對于矩陣 a,它在 np.matmul() 中會被理解成 兩個 2×4 的矩陣
對于矩陣 b,它在 np.matmul() 中會被理解成 兩個 4×2 的矩陣
因此運算結果為 out[ ] :
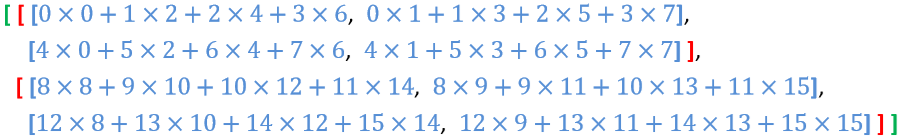
其次是 np.matmul(a, c):
因此運算結果為 out[ ] :
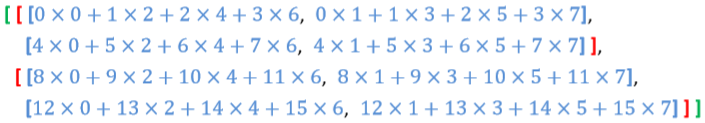
6.合并與分割
陣列水平合并/拼接:
np.hstack(*args)
對陣列元組 *args 中的陣列進行 水平 方向上的合并
*args 陣列元組,如:(ndarray1, ndarray2, … , ndarrayn)
例:

例:

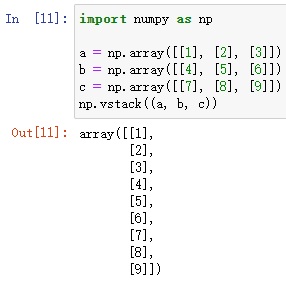
陣列豎直合并/拼接:
np.vstack(*args)
對陣列元組 *args 中的陣列進行 豎直 方向上的合并
*args 陣列元組,如:(ndarray1, ndarray2, … , ndarrayn)
例:
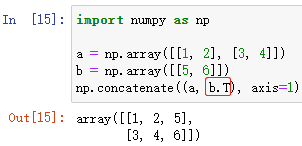
np.concatenate(*args, axis=)
對陣列元組 *args 中的陣列進行 水平或豎直 方向上的合并
*args 陣列元組,如:(ndarray1, ndarray2, … , ndarrayn)
**kwargs 中,axis=? 可以指定進行 水平或豎直 的拼接
- axis 指定按行或按列運算:
axis=0 表示進行水平拼接
axis=1或-1 表示進行豎直拼接
例:(注:這里的 陣列b 進行了 T 轉置)
例:將第一行和第三行的資料進行水平拼接
資料:
stock_rate = [[1.18713375, 0.77624391, -0.47452542], [-1.22011298, 1.26038645, 0.10170957], [-0.67131837, 1.47798017, -0.69569189]]

陣列分割:
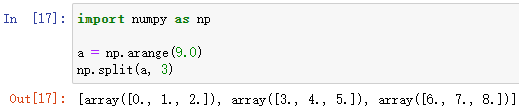
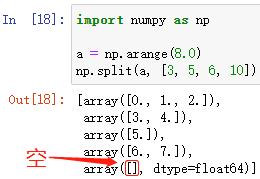
np.split(ndarray, indices_or_sections, axis=0)
對陣列進行指定份數的分割
ndarray 為需要分割的陣列
indices_or_sections 為指定的分割引數,可以是:
- 整數——平均分成整數份,如:3,即把 ndarray 平均分成3分
- 整數陣列——以陣列中的整數元素作為索引,索引對應 ndarray 中的元素作為分隔,如:[1, 2, 3],即把 ndarray 中索引為1、2、3的元素作為分隔,其中,分隔元素將作為下一個陣列的首元素
例:
例:
7.IO操作與資料處理
Numpy 讀取資料檔案:
np.genfromtxt(fname, delimiter=?)
把資料檔案讀取到 ndarray 陣列中
fname 檔案路徑和檔案名,檔案名包含擴展名
delimiter=? 分隔符,用于區元素
- 分隔符區分一維陣列的不同元素,不同的行則為二維陣列中的不同列
例:
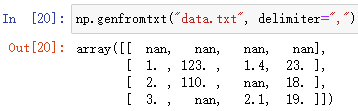
發現,對于字串資料和空格資料都會讀取成 缺失值nan(dtype 為 float64)
如何處理缺失值?
思路1:
直接洗掉含有缺失值的樣本
思路2:
替換/插補——按列求平均值,用平均值來填補 缺失值nan
例:替換/插補 nan 的函式定義
import numpy as np
def fill_nan_by_column_mean(t):
for i in range(t.shape[1]):
# 獲取nan的個數
nan_num = np.count_nonzero(t[:, i][t[:, i] != t[:, i]])
if nan_num > 0:
# 獲取當前列的元素
now_col = t[:, i]
# 求和
now_col_not_nan = now_col[np.isnan(now_col) == False].sum()
# 和/個數
now_col_mean = now_col_not_nan / (t.shape[0] - nan_num)
# 賦值給now_col
now_col[np.isnan(now_col)] = now_col_mean
# 賦值給t,即更新t的當前列
t[:, i] = now_col
return t
- 比較復雜,以后我們將會介紹 Pandas 庫來處理這些資料
上述所用函式:
np.count_nonzero(ndarray, axis=None, *, keepdims=False)
用于統計陣列中非零元素的個數
ndarray 被統計的陣列
axis=None 指定是否按軸統計,指定后則按行/列分別進行非零元素的統計
keepdims 未知…np.isnan(ndarray)
逐個檢查 ndarray 中的值是否為 nan,并以布爾陣列的形式回傳
- axis 指定按行或按列運算:
axis=0 表示進行水平拼接
axis=1或-1 表示進行豎直拼接
例:

8.擴展:axis=0或1 的互動方式
在很多函式中,我們多使用到了 axis=0或1 的引數,但我們只是針對二維陣列來進行簡要說明,在這里,我們將對 axis=0或1 的用法進行 N(N>2)維陣列 的展開:
在傳遞 axis=0或1 引數的函式中,我們需要明確一點:
- 假設這個 N(N>2)維陣列 的形狀為:shape (d0, d1, d2, …, dn)
那么首先要對 N(N>2)維陣列 進行降維度,它會把 shape (d0, d1, d2, …, dn) 的 N(N>2)維陣列 先拆分成 d0 個 N-1(N>2)維陣列,這個時候 axis=0或1 就很好解讀了:
- 對于拆分后的 d0 個 N-1(N>2)維陣列,有以下規則:
- 當 axis=1 時:d0 個 N-1(N>2)維陣列,每個陣列都在自身內部進行統計,和其他陣列沒有關聯
- 當 axis=0 時: d0 個 N-1(N>2)維陣列,這些陣列將會被一一串起來(每個陣列的形狀是一樣的),因此 d0 個陣列 之間,每個陣列之間的數都是一一串聯對應的,如圖:
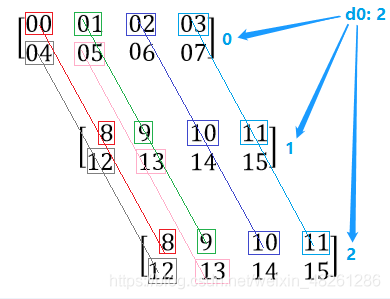
于是, axis=0 就表示每個陣列將會與其他陣列之間進行統計,每串數數進行對應統計
例:三維陣列
內部按列統計:

外部統計:

例:四維陣列
內部統計:

外部統計:

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/264427.html
標籤:AI