@Hadi
初來乍到 多多點贊
文章目錄
- @Hadi
- 前言
- 一、簡述Scrapy
- 1.什么是scrpay框架
- 2.基本架構
- 二、需求分析
- 1.需求是什么
- 2.對目標頁面進行分析
- URL結構分析
- 三.開始編碼
- 1.抓取串列中的二級URL
- 2.對詳情頁目標資訊的抓取
- 四.結果展示
- 寫在最后
前言
既然上一篇文章說到了爬蟲,那我就把這一塊再補充完整再換其他內容吧,其實我也是因為專案需求自學的爬蟲,這篇文章只能給入門者一個啟發的思路,如果想要更加系統化規范地了解學習網路爬蟲技術建議上中國大學MOOC找找相關的課程,畢竟技術總是日新月異的,用手去思考永遠不會錯,延續上一篇提及的scrapy框架,正文里會有詳細介紹,這次會利用它來爬取前程無憂所有的職位資訊,我覺得這個是入門者理解爬蟲的經典案例,因為51job沒有任何的反爬機制,所以在入門者修改除錯的時侯效率就非常高便于找到正確的思路,所以我會寫的比較詳細,希望能對入門的朋友有所啟發,
一、簡述Scrapy
1.什么是scrpay框架
Scrapy是一個適用爬取網站資料、提取結構性資料的應用程式框架,它可以應用在廣泛領域:Scrapy 常應用在包括資料挖掘,資訊處理或存盤歷史資料等一系列的程式中,通常我們可以很簡單的通過 Scrapy 框架實作一個爬蟲,抓取指定網站的內容或圖片, 盡管Scrapy原本是設計用來螢屏抓取(更精確的說,是網路抓取),但它也可以用來訪問API來提取資料,

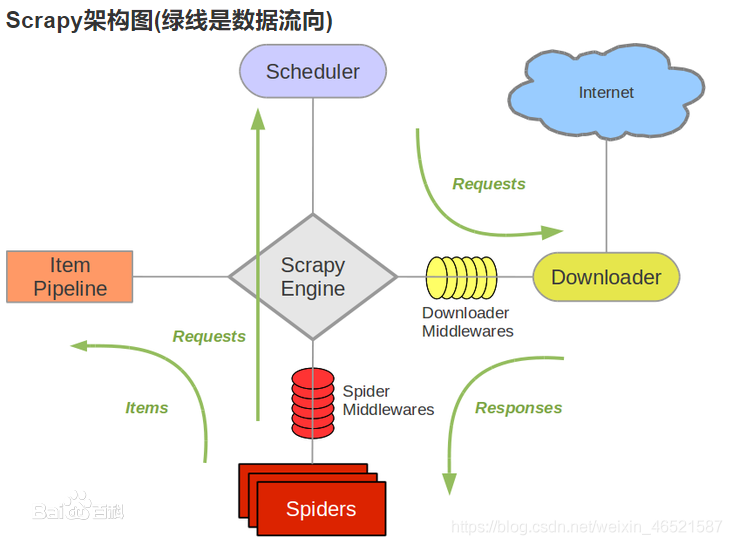
2.基本架構
Scrapy Engine(引擎):負責Spider、ItemPipeline、Downloader、Scheduler中間的通訊,信號、資料傳遞等,
Scheduler(調度器):它負責接受引擎發送過來的Request請求,并按照一定的方式進行整理排列,入隊,當引擎需要時,交還給引擎,
Downloader(下載器):負責下載Scrapy Engine(引擎)發送的所有Requests請求,并將其獲取到的Responses交還給Scrapy Engine(引擎),由引擎交給Spider來處理,
Spider(爬蟲):它負責處理所有Responses,從中分析提取資料,獲取Item欄位需要的資料,并將需要跟進的URL提交給引擎,再次進入Scheduler(調度器),
Item Pipeline(管道):它負責處理Spider中獲取到的Item,并進行進行后期處理(詳細分析、過濾、存盤等)的地方,
Downloader Middlewares(下載中間件):一個可以自定義擴展下載功能的組件,
Spider Middlewares(Spider中間件):一個可以自定擴展和操作引擎和Spider中間通信的功能組件
至于安裝步驟我就不細述了pip install Scrapy🙃
二、需求分析
這次的需求是爬取前程無憂里的職位資訊,所以第一步是先對目標網站進行摸索,先把網站基本的結構研究清楚,這很重要,因為不同的網站差異只有億點點 ,其實很好理解,公司的需求不一樣開發人員也不一樣,做出來的東西也千變萬化,所以思路很重要,具體案例具體分析,沒有固定的做法,要有自己思考分析的能力,但其實本質不會變,
1.需求是什么
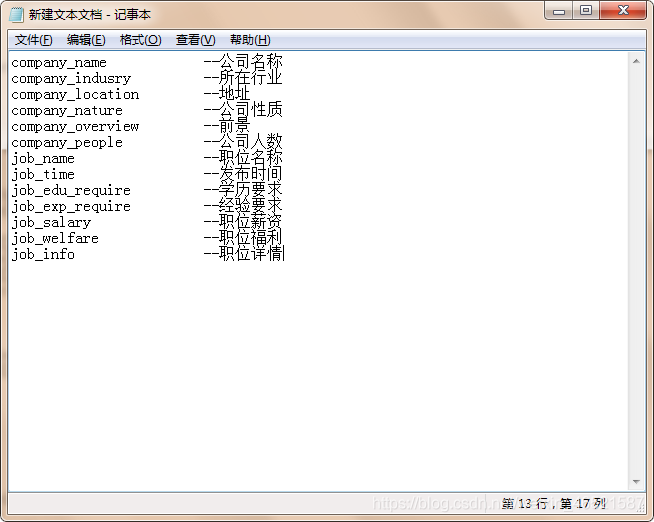
這里我定了相關的需求
作為演示我會爬取廣州JAVA相關職位資訊
2.對目標頁面進行分析
進入51job后我們先點開廣州JAVA的招聘資訊串列
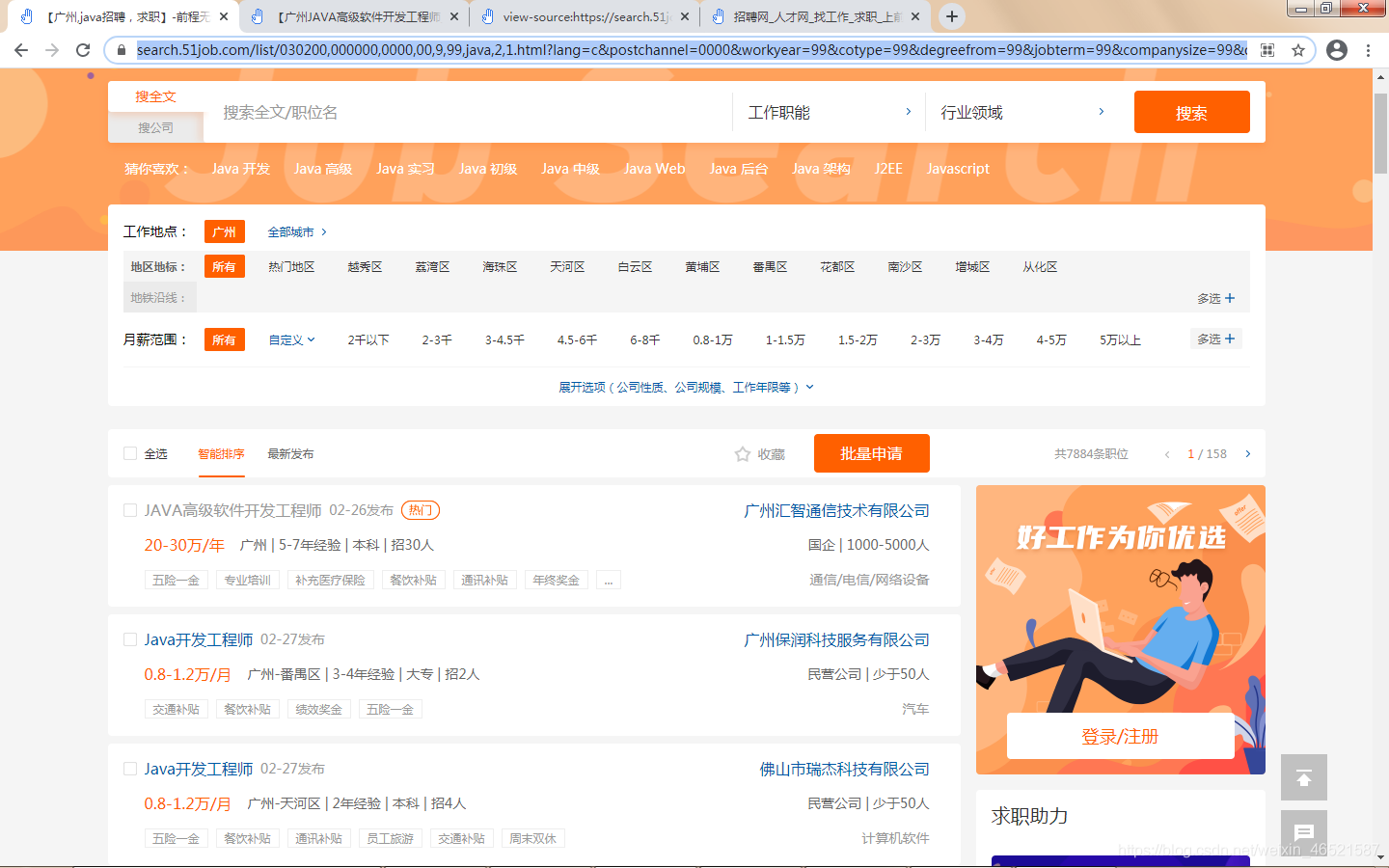
這時候發現串列中會有所需資訊,但是資訊并不全,詳細資訊會放在串列中點開的詳情頁里面,如圖所示,
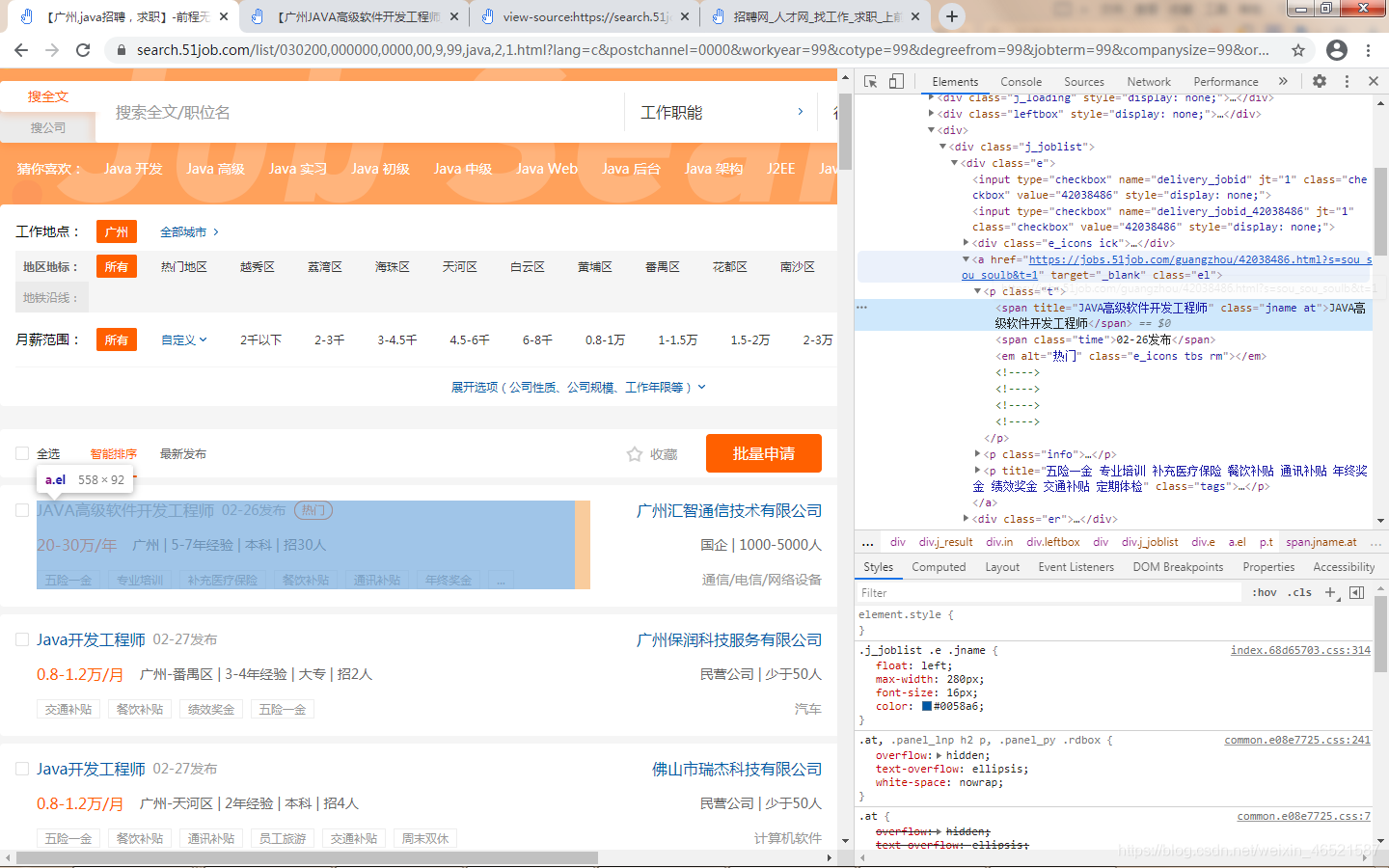
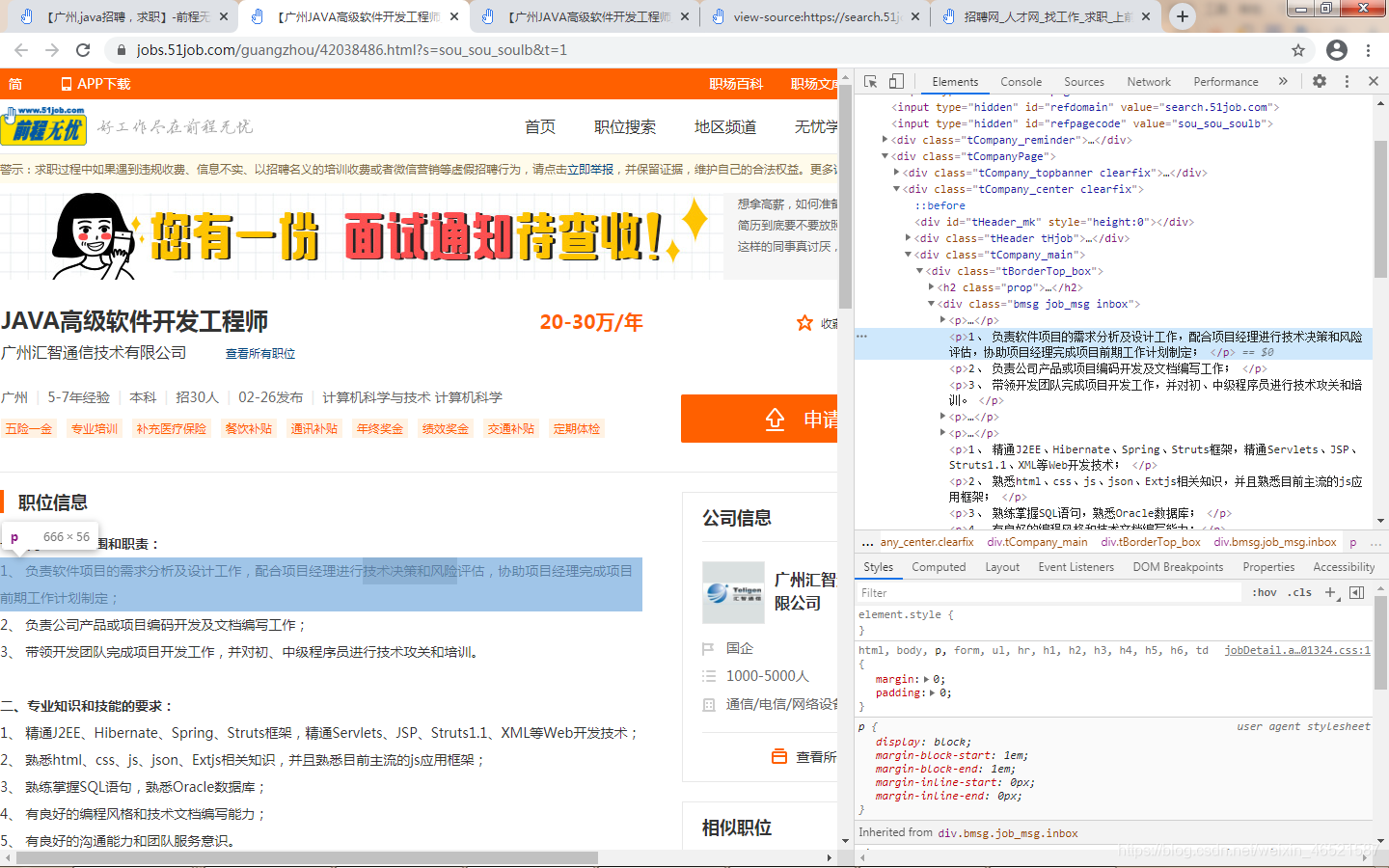
所以我們基本的思路就有了,我們先把串列中每一頁的詳情頁鏈接拿到手,再扔給二級function里對子鏈接進行目標資訊的抓取,至于目標資訊怎么拿,不是現在考慮的事情,我們現在要做的是先把二級url先取下來,因為車到山前必有路,切莫心浮氣躁,
URL結構分析
接下來這一步是非常重要的,我們要對目標的URL進行觀察,因為我們要清楚URL才是程式的起點,是程式請求的地址,
一般URL上都是一些資訊的編號,都是有實際意義的字符,一般這些資訊都會放在網頁原始碼或者web附隨的js檔案中,耐心改改重繪看看你就會發現其中的規律,
URL:“https://search.51job.com/list/030200,000000,0000,00,9,99,java,2,1.htmllang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=”
這個網站的URL還是比較友好的我也不多說了.
03200是廣州的編號
.html前的數字是請求的頁數
所以拼接前后的字串做一個數字的累加便可達到爬取所有串列資訊的目的,
三.開始編碼
1.抓取串列中的二級URL
其實不難發現串列中的相關資訊是動態加載的,我之前做到這一步的時候有點懵了,我一直在重繪網頁找動態加載的js,一直找不到,直到我打開網頁原始碼一行一行去看…
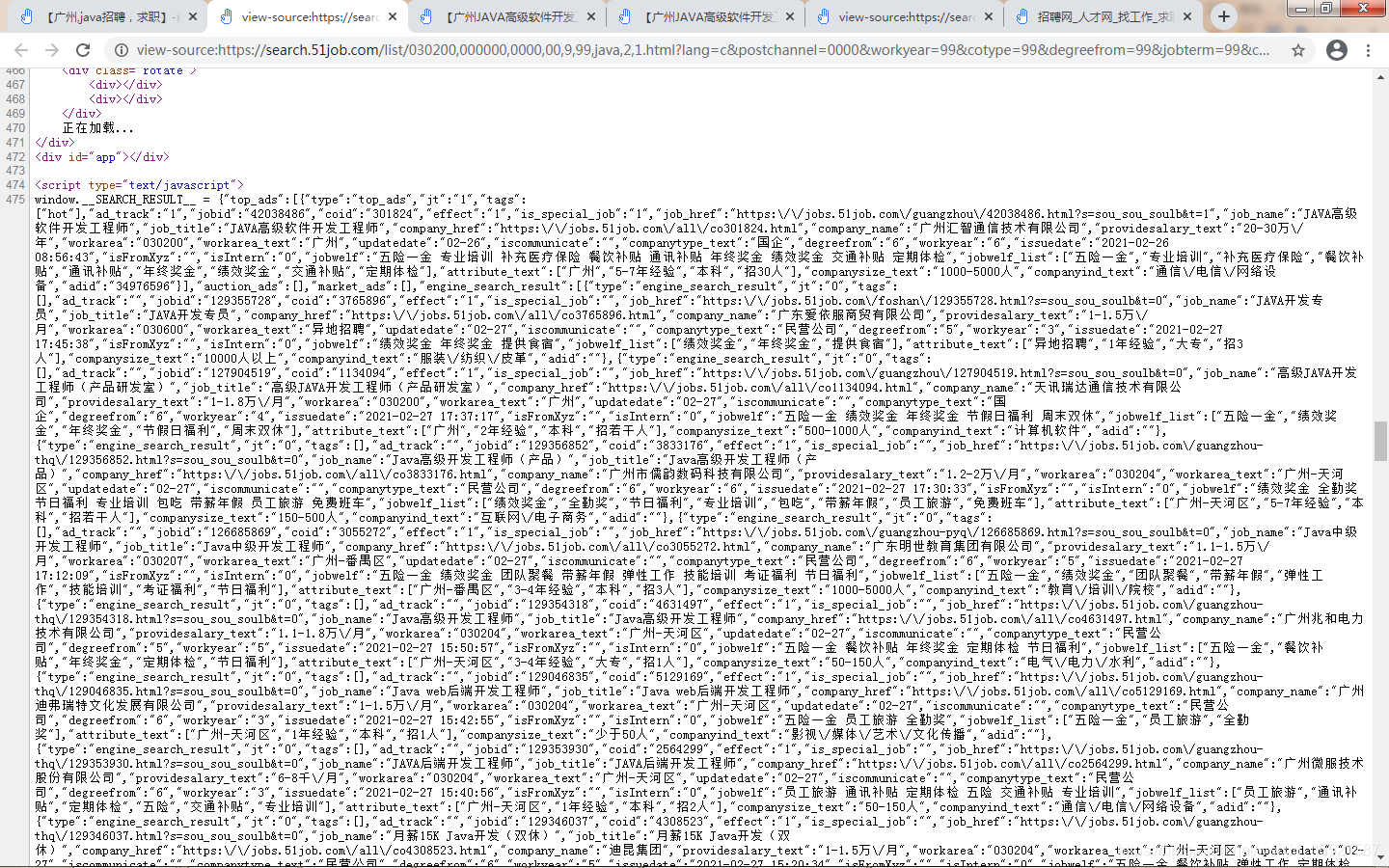
所以說具體問題具體分析嘛
接著xpath定位就可以直接拿了,幸福來得太突然哈哈哈哈,
//對原始碼上的資訊進行整理
contents_tmp = response.xpath('//script[contains(text(),"SEARCH_RESULT")]')[0].extract().strip().split("\r\n")[1].replace("window.__SEARCH_RESULT__ = ","").replace("\\","").split(",\"jobid_count")[0]+"}"
//整理后以json格式讀入
contents=json.loads(contentss)
datalist=contents['engine_search_result']
打點debug后抓取到的結果是這樣的
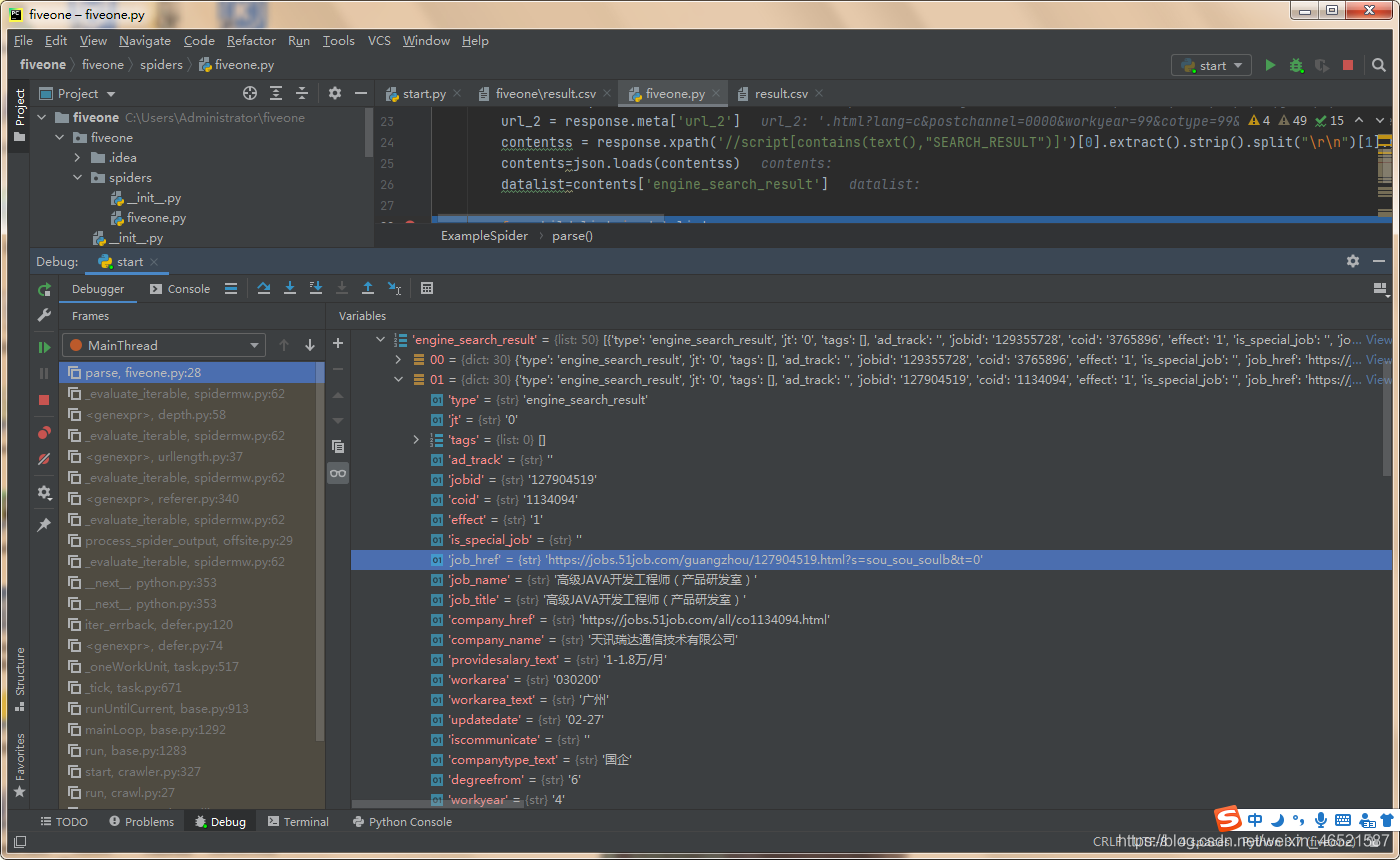
每條json里面的jobhref屬性不就是二級的URL嗎,我們要做的就是遍歷每一頁中的串列中的每一個二級URL并且將其扔給二級的function去做第二步的資訊抓取,跟著分析時的思路走就行了,
2.對詳情頁目標資訊的抓取
詳情頁里面就是一個靜態頁面,所以說這個網站對爬蟲還是比較友好的,怎么拿怎么有,
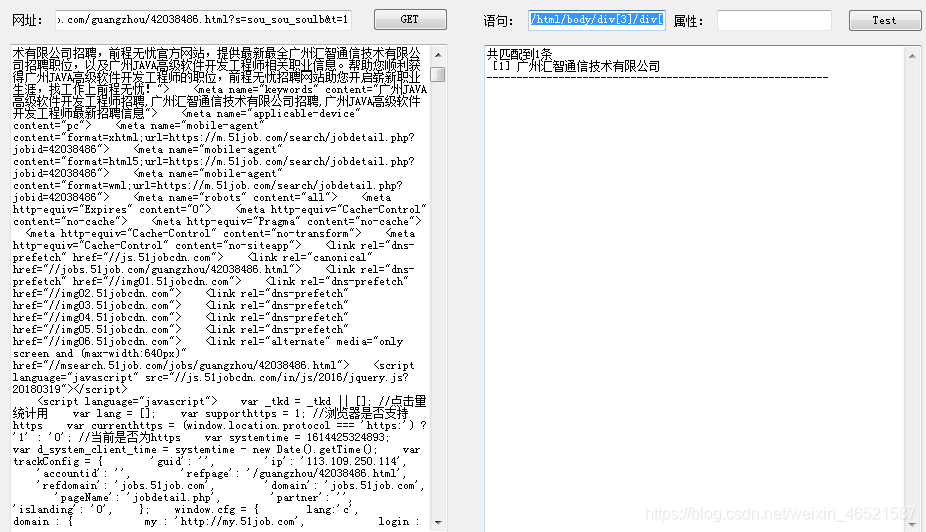
//二級抓取的方法
def parse_dail(self, response):
company_name = response.xpath('/html/body/div[3]/div[2]/div[4]/div[1]/div[1]/a/p/text()').extract()
company_industry = response.xpath('/html/body/div[3]/div[2]/div[4]/div[1]/div[2]/p[3]/a/text()').extract()
company_location=response.meta['job_list'][0]
company_nature = response.xpath('/html/body/div[3]/div[2]/div[4]/div[1]/div[2]/p[1]/text()').extract()
company_overview = response.xpath('/html/body/div[3]/div[2]/div[3]/div[3]/div/text()').extract()
company_people = response.xpath('/html/body/div[3]/div[2]/div[4]/div[1]/div[2]/p[2]/text()').extract()
job_name = response.xpath('//h1[@title]/@title').extract()
job_time=response.meta['date']
job_edu_require=response.meta['job_list'][2]
job_exp_require = response.meta['job_list'][1]
job_salary = response.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/strong/text()').extract()
job_info= response.xpath('/html/body/div[3]/div[2]/div[3]/div[1]/div/p/text()').extract()
job_welfare=response.meta['job_welfare']
四.結果展示
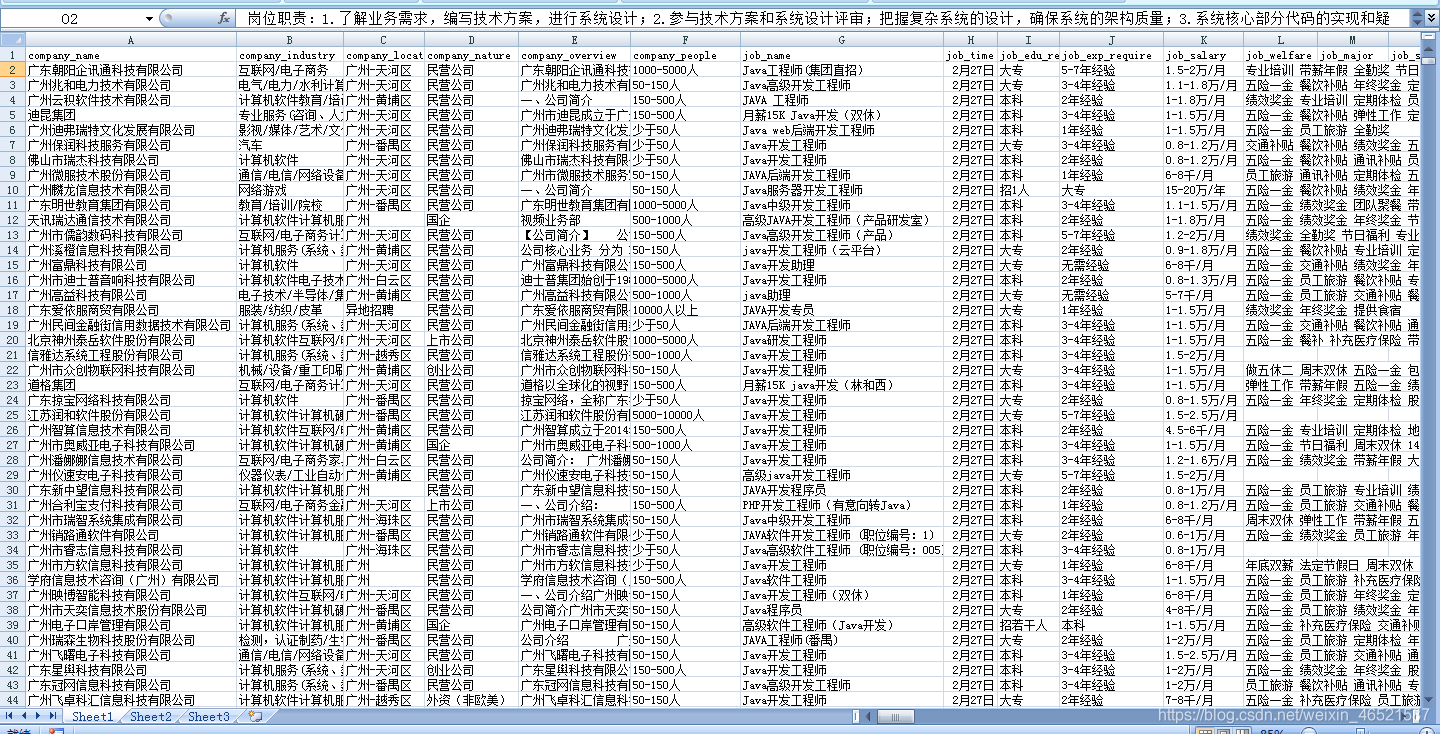
做到這里其實基本需求已經達到,接下來就是資料的反復確認清洗,因為這個網站也沒有任何的反爬機制,只要編碼到位你就能欣賞到控制臺上的資料在跳舞,
資料也是相當規整,有8000條目標資訊,
寫在最后
這篇文章都是以分析的思路為主,具體實作的代碼我就不po出來了,有興趣的朋友可以動手做一做,畢竟資料還是有它的實際效用的,然后上一篇文章沒想到kimol君竟然過來評論,一度以為看錯了哈哈哈,感謝大佬支持!
我是Hadi,祝大家周末愉快~

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/264433.html
標籤:AI