機器學習實戰(1)分類
參考書籍:Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems, Second Edition
編譯器:jupyter notebook
3.1 MNIST
MNIST資料集是一組數字圖片,相當于機器學習的“hello world”,其下載內容是一個類字典結構
下載資料集
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784',version=1)
mnist.keys()
輸出內容:
dict_keys(['data', 'target', 'frame', 'categories', 'feature_names', 'target_names', 'DESCR', 'details', 'url'])
看一下下載資料的陣列大小(.shape)
其中 X為特征資料,y為類別標簽
X, y = mnist["data"], mnist["target"]
X.shape
(70000, 784)
y.shape
(70000,)
資料中共有7000張圖片,我們可以用Matplotlib()的imshow()函式將其顯示出來:
import matplotlib as mpl
import matplotlib.pyplot as plt
some_digit = X[0]
some_digit_image = some_digit.reshape(28, 28)
plt.imshow(some_digit_image, cmap="binary")
plt.axis("off")
plt.show()
plt(matplotlib.pyplot)是python中的繪圖工具
其中some_digit儲存的是X[0],故可以顯示出X[0]的影像:
![X[0]](https://img.uj5u.com/2021/03/03/229625030736431.png)
這看起來就是數字5,而標簽告訴我們沒錯:
y[0]
'5'
這個標簽用字符格式儲存,而我們的演算法希望他是數字:
#將字符轉換成數字
import numpy as np
y = y.astype(np.uint8)
我們將前60000張圖片作為訓練集,后10000張圖片作為測驗集
#前60000是資料集,后10000是測驗集
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
3.2 訓練二級分類器
我們先從一個簡單的識別單一數字做起:這個數字 是5/不是5
我們先將y標簽改變(是5記為1,不是記為0)
y_train_5 = (y_train == 5)
y_test_5 = (y_test == 5)
接著挑選一個分類器并開始訓練: 隨機梯度下降(SGD)分類器
from sklearn.linear_model import SGDClassifier
sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(X_train, y_train_5)
說明:
1.sgd_clf儲存的是我們用的訓練方法,用 .fit(輸入資料, 標簽) 來進行樣本訓練
2.SGDClassfier本是隨機訓練,random_state是一個引數保證每次訓練結果相同,42是一個幸運數字而已
我們用它來檢驗數字5的圖片
(如果你的記憶力好,應該可以記得some_digit儲存的是X[0]這個資料)
sgd_clf.predict([some_digit])
輸出:
array([True])
3.3 性能測量
3.3.1 使用交叉驗證測量準確率
K-折交叉驗證:將k份資料中的 k-1個用來預測,1個用來訓練
本次我們用三個折疊進行預測
from sklearn.model_selection import cross_val_score
cross_val_score(sgd_clf, X_train, y_train_5, cv=3, scoring="accuracy")
輸出(每一個交叉驗證的準確率):
array([0.95035, 0.96035, 0.9604 ])
看似很高的分類準確率,但其實卻很低
假設我們有一個分類器,將每張圖片都看成:非5
事實表明它的準確率也會超過90%
3.3.2 混淆矩陣
評估分類器性能的更好方法是混淆矩陣,混淆矩陣會記錄A類別示例被分成B類別示例的次數,記錄在第A行第B列中,
為了不污染資料,我們先拋棄之前所應用的方法,用新的方法來驗證訓練集
#cross_val_predict: 一種直接的K-折交叉驗證,回傳每個折疊的預測
from sklearn.model_selection import cross_val_predict
y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3)
#獲取混淆矩陣
from sklearn.metrics import confusion_matrix
confusion_matrix(y_train_5, y_train_pred)
輸出:
array([[53892, 687],
[ 1891, 3530]], dtype=int64)
這表示,其中有53892張被正確的分為“非5”類別(True Negative),有687張被錯誤的分成了“5”(False Positive),有1891張被錯誤的分成了“非5”(False Negative),有3530張被正確的分為了“5”(True Positive),
混淆矩陣能提供大量資訊,但是有時你希望指標更簡潔一點:
3.3.3 精度 TP/(TP+FP)
from sklearn.metrics import precision_score, recall_score
precision_score(y_train_5, y_train_pred)
輸出:
0.8370879772350012
3.3.4 召回率 TP/(TP+FN)
recall_score(y_train_5, y_train_pred)
輸出:
0.6511713705958311
3.3.5 F1分數
F1分數:一個將精度和召回率結合的指標
F1=2/(1/精度+1/召回率)
#F1分數
from sklearn.metrics import f1_score
f1_score(y_train_5, y_train_pred)
輸出:
0.7325171197343846
3.3.6 召回率和精度權衡
我們先來看看SGDClassifier如何進行分類決策:
對于每個實體,他會基于決策函式計算出一個分值,如果該值大于閾值,則為正類,
閾值越高,召回率越低,(通常)精度越高
比如我們先觀察一下X[0]的決策分數
# decision_fuction函式回傳某個資料的決策分數
y_scores = sgd_clf.decision_function([some_digit])
y_scores
# 輸出:array([2164.22030239])
而我們對閾值的調整,會影響預測結果
threshold = 0
y_some_digit_pred = (y_scores > threshold)
y_some_digit_pred
#輸出:array([ True])
threshold = 8000
y_some_digit_pred = (y_scores > threshold)
y_some_digit_pred
#輸出:array([ False])
我們現要通過cross_val_predict()獲得所有資料的決策分數
y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3,
method="decision_function")
y_scores
#輸出:array([ 1200.93051237, -26883.79202424, -33072.03475406, ..., 13272.12718981, -7258.47203373, -16877.50840447])
通過這些決策分數,計算每種可能的閾值的精度和召回率是多少
#計算所有可能的閾值的精度和召回率
from sklearn.metrics import precision_recall_curve
precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores)
#用畫布畫出影像
def plot_precision_recall_vs_threshold(precisions, recalls, thresholds):
plt.plot(thresholds,precisions[:-1], "b--", label="Precision")
plt.plot(thresholds, recalls[:-1], "g--", label="Recall")
plot_precision_recall_vs_threshold(precisions, recalls, thresholds)
plt.show()
輸出:
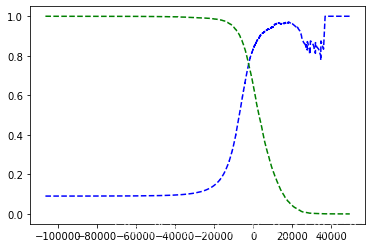
書中圖片并沒有后半段的折線,但出現這樣的情況應可以理解
我們找到精度>=90%的第一個閾值索引
#回傳精度>=90%的第一個閾值索引
threshold_90_precision = thresholds[np.argmax(precisions >= 0.90)]
threshold_90_precision
#輸出:3370.0194991439557
用這個閾值來進行二分類,并計算出這樣分類的精度和召回率
y_train_pred_90 = (y_scores >= threshold_90_precision)
#精度
precision_score(y_train_5, y_train_pred_90)
#輸出 0.9000345901072293
#召回率
recall_score(y_train_5, y_train_pred_90)
#輸出 0.4799852425751706
那你現在已經有一個90%精度的分類器了,
3.3.7 ROC曲線
ROC曲線的y軸為召回率,x軸為假正率
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_train_5, y_scores)
def plot_roc_curve(fpr, tpr, label=None):
plt.plot(fpr, tpr, linewidth=2, label=label)
plt.plot([0, 1],[0, 1], 'k--')
plot_roc_curve(fpr, tpr)
plt.show()
輸出:
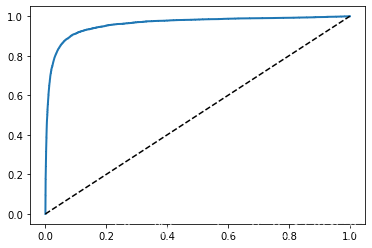
ROC的面積的大小(曲線包含的右下角面積)代表了分類器的好壞,用ROC AUC來表示
#計算ROC曲線下面積(AUG)
from sklearn.metrics import roc_auc_score
roc_auc_score(y_train_5, y_scores)
#輸出 0.9604938554008616
現在我們來用一個新的方法(隨機森林),來比較兩者的ROC AUC
#新方法:隨機森林
from sklearn.ensemble import RandomForestClassifier
forest_clf = RandomForestClassifier(random_state=42)
y_probas_forest = cross_val_predict(forest_clf, X_train, y_train_5, cv=3,
method="predict_proba")
y_scores_forest = y_probas_forest[:,1]
fpr_forest, tpr_forest, thresholds_forest = roc_curve(y_train_5, y_scores_forest)
plt.plot(fpr, tpr, "b:", label="SGD")
plot_roc_curve(fpr_forest, tpr_forest, "Random Forest")
plt.legend(loc="lower right")
plt.show()
輸出:
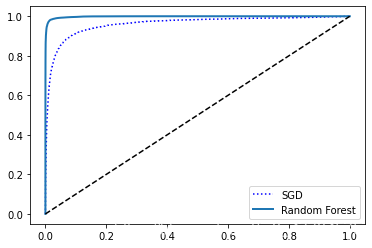
它更接近左上角,所以它的ROC AUC更高一些:
roc_auc_score(y_train_5, y_scores_forest)
#輸出:0.9983436731328145
3.4 多類分類器
創建一個系統將數字照片分為10類,有兩種方法:
1.OvR策略:用10個二元分類器:0-檢測器,1-檢測器…9-檢測器
2.OvO策略:每兩個數字創建一個二元分類器(45個):區分0和1,區分0和2,區分1和2,以此類推
我們在這里超前使用第五章的SVM分類器(OvR策略)
from sklearn.svm import SVC
svm_clf = SVC()
svm_clf.fit(X_train, y_train)
svm_clf.predict([some_digit])
輸出:
array([5], dtype=uint8)
檢測some_digit在每一個二元分類器中獲得的分數
some_digit_scores = svm_clf.decision_function([some_digit])
some_digit_scores
輸出:
array([[ 1.72501977, 2.72809088, 7.2510018 , 8.3076379 , -0.31087254,
9.3132482 , 1.70975103, 2.76765202, 6.23049537, 4.84771048]])
可見,它最大的可能的數字是5
SGD分類器可以直接將實體分為多個類,不用采用OvR或者OvO方式
sgd_clf.fit(X_train, y_train)
sgd_clf.predict([some_digit])
呼叫decision_fuction()就可以將SGD分類器每個實體分類的為每個類概率串列
sgd_clf.decision_function([some_digit])
輸出:
array([[-31893.03095419, -34419.69069632, -9530.63950739,
1823.73154031, -22320.14822878, -1385.80478895,
-26188.91070951, -16147.51323997, -4604.35491274,
-12050.767298 ]])
交叉驗證來評估SGD
cross_val_score(sgd_clf, X_train, y_train, cv=3, scoring="accuracy")
#輸出:array([0.87365, 0.85835, 0.8689 ])
將輸入進行簡單縮放,可以提高準確率
#縮放
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train.astype(np.float64))
cross_val_score(sgd_clf, X_train_scaled, y_train, cv=3, scoring="accuracy")
array([0.8983, 0.891 , 0.9018])
3.5 誤差分析
#混淆矩陣
y_train_pred = cross_val_predict(sgd_clf, X_train_scaled, y_train, cv=3)
conf_mx = confusion_matrix(y_train, y_train_pred)
conf_mx
array([[5577, 0, 22, 5, 8, 43, 36, 6, 225, 1],
[ 0, 6400, 37, 24, 4, 44, 4, 7, 212, 10],
[ 27, 27, 5220, 92, 73, 27, 67, 36, 378, 11],
[ 22, 17, 117, 5227, 2, 203, 27, 40, 403, 73],
[ 12, 14, 41, 9, 5182, 12, 34, 27, 347, 164],
[ 27, 15, 30, 168, 53, 4444, 75, 14, 535, 60],
[ 30, 15, 42, 3, 44, 97, 5552, 3, 131, 1],
[ 21, 10, 51, 30, 49, 12, 3, 5684, 195, 210],
[ 17, 63, 48, 86, 3, 126, 25, 10, 5429, 44],
[ 25, 18, 30, 64, 118, 36, 1, 179, 371, 5107]],
dtype=int64)
用畫布顯示
plt.matshow(conf_mx,cmap=plt.cm.gray)
plt.show()

但是我們需要關注錯誤,要將矩陣中每個值除以相應類中圖片數量,比較錯誤率
row_sums = conf_mx.sum(axis=1, keepdims=True)
norm_conf_mx = conf_mx / row_sums
并用0填充對角線
np.fill_diagonal(norm_conf_mx, 0)
plt.matshow(norm_conf_mx, cmap=plt.cm.gray)
plt.show()
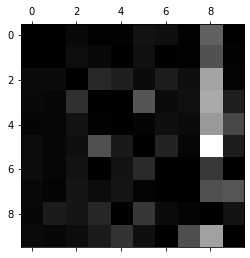
這樣才能獲得真實的錯誤率分布圖
比如,可以明顯看到,有很多數字被錯誤分類成數字8了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/265337.html
標籤:AI
上一篇:蘋果2021款 iPad Pro A14X 處理器性能比肩M1
下一篇:通過爬蟲實作twitter爬取