你在泰坦尼克號上你能活下來嗎?
泰坦尼克號的沉沒是歷史上最具影響力的海難之一,在1912年4月15日,泰坦尼克號的處女航中,與冰山相撞后沉沒,在當時,船上沒有足夠的救生艇供所有人使用,導致2224名乘客和機組人員中的1502人死亡,雖然幸存有一些運氣成分,但似乎有些人比其他人更有可能生存,
泰坦尼克號預測專案從kaggle建站開始,已經經歷了很多大佬的分析建模,有2萬多的團隊參與過該專案,是你加入kaggle最好的專案之一,
- 資料來源:https://www.kaggle.com/c/titanic/overview
- 本文主要是根據解決《泰坦尼克號》競賽和Manav Sehgal分享和一些其他來源的出色分享創建的,主要目的是為了對機器學習的各位提供一些專案實踐,原文地址如下:
- https://www.kaggle.com/startupsci/titanic-data-science-solutions
- A journey through Titanic
- Getting Started with Pandas: Kaggle’s Titanic Competition
- Titanic Best Working Classifier
先想明白我們怎么去做
參考《資料科學解決方案》一書,建模的7個流程:
- 定義問題,確定問題知道我們要做什么
- 獲取資料,一般是指訓練和測驗資料,
- 資料清洗,得到一份干凈好用的資料
- 資料分析,探索資料,為后續建模做準備,
- 建模,預測和解決問題,
- 可視化報告,呈現問題的解決步驟和最終解決方案,
- 得到結果,
建模流程
確定問題
每個資料集提出的同時也會伴隨著問題,kaggle會給與資料說明(https://www.kaggle.com/c/titanic/overview/description ),我們的問題很簡單: “什么樣的人更有可能生存呢?”
在泰坦尼克競賽中,我們可以訪問兩個類似的資料集,訓練集和測驗集,欄位包括乘客資訊,例如姓名、年齡、性別、社會經濟艙等,訓練集為“ train.csv”,測驗集為“ test.csv”,Train.csv將包含一部分乘客的詳細資訊(準確地說是891位乘客),并且重要的是,它會告訴我們他們是否幸存下來,“ test.csv”資料集包含類似的資訊,但沒有透露每位乘客的是否存活,我們的作業就是利用train.csv的資料訓練出模型,去預測機上其他418名乘客(在test.csv中找到)是否幸免于難,
獲取資料
kaggle 提供了很方便的下載方式,可以在資料界面中找到并下載資料:https://www.kaggle.com/c/titanic/overview/description
導包
# 匯入資料分析一些常用庫
import pandas as pd
import numpy as np
import random as rnd
# pd.options.display.max_columns = None
# 可視化包
import seaborn as sns
import matplotlib.pyplot as plt
plt.style.use("seaborn")
%matplotlib inline
sns.set(font="simhei")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 設定加載的字體名
plt.rcParams['axes.unicode_minus'] = False # 解決保存影像是負號'-'顯示為方塊的問題
# 機器學習包
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC, LinearSVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import Perceptron
from sklearn.linear_model import SGDClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.tree import DecisionTreeClassifier
匯入資料
train_df = pd.read_csv('train.csv')
test_df = pd.read_csv('test.csv')
combine = [train_df, test_df]
預覽資料
# 看一下我們有那些欄位
print(train_df.columns.values)
['PassengerId' 'Survived' 'Pclass' 'Name' 'Sex' 'Age' 'SibSp' 'Parch'
'Ticket' 'Fare' 'Cabin' 'Embarked']
# 簡單看一下我們的資料
train_df.head(3)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
train_df.tail(3)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 888 | 889 | 0 | 3 | Johnston, Miss. Catherine Helen "Carrie" | female | NaN | 1 | 2 | W./C. 6607 | 23.45 | NaN | S |
| 889 | 890 | 1 | 1 | Behr, Mr. Karl Howell | male | 26.0 | 0 | 0 | 111369 | 30.00 | C148 | C |
| 890 | 891 | 0 | 3 | Dooley, Mr. Patrick | male | 32.0 | 0 | 0 | 370376 | 7.75 | NaN | Q |
資料清洗
欄位整理
- PassengerId 用戶編號:目前作為用戶唯一標識,此處無特別意義(有些編號是具有價值的,比如身份證)
- Survived 是否幸存:目標欄位,是我們要預測的資料
- Pclass 用戶階級:分類欄位,1為最高級,3為最低級
- Name 姓名:可以看出家族關系
- Sex 性別
- Age 年齡
- SibSp:泰坦尼克號上與乘客同行的兄弟姐妹(Siblings)和配偶(Spouse)數目
- Parch:描述了泰坦尼克號上與乘客同行的家長(Parents)和孩子(Children)數目
- Ticket 船票號
- Fare 票價
- Cabin 船艙號
- Embarked 乘客上船時的港口
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-L2En3s3d-1614530159408)(attachment:image.png)]
識別特征型別
特征主要型別有:時間型、數值型、類別型、文本型
哪些特征是分型別特征?
類別型特征將相似屬性歸為一類,但是大多數模型都不能直接處理文本型資料,必須要轉換為數值型才能使用,
類別型特征可以分為定類變數、定序變數、定距變數和定比變數,
- 定類變數:如性別(男、女、其他),三種取值之間是相互獨立的,彼此之間完全沒有關系,這種變數稱之為名義變數,
- 定序變數:如學歷(小學、初中、高中),三種取值不是完全獨立的,我們可以明顯看出,在性質上可以有高中>初中>小學這樣 的聯系,學歷有高低,但是學歷的取值之間卻不是可以計算的,我們不能說小學 + 某個取值 = 初中,這是有序變 量,
- 定距變數:如溫度(>25攝氏度、>30攝氏度 、>35攝氏度),各個取值之間有聯系,且是可以互相計算的,而且兩者的差值有 意義,比如35攝氏度 - 25攝氏度 = 10攝氏度,分類之間可以通過數學計算互相轉換,這是有距變數,
- 定比變數:如質量(>10kg、>50kg、>100kg),各個取值之間有聯系,不僅可以計算差值,還可以計算其商值,
定序變數:Pclass 用戶階級:分類欄位,1為最高級,3為最低級
定類變數:Sex 性別,Embarked 乘客上船時的港口,Survived 是否幸存
哪些特征是數值型特征?
數值型隨樣本的不同而進行變化,一般分為連續型,離散型,經常使用歸一化,離散化等方法進行處理
連續型:Age 年齡,fare 票價,
離散型:SibSp,Parch,
哪些特征是文本型特征?
文本型:Name,姓名中有很多符號,也存在一些錯別字的問題
還有一些混合型特征
混合型資料特征:Ticket 船票號,Cabin 船艙號
- 還有1個特征: PassengerId 用戶編號(無意義,后續會洗掉)
資料清洗
空值,資料型別
空值:
訓練資料集空值排序:Cabin > Age > Embarked,
測驗資料集空值排序:Cabin > Age ,
各特征的資料型別是什么?
訓練集:7個特征是整數或浮點數,字串物件5個,
測驗集:6個特征是整數或浮點數,字串物件5個,
print(train_df.info())
print("--"*20)
print(test_df.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
None
----------------------------------------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 418 entries, 0 to 417
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 418 non-null int64
1 Pclass 418 non-null int64
2 Name 418 non-null object
3 Sex 418 non-null object
4 Age 332 non-null float64
5 SibSp 418 non-null int64
6 Parch 418 non-null int64
7 Ticket 418 non-null object
8 Fare 417 non-null float64
9 Cabin 91 non-null object
10 Embarked 418 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 36.0+ KB
None
- 通過訓練集各個特征的分布情況,我們可以得到一些很有用的資訊:
- 訓練集中有891條資料,泰塔尼克號實際有2224個客戶,占旅客實際數量的40%
- 是否幸存是只有0或1的分類特征
- 約有38%的樣本存活下來,但泰坦尼克號實際存活率為32%
- 大多數乘客(> 75%)沒有和父母或孩子一起旅行
- 近30%的乘客有兄弟姐妹和/或配偶
- 票價差異很大,只有極少的乘客(<1%)支付的費用高達512美元
- 65-80歲年齡段的老年乘客很少(<1%),
下面會有具體的資料展示
數值型分布
train_df.describe()
| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| count | 891.000000 | 891.000000 | 891.000000 | 714.000000 | 891.000000 | 891.000000 | 891.000000 |
| mean | 446.000000 | 0.383838 | 2.308642 | 29.699118 | 0.523008 | 0.381594 | 32.204208 |
| std | 257.353842 | 0.486592 | 0.836071 | 14.526497 | 1.102743 | 0.806057 | 49.693429 |
| min | 1.000000 | 0.000000 | 1.000000 | 0.420000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 223.500000 | 0.000000 | 2.000000 | 20.125000 | 0.000000 | 0.000000 | 7.910400 |
| 50% | 446.000000 | 0.000000 | 3.000000 | 28.000000 | 0.000000 | 0.000000 | 14.454200 |
| 75% | 668.500000 | 1.000000 | 3.000000 | 38.000000 | 1.000000 | 0.000000 | 31.000000 |
| max | 891.000000 | 1.000000 | 3.000000 | 80.000000 | 8.000000 | 6.000000 | 512.329200 |
類別型特征的分布
姓名在資料集中是唯一的(count = unique = 891)
性別變數有2個值,其中男性占65%(top=男性,freq = 577 / count = 891),
船艙號在樣本中具有多個重復項,也可以看出,有幾個乘客共用一個船艙,
港口有3個可能的值,大多數乘客使用的S埠(top= S)
船票號具有很高的重復率(unique = 681),為22%,
# 類別型分布
train_df.describe(include=['O'])
| Name | Sex | Ticket | Cabin | Embarked | |
|---|---|---|---|---|---|
| count | 891 | 891 | 891 | 204 | 889 |
| unique | 891 | 2 | 681 | 147 | 3 |
| top | Slabenoff, Mr. Petco | male | 1601 | G6 | S |
| freq | 1 | 577 | 7 | 4 | 644 |
資料探索及猜想
資料分析猜想
基于到目前為止完成的資料分析,我們得出以下假設,在采取適當措施之前,我們可能會進一步驗證這些假設,
1. Correlating.相關性
我們想知道每個特征與生存率的關聯程度,找到他們的相關關系,盡可能在早期就去做它,并將相關性與專案后期的建模相關性進行匹配,
2. Completing.完成
我們可能要完成“年齡”特征,因為它肯定與生存相關,
我們可能要完成“港口”特征,因為它也可能與生存或其他重要功能相關,
3. Correcting.糾正
船票號特征可能會從我們的分析中洗掉,因為它包含很高的重復率(22%),并且船票號與生存率之間可能沒有關聯,
船艙號特征可能由于高度不完整或在訓練和測驗資料集中包含許多空值而被洗掉,
游客ID可能會從訓練資料集中洗掉,因為它對生存沒有幫助,沒什么意義,
姓名特征是相對非標準的,可能不會直接有助于生存分析,因此可能會被放棄,
4. Creating.創建
我們可能想基于Parch和SibSp創建一個稱為“家庭”的新特征,以獲取船上家庭成員的總數,
我們可能要設計名稱特征,以將姓提取為新特征,
我們可能要為年齡段創建新功能,這會將連續的數字特征轉換為序數分類特征,
如果它有助于我們的分析,我們可能還想創建一個票價范圍特征,
5. Classifying.分類
我們也可以根據前面提到的問題描述增加假設,
女性(性別=女性)更有可能存活下來,
兒童(年齡<?)存活的可能性更高,
上等乘客(Pclass = 1)更有可能幸存下來,
透視表分析
透視表分析,類似Excel中的資料透視表,可以看到資料的分布趨勢
為了確認我們的一些觀察和假設,我們可以通過使特征獨立來快速分析特征的相關性,在此階段,我們只能對沒有任何空值的特征執行此操作,對分型別(Sex),有序型(Pclass)或離散型的(SibSp,Parch)的特征這樣做也是有意義的,
1. Pclass我們發現Pclass = 1和Survived之間存在顯著相關性(> 0.5),我們決定在模型中包括此功能,
2. 性別,我們觀察問題可以發現,即性別=女性具有很高的生存率,為74%,
3. SibSp和Parch這些特征對于某些值零相關,最好是從這些單個特征中派生一個特征或一組特征,做一個更好的特征出來,
# 上等乘客更容易存活
train_df[['Pclass', 'Survived'
]].groupby(['Pclass'],
as_index=False).mean().sort_values(by='Survived',
ascending=False)
| Pclass | Survived | |
|---|---|---|
| 0 | 1 | 0.629630 |
| 1 | 2 | 0.472826 |
| 2 | 3 | 0.242363 |
# 女性更容易存活
train_df[['Sex', 'Survived']].groupby(['Sex'],as_index=False).mean().sort_values(by='Survived',
ascending=False)
| Sex | Survived | |
|---|---|---|
| 0 | female | 0.742038 |
| 1 | male | 0.188908 |
# 與乘客同行的兄弟姐妹和配偶數量
train_df[["SibSp", "Survived"
]].groupby(['SibSp'],
as_index=False).mean().sort_values(by='Survived',
ascending=False)
| SibSp | Survived | |
|---|---|---|
| 1 | 1 | 0.535885 |
| 2 | 2 | 0.464286 |
| 0 | 0 | 0.345395 |
| 3 | 3 | 0.250000 |
| 4 | 4 | 0.166667 |
| 5 | 5 | 0.000000 |
| 6 | 8 | 0.000000 |
# 與乘客同行的家長和孩子的數目
train_df[["Parch", "Survived"
]].groupby(['Parch'],
as_index=False).mean().sort_values(by='Survived',
ascending=False)
| Parch | Survived | |
|---|---|---|
| 3 | 3 | 0.600000 |
| 1 | 1 | 0.550847 |
| 2 | 2 | 0.500000 |
| 0 | 0 | 0.343658 |
| 5 | 5 | 0.200000 |
| 4 | 4 | 0.000000 |
| 6 | 6 | 0.000000 |
可視化分析
可視化分析,通過圖表來形象的刻畫資料,確認一些假設,為后續建模做準備
1. 關聯數字特征
首先要了解數值特征與我們的求解目標之間的相關性,
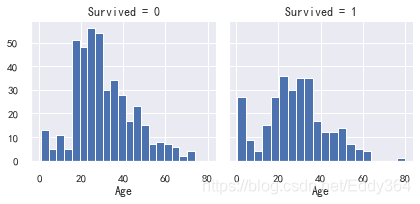
一般使用直方圖分析連續數字變數(例如Age),直方圖可以使用自動定義的bin或等距范圍的帶指示樣本的分布,這有助于我們回答與特定頻段有關的問題(比如:嬰兒的存活率更高嗎?)
2. 觀察可視化
嬰兒(年齡<= 4)具有較高的存活率,
年齡最大的乘客(年齡= 80)幸存下來,
15至25歲的大批人無法生存,
大多數乘客年齡在15-35歲之間,
3. 決定
通過簡單的可視化分析證實了我們的假設,為后面的建模做鋪墊,
在模型訓練中要考慮年齡,
補充年齡特征(空值),
分組年齡,
g = sns.FacetGrid(train_df, col='Survived')
g.map(plt.hist, 'Age', bins=20)
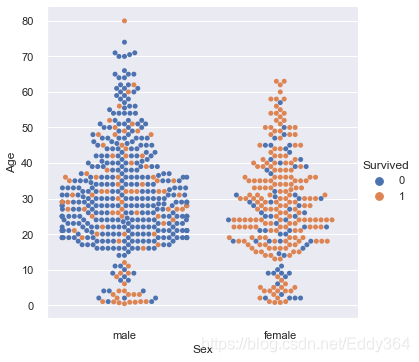
sns.set()
sns.catplot(data=train_df, kind="swarm", x="Sex",y="Age", hue="Survived")
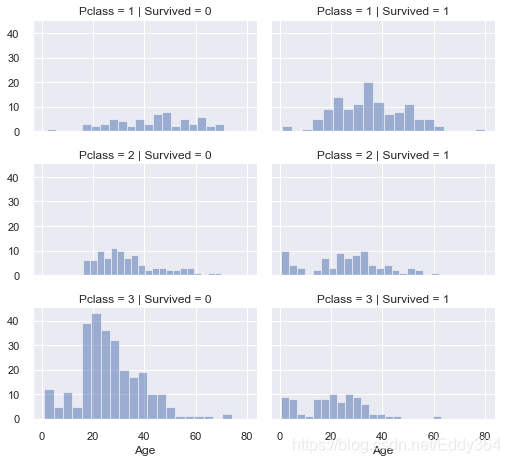
# grid = sns.FacetGrid(train_df, col='Pclass', hue='Survived')
grid = sns.FacetGrid(train_df, col='Survived', row='Pclass', size=2.2, aspect=1.6)
grid.map(plt.hist, 'Age', alpha=.5, bins=20)
grid.add_legend();
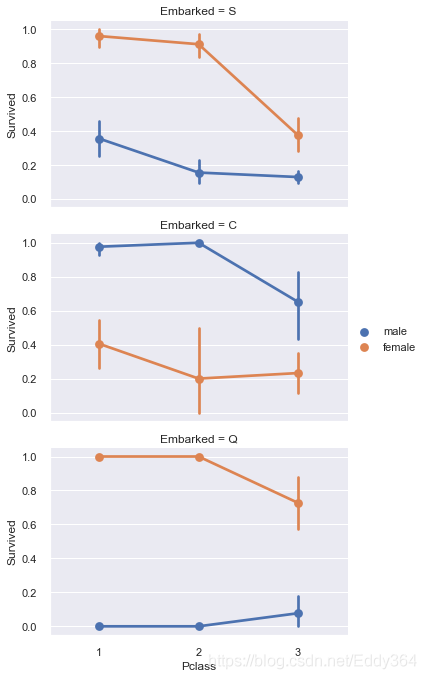
# grid = sns.FacetGrid(train_df, col='Embarked')
grid = sns.FacetGrid(train_df, row='Embarked', size=3.2, aspect=1.6)
grid.map(sns.pointplot, 'Pclass', 'Survived', 'Sex', palette='deep')
grid.add_legend()
make資料
資料分析猜想
基于到目前為止完成的資料分析,我們已經得到了許多有用的資訊,現在我們要利用之前得到的資訊對我們的資料,進行選擇,糾正,創造,選擇我們需要的資料,化繁為簡,以點透面,
洗掉特征
通過洗掉特性,我們可以處理更少的資料,加速資料處理,簡化分析,
基于前面我們的分析和假設:
- 洗掉Cabin(船艙號),它的缺失率很高(只有204條資料),空值太多且對于是否生存來說可能沒啥效果
- 洗掉Ticket(船票號),因為它包含很高的重復率(22%),并且船票號與生存率之間可能沒有關聯
通常我們可以同時對訓練和測驗資料集洗掉無意義的欄位,
print("Before", train_df.shape, test_df.shape, combine[0].shape, combine[1].shape)
train_df = train_df.drop(['Ticket', 'Cabin'], axis=1)
test_df = test_df.drop(['Ticket', 'Cabin'], axis=1)
combine = [train_df, test_df]
"After", train_df.shape, test_df.shape, combine[0].shape, combine[1].shape
Before (891, 12) (418, 11) (891, 12) (418, 11)
('After', (891, 10), (418, 9), (891, 10), (418, 9))
從現有特征中提取新特征,創造一個合適新特征可以讓模型更加準確,
在去掉名字和乘客id特征之前,我們想分析一下是否可以通過名字這個特征來提取到一些有用的資訊,仔細去看姓名這個特征會發現在姓前面是有記載著一些頭銜的,Miss,Mr,Sir等等,這些會不會和生存有關系呢,提取出這些稱呼看一下:
觀察資料
某些頭銜大多活了下來(夫人、女士、先生)
我們決定保留新的title特征用于模型訓練,
#使用正則運算式提取標題
for dataset in combine:
dataset['Title'] = dataset.Name.str.extract(' ([A-Za-z]+)\.', expand=False)
pd.crosstab(train_df['Title'], train_df['Sex'])
| Sex | female | male |
|---|---|---|
| Title | ||
| Capt | 0 | 1 |
| Col | 0 | 2 |
| Countess | 1 | 0 |
| Don | 0 | 1 |
| Dr | 1 | 6 |
| Jonkheer | 0 | 1 |
| Lady | 1 | 0 |
| Major | 0 | 2 |
| Master | 0 | 40 |
| Miss | 182 | 0 |
| Mlle | 2 | 0 |
| Mme | 1 | 0 |
| Mr | 0 | 517 |
| Mrs | 125 | 0 |
| Ms | 1 | 0 |
| Rev | 0 | 6 |
| Sir | 0 | 1 |
for dataset in combine:
dataset['Title'] = dataset['Title'].replace([
'Lady', 'Countess', 'Capt', 'Col', 'Don', 'Dr', 'Major', 'Rev', 'Sir',
'Jonkheer', 'Dona'
], 'Rare')
dataset['Title'] = dataset['Title'].replace('Mlle', 'Miss')
dataset['Title'] = dataset['Title'].replace('Ms', 'Miss')
dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs')
train_df[['Title', 'Survived']].groupby(['Title'], as_index=False).mean()
| Title | Survived | |
|---|---|---|
| 0 | Master | 0.575000 |
| 1 | Miss | 0.702703 |
| 2 | Mr | 0.156673 |
| 3 | Mrs | 0.793651 |
| 4 | Rare | 0.347826 |
dataset
| PassengerId | Pclass | Name | Sex | Age | SibSp | Parch | Fare | Embarked | Title | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 892 | 3 | Kelly, Mr. James | male | 34.5 | 0 | 0 | 7.8292 | Q | Mr |
| 1 | 893 | 3 | Wilkes, Mrs. James (Ellen Needs) | female | 47.0 | 1 | 0 | 7.0000 | S | Mrs |
| 2 | 894 | 2 | Myles, Mr. Thomas Francis | male | 62.0 | 0 | 0 | 9.6875 | Q | Mr |
| 3 | 895 | 3 | Wirz, Mr. Albert | male | 27.0 | 0 | 0 | 8.6625 | S | Mr |
| 4 | 896 | 3 | Hirvonen, Mrs. Alexander (Helga E Lindqvist) | female | 22.0 | 1 | 1 | 12.2875 | S | Mrs |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 413 | 1305 | 3 | Spector, Mr. Woolf | male | NaN | 0 | 0 | 8.0500 | S | Mr |
| 414 | 1306 | 1 | Oliva y Ocana, Dona. Fermina | female | 39.0 | 0 | 0 | 108.9000 | C | Rare |
| 415 | 1307 | 3 | Saether, Mr. Simon Sivertsen | male | 38.5 | 0 | 0 | 7.2500 | S | Mr |
| 416 | 1308 | 3 | Ware, Mr. Frederick | male | NaN | 0 | 0 | 8.0500 | S | Mr |
| 417 | 1309 | 3 | Peter, Master. Michael J | male | NaN | 1 | 1 | 22.3583 | C | Master |
418 rows × 10 columns
#將分類特征轉換成數值型
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5}
for dataset in combine:
dataset['Title'] = dataset['Title'].map(title_mapping)
dataset['Title'] = dataset['Title'].fillna(0)
train_df.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Fare | Embarked | Title | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | 7.2500 | S | 1 |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | 71.2833 | C | 3 |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | 7.9250 | S | 2 |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 53.1000 | S | 3 |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 8.0500 | S | 1 |
#現在把姓名和PassengerId洗掉
print("Before", train_df.shape, test_df.shape, combine[0].shape, combine[1].shape)
train_df = train_df.drop(['Name', 'PassengerId'], axis=1)
test_df = test_df.drop(['Name', 'PassengerId'], axis=1)
combine = [train_df, test_df]
"After", train_df.shape, test_df.shape, combine[0].shape, combine[1].shape
Before (891, 11) (418, 10) (891, 11) (418, 10)
('After', (891, 9), (418, 8), (891, 9), (418, 8))
轉換分類特性
大部分的模型都不能直接處理文本資料,需要將分型別資料轉換成數值型,目前我們還有Sex性別變數需要進行轉換
for dataset in combine:
dataset['Sex'] = dataset['Sex'].map( {'female': 1, 'male': 0} ).astype(int)
train_df.head()
| Survived | Pclass | Sex | Age | SibSp | Parch | Fare | Embarked | Title | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | 0 | 22.0 | 1 | 0 | 7.2500 | S | 1 |
| 1 | 1 | 1 | 1 | 38.0 | 1 | 0 | 71.2833 | C | 3 |
| 2 | 1 | 3 | 1 | 26.0 | 0 | 0 | 7.9250 | S | 2 |
| 3 | 1 | 1 | 1 | 35.0 | 1 | 0 | 53.1000 | S | 3 |
| 4 | 0 | 3 | 0 | 35.0 | 0 | 0 | 8.0500 | S | 1 |
現在我們已經得到了一份看起來很不錯的資料,有我們需要的欄位,但一些欄位仍有很多的空值,會影響模型的準確度,接下來我們要使用一些方法進行空值填充,缺失值填充有許多方法,一般的有,特殊值填充,均值/眾數/中位數填充,人工補充(利用資料間的聯系進行補充或者重新采集等),機器學習方法填充等(回歸,最大似然估計、聚類等),值得一說的是實際情況如果對模型的精度的要求不高或者特征的作用有限的情況下,考慮到運行效率的問題可以洗掉一些缺失度較高的特征,
補充連續數值型特征
現在,我們應該開始評估和填充缺失值或空值,我們對于目前模型來說可以考慮三種方法來完成數值連續特征,
- 一個簡單的方法是在均值和標準偏差之間生成亂數,
- 更準確的猜測缺失值的方法是使用其他相關特征,在我們的案例中,我們注意到年齡、性別和Pclass之間的相關性,我們可以使用Pclass和性別特征組合的年齡中位數猜測年齡值,因此,Pclass=1, Gender=0, Pclass=1, Gender=1,依此類推…
- 結合方法1和2,因此,不要根據中位數猜測年齡值,而是根據Pclass和性別組合,在平均值和標準偏差之間使用亂數字,方法1和3將在我們的模型中引入隨機噪聲,多次執行的結果可能不同,我們更喜歡方法二,
# grid = sns.FacetGrid(train_df, col='Pclass', hue='Gender')
grid = sns.FacetGrid(train_df, row='Pclass', col='Sex', size=2.2, aspect=1.6)
grid.map(plt.hist, 'Age', alpha=.5, bins=20)
grid.add_legend()
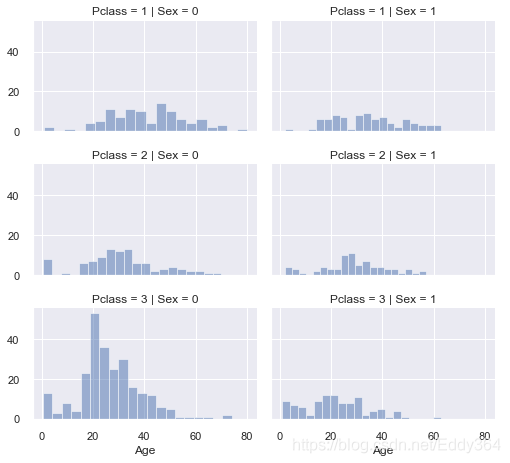
#現在開始用性別和Pclass 預測年齡,用陣列儲存
guess_ages = np.zeros((2,3))
guess_ages
array([[0., 0., 0.],
[0., 0., 0.]])
#遍歷 Sex和Pclass 進行預測
for dataset in combine:
for i in range(0, 2):
for j in range(0, 3):
guess_df = dataset[(dataset['Sex'] == i)
& (dataset['Pclass'] == j + 1)]['Age'].dropna()
# age_mean = guess_df.mean()
# age_std = guess_df.std()
# age_guess = rnd.uniform(age_mean - age_std, age_mean + age_std)
age_guess = guess_df.median()
guess_ages[i, j] = int(age_guess / 0.5 + 0.5) * 0.5
for i in range(0, 2):
for j in range(0, 3):
dataset.loc[(dataset.Age.isnull()) & (dataset.Sex == i) &
(dataset.Pclass == j + 1), 'Age'] = guess_ages[i, j]
dataset['Age'] = dataset['Age'].astype(int)
train_df.head()
| Survived | Pclass | Sex | Age | SibSp | Parch | Fare | Embarked | Title | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | 0 | 22 | 1 | 0 | 7.2500 | S | 1 |
| 1 | 1 | 1 | 1 | 38 | 1 | 0 | 71.2833 | C | 3 |
| 2 | 1 | 3 | 1 | 26 | 0 | 0 | 7.9250 | S | 2 |
| 3 | 1 | 1 | 1 | 35 | 1 | 0 | 53.1000 | S | 3 |
| 4 | 0 | 3 | 0 | 35 | 0 | 0 | 8.0500 | S | 1 |
#切分年齡,將年齡分段看看和存活之間的關系
train_df['AgeBand'] = pd.cut(train_df['Age'], 5)
train_df[['AgeBand', 'Survived'
]].groupby(['AgeBand'],
as_index=False).mean().sort_values(by='AgeBand',
ascending=True)
| AgeBand | Survived | |
|---|---|---|
| 0 | (-0.08, 16.0] | 0.550000 |
| 1 | (16.0, 32.0] | 0.337374 |
| 2 | (32.0, 48.0] | 0.412037 |
| 3 | (48.0, 64.0] | 0.434783 |
| 4 | (64.0, 80.0] | 0.090909 |
for dataset in combine:
dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0
dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32), 'Age'] = 1
dataset.loc[(dataset['Age'] > 32) & (dataset['Age'] <= 48), 'Age'] = 2
dataset.loc[(dataset['Age'] > 48) & (dataset['Age'] <= 64), 'Age'] = 3
dataset.loc[ dataset['Age'] > 64, 'Age']
train_df.head()
| Survived | Pclass | Sex | Age | SibSp | Parch | Fare | Embarked | Title | AgeBand | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | 0 | 1 | 1 | 0 | 7.2500 | S | 1 | (16.0, 32.0] |
| 1 | 1 | 1 | 1 | 2 | 1 | 0 | 71.2833 | C | 3 | (32.0, 48.0] |
| 2 | 1 | 3 | 1 | 1 | 0 | 0 | 7.9250 | S | 2 | (16.0, 32.0] |
| 3 | 1 | 1 | 1 | 2 | 1 | 0 | 53.1000 | S | 3 | (32.0, 48.0] |
| 4 | 0 | 3 | 0 | 2 | 0 | 0 | 8.0500 | S | 1 | (32.0, 48.0] |
#這樣年齡段就做好了
train_df = train_df.drop(['AgeBand'], axis=1)
combine = [train_df, test_df]
train_df.head()
| Survived | Pclass | Sex | Age | SibSp | Parch | Fare | Embarked | Title | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | 0 | 1 | 1 | 0 | 7.2500 | S | 1 |
| 1 | 1 | 1 | 1 | 2 | 1 | 0 | 71.2833 | C | 3 |
| 2 | 1 | 3 | 1 | 1 | 0 | 0 | 7.9250 | S | 2 |
| 3 | 1 | 1 | 1 | 2 | 1 | 0 | 53.1000 | S | 3 |
| 4 | 0 | 3 | 0 | 2 | 0 | 0 | 8.0500 | S | 1 |
繼續精簡資料,利用SibSp和Parch創建一個新特征
#FamilySize
for dataset in combine:
dataset['FamilySize'] = dataset['SibSp'] + dataset['Parch'] + 1
train_df[['FamilySize', 'Survived'
]].groupby(['FamilySize'],
as_index=False).mean().sort_values(by='Survived',
ascending=False)
| FamilySize | Survived | |
|---|---|---|
| 3 | 4 | 0.724138 |
| 2 | 3 | 0.578431 |
| 1 | 2 | 0.552795 |
| 6 | 7 | 0.333333 |
| 0 | 1 | 0.303538 |
| 4 | 5 | 0.200000 |
| 5 | 6 | 0.136364 |
| 7 | 8 | 0.000000 |
| 8 | 11 | 0.000000 |
#IsAlone 單獨一人來的
for dataset in combine:
dataset['IsAlone'] = 0
dataset.loc[dataset['FamilySize'] == 1, 'IsAlone'] = 1
train_df[['IsAlone', 'Survived']].groupby(['IsAlone'], as_index=False).mean()
| IsAlone | Survived | |
|---|---|---|
| 0 | 0 | 0.505650 |
| 1 | 1 | 0.303538 |
#使用IsAlone 代替'Parch', 'SibSp', 'FamilySize'
train_df = train_df.drop(['Parch', 'SibSp', 'FamilySize'], axis=1)
test_df = test_df.drop(['Parch', 'SibSp', 'FamilySize'], axis=1)
combine = [train_df, test_df]
train_df.head()
| Survived | Pclass | Sex | Age | Fare | Embarked | Title | IsAlone | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | 0 | 1 | 7.2500 | S | 1 | 0 |
| 1 | 1 | 1 | 1 | 2 | 71.2833 | C | 3 | 0 |
| 2 | 1 | 3 | 1 | 1 | 7.9250 | S | 2 | 1 |
| 3 | 1 | 1 | 1 | 2 | 53.1000 | S | 3 | 0 |
| 4 | 0 | 3 | 0 | 2 | 8.0500 | S | 1 | 1 |
同樣的 年齡和Pclass 我門也可以放到一起,做一個人工特征
for dataset in combine:
dataset['Age*Class'] = dataset.Age * dataset.Pclass
train_df.loc[:, ['Age*Class', 'Age', 'Pclass']].head(10)
| Age*Class | Age | Pclass | |
|---|---|---|---|
| 0 | 3 | 1 | 3 |
| 1 | 2 | 2 | 1 |
| 2 | 3 | 1 | 3 |
| 3 | 2 | 2 | 1 |
| 4 | 6 | 2 | 3 |
| 5 | 3 | 1 | 3 |
| 6 | 3 | 3 | 1 |
| 7 | 0 | 0 | 3 |
| 8 | 3 | 1 | 3 |
| 9 | 0 | 0 | 2 |
現在讓我們把分類特征也補充完整
#使用港口的眾數填充缺失值
freq_port = train_df.Embarked.dropna().mode()[0]
for dataset in combine:
dataset['Embarked'] = dataset['Embarked'].fillna(freq_port)
train_df[['Embarked', 'Survived'
]].groupby(['Embarked'],
as_index=False).mean().sort_values(by='Survived', ascending=False)
| Embarked | Survived | |
|---|---|---|
| 0 | C | 0.553571 |
| 1 | Q | 0.389610 |
| 2 | S | 0.339009 |
#轉換成數值型
for dataset in combine:
dataset['Embarked'] = dataset['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int)
train_df.head()
| Survived | Pclass | Sex | Age | Fare | Embarked | Title | IsAlone | Age*Class | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | 0 | 1 | 7.2500 | 0 | 1 | 0 | 3 |
| 1 | 1 | 1 | 1 | 2 | 71.2833 | 1 | 3 | 0 | 2 |
| 2 | 1 | 3 | 1 | 1 | 7.9250 | 0 | 2 | 1 | 3 |
| 3 | 1 | 1 | 1 | 2 | 53.1000 | 0 | 3 | 0 | 2 |
| 4 | 0 | 3 | 0 | 2 | 8.0500 | 0 | 1 | 1 | 6 |
快速完成和轉換的數字功能
現在,我們可以使用mode來完成測驗資料集中單個缺失值的Fare特征,以獲得該特征最頻繁出現的值,我們只需要一行代碼就可以完成,請注意,我們并沒有創建一個中間的新特性,也沒有做任何進一步的相關性分析來猜測丟失的特性,因為我們只替換了一個值,完成目標實作了模型演算法對非空值操作的預期要求,我們可能還想把票價四舍五入到兩個小數,因為它代表貨幣,
test_df['Fare'].fillna(test_df['Fare'].dropna().median(), inplace=True)
test_df.head()
| Pclass | Sex | Age | Fare | Embarked | Title | IsAlone | Age*Class | |
|---|---|---|---|---|---|---|---|---|
| 0 | 3 | 0 | 2 | 7.8292 | 2 | 1 | 1 | 6 |
| 1 | 3 | 1 | 2 | 7.0000 | 0 | 3 | 0 | 6 |
| 2 | 2 | 0 | 3 | 9.6875 | 2 | 1 | 1 | 6 |
| 3 | 3 | 0 | 1 | 8.6625 | 0 | 1 | 1 | 3 |
| 4 | 3 | 1 | 1 | 12.2875 | 0 | 3 | 0 | 3 |
#票價分組
train_df['FareBand'] = pd.qcut(train_df['Fare'], 4)
train_df[['FareBand', 'Survived'
]].groupby(['FareBand'],
as_index=False).mean().sort_values(by='FareBand',
ascending=True)
| FareBand | Survived | |
|---|---|---|
| 0 | (-0.001, 7.91] | 0.197309 |
| 1 | (7.91, 14.454] | 0.303571 |
| 2 | (14.454, 31.0] | 0.454955 |
| 3 | (31.0, 512.329] | 0.581081 |
#將票價特征轉換為基于票價帶的序數值
for dataset in combine:
dataset.loc[ dataset['Fare'] <= 7.91, 'Fare'] = 0
dataset.loc[(dataset['Fare'] > 7.91) & (dataset['Fare'] <= 14.454), 'Fare'] = 1
dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 31), 'Fare'] = 2
dataset.loc[ dataset['Fare'] > 31, 'Fare'] = 3
dataset['Fare'] = dataset['Fare'].astype(int)
train_df = train_df.drop(['FareBand'], axis=1)
combine = [train_df, test_df]
train_df.head(10)
| Survived | Pclass | Sex | Age | Fare | Embarked | Title | IsAlone | Age*Class | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | 0 | 1 | 0 | 0 | 1 | 0 | 3 |
| 1 | 1 | 1 | 1 | 2 | 3 | 1 | 3 | 0 | 2 |
| 2 | 1 | 3 | 1 | 1 | 1 | 0 | 2 | 1 | 3 |
| 3 | 1 | 1 | 1 | 2 | 3 | 0 | 3 | 0 | 2 |
| 4 | 0 | 3 | 0 | 2 | 1 | 0 | 1 | 1 | 6 |
| 5 | 0 | 3 | 0 | 1 | 1 | 2 | 1 | 1 | 3 |
| 6 | 0 | 1 | 0 | 3 | 3 | 0 | 1 | 1 | 3 |
| 7 | 0 | 3 | 0 | 0 | 2 | 0 | 4 | 0 | 0 |
| 8 | 1 | 3 | 1 | 1 | 1 | 0 | 3 | 0 | 3 |
| 9 | 1 | 2 | 1 | 0 | 2 | 1 | 3 | 0 | 0 |
test_df.head(10)
| Pclass | Sex | Age | Fare | Embarked | Title | IsAlone | Age*Class | |
|---|---|---|---|---|---|---|---|---|
| 0 | 3 | 0 | 2 | 0 | 2 | 1 | 1 | 6 |
| 1 | 3 | 1 | 2 | 0 | 0 | 3 | 0 | 6 |
| 2 | 2 | 0 | 3 | 1 | 2 | 1 | 1 | 6 |
| 3 | 3 | 0 | 1 | 1 | 0 | 1 | 1 | 3 |
| 4 | 3 | 1 | 1 | 1 | 0 | 3 | 0 | 3 |
| 5 | 3 | 0 | 0 | 1 | 0 | 1 | 1 | 0 |
| 6 | 3 | 1 | 1 | 0 | 2 | 2 | 1 | 3 |
| 7 | 2 | 0 | 1 | 2 | 0 | 1 | 0 | 2 |
| 8 | 3 | 1 | 1 | 0 | 1 | 3 | 1 | 3 |
| 9 | 3 | 0 | 1 | 2 | 0 | 1 | 0 | 3 |
到此,我們完成了一份資料的制作,為接下來的建模做好了資料準備
建模、預測和解決問題
現在我們已經準備好訓練模型并預測所需的解決方案了,
有60多種預測建模演算法可供選擇,我們必須了解問題的型別和解決方案的需求,將范圍縮小到我們可以評估的少數幾個模型,我們的問題是一個分類和回歸的類問題,我們想要確定輸出(是否存活)與其他變數或特征(性別、年齡、港口等)之間的關系,當我們用給定的資料集訓練我們的模型時,我們也在進行一類被稱為監督學習的機器學習,有了這兩個標準-監督學習加上分類和回歸,我們可以縮小我們的模型選擇,包括:
- 邏輯回歸
- SVM 支持向量機
- K近鄰
- 樸素貝葉斯分類器
- 決策樹
- 隨機森林
- 感知機
- 人工神經網路
X_train = train_df.drop("Survived", axis=1)
Y_train = train_df["Survived"]
X_test = test_df.copy()
X_train.shape, Y_train.shape, X_test.shape
((891, 8), (891,), (418, 8))
#看下我們的資料
X_train
| Pclass | Sex | Age | Fare | Embarked | Title | IsAlone | Age*Class | |
|---|---|---|---|---|---|---|---|---|
| 0 | 3 | 0 | 1 | 0 | 0 | 1 | 0 | 3 |
| 1 | 1 | 1 | 2 | 3 | 1 | 3 | 0 | 2 |
| 2 | 3 | 1 | 1 | 1 | 0 | 2 | 1 | 3 |
| 3 | 1 | 1 | 2 | 3 | 0 | 3 | 0 | 2 |
| 4 | 3 | 0 | 2 | 1 | 0 | 1 | 1 | 6 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 886 | 2 | 0 | 1 | 1 | 0 | 5 | 1 | 2 |
| 887 | 1 | 1 | 1 | 2 | 0 | 2 | 1 | 1 |
| 888 | 3 | 1 | 1 | 2 | 0 | 2 | 0 | 3 |
| 889 | 1 | 0 | 1 | 2 | 1 | 1 | 1 | 1 |
| 890 | 3 | 0 | 1 | 0 | 2 | 1 | 1 | 3 |
891 rows × 8 columns
邏輯回歸
邏輯回歸是一個非常經典的演算法,雖然被稱為回歸,但其實際上是一個分類模型,并常用于二分類,
優點:就是簡單、可并行化、可解釋強,
缺點:對于多重共線性很敏感,如果出現高相關的特征,需要使用因子分析、聚類分析等方法進行拆解降維,
log = LogisticRegression()
log.fit(X_train,Y_train)
Y_pre = log.predict(X_test)
acc_log = round(log.score(X_train, Y_train) * 100, 2)
acc_log
80.36
我們可以使用邏輯回歸來驗證我們之前創建的一些特征,這可以通過計算決策函式中特征的系數來實作,正系數增加回應的對數概率(從而增加概率),負系數降低回應的對數概率(從而降低概率),
- 性別是最高的正相關系數,隨著性別值的增加(男性:O到女性:1),存活的概率增加最多;
- 隨著Pclass(1為最高級,3為最低級)的增加,存活的概率降低最大;
- 因此年齡*等級是一個很好的人工特征來建模,因為它與存活的負相關系數是第二高;
- 頭銜是第二高的正相關系數,
pd.DataFrame(log.coef_)
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|
| 0 | -0.7507 | 2.201619 | 0.287011 | -0.086655 | 0.261473 | 0.397888 | 0.126553 | -0.311069 |
coeff_df = pd.DataFrame(train_df.columns.delete(0))
coeff_df.columns = ['Feature']
coeff_df["Correlation"] = pd.Series(log.coef_[0])
coeff_df.sort_values(by='Correlation', ascending=False)
| Feature | Correlation | |
|---|---|---|
| 1 | Sex | 2.201619 |
| 5 | Title | 0.397888 |
| 2 | Age | 0.287011 |
| 4 | Embarked | 0.261473 |
| 6 | IsAlone | 0.126553 |
| 3 | Fare | -0.086655 |
| 7 | Age*Class | -0.311069 |
| 0 | Pclass | -0.750700 |
SVM支持向量機
已監督學習方式對資料進行二元分類的廣義線性分類器,簡單來說就是進行一個二分類,求解最優的那個分類面,然后用這個最優解進行分類
優點:魯棒性強,對樣本要求不高,
缺點:SVM的超引數需要通過交叉驗證得到,非常耗費時間,而且SVM的核函式必須是正定的,計算量大,多分類很難使用,
#此處效果不是很好
svm = SVC()
svm.fit(X_train,Y_train)
Y_pred = svm.predict(X_test)
acc_svm = round(svm.score(X_train, Y_train) * 100, 2)
acc_svm
78.23
#線性SVM
linear_svc = LinearSVC()
linear_svc.fit(X_train, Y_train)
Y_pred = linear_svc.predict(X_test)
acc_linear_svc = round(linear_svc.score(X_train, Y_train) * 100, 2)
acc_linear_svc
79.12
KNN最近鄰
knn是測量不同特征值之間的距離來進行分類,類似于近朱者赤近墨者黑,往往通過輪廓系數、交叉檢驗來找最優解
優點:簡單易懂,
缺點:計算量大,對于不平衡樣本處理起來較困難,
# 一般使用knn 是需要將資料進行標準化,消除量綱的影響(SVM等 需要計算距離的模型一般都要進行去量綱的操作)
Knn = KNeighborsClassifier()
Knn.fit(X_train,Y_train)
Y_pred = Knn.predict(X_test)
acc_Knn = round(Knn.score(X_train, Y_train) * 100, 2)
acc_Knn
83.95
樸素貝葉斯分類器
貝葉斯模型非常特殊,是一個概率模型,通過事件屬性相關事件發生的概率(先驗概率)去推測該事件發生的概率,
優點:對缺失資料不太敏感,演算法也比較簡單,常用于文本分類、郵件分類等,
缺點:貝葉斯是一個理論上的模型,主要是因為貝葉斯首先是假設各特征之間是相互獨立,通常很難保證,還有先驗概率通常是假設出來,并不一定準確,
值得一提的是貝葉斯網路,也稱信念網路目前是最火熱的模型之一,畢竟“信貝爺, 得永生”
# Gaussian Naive Bayes
bys = GaussianNB()
bys.fit(X_train, Y_train)
Y_pred = bys.predict(X_test)
acc_gaussian = round(bys.score(X_train, Y_train) * 100, 2)
acc_gaussian
72.28
決策樹
決策樹(分類樹)是一種十分常用的分類方法,使用資訊熵增益、資訊熵增益率、Gini系數等進行剪枝尋求最優解
優點:可解釋性強、對樣本要求較低,
缺點:容易過擬合,尋求最優解往往會形成一個NP難(能在多項式時間內驗證得出一個正確解)問題,
decision_tree = DecisionTreeClassifier()
decision_tree.fit(X_train, Y_train)
Y_pred = decision_tree.predict(X_test)
acc_decision_tree = round(decision_tree.score(X_train, Y_train) * 100, 2)
acc_decision_tree
86.76
Random forest 隨機森林
隨機森林是一個包含多個決策樹的分類器, 并且其輸出的類別是由個別樹輸出的類別的眾數而定
優點:魯棒性好,既可以分類又可以回歸,準確度高,
缺點:黑盒模型、計算量大,
random_forest = RandomForestClassifier(n_estimators=100)
random_forest.fit(X_train, Y_train)
Y_pred = random_forest.predict(X_test)
random_forest.score(X_train, Y_train)
acc_random_forest = round(random_forest.score(X_train, Y_train) * 100, 2)
acc_random_forest
86.76
感知機
找一個超平面來分類
優點:簡單,
缺點:通常只能用來二分類問題,對于非線性問題效果差,
perceptron = Perceptron()
perceptron.fit(X_train, Y_train)
Y_pred = perceptron.predict(X_test)
acc_perceptron = round(perceptron.score(X_train, Y_train) * 100, 2)
acc_perceptron
78.34
人工神經網路
人工神經網路就是模擬人思維的第二種方式,這是一個非線性動力學系統,其特色在于資訊的分布式存盤和并行協同處理,
優點:準,
缺點:黑盒模型、計算要求高,有時候可能比挖位元幣更復雜,有時間跑神經網路我為什么不用來挖位元幣呢,
ann = MLPClassifier()
ann.fit(X_train, Y_train)
Y_pred = lf.predict(X_test)
acc_ann = round(ann.score(X_train, Y_train) * 100, 2)
acc_ann
83.5
模型對比
對所有模型進行對比,選出最好的模型
# Random Forest和Decision Tree 評分相同 但是隨機森林沒有過擬合的問題,所以選擇隨機森林
models = pd.DataFrame({
'Model': ['Support Vector Machines', 'KNN', 'Logistic Regression',
'Random Forest', 'Naive Bayes', 'Perceptron',
'Artificial Neural Networks', 'Linear SVC',
'Decision Tree'],
'Score': [acc_svm, acc_Knn, acc_log,
acc_random_forest, acc_gaussian, acc_perceptron,
acc_ann, acc_linear_svc, acc_decision_tree]})
models.sort_values(by='Score', ascending=False)
| Model | Score | |
|---|---|---|
| 3 | Random Forest | 86.76 |
| 8 | Decision Tree | 86.76 |
| 1 | KNN | 83.95 |
| 6 | Artificial Neural Networks | 83.50 |
| 2 | Logistic Regression | 80.36 |
| 7 | Linear SVC | 79.12 |
| 5 | Perceptron | 78.34 |
| 0 | Support Vector Machines | 78.23 |
| 4 | Naive Bayes | 72.28 |
random_forest = RandomForestClassifier(n_estimators=100)
random_forest.fit(X_train, Y_train)
Y_pred = random_forest.predict(X_test)
X_test['Survived']=Y_pred
如果你懂了 你應該知道你能不能活下來(老凡爾賽了)
X_test[X_test['Survived']==1]
| Pclass | Sex | Age | Fare | Embarked | Title | IsAlone | Age*Class | Survived | |
|---|---|---|---|---|---|---|---|---|---|
| 4 | 3 | 1 | 1 | 1 | 0 | 3 | 0 | 3 | 1 |
| 6 | 3 | 1 | 1 | 0 | 2 | 2 | 1 | 3 | 1 |
| 8 | 3 | 1 | 1 | 0 | 1 | 3 | 1 | 3 | 1 |
| 11 | 1 | 0 | 2 | 2 | 0 | 1 | 1 | 2 | 1 |
| 12 | 1 | 1 | 1 | 3 | 0 | 3 | 0 | 1 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 410 | 3 | 1 | 1 | 0 | 2 | 2 | 1 | 3 | 1 |
| 411 | 1 | 1 | 2 | 3 | 2 | 3 | 0 | 2 | 1 |
| 412 | 3 | 1 | 1 | 0 | 0 | 2 | 1 | 3 | 1 |
| 414 | 1 | 1 | 2 | 3 | 1 | 5 | 1 | 2 | 1 |
| 417 | 3 | 0 | 1 | 2 | 1 | 4 | 0 | 3 | 1 |
152 rows × 9 columns
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/265342.html
標籤:AI
下一篇:PyTorch 神經網路氣溫預測