函式說明
- rank() 排序相同時會重復,總數不會變
- dense_rank() 排序相同時會重復,總數會減少
- row_number() 會根據順序計算
這三個函式很經常使用,也很經常被混淆,在面試中也是常常被提及,下面提供一個案例來幫助理解,以及最后用一點小思維幫助大家記憶區分,

案例:
1)資料準備
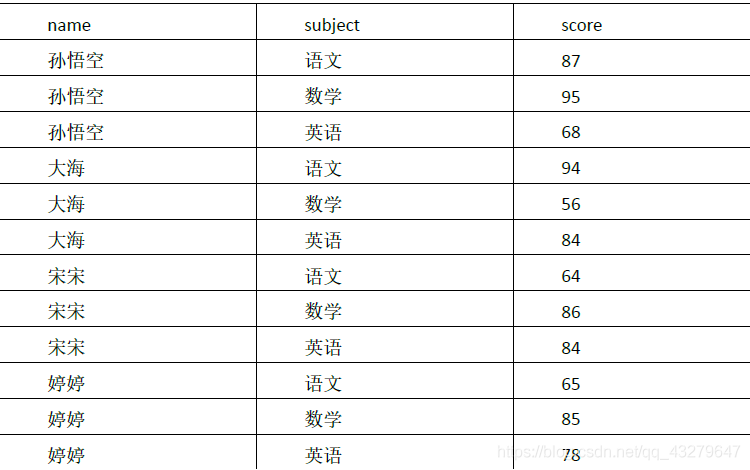
2)需求
計算每門學科成績排名,
3)創建本地score.txt,匯入資料
[ysh@hadoop102 datas]$ vi score.txt
4)創建hive表并匯入資料
create table score(
name string,
subject string,
score int)
row format delimited fields terminated by "\t";
load data local inpath '/opt/module/datas/score.txt' into table score;
5)按需求查詢資料
select name,
subject,
score,
rank() over(partition by subject order by score desc) rp,
dense_rank() over(partition by subject order by score desc) drp,
row_number() over(partition by subject order by score desc) rmp
from score;
6)結果展示
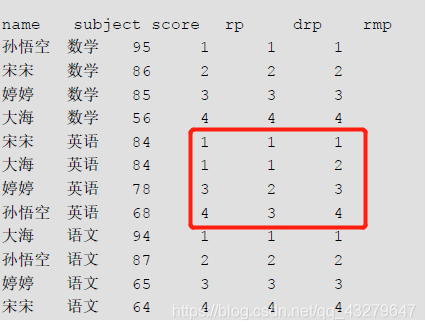
可以這么理解:
- rank(),是有間隔的排名,有并列排名的時候,下一個排名會間隔(并列數-1)個數
- dense_rank(),dense(密集的),有并列排名的時候下一個排名緊接上一個并列的排名
- row_number(),可以理解為行的序號,不考慮并列排名(因為沒有rank)
記憶:“沒有rank按順序,只有rank有間隔,dense是密集的”

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/265363.html
標籤:其他
上一篇:快速了解odp