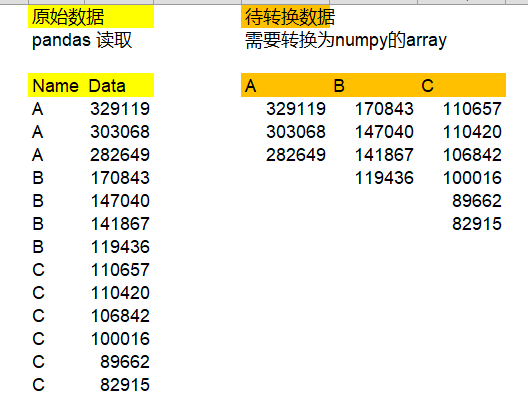
如何實作從左邊轉換為右邊的numpy 陣列格式呢:
注:ABC僅為舉例使用,實際情況可能會有未知數量的多個標簽
uj5u.com熱心網友回復:
資料能用代碼形式發出來嗎?打數字也得會兒功夫uj5u.com熱心網友回復:
資料是隨便生成的,能轉換就好
uj5u.com熱心網友回復:
資料是隨便生成的,能轉換就好
uj5u.com熱心網友回復:
資料是隨便生成的,能轉換就好
uj5u.com熱心網友回復:
import pandas as pd
import numpy as np
import pandas.io.formats.excel # 設定格式用
import xlsxwriter # 設定格式用,pip install xlsxwriter
chengji = [["a", 95, 100, 99], ["a", 98, 99, 100], ["a", 95, 98, 88],
["b", 98, 97, 87], ["b", 90, 96, 85], ["b", 94, 93, 91], ["a", 99, 93, 91]]
data = pd.DataFrame(chengji, columns=['類別', "語文", '數學', '政治'])
print(data.index, data.columns) # 豎序列,橫標題
print("*"*50, "原始資料")
print(data)
data1=data.set_index('類別')
print(data1)
# data1 = data.groupby('類別') # 單一分組,可用([..],[...])多列分組
# data2 = data1['語文'].agg([np.sum, np.mean])
# print("*"*50, "用分類后語文,NP求和,平均值")
# print(data2)
lb=set(data['類別'].tolist())
print(lb)
data2=pd.DataFrame()
for lbx in lb:
nr=data1[data1.index==lbx]["語文"].tolist()
for num,nrx in enumerate(nr):
data2.loc[num,lbx]=nrx
print(data2)
uj5u.com熱心網友回復:
import pandas as pd
data = [['A', 329119], ['A', 303068], ['A', 282649], ['B', 170843], ['B', 147040],['B', 141867],['B', 119436], ['C', 110657], ['C', 106842], ['C', 100016], ['C', 106842], ['C', 89662]]
df = pd.DataFrame(data = data, columns=['Name', 'Data'])
b = df['Name'].unique()
d = {}
for i in range(0, len(b)):
d[b[i]] = df.loc[df.Name==b[i], 'Data'].reset_index(drop=True)
result = pd.DataFrame(d, columns=b)
print(result)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/26549.html