目錄
Spark
Spark的特點?
Spark具備的能力
spark與Hadoop的異同?
Spark的應用場景
Spark的生態系統
spark的構架和原理
spark架構設計
spark的作業流程
核心原理
每文一語
Spark
Spark的特點?
Spark首先是一個大規模資料處理的統一分析引擎,它是類與Hadoop MapReduce的通用并行框架,專門為大資料處理的一個快速計算引擎,如果說Hadoop是大資料的第一把利劍,那么毫無疑問spark就是大資料分析與計算的第二把利劍,spark具有下面四個特點:
快速: 在相同的實驗環境下處理相同的資料,若在記憶體中運行,那么Spark要比MapReduce快100倍(只是在邏輯回歸測驗中),
通用:Spark 是一個通用引擎,可用它來完成各種運算,包括 SQL 查詢、文本處理、機器學習、實時流處理等,我們之前花費大量的時間去學習SQL的規范與語法,就是為了在后面有更好的突破和發展,
易用:Spark提供了高級 API,應用開發者只用專注于應用計算本身即可,而不用關注集群本身,這使得Spark更簡單易用,至于提供了高級的API,那么我們知道Python是一個膠水語言,一般在智能的分析里面我們還是要利用Python的特性,提供pyspark這個模塊進行我們更加快速方便的操作,
兼容性好:Spark可以非常方便地與其他的開源產品進行融合,比如,Spark可以使用Hadoop的YARN和Apache Mesos作為它的資源管理和調度器,并且可以處理所有Hadoop支持的資料,包括HDFS、HBase和Cassandra等,
Spark具備的能力
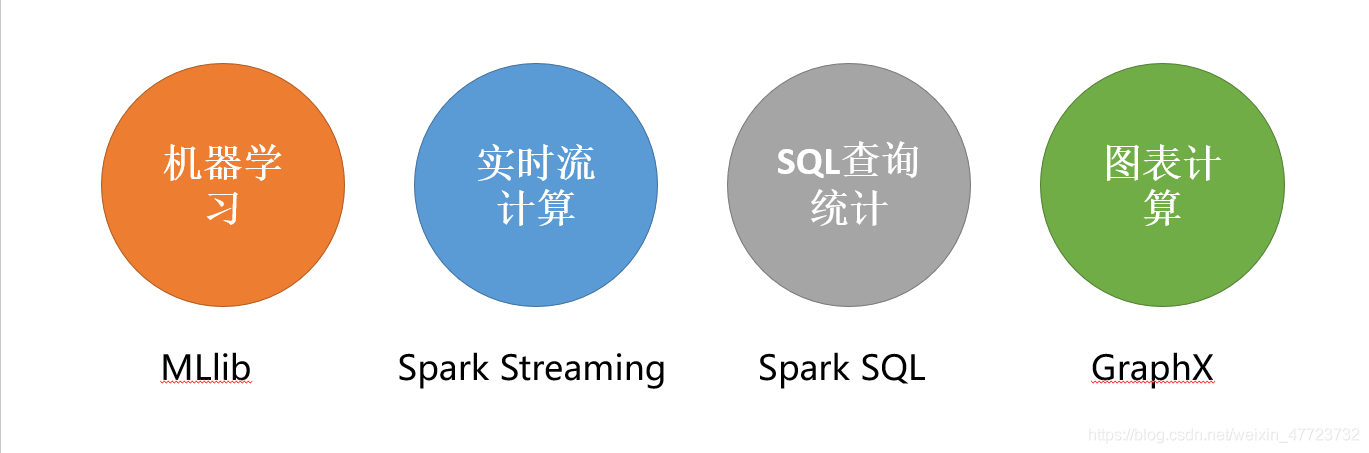
說實話spark在這些領域能夠具有不一般的地位,在于時代的需要和發展,任何一個產品如果不適應時代的需要,那么即使它擁有非常好的資源也終究會時間淘汰,
spark與Hadoop的異同?
我們都知道Hadoop,之前我們也介紹了在Hadoop里面處理大量的資料進行分析,Hadoop也可以,那么spark和Hadoop究竟有些什么不一樣呢?
1.首先解決問題方式不一樣
首先,Hadoop和Apache Spark兩者都是大資料框架,但是各自的屬性和性能卻不完全相同,Hadoop實質上更多是一個分布式資料基礎設施,它將巨大的資料集分派到一個由普通計算機組成的集群中的多個節點進行存盤,意味著我們不需要購買和維護昂貴的服務器硬體,同時,Hadoop還會排序和追蹤這些資料,這使得大資料處理和分析效率更加迅速,在之前我們的Hadoop的實驗里面我們也發現這個問題,但是處理速度,確實有點不盡人意,每次執行查詢的時候都進行MapReduce的過濾和分析,時間上還是浪費了許多,
Spark則是一個專門的,用來對那些分布式存盤的大資料進行處理的工具,但它并不會進行分布式資料的存盤,
2.Hadoop與spark可謂珠聯璧合
Hadoop不僅提供了從前的 HDFS分布式資料存盤功能之外,而且提供了叫做MapReduce的資料處理的功能,所以我們可以不使用Spark,而選擇使用Hadoop自身的MapReduce來對資料進行處理,這個當然是可以的,但是我們了解了spark之后就會選擇在不同的場景下進行不同的選擇和應用,不然也沒有必要的去了解這個產品,
同樣的,Spark也不一定需要依附在Hadoop系統中,但如上所述,畢竟它沒有提供檔案管理系統,所以,它需要和其他的分布式檔案系統先進行集成然后運作,這里我們可以選擇一些基于云的資料系統平臺進行操作,
3.spark某些方面比Hadoop更勝一籌
①它可以把中間結果放在記憶體!Hadoop卻不能,這就是Hadoop執行每次任務較慢的重要原因之一:基于MapReduce的計算模型會將中間結果序列化到磁盤上,而Spark將執行模型抽象為通用的有向無環圖執行計劃,且可以將中間結果快取記憶體中,
②自動布局和資料格式轉換:Spark抽象出分布式記憶體存盤結構,即彈性分布式資料集RDD(Resilient Distributed Datasets)進行資料存盤,Spark能夠控制資料在不同節點上的磁區,用戶可以自定義磁區策略,
③執行策略高:MapReduce在資料shuffle之前總是花費大量時間來排序,Spark支持基于Hash的分布式聚合,在需要的時候再進行實際排序,
④任務調度可以減少:MapReduce上的不同作業在同一個節點運行時,會各自啟動一個JVM,而Spark同一節點的所有任務都可以在一個JVM上運行,
其實我們也不能光否定Hadoop,一味地去夸spark,Hadoop也是基于記憶體計算,Spark只是把計算程序中間的結果快取在記憶體中,Spark只是在邏輯回歸測驗時候速度比Hadoop快了100倍,其他演算法不一定,這個是需要我們注意的,并不是所有的演算法都是這樣,
Spark的應用場景
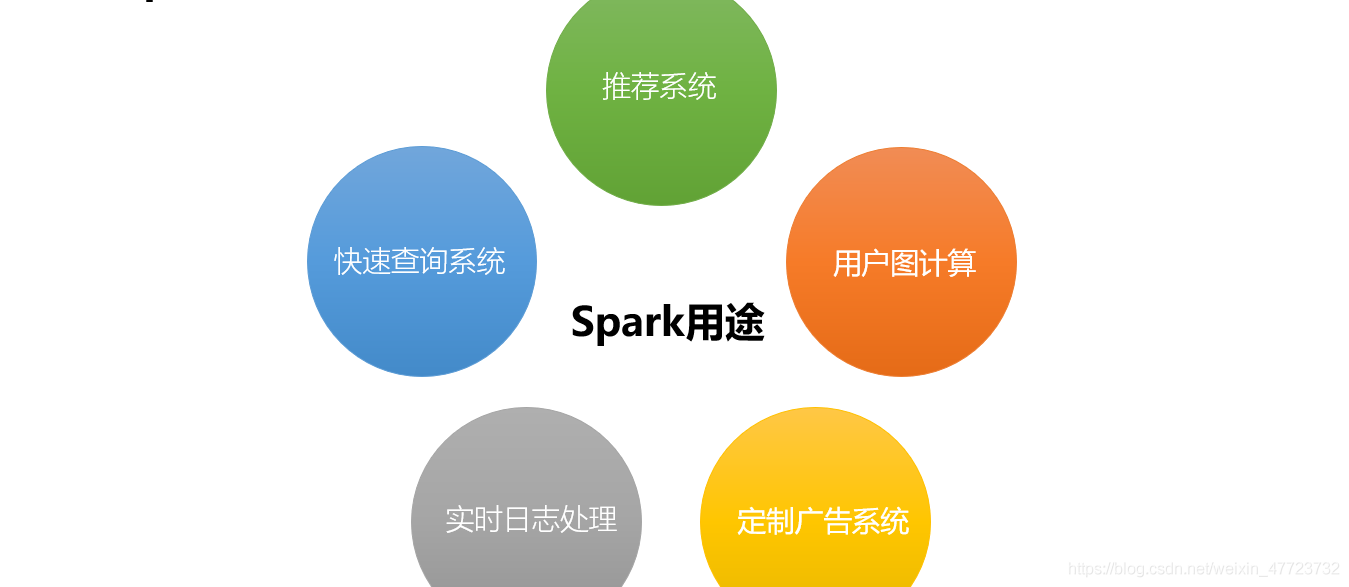
Spark使用了記憶體分布式資料集,除了能夠提供互動式查詢外,它還提升了迭代作業負載的功能,在Spark SQL、Spark Streaming、MLlib、GraphX中都有自己一定的子專案,在互聯網領域,Spark有快速查詢、實時日志采集處理、業務推薦、定制廣告、用戶圖計算等強大功能,國內外的一些大公司,比如Google、阿里巴巴、Intel、網易、科大訊飛等都有實際業務運行在Spark平臺上,下面簡要說明Spark在各個領域中的用途,

Spark的生態系統
我們都知道一個技術產品的生態系統的好壞決定了這個技術產品未來的走勢和發展,那么spark的生態系統是怎么樣的?下面我們就來看看
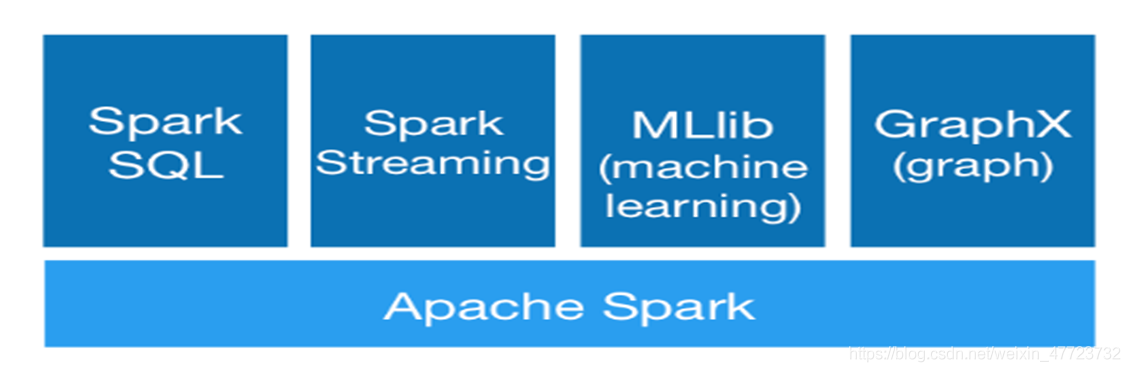
Spark 生態系統以Spark Core 為核心,利用Standalone、YARN 和Mesos 等資源調度管理,完成應用程式分析與處理,這些應用程式來自Spark 的不同組件,如Spark Shell 或Spark Submit 互動式批處理方式、Spark Streaming 的實時流處理應用、Spark SQL 的即席查詢、MLlib 的機器學習、GraphX 的圖處理等,
spark的構架和原理
spark架構設計
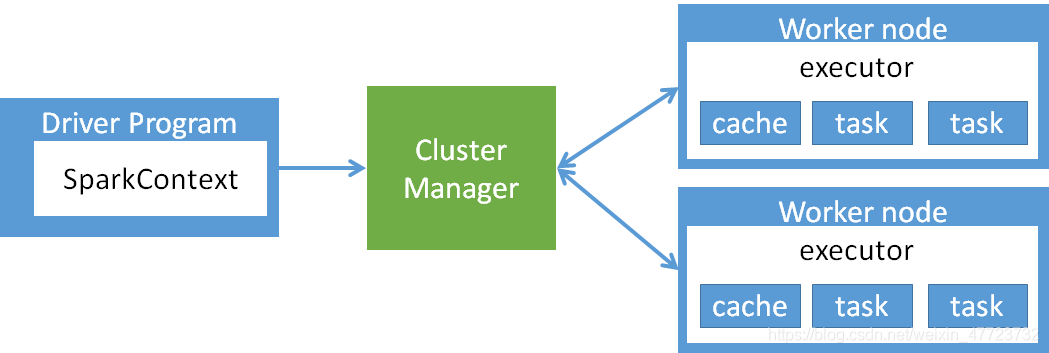
(1)Cluster Manager:Spark的集群管理器,主要負責資源的分配與管理,集群管理器分配的資源屬于一級分配,它將各個Worker上的記憶體、CPU等資源分配給應用程式,但是并不分配Executor的資源,目前,Standalone、YARN、Mesos、EC2等都可以作為Spark的集群管理器,
(2)Worker:Spark的作業節點,對Spark應用程式來說,由集群管理器分配得到資源的Worker節點主要負責以下作業:創建Executor,將資源和任務進一步分配給Executor,然后同步資源資訊給Cluster Manager,
(3)Executor:執行計算任務的一線行程,主要負責任務的執行以及與Worker、Driver App的資訊同步,
(4)Driver Program:客戶端驅動程式,也可以理解為客戶端應用程式,用于將任務程式轉換為RDD和DAG,并與Cluster Manager進行通信與調度,
其實說了這么多可能你還是不夠了解這個,但是我們再來看看這個你就看明白了
Master行程和Worker行程,對整個集群進行控制,
Driver 程式是應用邏輯執行的起點,負責作業的調度,即Task任務的分發
Worker用來管理計算節點和創建Executor并行處理任務,
Executor對相應資料磁區的任務進行處理,
spark的作業流程
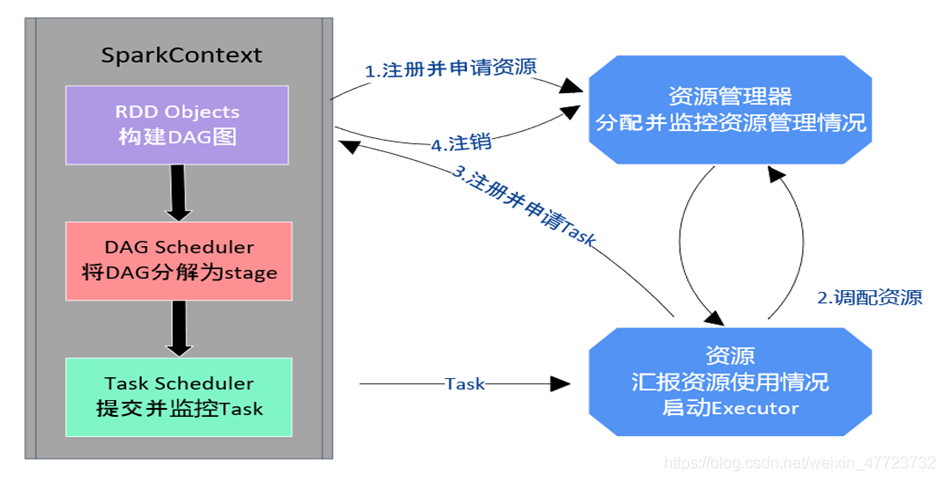
(1)構建Spark Application的運行環境,啟動SparkContext,
(2)SparkContext向資源管理器(可以是Standalone,Mesos,Yarn)申 請運行Executor資源,
(3)Executor向SparkContext申請Task,
(4)SparkContext將應用程式分發給Executor,
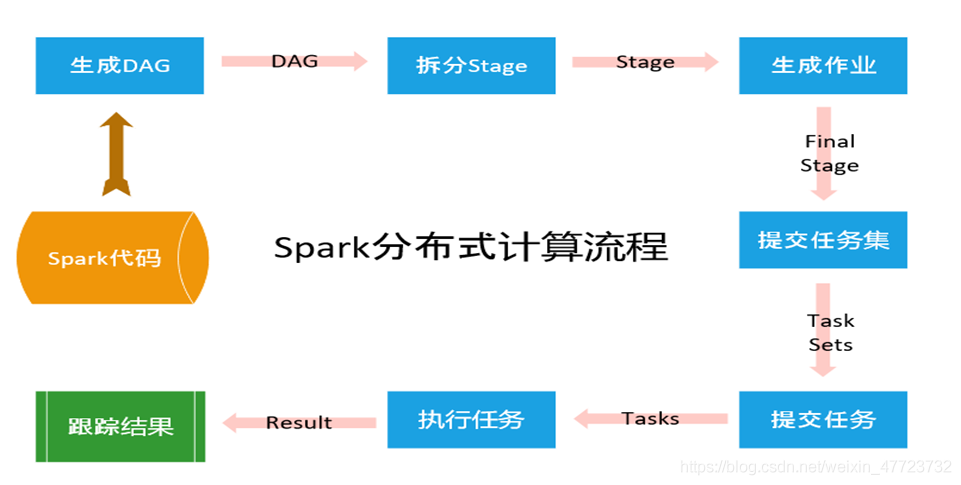
(5)SparkContext構 建成DAG圖( Directed Acyclic Graph有向無環圖),將DAG圖分解成Stage、將Taskset發送給Task Scheduler,最后由Task Scheduler將Task發送給Executor運行,
(6)Task在Executor上運行,運行完釋放所有資源,
核心原理
還是那句話工欲善其事必先利其器,本專欄使用的是spark2.X版本的,具有很好地效果
每文一語
底線,是有所為有所不為!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/265878.html
標籤:其他
下一篇:四十四、Kafka的架構