先說結果
筆者今年大二,參加了上屆的泰迪杯資料挖掘技能賽,也是大學第一次參加比賽,最后結果是A題未獲獎,B題一等獎,下面來簡單介紹一下我們的參加經歷,講講比賽總結,
隊員配置
兩人大二、一人大一,專業是自動化/機械,
不過這并不意味著什么專業都可以參賽,我們三人都有python的基礎,顯然參賽前需要預先學習和準備相關編程知識,也要有對資料挖掘和資料處理有一定的概念,
學習&準備程序
第一次嘗試做泰迪杯真題是10月初,當時在做18年的B題,筆者一口氣做了七天,一個人每天兩三小時做完了,我覺得第一次的實戰經驗是很重要的,比賽的準備可以從實戰先開始,當然,當時對資料分析、資料挖掘一竅不通,可以說是走了很多彎路,很多部分都是面向CSDN編程,其中有個雷坑就建議大家不要走了,當時代碼大量學習了 @蘑菇果實使用者=w= 的博客,結果可以說是走了很多彎路,,,
十月末和十一月初就和隊友們經常來實驗室一起敲代碼、做真題、總結套路,最后一周做了19年的兩道題,其中大量學習和運用了numpy、pandas、matplotlib的用法和套路,可以說是非常重要,
比如以下部分:
#2018Btask1_2
SaleList = [line.rstrip('\n').split(',') for line in open('result\\'+file,'r')]
TimeList = [line[5].replace('/',' ').split(' ') for line in SaleList]
#代碼來自 @蘑菇果實使用者=w=
很復雜的代碼,因為題目給的csv檔案,樸素做法的確是需要類似 line.rstrip(’\n’).split(’,’) 這樣的部分,但是當你學會pandas后,就根本不需要這樣處理了:
#2019Atask1_3 統計每個中類商品的促銷銷售金額和非促銷銷售金額,將結果保 存為“task1_3.csv”
import pandas as pd
def task1_3():
data = pd.read_csv('data.csv')
data_yes = data[data['是否促銷'] == '是']
data_no = data[data['是否促銷'] == '否']
data_task1_3_yes = pd.pivot_table(data_yes, index = ['中類名稱'], values = ['銷售金額'], aggfunc = 'sum')
data_task1_3_no = pd.pivot_table(data_no, index = ['中類名稱'], values = ['銷售金額'], aggfunc = 'sum')
data_task1_3 = pd.DataFrame({'促銷銷售金額': data_task1_3_yes.iloc[:, 0], '非促銷銷售金額': data_task1_3_no.iloc[:, 0]})
data_task1_3.to_csv('task1_3.csv', encoding = 'utf_8_sig')
其中pandas庫提供的資料結構Dataframe非常適合存盤二維資料,對資料進行操作也非常快捷和方便,通過 pandas.read_csv() 方法可以直接把csv讀取,也不再需要使用 .split(’.’) 這樣的笨方法,所以非常推薦大家去學習numpy&pandas的用法及其提供的資料結構,
再者就是資料可視化,一般采用matplotlib或seaborn這兩個庫之一,這里以matplotlib為例,筆者自己總結的繪制折線圖固定代碼模板,這樣在比賽遇到相關題目時可以直接復制大段代碼,然后簡單處理題目資料并套用即可,

因此筆者嘗試根據自己經驗總結一下參賽的學習計劃該怎么規劃:
- 學習至少一門資料科學語言,這里推薦python,如果完全沒有編程基礎,至少需要兩周以上時間熟悉python語法和簡單的資料結構如list、dictionary等,
- 嘗試做一下真題,熟悉一下題目型別和題目難度,可以嘗試一個人完成真題的task1和task2,由于task3較為開放性,有一定數學建模的意味,可以暫時不管,
- 學習第三方庫numpy、pandas、matplotlib,總結套路,我們在集中刷題時發現題目在task1、task2很多題型都大同小異,可以用一些固定套路解決,對于這些固定套路最好就是要熟記其函式和方法,比如 pd.pivot_table() 方法等,
- 刷往年真題,值得一提,程序3可以在刷真題中一并學習,
參賽程序
參賽程序可謂稍有曲折,比賽要求是A、B題各一天,每天12小時,要求最后提交代碼和論文,其中論文并沒有嚴格要求格式,如果能規范正規論文格式當然更好,
A題題目出來后,我們三個人立刻開始分工,一人做task1,兩人做task2,當時我們預計的資料預處理和簡單資料挖掘部分大概在上午12點之前可以全部完成,實際上卻有不同程度的麻煩發生,資料預處理倒是很順利,A同學很快就完成了;但是task2的任務復雜度超出了我的想象,事實上我花了將近7小時在其中一道題上,最后還是做錯了,代碼的時間復雜度極高,加上題目給的資料基本都是幾十萬行的,樸素硬解猶如煉丹,出一張圖要等幾十分鐘,最后思路還是錯的,

(一定要多審題,劃重點)
總結來說,當一道題完全做不動時,要主動尋求隊友的幫助,可以互相換換題做,多討論,不要死磕,
A題做完的時候三個人已經很累了,晚上九點多出學校吃夜宵,因為六七點是緊張的趕deadline和趕論文時間,根本顧不上晚飯,當時我們三個人普遍對今天不太滿意,但是又累到不想再打一天,最后達成共識:早上八點來實驗室看下題目難度,如果題目比較常規且好做就肝,如果是怪題就直接下班,
幸運的是我們選擇了堅持,第二天來的時候大家重新充滿了精力,二話不說開始干B題,B題中意外的出現了“數字大屏”這一從來沒了解過的資料可視化呈現方式,這一部分通過討論后,我們決定采取了分別制圖后用photoshop制圖的方式(筆者熟練掌握ps,所以多一項技能一定是好事~),最后的task3部分,我們采用的思路是用sklearn庫里的KMeans演算法,這里也推薦大家至少一人要去了解一下簡單的機器學習演算法和數學建模方法,免得task3無從下手,
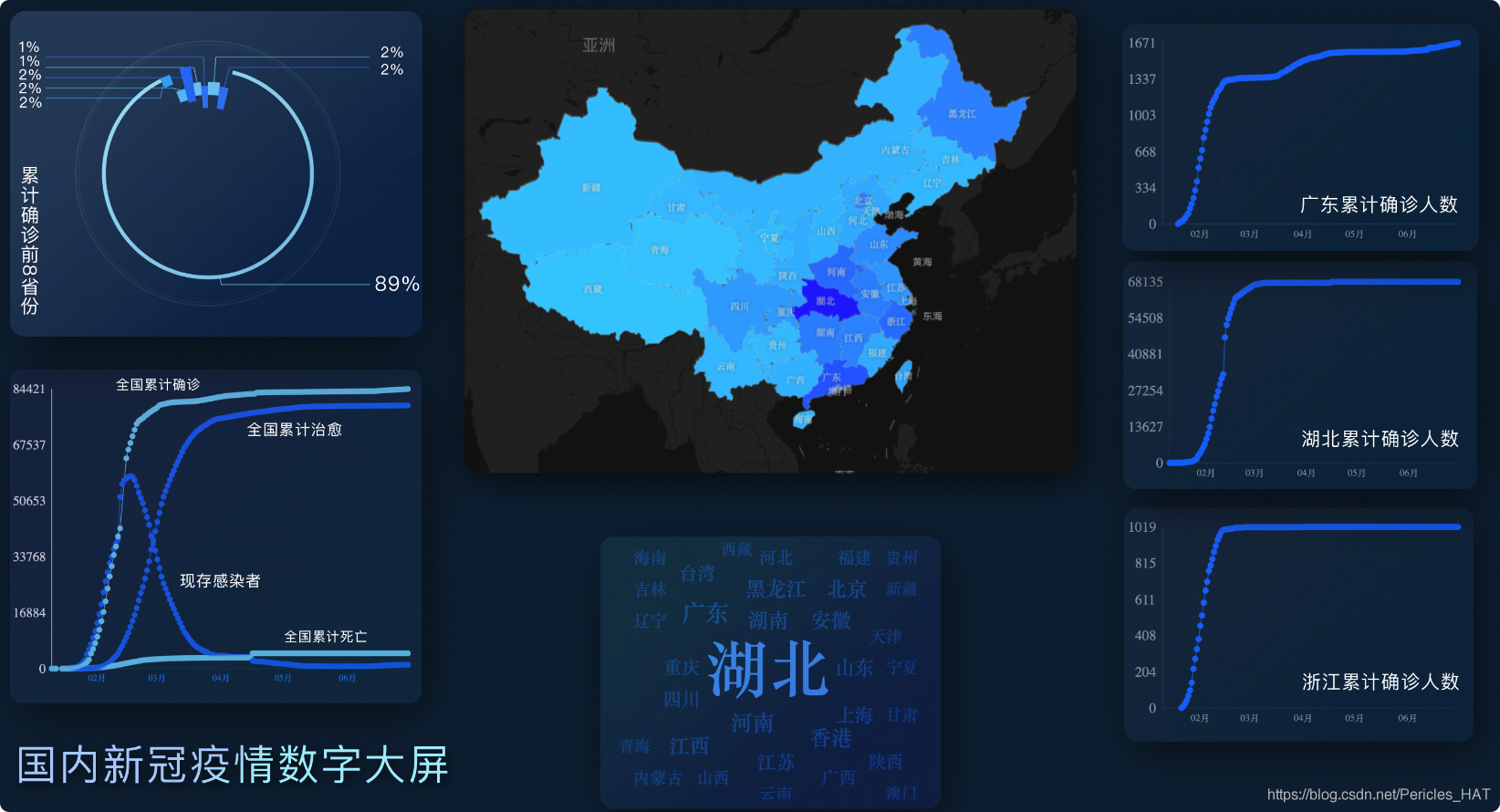
總結
- 學習資料科學的相關編程方法、總結套路
- 記得需要資料預處理,篩掉無用資料和錯誤資料
- 制作更精美的資料可視化圖可能比文字說明更有用
- 要會用excel的透視表,把握資料
- 不要用樸素做法強解,往往時間復雜度極高
- 如果是cs專業的學生,將C的資料結構相關知識應用在python上可以極大程度避免不必要的資料錯誤
- 多看看網上的教程博客怎么處理有時間要求的相關資料,比如題目要求某幾個月某幾天的資料,我們花了很多時間學習這一部分
- 熟練掌握debug方法
- 貴在堅持,做完A、B題
希望這篇博客對你有幫助,加油!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/265883.html
標籤:其他
上一篇:shell腳本詳解(一)——Shell編程規范與變數
下一篇:Jenkins最簡單的安裝方法