普通快速排序的缺陷
普通快速排序源代碼
template<typename T>
void quickSort(T* arr, int size) {
if (size == 0)return;
int front = 0, rear = size - 1;
T pivot = arr[0];
while (front < rear) {
while (front < rear && arr[rear] >= pivot) { --rear; }
arr[front] = arr[rear];
while (front < rear && arr[front] <= pivot) { ++front; }
arr[rear] = arr[front];
}
arr[front] = pivot;
quickSort(arr, front);
quickSort(arr + front + 1, size - 1 - front);
}
我們輸入一個完全倒序的陣列,測驗一下
int main() {
constexpr int size = 10000;
int* nums = new int[size]{0};
// 完全倒序的一個陣列
for (int i = 0; i < size; ++i) {
nums[i] = size - i;
}
quickSort(nums, size);
delete[] nums;
return 0;
}
對 10000 個完全倒序的數進行排序并計一下時,可以發現快速排序是非常慢的!因為此時快速排序已經退化成了冒泡排序!
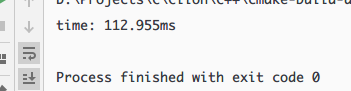
同時如果輸入的陣列中的資料完全相同,那么普通的快速排序會產生不必要的劃分和遞回,既浪費時間又浪費空間
快速排序的優化
優化 pivot 的選取
1.隨機選取中軸
template<typename T>
void quickSort(T* arr, int size) {
if (size == 0)return;
int front = 0, rear = size - 1;
// 在arr中隨機選一個數,然后和arr[0]交換一下
swap(arr[0], arr[rand() % size]);
T pivot = arr[0];
while (front < rear) {
while (front < rear && arr[rear] >= pivot) { --rear; }
arr[front] = arr[rear];
while (front < rear && arr[front] <= pivot) { ++front; }
arr[rear] = arr[front];
}
arr[front] = pivot;
quickSort(arr, front);
quickSort(arr + front + 1, size - 1 - front);
}
重新對 10000 完全倒序的數進行排序,可以發現速度大幅度提升
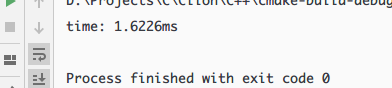
2.三數取中
template<typename T>
void quickSort(T* arr, int size) {
if (size == 0)return;
int front = 0, rear = size - 1, mid = rear / 2;
// 把arr[0],arr[mid],arr[rear]的中位數與arr[0]調換位置
if (arr[mid] > arr[rear]) {
swap(arr[mid], arr[rear]);
}
if (arr[front] > arr[rear]) {
swap(arr[front], arr[rear]);
}
if (arr[mid] > arr[front]) {
swap(arr[mid], arr[front]);
}
T pivot = arr[0];
while (front < rear) {
while (front < rear && arr[rear] >= pivot) { --rear; }
arr[front] = arr[rear];
while (front < rear && arr[front] <= pivot) { ++front; }
arr[rear] = arr[front];
}
arr[front] = pivot;
quickSort(arr, front);
quickSort(arr + front + 1, size - 1 - front);
}
對演算法的優化
1. 在資料量小的時候使用插入排序
我們只需要把
if (size == 0) return;
改為
if (size <= 10) {
// do insertSort ...
return;
}
即可!
2. 把與 pivot 相同的資料盡可能的聚集到中軸附近
先來看一組數,這是經過一次劃分之后的陣列,其中粗體的 5 是這個陣列的中軸,左邊的數全部<=5,右邊的數全部>=5
1 5 3 2 4 5 6 5 7 5 9
此時我們需要對 1 5 3 2 4 和 6 5 7 5 9 進行快速排序
如果我們把陣列中所有的 5 全部向中軸聚集,我們會得到這樣一個陣列
1 4 3 2 5 5 5 5 7 6 9
這樣我們只需對 1 4 3 2 和 7 6 9 進行快速排序就可以了,效率得到提高
template<typename T>
void quickSort(T* arr, int size) {
if (size == 0)return;
int front = 0, rear = size - 1;
T pivot = arr[0];
while (front < rear) {
while (front < rear && arr[rear] >= pivot) { --rear; }
arr[front] = arr[rear];
while (front < rear && arr[front] <= pivot) { ++front; }
arr[rear] = arr[front];
}
arr[front] = pivot;
// 向中間聚集
int left = front - 1, right = front + 1;
for (int i = left; i >= 0; i--) {
if (arr[i] == pivot) {
swap(arr[i], arr[left]);
--left;
}
}
for (int i = right; i < size; i++) {
if (arr[i] == pivot) {
swap(arr[i], arr[right]);
++right;
}
}
quickSort(arr, left + 1);
quickSort(arr + right, size - right);
}
最終版本
template<typename T>
void quickSort(T* const arr, const size_t size) {
if (size <= 10) {
// lambda實作直接插入排序
([arr, size]() -> void {
int i, j;
T temp;
for (i = 1; i < size; ++i) {
temp = arr[i];
for (j = i - 1; j >= 0 && arr[j] > temp; --j) {
arr[j + 1] = arr[j];
}
arr[j + 1] = temp;
}
})();
return;
}
int front = 0, rear = size - 1, mid = rear / 2;
if (arr[mid] > arr[rear]) {
swap(arr[mid], arr[rear]);
}
if (arr[front] > arr[rear]) {
swap(arr[front], arr[rear]);
}
if (arr[mid] > arr[front]) {
swap(arr[mid], arr[front]);
}
T pivot = arr[0];
while (front < rear) {
while (front < rear && arr[rear] >= pivot) {
--rear;
}
arr[front] = arr[rear];
while (front < rear && arr[front] <= pivot) {
++front;
}
arr[rear] = arr[front];
}
arr[front] = pivot;
int left = front - 1, right = front + 1;
for (int i = left; i >= 0; i--) {
if (arr[i] == pivot) {
swap(arr[i], arr[left]);
--left;
}
}
for (int i = right; i < size; i++) {
if (arr[i] == pivot) {
swap(arr[i], arr[right]);
++right;
}
}
quickSort(arr, left + 1);
quickSort(arr + right, size - right);
}
對 n 個亂數排序耗時如下:
普通快速排序耗時
| 資料量 | 10^4 | 10^5 | 10^6 | 10^7 |
|---|---|---|---|---|
| 耗時/ms | 0.8397 | 10.713 | 133.032 | 3680.29 |
優化后的快速排序耗時
| 資料量 | 10^4 | 10^5 | 10^6 | 10^7 |
|---|---|---|---|---|
| 耗時/ms | 1.0617 | 13.1352 | 132.874 | 1340.78 |
其他
單軸快速排序還可以繼續優化,例如可以把尾遞回改為回圈實作,使用多執行緒加快排序速度
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/266003.html
標籤:其他
上一篇:ESP8266連接ONENET