文章目錄
- 思考
- 優化
- 轉存資訊
- 資料轉換
- LSTM
智能車AI電磁部署學習 (一)
思考
AI組本意是通過短前瞻短資料集去長前瞻的打腳值,來使得智能車通過短前瞻獲得與長前瞻一致的速度,
相對于短前瞻,長前瞻的資訊相對更加豐富、準確,短前瞻甚至會喪失一部分關鍵資訊,經過了解、學習LSTM后,并與隊友討論,認為輸入不僅要只有電感值,可以嘗試輸入一些前次或前前次的舵機打腳值與某些主要電感數值,來使得系統更加穩定,且與時間有關,前后聯系更加緊密,因為電磁變化是個連續程序,相鄰兩次的數值是有關聯的,而此關聯與轉角值恰好是有某種非線性函式關系,
優化
資料都是單片機采集存盤的,需要把資料整理、發送到PC端并轉換成一個訓練集、測驗集,這里假定智能車采用無線透傳串口模塊或是SD卡FatFS檔案系統存盤采集資料,
本著在家要摸魚的原則,優化了這一流程,更加方便實作訓練流程,減少時間開銷,撰寫了一個txt轉py陣列,且隨機打亂自動分配訓練、測驗集的腳本,
可以讀取相應格式的txt文本,轉換成對應X Y矩陣,自定義設定訓練集比例,可直接傳入神經網路,
轉存資訊
首先規定通信格式,
在檢測到begin關鍵字后開始進行資料轉換,一行資料的前N-1項是神經網路的輸入,最后的一個引數為訓練的結果值,例如100,100,0,其中100 100為2輸入神經網路的X值,0 為Y值(這里我用的是Softmax分類,通過數字轉換成獨熱碼,真正的多輸出還需改寫腳本,舵機打腳值一個資料位即可),
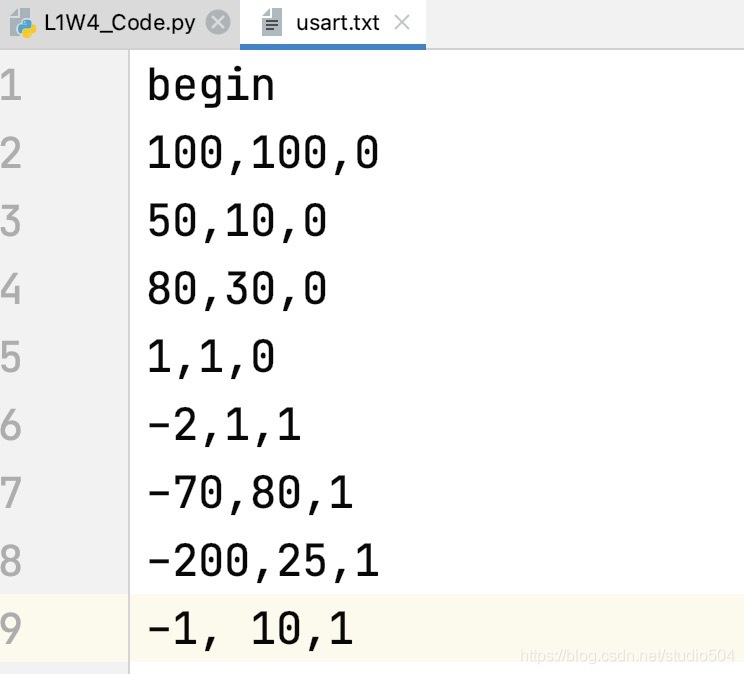
資料轉換
通過讀取txt內的資料并將其轉換為train_x,train_y,test_x,test_y,四個矩陣,
train_x_org, train_y_org = readtxt_make_arr("usart.txt", "begin")
train_x_y_org = np.c_[train_x_org, train_y_org] # 合并矩陣 為了保證打亂順序后其x y值仍然相互對應
train_x_y, test_x_y = split_train(train_x_y_org, 0.2)
train_x, train_y = np.split(train_x_y, [-1], axis=1) # 分割陣列最后一列做為y
test_x, test_y = np.split(test_x_y, [-1], axis=1)
np.split(train_x_y, [-1], axis=1) # axis = 1對列操作
讀取后,可以看到x_org與y_org的大小與輸入一致,
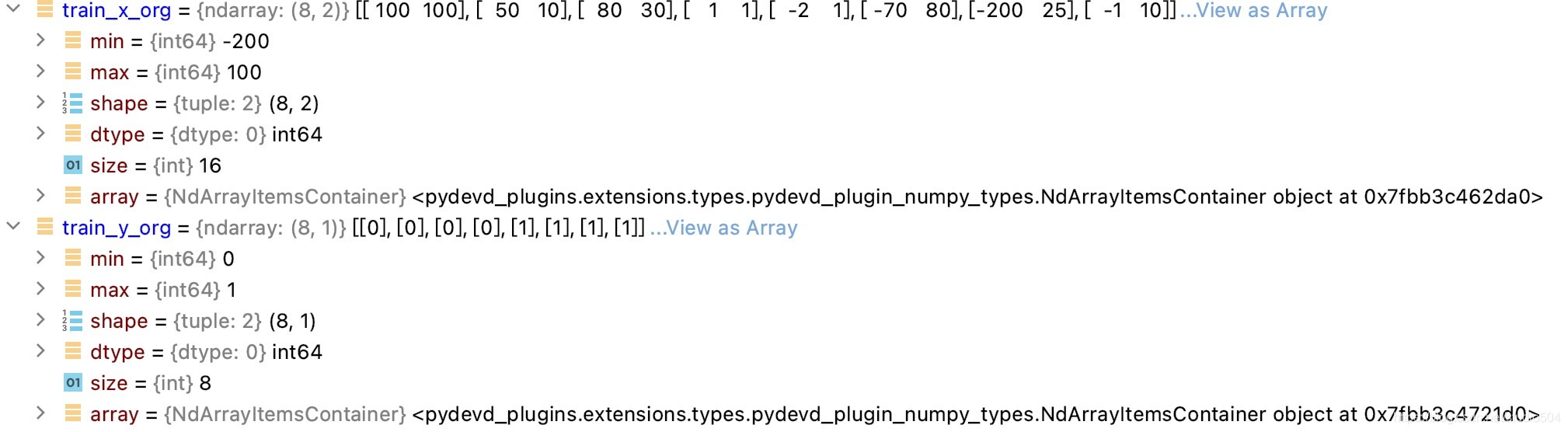
打亂并且分割后,訓練集與測驗集數量相加與源矩陣維度相同,分割比例為0.2,數量正確,

LSTM
LSTM是長短期記憶(Long short-term memory, LSTM),作為一種特殊的RNN相比普通的RNN,LSTM能夠在更長的序列中有更好的表現,而電磁資料恰好是一個較長的連續序列,
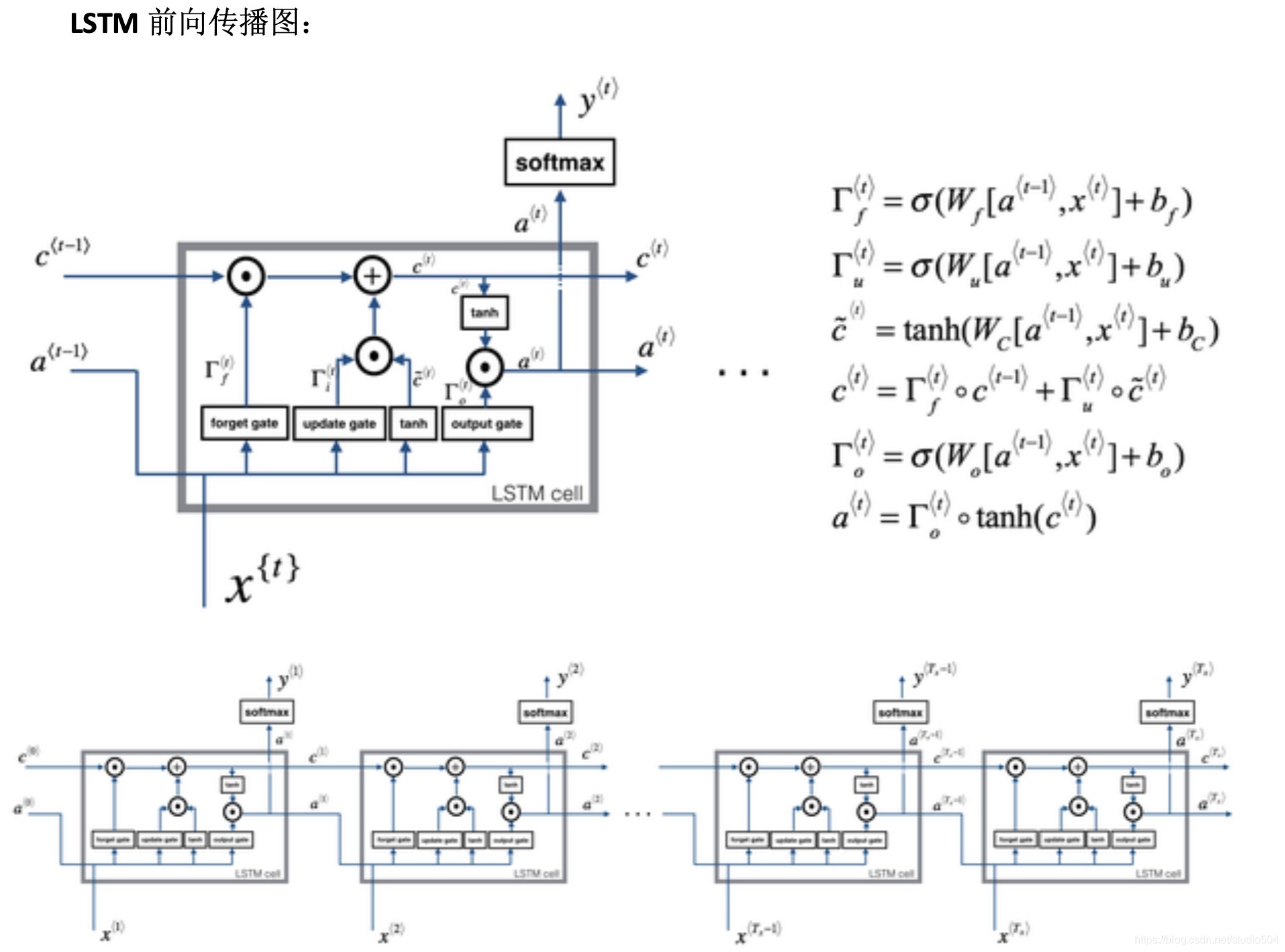
相對于普通的ANN網路,RNN中的LSTM的前向傳播看起來還是略顯復雜,
LSTM中遺忘門與更新門是保存記憶與更新記憶的關鍵,當神經網路可以判斷出智能車處于轉彎處或是長直道且保存記憶,并在離開元素后更新記憶,效果應該是較為理想的,
但良好的記憶能力使得其非常擅長于長時間記憶某個值,對于存在記憶細胞中的某個值,即使經過很長很長的時間步——吳恩達,
在所剩無幾的假期中我并沒有打算著手去實作LSTM流程,但其思想可少許借鑒于現有ANN網路的改進,也就是文章開頭所說的思考,即使用前次電感值、新電感值、上次打腳值作為神經網路輸入,計算出新打腳值,
當回校后若普通ANN效果不盡人意,再考慮是否嘗試LSTM的實作,
我認為LSTM可能是電磁傳感器控制一種較為合理的方案,智能車AI電磁部署學習 (一)開頭的知乎鏈接中的前輩也提到LSTM(若日后攝像頭也可以跑神經網路,那可能一定是采用CNN,或者CNN+RNN的方案) ,
歡迎讀者評論、留言、私信共同探討,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/266325.html
標籤:AI
下一篇:結構體及結構體記憶體對齊講解