本文說討論的 IncrementalPuller 是指 Hadoop 資料的增量查詢,有兩種場景,batch 模式下查詢是指一次性回傳所有或者有變化的資料,steaming 模式下查詢是指連續回傳所有資料并接著只回傳有變化的資料,或者只回傳有變化的資料,這取決于用戶如何指定 increment scan 的 snapshot,
IncrementalPuller 配合資料的 Row Level Delete(即資料的update、delete)即可以實作 Incremental processing on Hadoop ,介于 batch processing 和 Stream processing 之間的 near-real-time processing,比如 batch processing 指的是資料結果延遲 1小時以上的,經典的是以 MR/Spark 為代表的 T+1 資料,Stream processing 指的是資料結果延遲小于5分鐘,以 Flink/Spark Streaming 為代表,而 near-real-time processing 指的是資料結果延遲在 5分鐘 到 1小時 之間計算,經典的場景是計算最近X分鐘某種結果,Uber 把這種近實時處理稱為 Incremental processing, 即增量處理,
舉個例子,計算最近十五分鐘訂單的成交金額,原始資料在 kafka 中,在不引入第三方存盤或者分析引擎,如 druid、ES、Kudu 等,批處理是無法得到結果的,但是對應的代價就是架構的復雜和重復的存盤,當然如果使用流處理利用視窗是可以得到結果的,劣勢在于流處理是長時間持有 Yarn Container 資源的,會對資源有浪費,若能實作增量處理,即通過只處理最近15分鐘變化的資料,可以避免批處理需要掃描所有資料,也可以避免流處理常駐行程導致的資源浪費,
Iceberg
以 flink 為例,在 iceberg 中 increment read 實作分為兩種,以 isStreaming 標志分別是 batch 和 streaming 兩種模式,batch 模式較為簡單,我們以 streaming 模式具體展開,
引數說明
- streaming true: 表示流計算模式
- snapshotId: 表示讀取哪個版本的資料,streaming reader 下不能設定該引數
- asOfTimestamp: 和 snapshotId 引數作用類似,相當于用時間戳來指定 snapshotId ,若在時間遞增的情況下,有 snapshotId-NAN,timestamp-A,snapshotId-1,snapshotId-2,timestamp-B,snapshotId-3,其中 timestamp-A < timestamp-B, snapshotId-NAN 表示無 snapshot 生成,若用戶指定 timestamp-B,則從 snapshot-2 開始讀取資料,即最近提交的版本,
若用戶指定 timestamp-A,則將報錯,因為之前沒有提交成功的版本
- startSnapshotId: streaming reader 從哪個版本開始讀取資料,但是不包括該版本的資料,不指定則讀取歷史所有資料
- endSnapshotId: streaming reader 不能指定 end,batch 時指定后表示讀取到哪個版本為止,包括該版本
實作
測驗類
/**
* 需要本地啟動 hadoop 服務
*/
public class IcebergReadWriteTest {
public static void main(String[] args) throws Exception {
// write();
incrementalRead();
}
public static void write() throws Exception {
StreamExecutionEnvironment env = initEnv();
DataStream<RowData> inputStream = env.addSource(new RichSourceFunction<RowData>() {
private static final long serialVersionUID = 1L;
boolean flag = true;
@Override
public void run(SourceContext<RowData> ctx) throws Exception {
while (flag) {
GenericRowData row = new GenericRowData(2);
row.setField(0, System.currentTimeMillis());
row.setField(1, StringData.fromString(UUID.randomUUID().toString()));
ctx.collect(row);
}
}
@Override
public void cancel() {
flag = false;
}
});
// define iceberg table schema.
Schema schema = new Schema(Types.NestedField.optional(1, "id", Types.LongType.get()),
Types.NestedField.optional(2, "data", Types.StringType.get()));
// define iceberg partition specification.
PartitionSpec spec = PartitionSpec.unpartitioned();
// table path
String basePath = "hdfs://localhost:8020/";
String tablePath = basePath.concat("iceberg-table-2");
// property settings, format as orc or parquet
Map<String, String> props =
ImmutableMap.of(TableProperties.DEFAULT_FILE_FORMAT, FileFormat.ORC.name());
// create an iceberg table.
Table table = new HadoopTables().create(schema, spec, props, tablePath);
TableLoader tableLoader = TableLoader.fromHadoopTable(tablePath);
FlinkSink.forRowData(inputStream).table(table).tableLoader(tableLoader).writeParallelism(1).build();
env.execute("iceberg write and read.");
}
public static void incrementalRead() throws Exception {
StreamExecutionEnvironment env = initEnv();
// table path
String basePath = "hdfs://localhost:8020/";
String tablePath = basePath.concat("iceberg-table-2");
TableLoader tableLoader = TableLoader.fromHadoopTable(tablePath);
//read file
DataStream<RowData> dataStream = FlinkSource.forRowData().env(env).tableLoader(tableLoader).streaming(true)
.startSnapshotId(2790691321534033651L).build();
dataStream.print("===");
env.execute("iceberg read");
}
public static StreamExecutionEnvironment initEnv() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.enableCheckpointing(5000L);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(5000);
env.getCheckpointConfig().setCheckpointTimeout(60 * 1000L);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
return env;
}
} |
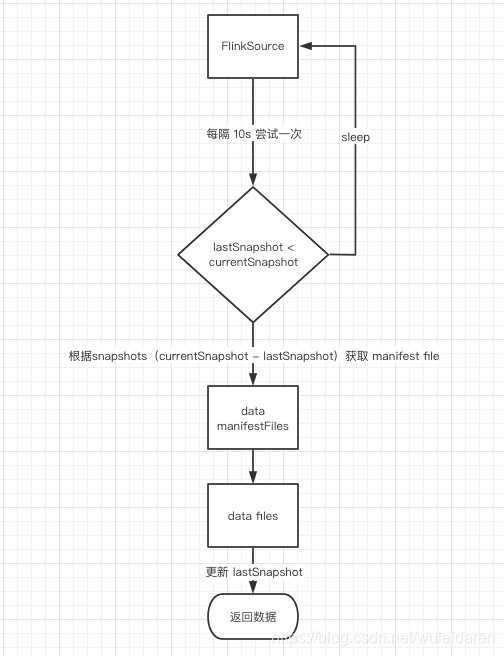
整體流程
- FlinkSource 每隔 10s 嘗試去拉取增量資料,判斷上次讀取的版本號,即 lastSnapshot,若 lastSnapshot 已經為當前最新的版本,說明所有的資料已經讀取,進入休眠
- 若 lastSnapshot 小于當前最新版本,說明至少有一個版本的 change log 沒有讀取,則根據 currentSnapshot - lastSnapshot 得到所有未讀取的 snapShots
- 根據 snapShots,可以得到這些版本號對應的所有的 manifestList,通過 manifestList 得到對應所有的 manifestFile,對 manifestFile 過濾,得到只屬于這些 snapShot 新增的 data manifestFile(manifestFile 新建時維護了相關屬性 content 和 snapshot)
- 根據上一步的 data manifestFile,得到對應所有的 data file,對 data file 過濾,得到只屬于這些 snapShot 新增的 data file (data file 新建時維護了相關屬性 status 和 snapshot)
- 根據 data file 構建 FileScanTask,并更新 lastSnapshot 為currentSnapshot
代碼說明
FlinkSource.build() 方法中根據 isStreaming=true 會構造 StreamingMonitorFunction,這個類繼承 Flink RichSourceFunction,相當于 Source
@Override
public void run(SourceContext<FlinkInputSplit> ctx) throws Exception {
this.sourceContext = ctx;
while (isRunning) {
synchronized (sourceContext.getCheckpointLock()) {
if (isRunning) {
monitorAndForwardSplits();
}
}
// 固定時間間隔去構造 FlinkInputSplit,默認 10s,
Thread.sleep(scanContext.monitorInterval().toMillis());
}
} |
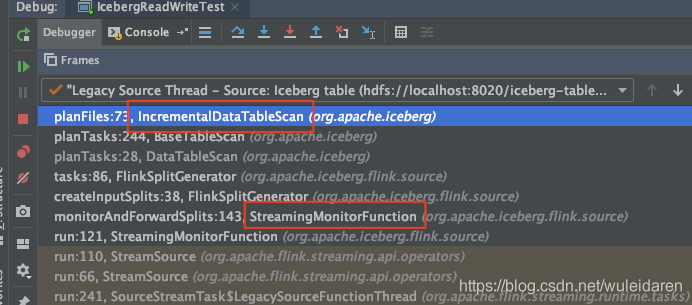
由 StreamingMonitorFunction 中構造 Split ,一直跳轉到 IncrementalDataTableScan 構造 planFiles,獲取需要特定檔案構造 Source 中本次讀取的資料
@Override
public CloseableIterable<FileScanTask> planFiles() {
// 獲取所需要遍歷的 Snapshot 集合,(fromSnapshotId, toSnapshotId], 左開右閉
List<Snapshot> snapshots = snapshotsWithin(table(),
context().fromSnapshotId(), context().toSnapshotId());
Set<Long> snapshotIds = Sets.newHashSet(Iterables.transform(snapshots, Snapshot::snapshotId));
// 遍歷得到所有需要掃描的 ManifestFile
Set<ManifestFile> manifests = FluentIterable
.from(snapshots)
// 過濾 deleteManifests
.transformAndConcat(Snapshot::dataManifests)
// manifestFile 創建的時候會帶上對應的 snapshotId,此處過濾相當于獲取每個 snapshot 新增的 manifestFile
.filter(manifestFile -> snapshotIds.contains(manifestFile.snapshotId()))
.toSet();
ManifestGroup manifestGroup = new ManifestGroup(tableOps().io(), manifests)
.caseSensitive(isCaseSensitive())
.select(colStats() ? SCAN_WITH_STATS_COLUMNS : SCAN_COLUMNS)
.filterData(filter())
.filterManifestEntries(
manifestEntry ->
// manifestEntry 是 dataFile 或 deleteFile 的包裝類,file 創建時會帶上對應的 snapshotId,此處過濾相當于獲取每個 manifestFile 中新增的 dataFile(deleteManifests 已被過濾)
snapshotIds.contains(manifestEntry.snapshotId()) &&
manifestEntry.status() == ManifestEntry.Status.ADDED)
.specsById(tableOps().current().specsById())
.ignoreDeleted();
if (shouldIgnoreResiduals()) {
manifestGroup = manifestGroup.ignoreResiduals();
}
Listeners.notifyAll(new IncrementalScanEvent(table().name(), context().fromSnapshotId(),
context().toSnapshotId(), context().rowFilter(), schema()));
if (PLAN_SCANS_WITH_WORKER_POOL && manifests.size() > 1) {
manifestGroup = manifestGroup.planWith(ThreadPools.getWorkerPool());
}
return manifestGroup.planFiles();
} |
/**
* manifestGroup.planFiles() 通過上一步,已經得到部分 dataFile, 此處對所有 dataFile 進行遍歷,每一個 dataFile 構造為一個 task
* 當前 IncrementalDataTableScan 不支持 overwrite 操作,故 delete file 為空
*/
public CloseableIterable<FileScanTask> planFiles() {
LoadingCache<Integer, ResidualEvaluator> residualCache = Caffeine.newBuilder().build(specId -> {
PartitionSpec spec = specsById.get(specId);
Expression filter = ignoreResiduals ? Expressions.alwaysTrue() : dataFilter;
return ResidualEvaluator.of(spec, filter, caseSensitive);
});
DeleteFileIndex deleteFiles = deleteIndexBuilder.build();
boolean dropStats = ManifestReader.dropStats(dataFilter, columns);
if (!deleteFiles.isEmpty()) {
select(ManifestReader.withStatsColumns(columns));
}
Iterable<CloseableIterable<FileScanTask>> tasks = entries((manifest, entries) -> {
int specId = manifest.partitionSpecId();
PartitionSpec spec = specsById.get(specId);
String schemaString = SchemaParser.toJson(spec.schema());
String specString = PartitionSpecParser.toJson(spec);
ResidualEvaluator residuals = residualCache.get(specId);
if (dropStats) {
return CloseableIterable.transform(entries, e -> new BaseFileScanTask(
e.file().copyWithoutStats(), deleteFiles.forEntry(e), schemaString, specString, residuals));
} else {
return CloseableIterable.transform(entries, e -> new BaseFileScanTask(
e.file().copy(), deleteFiles.forEntry(e), schemaString, specString, residuals));
}
});
if (executorService != null) {
return new ParallelIterable<>(tasks, executorService);
} else {
return CloseableIterable.concat(tasks);
}
} |
Hudi
測驗類如下,實作待定~
@Test def testCount() {
// First Operation:
// Producing parquet files to three default partitions.
// SNAPSHOT view on MOR table with parquet files only.
val records1 = recordsToStrings(dataGen.generateInserts("001", 100)).toList
val inputDF1 = spark.read.json(spark.sparkContext.parallelize(records1, 2))
inputDF1.write.format("org.apache.hudi")
.options(commonOpts)
.option("hoodie.compact.inline", "false") // else fails due to compaction & deltacommit instant times being same
.option(DataSourceWriteOptions.OPERATION_OPT_KEY, DataSourceWriteOptions.INSERT_OPERATION_OPT_VAL)
.option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY, DataSourceWriteOptions.MOR_TABLE_TYPE_OPT_VAL)
.mode(SaveMode.Overwrite)
.save(basePath)
assertTrue(HoodieDataSourceHelpers.hasNewCommits(fs, basePath, "000"))
val hudiSnapshotDF1 = spark.read.format("org.apache.hudi")
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_SNAPSHOT_OPT_VAL)
.load(basePath + "/*/*/*/*")
assertEquals(100, hudiSnapshotDF1.count()) // still 100, since we only updated
// Second Operation:
// Upsert the update to the default partitions with duplicate records. Produced a log file for each parquet.
// SNAPSHOT view should read the log files only with the latest commit time.
val records2 = recordsToStrings(dataGen.generateUniqueUpdates("002", 100)).toList
val inputDF2: Dataset[Row] = spark.read.json(spark.sparkContext.parallelize(records2, 2))
inputDF2.write.format("org.apache.hudi")
.options(commonOpts)
.mode(SaveMode.Append)
.save(basePath)
val hudiSnapshotDF2 = spark.read.format("org.apache.hudi")
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_SNAPSHOT_OPT_VAL)
.load(basePath + "/*/*/*/*")
assertEquals(100, hudiSnapshotDF2.count()) // still 100, since we only updated
val commit1Time = hudiSnapshotDF1.select("_hoodie_commit_time").head().get(0).toString
val commit2Time = hudiSnapshotDF2.select("_hoodie_commit_time").head().get(0).toString
assertEquals(hudiSnapshotDF2.select("_hoodie_commit_time").distinct().count(), 1)
assertTrue(commit2Time > commit1Time)
assertEquals(100, hudiSnapshotDF2.join(hudiSnapshotDF1, Seq("_hoodie_record_key"), "left").count())
// incremental view
// base file only
val hudiIncDF1 = spark.read.format("org.apache.hudi")
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_INCREMENTAL_OPT_VAL)
.option(DataSourceReadOptions.BEGIN_INSTANTTIME_OPT_KEY, "000")
.option(DataSourceReadOptions.END_INSTANTTIME_OPT_KEY, commit1Time)
.load(basePath)
assertEquals(100, hudiIncDF1.count())
assertEquals(1, hudiIncDF1.select("_hoodie_commit_time").distinct().count())
assertEquals(commit1Time, hudiIncDF1.select("_hoodie_commit_time").head().get(0).toString)
hudiIncDF1.show(1)
// log file only
val hudiIncDF2 = spark.read.format("org.apache.hudi")
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_INCREMENTAL_OPT_VAL)
.option(DataSourceReadOptions.BEGIN_INSTANTTIME_OPT_KEY, commit1Time)
.option(DataSourceReadOptions.END_INSTANTTIME_OPT_KEY, commit2Time)
.load(basePath)
assertEquals(100, hudiIncDF2.count())
assertEquals(1, hudiIncDF2.select("_hoodie_commit_time").distinct().count())
assertEquals(commit2Time, hudiIncDF2.select("_hoodie_commit_time").head().get(0).toString)
hudiIncDF2.show(1)
// base file + log file
val hudiIncDF3 = spark.read.format("org.apache.hudi")
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_INCREMENTAL_OPT_VAL)
.option(DataSourceReadOptions.BEGIN_INSTANTTIME_OPT_KEY, "000")
.option(DataSourceReadOptions.END_INSTANTTIME_OPT_KEY, commit2Time)
.load(basePath)
assertEquals(100, hudiIncDF3.count())
// log file being load
assertEquals(1, hudiIncDF3.select("_hoodie_commit_time").distinct().count())
assertEquals(commit2Time, hudiIncDF3.select("_hoodie_commit_time").head().get(0).toString)
// Unmerge
val hudiSnapshotSkipMergeDF2 = spark.read.format("org.apache.hudi")
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_SNAPSHOT_OPT_VAL)
.option(DataSourceReadOptions.REALTIME_MERGE_OPT_KEY, DataSourceReadOptions.REALTIME_SKIP_MERGE_OPT_VAL)
.load(basePath + "/*/*/*/*")
assertEquals(200, hudiSnapshotSkipMergeDF2.count())
assertEquals(100, hudiSnapshotSkipMergeDF2.select("_hoodie_record_key").distinct().count())
assertEquals(200, hudiSnapshotSkipMergeDF2.join(hudiSnapshotDF2, Seq("_hoodie_record_key"), "left").count())
// Test Read Optimized Query on MOR table
val hudiRODF2 = spark.read.format("org.apache.hudi")
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_READ_OPTIMIZED_OPT_VAL)
.load(basePath + "/*/*/*/*")
assertEquals(100, hudiRODF2.count())
// Third Operation:
// Upsert another update to the default partitions with 50 duplicate records. Produced the second log file for each parquet.
// SNAPSHOT view should read the latest log files.
val records3 = recordsToStrings(dataGen.generateUniqueUpdates("003", 50)).toList
val inputDF3: Dataset[Row] = spark.read.json(spark.sparkContext.parallelize(records3, 2))
inputDF3.write.format("org.apache.hudi")
.options(commonOpts)
.mode(SaveMode.Append)
.save(basePath)
val hudiSnapshotDF3 = spark.read.format("org.apache.hudi")
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_SNAPSHOT_OPT_VAL)
.load(basePath + "/*/*/*/*")
// still 100, because we only updated the existing records
assertEquals(100, hudiSnapshotDF3.count())
// 50 from commit2, 50 from commit3
assertEquals(hudiSnapshotDF3.select("_hoodie_commit_time").distinct().count(), 2)
assertEquals(50, hudiSnapshotDF3.filter(col("_hoodie_commit_time") > commit2Time).count())
assertEquals(50,
hudiSnapshotDF3.join(hudiSnapshotDF2, Seq("_hoodie_record_key", "_hoodie_commit_time"), "inner").count())
// incremental query from commit2Time
val hudiIncDF4 = spark.read.format("org.apache.hudi")
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_INCREMENTAL_OPT_VAL)
.option(DataSourceReadOptions.BEGIN_INSTANTTIME_OPT_KEY, commit2Time)
.load(basePath)
assertEquals(50, hudiIncDF4.count())
// skip merge incremental view
// including commit 2 and commit 3
val hudiIncDF4SkipMerge = spark.read.format("org.apache.hudi")
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_INCREMENTAL_OPT_VAL)
.option(DataSourceReadOptions.BEGIN_INSTANTTIME_OPT_KEY, "000")
.option(DataSourceReadOptions.REALTIME_MERGE_OPT_KEY, DataSourceReadOptions.REALTIME_SKIP_MERGE_OPT_VAL)
.load(basePath)
assertEquals(200, hudiIncDF4SkipMerge.count())
// Fourth Operation:
// Insert records to a new partition. Produced a new parquet file.
// SNAPSHOT view should read the latest log files from the default partition and parquet from the new partition.
val partitionPaths = new Array[String](1)
partitionPaths.update(0, "2020/01/10")
val newDataGen = new HoodieTestDataGenerator(partitionPaths)
val records4 = recordsToStrings(newDataGen.generateInserts("004", 100)).toList
val inputDF4: Dataset[Row] = spark.read.json(spark.sparkContext.parallelize(records4, 2))
inputDF4.write.format("org.apache.hudi")
.options(commonOpts)
.mode(SaveMode.Append)
.save(basePath)
val hudiSnapshotDF4 = spark.read.format("org.apache.hudi")
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_SNAPSHOT_OPT_VAL)
.load(basePath + "/*/*/*/*")
// 200, because we insert 100 records to a new partition
assertEquals(200, hudiSnapshotDF4.count())
assertEquals(100,
hudiSnapshotDF1.join(hudiSnapshotDF4, Seq("_hoodie_record_key"), "inner").count())
// Incremental query, 50 from log file, 100 from base file of the new partition.
val hudiIncDF5 = spark.read.format("org.apache.hudi")
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_INCREMENTAL_OPT_VAL)
.option(DataSourceReadOptions.BEGIN_INSTANTTIME_OPT_KEY, commit2Time)
.load(basePath)
assertEquals(150, hudiIncDF5.count())
// Fifth Operation:
// Upsert records to the new partition. Produced a newer version of parquet file.
// SNAPSHOT view should read the latest log files from the default partition
// and the latest parquet from the new partition.
val records5 = recordsToStrings(newDataGen.generateUniqueUpdates("005", 50)).toList
val inputDF5: Dataset[Row] = spark.read.json(spark.sparkContext.parallelize(records5, 2))
inputDF5.write.format("org.apache.hudi")
.options(commonOpts)
.mode(SaveMode.Append)
.save(basePath)
val commit5Time = HoodieDataSourceHelpers.latestCommit(fs, basePath)
val hudiSnapshotDF5 = spark.read.format("org.apache.hudi")
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_SNAPSHOT_OPT_VAL)
.load(basePath + "/*/*/*/*")
assertEquals(200, hudiSnapshotDF5.count())
// Sixth Operation:
// Insert 2 records and trigger compaction.
val records6 = recordsToStrings(newDataGen.generateInserts("006", 2)).toList
val inputDF6: Dataset[Row] = spark.read.json(spark.sparkContext.parallelize(records6, 2))
inputDF6.write.format("org.apache.hudi")
.options(commonOpts)
.option("hoodie.compact.inline", "true")
.mode(SaveMode.Append)
.save(basePath)
val commit6Time = HoodieDataSourceHelpers.latestCommit(fs, basePath)
val hudiSnapshotDF6 = spark.read.format("org.apache.hudi")
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_SNAPSHOT_OPT_VAL)
.load(basePath + "/2020/01/10/*")
assertEquals(102, hudiSnapshotDF6.count())
val hudiIncDF6 = spark.read.format("org.apache.hudi")
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_INCREMENTAL_OPT_VAL)
.option(DataSourceReadOptions.BEGIN_INSTANTTIME_OPT_KEY, commit5Time)
.option(DataSourceReadOptions.END_INSTANTTIME_OPT_KEY, commit6Time)
.load(basePath)
// compaction updated 150 rows + inserted 2 new row
assertEquals(152, hudiIncDF6.count())
} |
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/266347.html
標籤:其他