前幾篇文章我們主要介紹了一些理論上的知識,下面我們來實操一下,本文主要講解Kafka生產者的API,關注專欄《破繭成蝶——大資料篇》,查看更多相關的內容~
目錄
一、Kafka的訊息發送流程
二、Kafka異步發送
2.1 不含回呼函式的異步發送
2.1.1 編碼實作
2.1.2 測驗
2.2 含回呼函式的異步發送
2.2.1 編碼實作
2.2.2 測驗
三、Kafka同步發送
3.1 編碼實作
3.2 測驗
一、Kafka的訊息發送流程
Kafka的Producer發送訊息采用的是異步發送的方式,在訊息發送的程序中,涉及到了兩個執行緒——main執行緒和Sender執行緒,以及一個執行緒共享變數——RecordAccumulator,main執行緒將訊息發送給RecordAccumulator,Sender執行緒不斷從RecordAccumulator中拉取訊息發送到Kafka broker,
下面列舉出了原始碼中Kafka生產者的配置引數:
public static final String BOOTSTRAP_SERVERS_CONFIG = "bootstrap.servers";
public static final String METADATA_MAX_AGE_CONFIG = "metadata.max.age.ms";
private static final String METADATA_MAX_AGE_DOC = "The period of time in milliseconds after which we force a refresh of metadata even if we haven't seen any partition leadership changes to proactively discover any new brokers or partitions.";
public static final String BATCH_SIZE_CONFIG = "batch.size";//資料積累到batch.size之后,sender才會發送資料
private static final String BATCH_SIZE_DOC = "The producer will attempt to batch records together into fewer requests whenever multiple records are being sent to the same partition. This helps performance on both the client and the server. This configuration controls the default batch size in bytes. <p>No attempt will be made to batch records larger than this size. <p>Requests sent to brokers will contain multiple batches, one for each partition with data available to be sent. <p>A small batch size will make batching less common and may reduce throughput (a batch size of zero will disable batching entirely). A very large batch size may use memory a bit more wastefully as we will always allocate a buffer of the specified batch size in anticipation of additional records.";
public static final String ACKS_CONFIG = "acks";
private static final String ACKS_DOC = "The number of acknowledgments the producer requires the leader to have received before considering a request complete. This controls the durability of records that are sent. The following settings are allowed: <ul> <li><code>acks=0</code> If set to zero then the producer will not wait for any acknowledgment from the server at all. The record will be immediately added to the socket buffer and considered sent. No guarantee can be made that the server has received the record in this case, and the <code>retries</code> configuration will not take effect (as the client won't generally know of any failures). The offset given back for each record will always be set to -1. <li><code>acks=1</code> This will mean the leader will write the record to its local log but will respond without awaiting full acknowledgement from all followers. In this case should the leader fail immediately after acknowledging the record but before the followers have replicated it then the record will be lost. <li><code>acks=all</code> This means the leader will wait for the full set of in-sync replicas to acknowledge the record. This guarantees that the record will not be lost as long as at least one in-sync replica remains alive. This is the strongest available guarantee. This is equivalent to the acks=-1 setting.";
public static final String LINGER_MS_CONFIG = "linger.ms";//如果資料一直沒有達到batch.size,sender等待linger.ms之后就會發送資料
private static final String LINGER_MS_DOC = "The producer groups together any records that arrive in between request transmissions into a single batched request. Normally this occurs only under load when records arrive faster than they can be sent out. However in some circumstances the client may want to reduce the number of requests even under moderate load. This setting accomplishes this by adding a small amount of artificial delay—that is, rather than immediately sending out a record the producer will wait for up to the given delay to allow other records to be sent so that the sends can be batched together. This can be thought of as analogous to Nagle's algorithm in TCP. This setting gives the upper bound on the delay for batching: once we get <code>batch.size</code> worth of records for a partition it will be sent immediately regardless of this setting, however if we have fewer than this many bytes accumulated for this partition we will 'linger' for the specified time waiting for more records to show up. This setting defaults to 0 (i.e. no delay). Setting <code>linger.ms=5</code>, for example, would have the effect of reducing the number of requests sent but would add up to 5ms of latency to records sent in the absense of load.";
public static final String CLIENT_ID_CONFIG = "client.id";
public static final String SEND_BUFFER_CONFIG = "send.buffer.bytes";
public static final String RECEIVE_BUFFER_CONFIG = "receive.buffer.bytes";
public static final String MAX_REQUEST_SIZE_CONFIG = "max.request.size";
private static final String MAX_REQUEST_SIZE_DOC = "The maximum size of a request in bytes. This is also effectively a cap on the maximum record size. Note that the server has its own cap on record size which may be different from this. This setting will limit the number of record batches the producer will send in a single request to avoid sending huge requests.";
public static final String RECONNECT_BACKOFF_MS_CONFIG = "reconnect.backoff.ms";
public static final String RECONNECT_BACKOFF_MAX_MS_CONFIG = "reconnect.backoff.max.ms";
public static final String MAX_BLOCK_MS_CONFIG = "max.block.ms";
private static final String MAX_BLOCK_MS_DOC = "The configuration controls how long <code>KafkaProducer.send()</code> and <code>KafkaProducer.partitionsFor()</code> will block.These methods can be blocked either because the buffer is full or metadata unavailable.Blocking in the user-supplied serializers or partitioner will not be counted against this timeout.";
public static final String BUFFER_MEMORY_CONFIG = "buffer.memory";
private static final String BUFFER_MEMORY_DOC = "The total bytes of memory the producer can use to buffer records waiting to be sent to the server. If records are sent faster than they can be delivered to the server the producer will block for <code>max.block.ms</code> after which it will throw an exception.<p>This setting should correspond roughly to the total memory the producer will use, but is not a hard bound since not all memory the producer uses is used for buffering. Some additional memory will be used for compression (if compression is enabled) as well as for maintaining in-flight requests.";
public static final String RETRY_BACKOFF_MS_CONFIG = "retry.backoff.ms";
public static final String COMPRESSION_TYPE_CONFIG = "compression.type";
private static final String COMPRESSION_TYPE_DOC = "The compression type for all data generated by the producer. The default is none (i.e. no compression). Valid values are <code>none</code>, <code>gzip</code>, <code>snappy</code>, or <code>lz4</code>. Compression is of full batches of data, so the efficacy of batching will also impact the compression ratio (more batching means better compression).";
public static final String METRICS_SAMPLE_WINDOW_MS_CONFIG = "metrics.sample.window.ms";
public static final String METRICS_NUM_SAMPLES_CONFIG = "metrics.num.samples";
public static final String METRICS_RECORDING_LEVEL_CONFIG = "metrics.recording.level";
public static final String METRIC_REPORTER_CLASSES_CONFIG = "metric.reporters";
public static final String MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION = "max.in.flight.requests.per.connection";
private static final String MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION_DOC = "The maximum number of unacknowledged requests the client will send on a single connection before blocking. Note that if this setting is set to be greater than 1 and there are failed sends, there is a risk of message re-ordering due to retries (i.e., if retries are enabled).";
public static final String RETRIES_CONFIG = "retries";
private static final String RETRIES_DOC = "Setting a value greater than zero will cause the client to resend any record whose send fails with a potentially transient error. Note that this retry is no different than if the client resent the record upon receiving the error. Allowing retries without setting <code>max.in.flight.requests.per.connection</code> to 1 will potentially change the ordering of records because if two batches are sent to a single partition, and the first fails and is retried but the second succeeds, then the records in the second batch may appear first.";
public static final String KEY_SERIALIZER_CLASS_CONFIG = "key.serializer";
public static final String KEY_SERIALIZER_CLASS_DOC = "Serializer class for key that implements the <code>Serializer</code> interface.";
public static final String VALUE_SERIALIZER_CLASS_CONFIG = "value.serializer";
public static final String VALUE_SERIALIZER_CLASS_DOC = "Serializer class for value that implements the <code>Serializer</code> interface.";
public static final String CONNECTIONS_MAX_IDLE_MS_CONFIG = "connections.max.idle.ms";
public static final String PARTITIONER_CLASS_CONFIG = "partitioner.class";
private static final String PARTITIONER_CLASS_DOC = "Partitioner class that implements the <code>Partitioner</code> interface.";
public static final String REQUEST_TIMEOUT_MS_CONFIG = "request.timeout.ms";
private static final String REQUEST_TIMEOUT_MS_DOC = "The configuration controls the maximum amount of time the client will wait for the response of a request. If the response is not received before the timeout elapses the client will resend the request if necessary or fail the request if retries are exhausted. This should be larger than replica.lag.time.max.ms (a broker configuration) to reduce the possibility of message duplication due to unnecessary producer retries.";
public static final String INTERCEPTOR_CLASSES_CONFIG = "interceptor.classes";
public static final String INTERCEPTOR_CLASSES_DOC = "A list of classes to use as interceptors. Implementing the <code>ProducerInterceptor</code> interface allows you to intercept (and possibly mutate) the records received by the producer before they are published to the Kafka cluster. By default, there are no interceptors.";
public static final String ENABLE_IDEMPOTENCE_CONFIG = "enable.idempotence";
public static final String ENABLE_IDEMPOTENCE_DOC = "When set to 'true', the producer will ensure that exactly one copy of each message is written in the stream. If 'false', producer retries due to broker failures, etc., may write duplicates of the retried message in the stream. This is set to 'false' by default. Note that enabling idempotence requires <code>max.in.flight.requests.per.connection</code> to be set to 1 and <code>retries</code> cannot be zero. Additionally acks must be set to 'all'. If these values are left at their defaults, we will override the default to be suitable. If the values are set to something incompatible with the idempotent producer, a ConfigException will be thrown.";
public static final String TRANSACTION_TIMEOUT_CONFIG = "transaction.timeout.ms";
public static final String TRANSACTION_TIMEOUT_DOC = "The maximum amount of time in ms that the transaction coordinator will wait for a transaction status update from the producer before proactively aborting the ongoing transaction.If this value is larger than the max.transaction.timeout.ms setting in the broker, the request will fail with a `InvalidTransactionTimeout` error.";
public static final String TRANSACTIONAL_ID_CONFIG = "transactional.id";
public static final String TRANSACTIONAL_ID_DOC = "The TransactionalId to use for transactional delivery. This enables reliability semantics which span multiple producer sessions since it allows the client to guarantee that transactions using the same TransactionalId have been completed prior to starting any new transactions. If no TransactionalId is provided, then the producer is limited to idempotent delivery. Note that enable.idempotence must be enabled if a TransactionalId is configured. The default is empty, which means transactions cannot be used.";
二、Kafka異步發送
2.1 不含回呼函式的異步發送
2.1.1 編碼實作
1、首先需要匯入依賴,如下所示:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.0</version>
</dependency>2、代碼實作
首先需要創建一個生產者物件KafkaProducer用來發送資料,通過ProducerConfig配置生產者所需要的引數,最后將資料封裝成一個ProducerRecord物件,
package com.xzw.kafka.producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
/**
* @author: xzw
* @create_date: 2021/3/2 8:43
* @desc: 異步發送
* @modifier:
* @modified_date:
* @desc:
*/
public class AsyncProducer {
public static void main(String[] args) {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "master:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.ACKS_CONFIG, "all");
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
props.put(ProducerConfig.LINGER_MS_CONFIG, 1);
//1、創建一個生產者物件
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
//2、呼叫生產者的send方法
for (int i = 0; i < 10; i++) {
producer.send(new ProducerRecord<String, String>("test", i + "", "data-" + i));
}
//3、關閉生產者
producer.close();
}
}
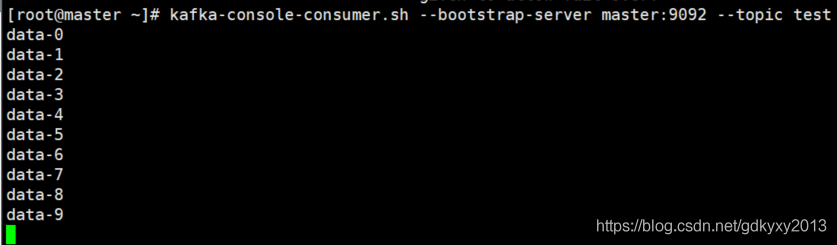
2.1.2 測驗
新開一個消費者的視窗,同時啟動生產者的API,可以發現消費者已經消費到了資料:
2.2 含回呼函式的異步發送
回呼函式會在producer收到ack時呼叫,為異步呼叫,該方法有兩個引數,分別是RecordMetadata和Exception,如果Exception為null,說明訊息發送成功,如果Exception不為null,說明訊息發送失敗,這里需要注意的是,訊息發送失敗會自動重試,不需要我們在回呼函式中手動重試,
2.2.1 編碼實作
實作回呼函式非常簡單,只需要在send方法中添加如下的運算式即可:

2.2.2 測驗
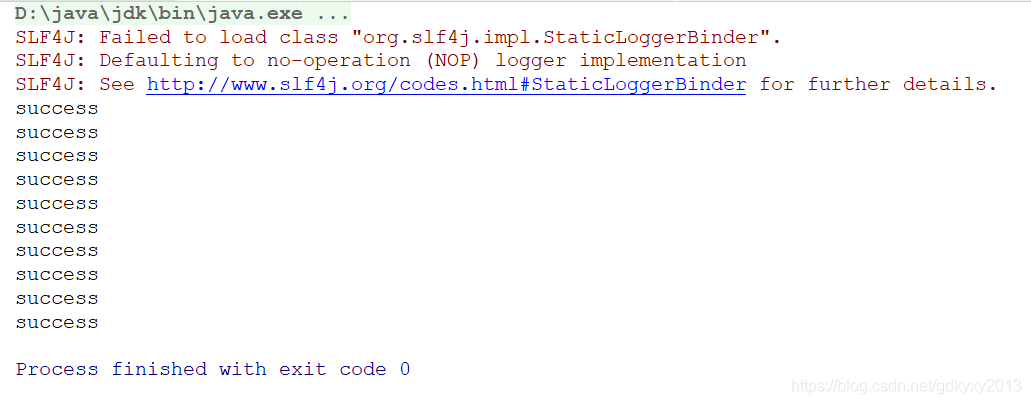
新開一個消費者的視窗,同時啟動生產者的API,可以發現消費者已經消費到了資料:
同時在本地控制臺,也發現了回呼函式列印出來的資料:
三、Kafka同步發送
同步發送的意思就是,一條訊息發送之后,會阻塞當前執行緒,直至回傳ack,同步發送的實作程序非常簡單,下面是具體的實作代碼,只需在呼叫Future物件的get方法即可,
3.1 編碼實作
package com.xzw.kafka.producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
/**
* @author: xzw
* @create_date: 2021/3/2 10:08
* @desc: 同步發送
* @modifier:
* @modified_date:
* @desc:
*/
public class SyncProducer {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "master:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.ACKS_CONFIG, "all");
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
props.put(ProducerConfig.LINGER_MS_CONFIG, 1000);
//1、創建一個生產者物件
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
//2、呼叫生產者的send方法
for (int i = 0; i < 10; i++) {
RecordMetadata metadata =
producer.send(new ProducerRecord<String, String>("test", i + "", "data-" + i)).get();
System.out.println("offset=" + metadata.offset());
}
//3、關閉生產者
producer.close();
}
}
3.2 測驗
通過測驗可以發現,同步發送,很明顯是一條一條發送的,因為一條訊息發送之后,會阻塞當前執行緒,直至回傳ack,

本文到此已經接近尾聲了,本文主要講述了一下Kafka生產者的API,內容比較簡單,你們在此程序中遇到了什么問題,歡迎留言,讓我看看你們都遇到了哪些問題~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/266645.html
標籤:其他
下一篇:涉及作業中Linux常用命令詳解