一步一步學習,記錄小編的成長和小編足跡,想要學習python的朋友,可以參考小編以前寫的博客哦,
web請求:
當我們在f訪問百度的時候就有web請求,我們輸入一個網址后,瀏覽器還發送請求給百度的服務器,百度服務器會回傳百度的html,當我們在百度搜索其他內容的時候,內容就以引數形式發送給百度瀏覽器,百度瀏覽器接收后,會按照引數繼續內部的檢索,找到根據引數的內容,進行排序,把引數的內容寫入html里面,然后統一帶有引數內容進行回傳,(特點:在源代碼中能看見)
(ctrl+f:網頁查找快捷鍵)
服務器渲染(在服務器把資料和html進行集合,統一回傳給瀏覽器程序)
客戶端渲染:當你請求網頁內容的時候,就給你一個html的骨架,然后瀏覽器去請求服務器資料,然后服務器會給資料,客戶端將骨架和資料進行拼接在一起,(特點:在頁面源代碼中看不到,查找資料就要使用瀏覽器抓包工具:滑鼠右鍵檢查或F12)
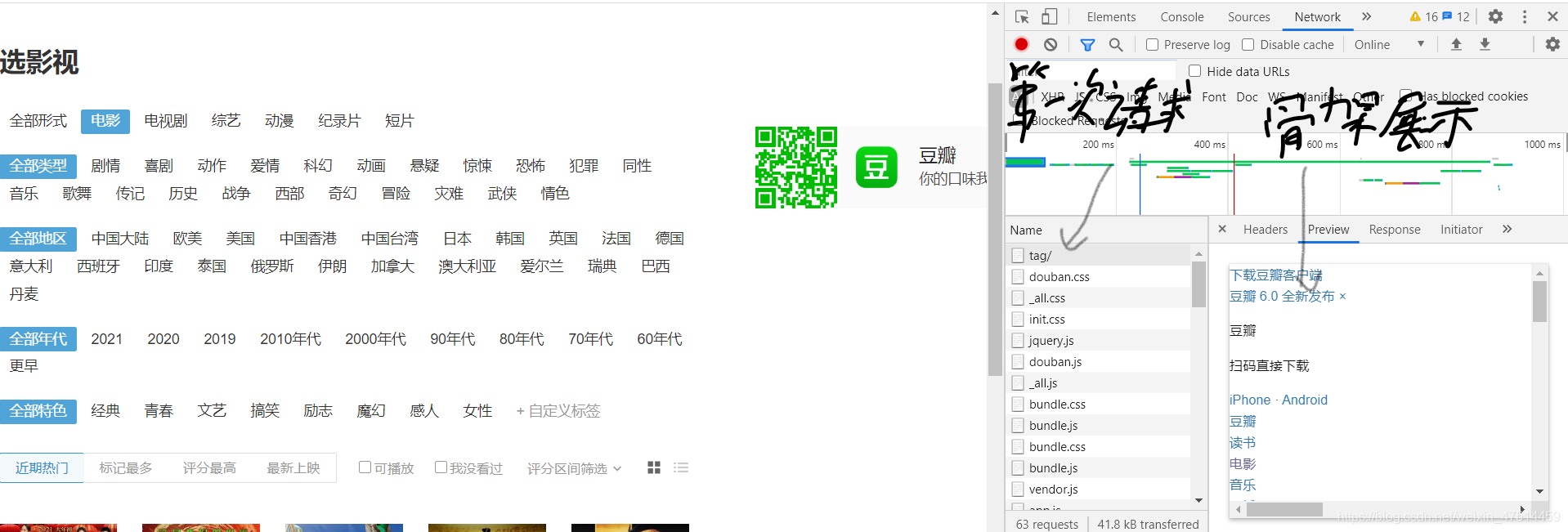
http協議:(超文本協議:html里面內容就是超文本)
每次我們訪問www,xxxxxxx.com的時候都會自動的添加http或https,表示url地址遵循http協議,
協議:二臺計算機之間為能夠進行溝通而設定的規則,
```python
'''
請求:
請求行——請求方式(get,put,post等),請求url地址,協議
請求頭——服務器里使用的附加資訊(放反爬內容)
請求體——一般放請求引數
回應:
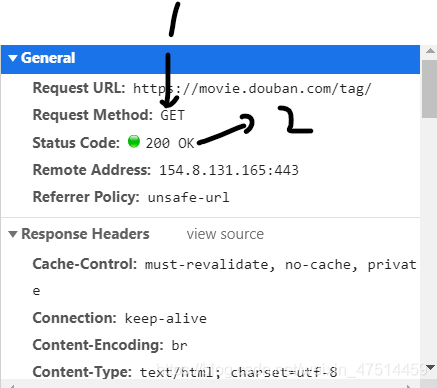
狀態行——協議,狀態碼(200,5000,302,401,404,403等等)
回應頭——放置客戶端需要的一些附加資訊
回應體——服務器回傳的真正客戶端的要用的內容(HTML,json)等
'''
1,請求方式,2,狀態碼
'''
請求頭:
1,User-Agent:請求載體的身份標識(用什么瀏覽器發送的請求)
2,Referer:防盜鏈(判別請求從哪里來,用來反爬)
3,cookie:本地字串資料資訊(用來用戶登錄,反爬的token)
回應頭:
1,cookie:
2,各種各樣的字串(一般都是token字樣,防止各種攻擊和反爬)
'''
常見請求發送(get,post)
get:顯示提交(一般用來查看)
post:隱顯提交(一般用來修改,增加,上傳服務器內容)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/267084.html
標籤:其他
上一篇:計算機網路原理【四】之 網路層