本文主要參考是的:
https://blog.csdn.net/asialee_bird/article/details/88813385
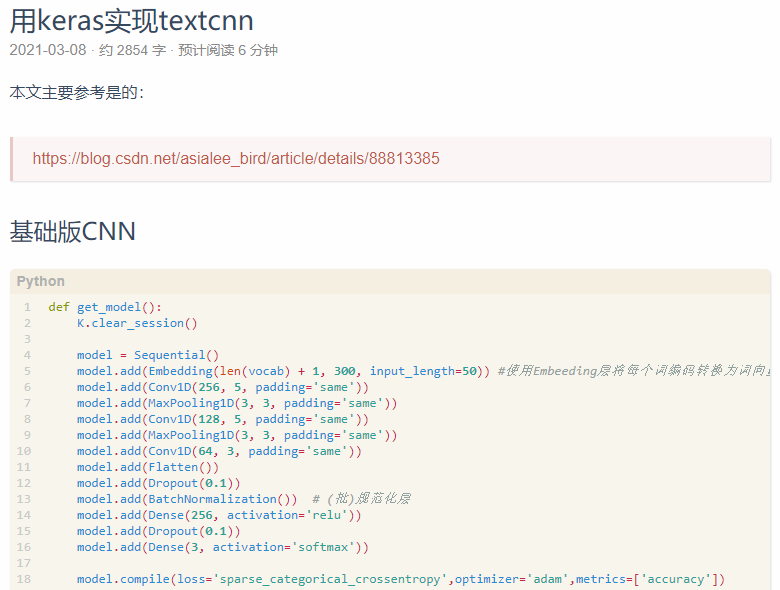
基礎版CNN
def get_model():
K.clear_session()
model = Sequential()
model.add(Embedding(len(vocab) + 1, 300, input_length=50)) #使用Embeeding層將每個詞編碼轉換為詞向量
model.add(Conv1D(256, 5, padding='same'))
model.add(MaxPooling1D(3, 3, padding='same'))
model.add(Conv1D(128, 5, padding='same'))
model.add(MaxPooling1D(3, 3, padding='same'))
model.add(Conv1D(64, 3, padding='same'))
model.add(Flatten())
model.add(Dropout(0.1))
model.add(BatchNormalization()) # (批)規范化層
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.1))
model.add(Dense(3, activation='softmax'))
model.compile(loss='sparse_categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
print(model.summary())
return model
簡單版TextCNN
def get_model():
K.clear_session()
main_input = Input(shape=(50,), dtype='float64')
# 詞嵌入(使用預訓練的詞向量)
embedder = Embedding(len(vocab) + 1, 300, input_length=50, trainable=False)
embed = embedder(main_input)
# 詞窗大小分別為3,4,5
cnn1 = Conv1D(256, 3, padding='same', strides=1, activation='relu')(embed)
cnn1 = MaxPooling1D(pool_size=48)(cnn1)
cnn2 = Conv1D(256, 4, padding='same', strides=1, activation='relu')(embed)
cnn2 = MaxPooling1D(pool_size=47)(cnn2)
cnn3 = Conv1D(256, 5, padding='same', strides=1, activation='relu')(embed)
cnn3 = MaxPooling1D(pool_size=46)(cnn3)
# 合并三個模型的輸出向量
cnn = concatenate([cnn1, cnn2, cnn3], axis=-1)
flat = Flatten()(cnn)
drop = Dropout(0.2)(flat)
main_output = Dense(3, activation='softmax')(drop)
model = Model(inputs=main_input, outputs=main_output)
model.compile(loss='sparse_categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
print(model.summary())
return model
附錄
全部原始碼
導包
import os
import random
from joblib import load, dump
from sklearn.model_selection import train_test_split
import pandas as pd
import jieba
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from tqdm import tqdm
import numpy as np
import pandas as pd
from keras.models import Sequential, Model
from keras.layers import Embedding, Conv1D, MaxPooling1D, Flatten, Dropout, BatchNormalization, Dense, Input, concatenate
from keras import backend as K
from keras.callbacks import EarlyStopping, ReduceLROnPlateau
構建文本迭代器
def get_text_label_iterator(data_path):
with open(data_path, 'r', encoding='utf-8') as f:
for line in f:
line_split = line.strip().split('\t')
if len(line_split) != 2:
print(line)
continue
yield line_split[0], line_split[1]
it = get_text_label_iterator(r"data/keras_bert_train.txt")
next(it)
('競彩決議:日本美國爭冠死磕 兩巴相逢必有生死,周日受注賽事,女足世界杯決賽、美洲杯兩場1/4決賽毫無疑問是全世界球迷和彩民關注的焦點,本屆女足世界杯的最大黑馬日本隊能否一黑到底,創造亞洲奇跡?女子足壇霸主美國隊能否再次“滅黑”成功,成就三冠偉業?巴西、巴拉圭冤家路窄,誰又能笑到最后?諸多謎底,在周一凌晨就會揭曉,日本美國爭冠死磕,本屆女足世界杯,是顛覆與反顛覆之爭,奪冠大熱門東道主德國隊1/4決賽被日本隊加時賽一球而“黑”,另一個奪冠大熱門瑞典隊則在半決賽被日本隊3:1徹底打垮,而美國隊則捍衛著女足豪強的尊嚴,在1/4決賽,她們與巴西女足苦戰至點球大戰,最終以5:3淘汰這支迅速崛起的黑馬球隊,而在半決賽,她們更是3:1大勝歐洲黑馬法國隊,美日兩隊此次世界杯行程驚人相似,小組賽前兩輪全勝,最后一輪輸球,1/4決賽同樣與對手90分鐘內戰成平局,半決賽竟同樣3:1大勝對手,此次決戰,無論是日本還是美國隊奪冠,均將創造女足世界杯新的歷史,兩巴相逢必有生死,本屆美洲杯,讓人大跌眼鏡的事情太多,巴西、巴拉圭冤家路窄似乎更具傳奇色彩,兩隊小組賽同分在B組,原本兩個出線大熱門,卻雙雙在前兩輪小組賽戰平,兩隊直接交鋒就是2:2平局,結果雙雙面臨出局危險,最后一輪,巴西隊在下半場終于發威,4:2大勝厄瓜多爾后來居上以小組第一出線,而巴拉圭最后一戰還是3:3戰平委內瑞拉獲得小組第三,僥幸憑借凈勝球優勢擠掉A組第三名的哥斯達黎加,獲得一個八強席位,在小組賽,巴西隊是在最后時刻才逼平了巴拉圭,他們的好運氣會在淘汰賽再顯神威嗎?巴拉圭此前3輪小組賽似乎都缺乏運氣,此番又會否被幸運之神補償一下呢?,另一場美洲杯1/4決賽,智利隊在C組小組賽2勝1平以小組頭名晉級八強;而委內瑞拉在B組是最不被看好的球隊,但竟然在與巴西、巴拉圭同組的情況下,前兩輪就奠定了小組出線權,他們小組3戰1勝2平保持不敗戰績,而入球數跟智利一樣都是4球,只是失球數比智利多了1個,但既然他們面對強大的巴西都能保持球門不失,此番再創佳績也不足為怪,',
'彩票')
獲得詞匯表vocab
def get_segment_iterator(data_path):
data_iter = get_text_label_iterator(data_path)
for text, label in data_iter:
yield list(jieba.cut(text)), label
it = get_segment_iterator(r"data/keras_bert_train.txt")
# next(it)
def get_only_segment_iterator(data_path):
segment_iter = get_segment_iterator(data_path)
for segment, label in tqdm(segment_iter):
yield segment
# tokenizer=Tokenizer() #創建一個Tokenizer物件
# # fit_on_texts函式可以將輸入的文本中的每個詞編號,編號是根據詞頻的,詞頻越大,編號越小
# tokenizer.fit_on_texts(get_only_segment_iterator(r"data/keras_bert_train.txt"))
# dump(tokenizer, r"data/keras_textcnn_tokenizer.bin")
tokenizer = load(r"data/keras_textcnn_tokenizer.bin")
vocab = tokenizer.word_index #得到每個詞的編號
獲取樣本個數
def get_sample_count(data_path):
data_iter = get_text_label_iterator(data_path)
count = 0
for text, label in tqdm(data_iter):
count += 1
return count
train_sample_count = get_sample_count(r"data/keras_bert_train.txt")
dev_sample_count = get_sample_count(r"data/keras_bert_dev.txt")
構建標簽表
def read_category(data_path):
"""讀取分類目錄,固定"""
categories = os.listdir(data_path)
cat_to_id = dict(zip(categories, range(len(categories))))
return categories, cat_to_id
categories, cat_to_id = read_category("000_text_classifier_tensorflow_textcnn/THUCNews")
cat_to_id
{'彩票': 0,
'家居': 1,
'游戲': 2,
'股票': 3,
'科技': 4,
'社會': 5,
'財經': 6,
'時尚': 7,
'星座': 8,
'體育': 9,
'房產': 10,
'娛樂': 11,
'時政': 12,
'教育': 13}
構建輸入資料迭代器
def get_data_iterator(data_path):
while True:
segment_iter = get_segment_iterator(data_path)
for segment, label in segment_iter:
word_ids = tokenizer.texts_to_sequences([segment])
padded_seqs = pad_sequences(word_ids,maxlen=50)[0] #將超過固定值的部分截掉,不足的在最前面用0填充
yield padded_seqs, cat_to_id[label]
it = get_data_iterator(r"data/keras_bert_train.txt")
next(it)
Building prefix dict from the default dictionary ...
Loading model from cache /tmp/jieba.cache
Loading model cost 1.039 seconds.
Prefix dict has been built succesfully.
(array([ 69, 2160, 57, 3010, 55, 828, 68, 1028,
? 456, 3712, 2130, 1, 36, 116604, 361, 7019,
? 377, 26, 8, 76, 539, 1, 346, 7323,
? 89885, 7019, 73, 7, 55, 84, 3, 33,
? 3199, 69, 579, 1366, 2, 1526, 26, 89,
? 456, 5741, 8256, 1, 6163, 7253, 10831, 14,
? 77404, 3], dtype=int32),
def get_batch_data_iterator(data_path, batch_size=64, shuffle=True):
data_iter = get_data_iterator(data_path)
while True:
data_list = []
for _ in range(batch_size):
data = https://www.cnblogs.com/zhangsheng377/archive/2021/03/08/next(data_iter)
data_list.append(data)
if shuffle:
random.shuffle(data_list)
pad_sequences_list = []
label_index_list = []
for data in data_list:
pad_sequences, label_index = data
pad_sequences_list.append(pad_sequences.tolist())
label_index_list.append(label_index)
yield np.array(pad_sequences_list), np.array(label_index_list)
it = get_batch_data_iterator(r"data/keras_bert_train.txt", batch_size=1)
next(it)
(array([[ 69, 2160, 57, 3010, 55, 828, 68, 1028,
? 456, 3712, 2130, 1, 36, 116604, 361, 7019,
? 377, 26, 8, 76, 539, 1, 346, 7323,
? 89885, 7019, 73, 7, 55, 84, 3, 33,
? 3199, 69, 579, 1366, 2, 1526, 26, 89,
? 456, 5741, 8256, 1, 6163, 7253, 10831, 14,
? 77404, 3]]),
array([0]))
it = get_batch_data_iterator(r"data/keras_bert_train.txt", batch_size=1)
next(it)
(array([[ 5, 5013, 14313, 601, 15377, 23499, 13, 493,
? 1541, 247, 5, 35557, 21529, 15377, 5, 1764,
? 11, 2774, 15377, 5, 279, 1764, 430, 5,
? 4742, 36921, 24090, 6387, 23499, 13, 5013, 8319,
? 6387, 5, 2370, 1764, 6387, 5, 16122, 1764,
? 6387, 5, 14313, 3707, 6387, 5, 11, 2774,
? 247, 6387],
? [ 69, 2160, 57, 3010, 55, 828, 68, 1028,
? 456, 3712, 2130, 1, 36, 116604, 361, 7019,
? 377, 26, 8, 76, 539, 1, 346, 7323,
? 89885, 7019, 73, 7, 55, 84, 3, 33,
? 3199, 69, 579, 1366, 2, 1526, 26, 89,
? 456, 5741, 8256, 1, 6163, 7253, 10831, 14,
? 77404, 3]]),
array([0, 0]))
定義 基礎版CNN
def get_model():
K.clear_session()
model = Sequential()
model.add(Embedding(len(vocab) + 1, 300, input_length=50)) #使用Embeeding層將每個詞編碼轉換為詞向量
model.add(Conv1D(256, 5, padding='same'))
model.add(MaxPooling1D(3, 3, padding='same'))
model.add(Conv1D(128, 5, padding='same'))
model.add(MaxPooling1D(3, 3, padding='same'))
model.add(Conv1D(64, 3, padding='same'))
model.add(Flatten())
model.add(Dropout(0.1))
model.add(BatchNormalization()) # (批)規范化層
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.1))
model.add(Dense(3, activation='softmax'))
model.compile(loss='sparse_categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
print(model.summary())
return model
early_stopping = EarlyStopping(monitor='val_acc', patience=3) #早停法,防止過擬合
plateau = ReduceLROnPlateau(monitor="val_acc", verbose=1, mode='max', factor=0.5, patience=2) #當評價指標不在提升時,減少學習率
# checkpoint = ModelCheckpoint('trained_model/keras_bert_THUCNews.hdf5', monitor='val_acc',verbose=2, save_best_only=True, mode='max', save_weights_only=True) #保存最好的模型
def get_step(sample_count, batch_size):
step = sample_count // batch_size
if sample_count % batch_size != 0:
step += 1
return step
batch_size = 8
train_step = get_step(train_sample_count, batch_size)
dev_step = get_step(dev_sample_count, batch_size)
train_dataset_iterator = get_batch_data_iterator(r"data/keras_bert_train.txt", batch_size)
dev_dataset_iterator = get_batch_data_iterator(r"data/keras_bert_dev.txt", batch_size)
model = get_model()
#模型訓練
model.fit(
train_dataset_iterator,
steps_per_epoch=train_step,
epochs=10,
validation_data=https://www.cnblogs.com/zhangsheng377/archive/2021/03/08/dev_dataset_iterator,
validation_steps=dev_step,
callbacks=[early_stopping, plateau],
verbose=1
)
Model: "sequential"
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 50, 300) 454574700
conv1d (Conv1D) (None, 50, 256) 384256
max_pooling1d (MaxPooling1D) (None, 17, 256) 0
conv1d_1 (Conv1D) (None, 17, 128) 163968
max_pooling1d_1 (MaxPooling1 (None, 6, 128) 0
conv1d_2 (Conv1D) (None, 6, 64) 24640
flatten (Flatten) (None, 384) 0
dropout (Dropout) (None, 384) 0
batch_normalization (BatchNo (None, 384) 1536
dense (Dense) (None, 256) 98560
dropout_1 (Dropout) (None, 256) 0
dense_1 (Dense) (None, 3) 771
=================================================================
Total params: 455,248,431
Trainable params: 455,247,663
Non-trainable params: 768
None
Epoch 1/10
? 1/83608 [..............................] - ETA: 3:28 - loss: 1.1427 - accuracy: 0.3750
定義 簡單版TextCNN
def get_model():
K.clear_session()
main_input = Input(shape=(50,), dtype='float64')
# 詞嵌入(使用預訓練的詞向量)
embedder = Embedding(len(vocab) + 1, 300, input_length=50, trainable=False)
embed = embedder(main_input)
# 詞窗大小分別為3,4,5
cnn1 = Conv1D(256, 3, padding='same', strides=1, activation='relu')(embed)
cnn1 = MaxPooling1D(pool_size=48)(cnn1)
cnn2 = Conv1D(256, 4, padding='same', strides=1, activation='relu')(embed)
cnn2 = MaxPooling1D(pool_size=47)(cnn2)
cnn3 = Conv1D(256, 5, padding='same', strides=1, activation='relu')(embed)
cnn3 = MaxPooling1D(pool_size=46)(cnn3)
# 合并三個模型的輸出向量
cnn = concatenate([cnn1, cnn2, cnn3], axis=-1)
flat = Flatten()(cnn)
drop = Dropout(0.2)(flat)
main_output = Dense(3, activation='softmax')(drop)
model = Model(inputs=main_input, outputs=main_output)
model.compile(loss='sparse_categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
print(model.summary())
return model
batch_size = 8
train_step = get_step(train_sample_count, batch_size)
dev_step = get_step(dev_sample_count, batch_size)
train_dataset_iterator = get_batch_data_iterator(r"data/keras_bert_train.txt", batch_size)
dev_dataset_iterator = get_batch_data_iterator(r"data/keras_bert_dev.txt", batch_size)
model = get_model()
#模型訓練
model.fit(
train_dataset_iterator,
steps_per_epoch=train_step,
epochs=10,
validation_data=https://www.cnblogs.com/zhangsheng377/archive/2021/03/08/dev_dataset_iterator,
validation_steps=dev_step,
callbacks=[early_stopping, plateau],
verbose=1
)
Model: "functional_1"
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 50)] 0
embedding (Embedding) (None, 50, 300) 454574700 input_1[0][0]
conv1d (Conv1D) (None, 50, 256) 230656 embedding[0][0]
conv1d_1 (Conv1D) (None, 50, 256) 307456 embedding[0][0]
conv1d_2 (Conv1D) (None, 50, 256) 384256 embedding[0][0]
max_pooling1d (MaxPooling1D) (None, 1, 256) 0 conv1d[0][0]
max_pooling1d_1 (MaxPooling1D) (None, 1, 256) 0 conv1d_1[0][0]
max_pooling1d_2 (MaxPooling1D) (None, 1, 256) 0 conv1d_2[0][0]
concatenate (Concatenate) (None, 1, 768) 0 max_pooling1d[0][0]
? max_pooling1d_1[0][0]
? max_pooling1d_2[0][0]
flatten (Flatten) (None, 768) 0 concatenate[0][0]
dropout (Dropout) (None, 768) 0 flatten[0][0]
dense (Dense) (None, 3) 2307 dropout[0][0]
==================================================================================================
Total params: 455,499,375
Trainable params: 924,675
Non-trainable params: 454,574,700
None
Epoch 1/10
238/83608 [..............................] - ETA: 2:31:07 - loss: 0.0308 - accuracy: 0.9979
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/267338.html
標籤:其他
上一篇:大資料實戰-Spark實戰技巧
下一篇:新汽車電子技術圖譜