目錄
- 一、GlusterFS簡介
- 1、GlusterFS的概念
- 2、GlusterFS特點
- 3、GlusterFS術語
- 4、GlusterFS的模塊化堆疊式架構
- 5、GlusterFS的作業流程
- 6、后端存盤如何定位檔案
- 7、GFS支持的七種卷
- (1)分布式卷(默認)
- (2)條帶卷(默認)
- (3)復制卷(Replica volume)
- (4)分布式條帶卷(Distribute Stripe volume)
- (5)分布式復制卷(Distribute Replica volume)
- (6)條帶復制卷(Stripe Replca volume)
- (7)分布式條帶復制卷(Distribute Stripe Replicavolume)
- 二、相關維護命令
- 1、查看GlusterFS卷
- 2、查看所有卷的資訊
- 3、查看所有卷的狀態
- 4、停止一個卷
- 5、洗掉一個卷
- 6.設定卷的訪問控制
- 三、GFS部署
- 1、節點進行磁盤磁區、掛載
- 2、配置/etc/hosts檔案
- 3、安裝、啟動GlusterFS
- 4、添加節點創建集群
- 5、根據規劃創建卷
- (1)創建分布式卷
- (2)創建條帶卷
- (3)創建復制卷
- (4)創建分布式條帶卷
- (5)創建分布式復制卷
- 6、部署gluster客戶端
- 7、測驗 Gluster 檔案系統
- 7、查看檔案分布
- (1)查看分布式檔案分布
- (2)查看條帶卷檔案分布
- (3)查看復制卷檔案分布
- (4)查看分布式條帶卷分布
- (5)查看分布式復制卷分布
- 四、冗余測驗
- 1、分布式卷
- 2、條帶卷
- 3、分布式條帶卷
- 4、分布式復制卷
- 5、復制卷
- 總結
一、GlusterFS簡介
1、GlusterFS的概念
GlusterFS:分布式檔案系統
- 開源的分布式檔案系統
- 組成:
- 存盤服務器
- 客戶端
- NFS/Samba 存盤網關
- 無元資料服務器
- 資料分散存盤
- 可避免出現單點故障
補充:
FS(檔案系統)的作用:從系統角度來看,檔案系統是對檔案存盤設備的空間進行組織和分配,負責檔案存盤并對存入的檔案進行保護和檢索的系統,
具體地說,它負責為用戶建立檔案,存入、讀出、修改、轉儲檔案,控制檔案的存取
檔案系統組成:
1)檔案系統介面
2)對對像管理的軟體集合
3)物件及屬性
2、GlusterFS特點
擴展性和高性能
GlusterFS利用雙重特性來提供高容量存盤解決方案,
(1)Scale-Out架構允許通過簡單地增加存盤節點的方式來提高存盤容量和性能(磁盤、計算和I/O資源都可以獨立增加),支持10GbE和 InfiniBand等高速網路互聯,
(2)Gluster彈性哈希(ElasticHash)解決了GlusterFS對元資料服務器的依賴,改善了單點故障和性能瓶頸,真正實作了并行化資料訪問,GlusterFS采用彈性哈希演算法在存盤池中可以智能地定位任意資料分片(將資料分片存盤在不同節點上),不需要查看索引或者向元資料服務器查詢,
高可用性
GlusterFS可以對檔案進行自動復制,如鏡像或多次復制,從而確保資料總是可以訪問,甚至是在硬體故障的情況下也能正常訪問,
當資料出現不一致時,自我修復功能能夠把資料恢復到正確的狀態,資料的修復是以增量的方式在后臺執行,幾乎不會產生性能負載,
GlusterFS可以支持所有的存盤,因為它沒有設計自己的私有資料檔案格式,而是采用作業系統中主流標準的磁盤檔案系統(如EXT3、XFS等)來存盤檔案,因此資料可以使用傳統訪問磁盤的方式被訪問,
全域統一命名空間
分布式存盤中,將所有節點的命名空間整合為統一命名空間,將整個系統的所有節點的存盤容量組成一個大的虛擬存盤池,供前端主機訪問這些節點完成資料讀寫操作,
彈性卷管理
GlusterFS通過將資料儲存在邏輯卷中,邏輯卷從邏輯存盤池進行獨立邏輯劃分而得到,
邏輯存盤池可以在線進行增加和移除,不會導致業務中斷,邏輯卷可以根據需求在線增長和縮減,并可以在多個節點中實作負載均衡,
檔案系統配置也可以實時在線進行更改并應用,從而可以適應作業負載條件變化或在線性能調優,
基于標準協議
Gluster 存盤服務支持 NFS、CIFS、HTTP、FTP、SMB 及 Gluster原生協議,完全與 POSIX 標準兼容,
現有應用程式不需要做任何修改就可以對Gluster 中的資料進行訪問,也可以使用專用 API 進行訪問,
3、GlusterFS術語
這里先補充一點等會要用的GlusterFS術語
- Brick(塊存盤):由主機提供的用于物理存盤的專用磁區,是GlusterFS中的基本存盤單元,同時也是可信存盤池中服務器上對外提供的存盤目錄,
- Volume(邏輯卷):一個邏輯卷是一組 Brick 的集合,卷是資料存盤的邏輯設備,類似于 LVM 中的邏輯卷,大部分 Gluster 管理操作是在卷上進行的,
- FUSE:用戶空間的檔案系統(類別EXT4),”這是一個偽檔案系統“,用戶端的交換模塊
- VFS(虛擬埠):內核態的虛擬檔案系統,用戶是提交請求給VFS 然后VFS交給FUSH,再交給GFS客戶端,最后由客戶端交給遠端的存盤
- Glusterd(服務):是運行再存盤節點的行程(客戶端運行的是gluster client)GFS使用程序中整個GFS之間的交換由Gluster client 和glusterd完成
4、GlusterFS的模塊化堆疊式架構
- 模塊化、堆疊式的架構
- 模塊化:每個模塊可以提供不同的功能
- 堆疊式:同時啟用多個模塊,多個功能可以組合,實作復雜的功能
- 通過對模塊的組合,實作復雜的功能
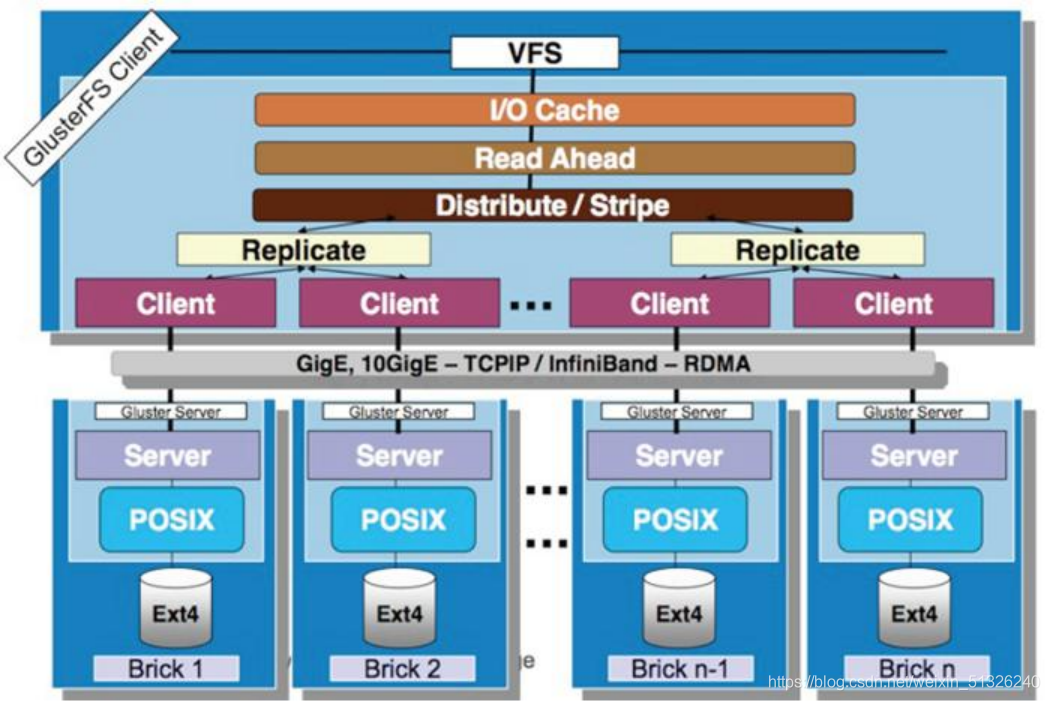
GlusterFS Client客戶端
VFS(虛擬檔案系統):為各類檔案系統提供了一個統一的操作界面和應用編程介面
I/O cache(I/O快取,Input/Output):用于資料在內部存盤器和外部存盤器或其他周邊設備之間的輸入和輸出,
read ahead(內核檔案預讀)
Distribute/Stripe:分布式、條帶化
replicate:復制功能
網路層
Gige(千兆網/千兆介面)
TCP/IP(網路協議)
InfiniBand(網路協議):與TCP/IP相比,TCP/IP具有轉發丟失資料包的特性,基于此通信協議可能導致通信變慢,而IB使用基于信任的、流控制的機制來保證連接完整性
RDMA(Remote Direct Memory Access,遠程直接資料存取)負責資料傳輸,功能:為了解決傳輸程序中客戶端與服務器端資料處理的延遲
Server服務端
posix(可移植作業系統介面):解決客戶端與服務端系統兼容性問題
Brick:塊存盤
總結
1、GlusterFS采用模塊化、堆疊式的架構,可通過靈活的配置支持高度定制化的應用環境,比方大檔案存盤、海量小檔案存盤、云存盤、多傳輸協議應用等,
2、每一個功能以模塊形式實作,然后以積木方式進行簡單的組合,就可以實作復雜的功能,比方,Replicate模塊可實作RAID1,Stripe模塊可實作RAID0,通過兩者的組合可實作RAID10和RAID01,同一時候獲得高性能和高可靠性,
3、然后以請求的方式與客戶端進行互動,客戶端與服務端進行互動時,通過posix來解決出現的系統兼容性問題,讓客戶端的命令通過posix過濾后可以在服務端執行
5、GlusterFS的作業流程
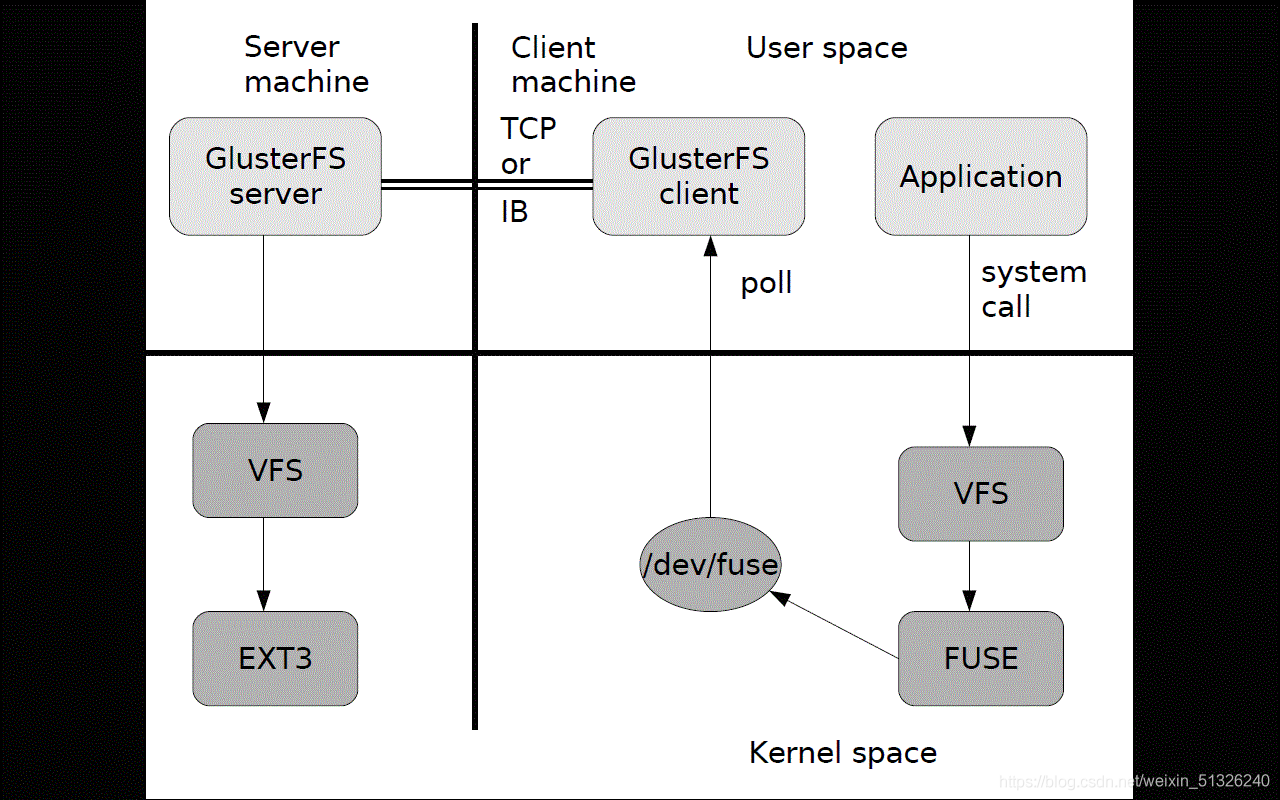
例如
1、外來一個請求,例:用戶端申請創建一個檔案,客戶端或應用程式通過GFS的掛載點訪問資料
2、linux系統內容通過VFSAPI收到請求并處理
3、VFS將資料遞交給FUSE內核檔案系統,fuse檔案系統則是將資料通過/dev/fuse設備檔案遞交給了GlusterFS client端
4、GlusterFS client端收到資料后,會根據組態檔的配置對資料進行處理
5、再通過網路,將資料發送給遠端的ClusterFS server,并將資料寫入到服務器儲存設備上
6、server再將資料轉交給VFS偽檔案系統,再由VFS進行轉存處理,最后交給EXT3
6、后端存盤如何定位檔案
使用彈性HASH演算法
為了解決分布式檔案資料索引、定位的復雜程度,而使用彈性HASH演算法來解決資料定位、索引、尋址的功能
- 先通過HASH演算法對資料可以得到一個值
- 該值有2的32次方個組合
- 每個資料對應了0-2的32次方的一個值
- 通常情況下,不同資料得到的值是不同的
彈性 HASH 演算法的優點
- 保證資料平均分布在每一個 Brick 中,
- 解決了對元資料服務器的依賴,進而解決了單點故障以及訪問瓶頸,
7、GFS支持的七種卷
(1)分布式卷(默認)
檔案通過HASH演算法分布到所有Brick Server上,這種卷是GFS的基礎;檔案沒有被分片,直接根據HASH演算法散列到不同的Brick,其實只是擴大了磁盤空間,并不具備容錯能力,屬于檔案級RAID 0
分布式卷的特點
- 檔案分布在不同的服務器,不具備冗余性
- 更容易和廉價地擴展卷的大小
- 單點故障會造成資料丟失
- 依賴底層的資料保護
創建命令
- 創建一個名為dis-volume的分布式卷,檔案將根據HASH分布在server1:/dir1、server2:/dir2和server3:/dir3中
gluster volume create dis-volume server1:/dir1 server2:/dir2
(2)條帶卷(默認)
類似RAID 0,檔案被分成資料庫并以輪詢的方式分布到多個Brick Server上,檔案存盤以資料塊為單位,支持大檔案存盤,檔案越大,讀取效率越高
條帶卷特點
- 資料被分割成更小塊分布到塊服務器群中的不同條帶區
- 分布減少了負載且更小的檔案加速了存取的速度
- 沒有資料冗余
創建命令
- 創建了一個名為Stripe-volume的條帶卷,檔案將被分塊輪詢的存盤在Server1:/dir1和Server2:/dir2兩個Brick
gluster volume create stripe-volume stripe 2 transport tcp server1:/dir1 server2:/dir2
(3)復制卷(Replica volume)
將檔案同步到多個Brick上,使其具備多個檔案副本,屬于檔案級RAID 1,具有容錯能力,因為資料分散在多個Brick中,所以讀性能得到很大提升,但寫性能下降
復制卷特點
- 卷中所有的服務器均保存一個完整的副本
- 卷的副本數量可由客戶創建的時候決定
- 至少由兩個塊服務器或更多服務器
- 具備冗余性
創建命令
#創建名為rep-volume的復制卷,檔案將同時存盤兩個副本,分別在Server1:/dir1和Server2:/dir2兩個Brick中
gluster volume create rep-volume replica 2 transport tcp server1:/dir1 server2:/dir2
(4)分布式條帶卷(Distribute Stripe volume)
Brick Server數量是條帶數(資料塊分布的Brick數量)的倍數
兼具分布式卷和條帶的特點
創建命令
- 創建了一個名為dis-stripe的分布式條帶卷,配置分布式的條帶卷時,卷中Brick所包含的存盤服務器數必須是條帶數的倍數(>=2倍)
gluster volume create rep-volume replica 2 transport tcp server1:/dir1 server2:/dir2
(5)分布式復制卷(Distribute Replica volume)
Brick Server數量是鏡像數(資料副本 數量)的倍數
兼具分布式卷和復制卷的特點
創建命令
- 創建了一個名為dis-rep的分布式條帶卷,配置分布式的復制卷時,卷中Brick所包含的存盤服務器數必須是復制數的倍數(>=2倍)
gluster volume create rep-volume replica 2 transport tcp server1:/dir1 server2:/dir2 server3:/dir3 server4:/dir4
(6)條帶復制卷(Stripe Replca volume)
類似RAID 10,同時具有條帶卷和復制卷的特點
(7)分布式條帶復制卷(Distribute Stripe Replicavolume)
三種基本卷的復合卷通常用于類Map Reduce應用
二、相關維護命令
1、查看GlusterFS卷
gluster volume list
2、查看所有卷的資訊
gluster volume info
3、查看所有卷的狀態
gluster volume status
4、停止一個卷
gluster volume stop dis-stripe
5、洗掉一個卷
注意:洗掉卷時,需要先停止卷,且信任池中不能有主機處于宕機狀態,否則洗掉不成功
gluster volume delete dis-stripe
6.設定卷的訪問控制
僅拒絕
gluster volume set dis-rep auth.allow 192.168.163.100
僅允許
gluster volume set dis-rep auth.allow 192.168.163.* #設定192.168.163.0網段的所有IP地址都能訪問dis-rep卷(分布式復制卷)
三、GFS部署
gfsrepo.zip
相關軟體包
集群環境準備
| 節點名稱 | ip地址 | 磁盤 | 掛載點 |
|---|---|---|---|
| Node1節點 | 192.168.163.11 | /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 | /data/sdb1 /data/sdc1 /data/sdd1 /data/sde1 |
| Node2節點 | 192.168.163.12 | /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 | /data/sdb1 /data/sdc1 /data/sdd1 /data/sde1 |
| Node3節點 | 192.168.163.13 | /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 | /data/sdb1 /data/sdc1 /data/sdd1 /data/sde1 |
| Node4節點 | 192.168.163.14 | /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 | /data/sdb1 /data/sdc1 /data/sdd1 /data/sde1 |
| 客戶端 | 192.168.163.15 |
所有節點更改名稱,方便識別
關防火墻(所有節點和客戶端)
systemctl stop firewalld
setenforce 0

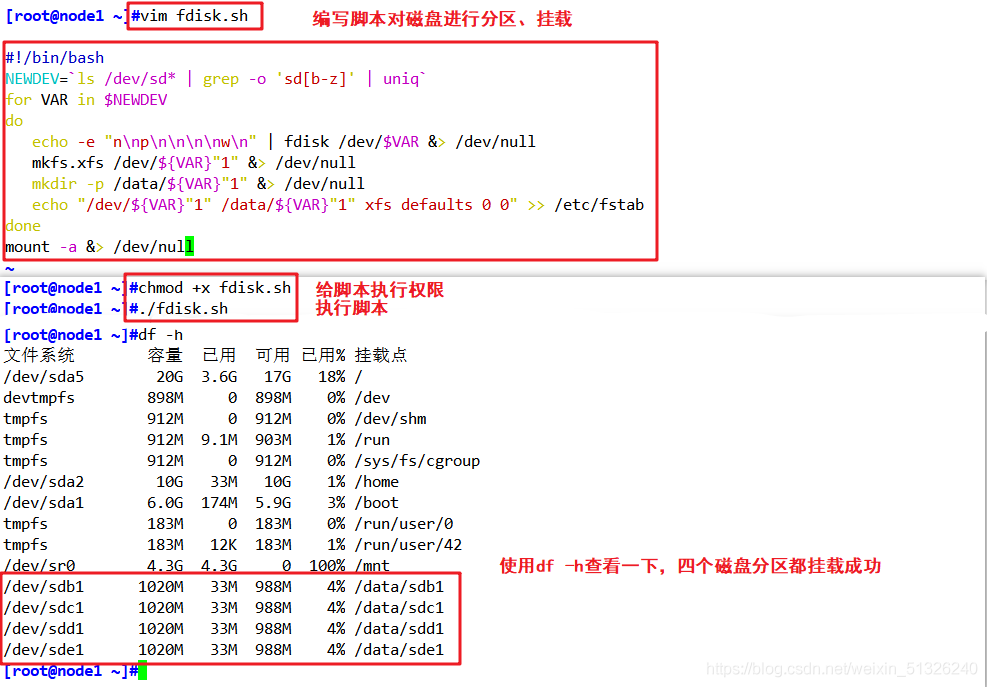
1、節點進行磁盤磁區、掛載
Node1節點:192.168.163.11
Node2節點:192.168.163.12
Node3節點:192.168.163.13
Node4節點:192.168.163.14
這里使用node1作為示范,用腳本對磁盤進行操作
vim fdisk.sh
#!/bin/bash
NEWDEV=`ls /dev/sd* | grep -o 'sd[b-z]' | uniq`
for VAR in $NEWDEV
do
echo -e "n\np\n\n\n\nw\n" | fdisk /dev/$VAR &> /dev/null
mkfs.xfs /dev/${VAR}"1" &> /dev/null
mkdir -p /data/${VAR}"1" &> /dev/null
echo "/dev/${VAR}"1" /data/${VAR}"1" xfs defaults 0 0" >> /etc/fstab
done
mount -a &> /dev/null
chmod +x fdisk.sh
./fdisk.sh
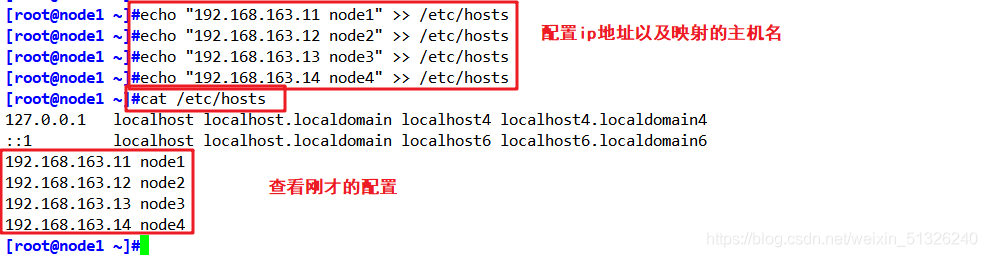
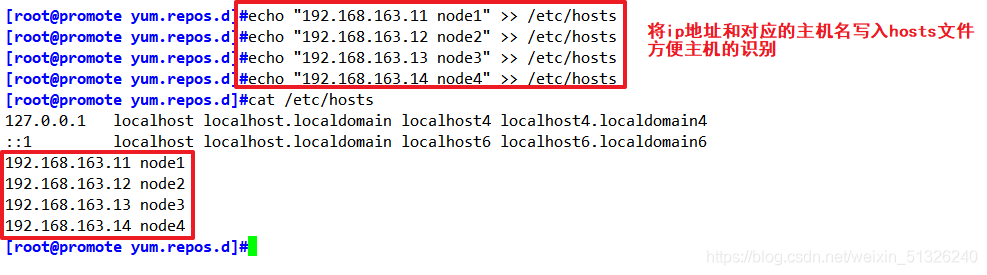
2、配置/etc/hosts檔案
Node1節點:192.168.163.11
Node2節點:192.168.163.12
Node3節點:192.168.163.13
Node4節點:192.168.163.14
使用node1作為示范
echo "192.168.163.11 node1" >> /etc/hosts
echo "192.168.163.12 node2" >> /etc/hosts
echo "192.168.163.13 node3" >> /etc/hosts
echo "192.168.163.14 node4" >> /etc/hosts
3、安裝、啟動GlusterFS
Node1節點:192.168.163.11
Node2節點:192.168.163.12
Node3節點:192.168.163.13
Node4節點:192.168.163.14
使用node1作為示范
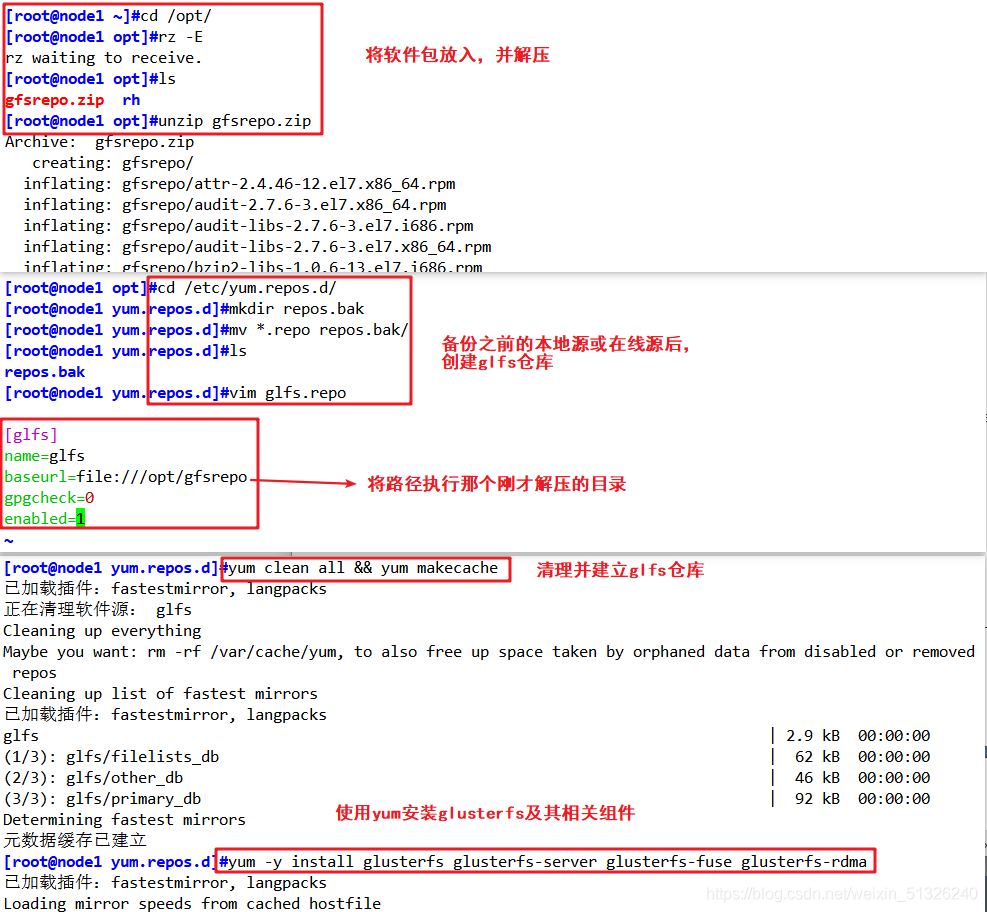
#將軟體包放入opt目錄下
cd /opt
unzip gfsrepo.zip
cd /etc/yum.repos.d/
mkdir repos.bak
mv * repos.bak/
vim glfs.repo
[glfs]
name=glfs
baseurl=file:///opt/gfsrepo
gpgcheck=0
enabled=1
yum clean all && yum makecache
yum -y install glusterfs glusterfs-server glusterfs-fuse glusterfs-rdma
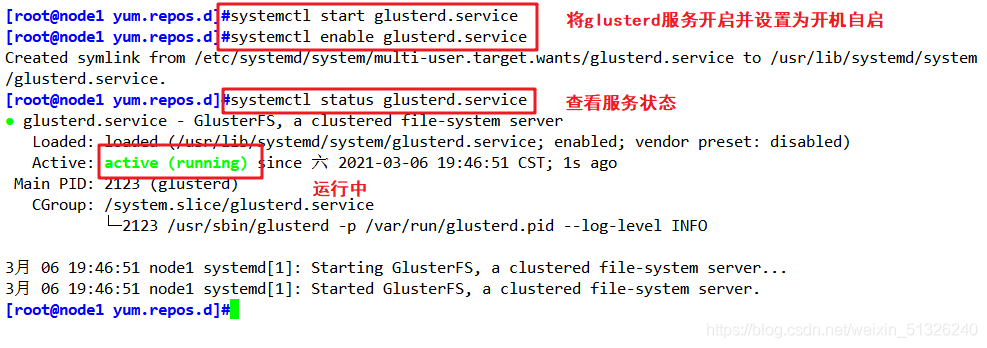
systemctl start glusterd.service
systemctl enable glusterd.service
systemctl status glusterd.service
4、添加節點創建集群
Node1節點:192.168.163.11
添加節點到存盤信任池中
gluster peer probe node1
gluster peer probe node2
gluster peer probe node3
gluster peer probe node4
#查看群集狀態(可以在每個節點上使用)
gluster peer status

5、根據規劃創建卷
創建卷只需要在一臺節點上創建即可
根據以下規劃創建卷:
| 卷名稱 | 卷型別 | Brick |
|---|---|---|
| dis-volume | 分布式卷 | node1(/data/sdb1)、node2(/data/sdb1) |
| stripe-volume | 條帶卷 | node1(/data/sdc1)、node2(/data/sdc1) |
| rep-volume | 復制卷 | node3(/data/sdb1)、node4(/data/sdb1) |
| dis-stripe | 分布式條帶卷 | node1(/data/sdd1)、node2(/data/sdd1)、node3(/data/sdd1)、node4(/data/sdd1) |
| dis-rep | 分布式復制卷 | node1(/data/sde1)、node2(/data/sde1)、node3(/data/sde1)、node4(/data/sde1) |
(1)創建分布式卷
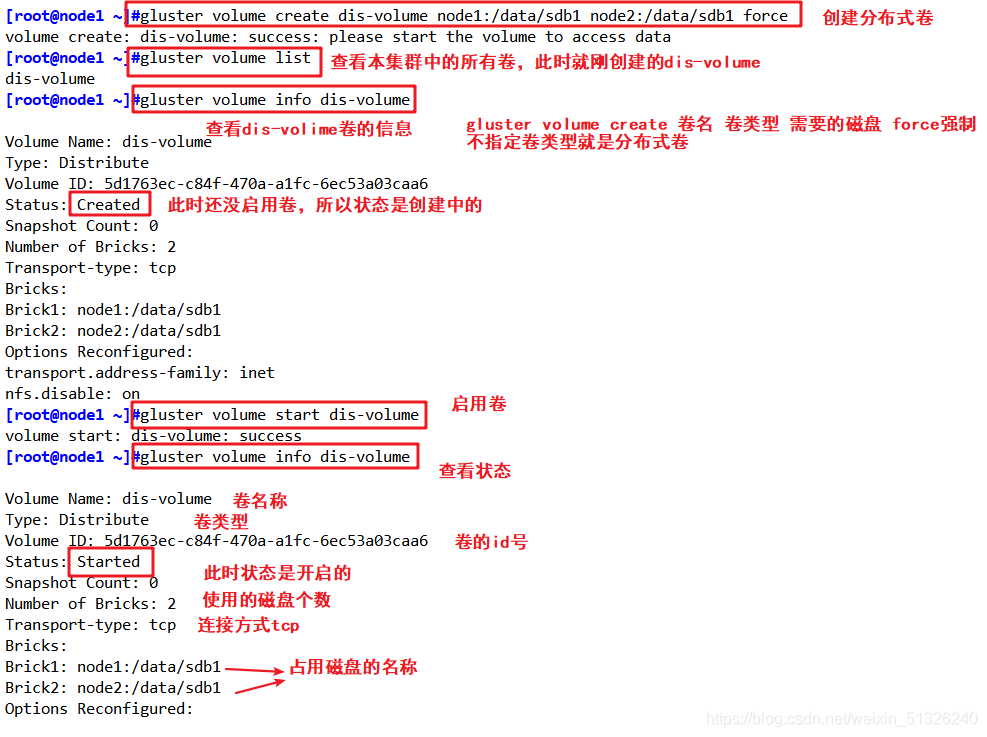
創建分布式卷,沒有指定型別,默認創建的是分布式卷
創建分布式卷
gluster volume create dis-volume node1:/data/sdb1 node2:/data/sdb1 force
查看卷串列
gluster volume list
啟動新建分布式卷
gluster volume start dis-volume
查看創建分布式卷資訊
gluster volume info dis-volume
(2)創建條帶卷
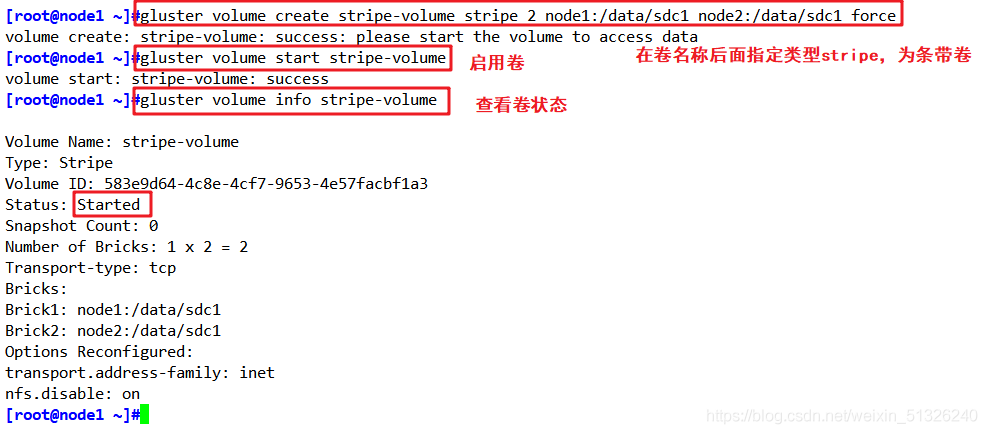
指定型別為 stripe,數值為 2,且后面跟了 2 個 Brick Server,所以創建的是條帶卷
創建條帶卷
gluster volume create stripe-volume stripe 2 node1:/data/sdc1 node2:/data/sdc1 force
啟動新建條帶卷
gluster volume start stripe-volume
查看創建條帶卷資訊
gluster volume info stripe-volume
(3)創建復制卷
指定型別為 replica,數值為 2,且后面跟了 2 個 Brick Server,所以創建的是復制卷
創建復制卷
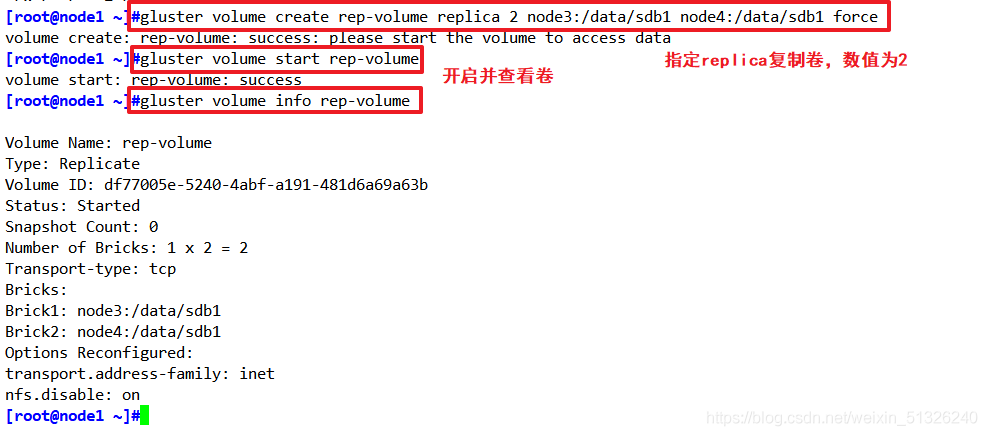
gluster volume create rep-volume replica 2 node3:/data/sdb1 node4:/data/sdb1 force
啟動新建復制卷
gluster volume start rep-volume
查看創建復制卷資訊
gluster volume info rep-volume
(4)創建分布式條帶卷
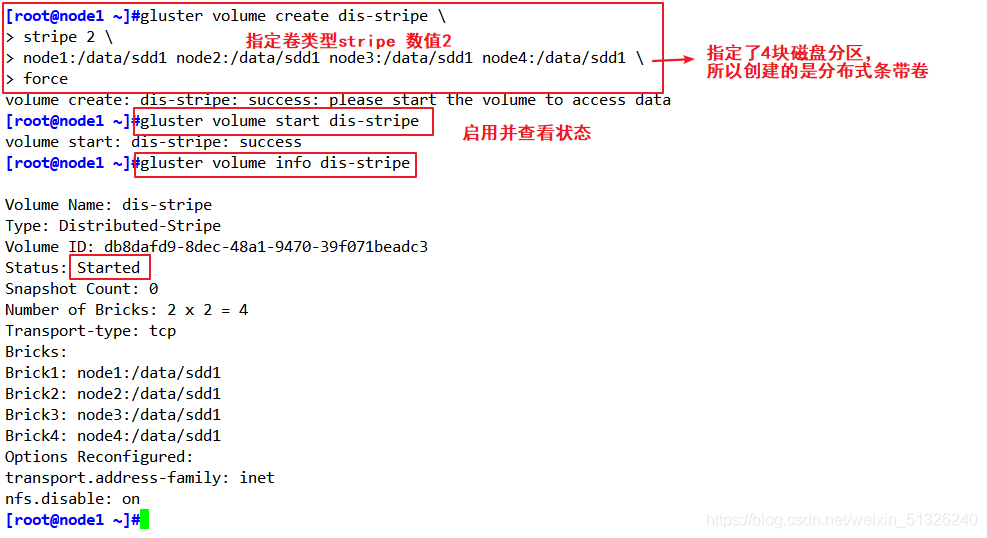
指定型別為 stripe,數值為 2,而且后面跟了 4 個 Brick Server,是 2 的兩倍,所以創建的是分布式條帶卷
創建分布式條帶卷
gluster volume create dis-stripe stripe 2 node1:/data/sdd1 node2:/data/sdd1 node3:/data/sdd1 node4:/data/sdd1 force
啟動新建分布式條帶卷
gluster volume start dis-stripe
查看創建分布式條帶卷資訊
gluster volume info dis-stripe
(5)創建分布式復制卷
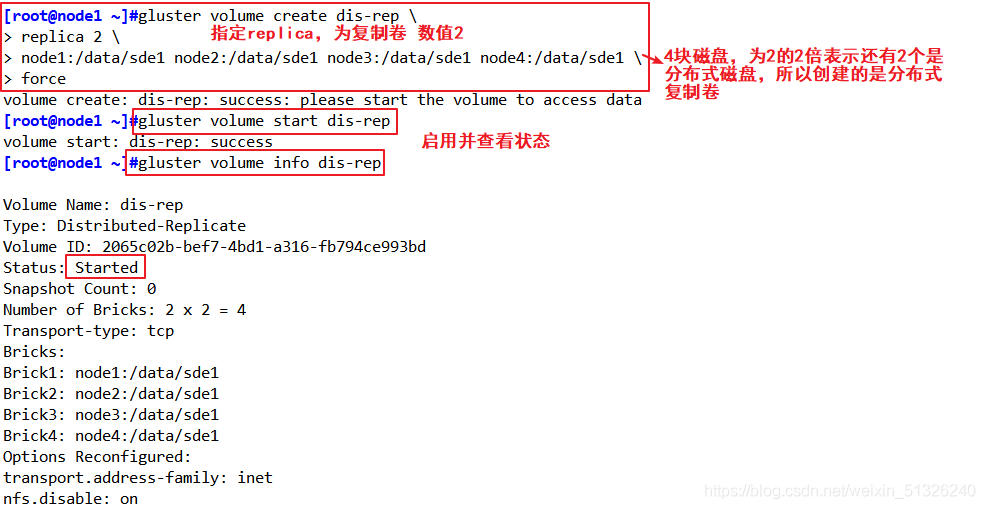
指定型別為 replica,數值為 2,而且后面跟了 4 個 Brick Server,是 2 的兩倍,所以創建的是分布式復制卷
創建分布式復制卷
gluster volume create dis-rep replica 2 node1:/data/sde1 node2:/data/sde1 node3:/data/sde1 node4:/data/sde1 force
啟動新建分布式復制卷
gluster volume start dis-rep
查看創建分布式復制卷資訊
gluster volume info dis-rep
查看卷串列
gluster volume list

6、部署gluster客戶端
部署Gluster客戶端(192.168.163.15)
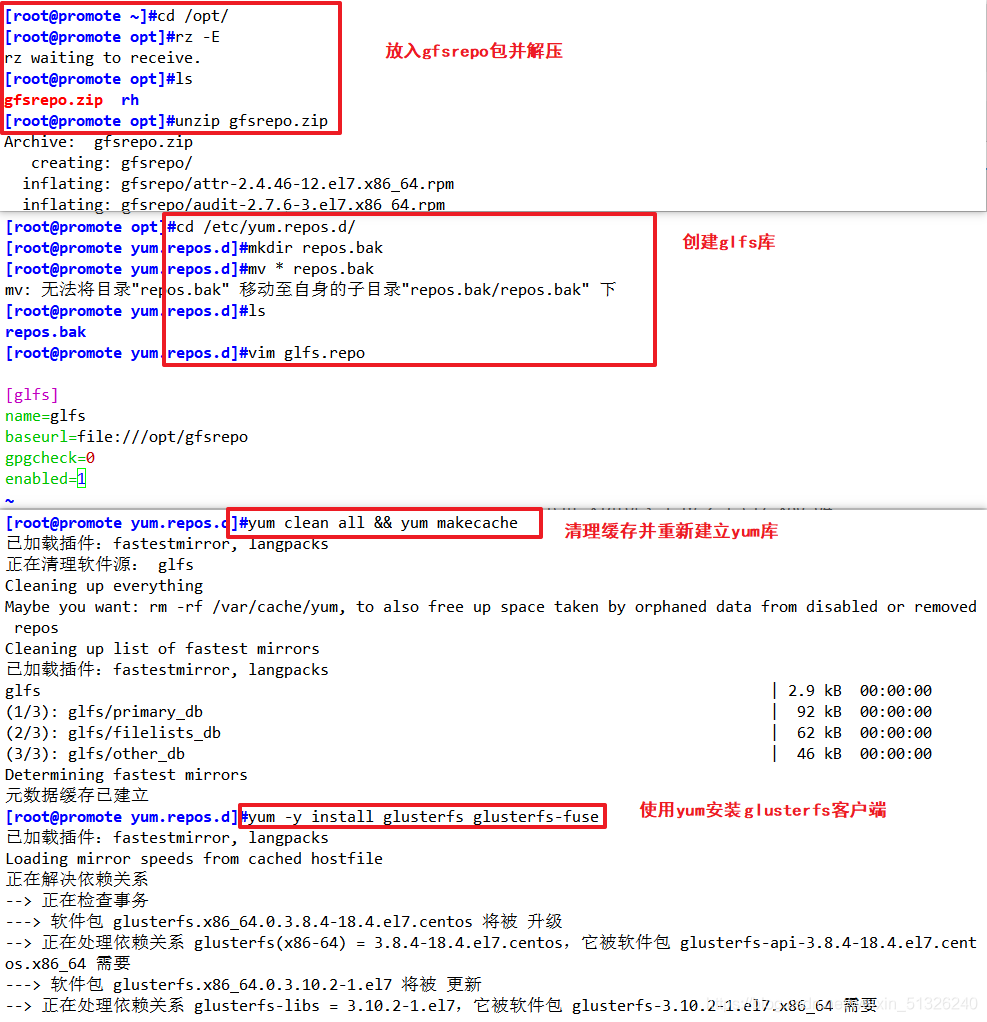
(1)安裝客戶端軟體
cd /opt
unzip gfsrepo.zip
cd /etc/yum.repos.d/
mkdir repos.bak
mv * repos.bak/
vim glfs.repo
[glfs]
name=glfs
baseurl=file:///opt/gfsrepo
gpgcheck=0
enabled=1
yum clean all && yum makecache
yum -y install glusterfs glusterfs-fuse
(2)配置 /etc/hosts 檔案
echo "192.168.163.11 node1" >> /etc/hosts
echo "192.168.163.12 node2" >> /etc/hosts
echo "192.168.163.13 node3" >> /etc/hosts
echo "192.168.163.14 node4" >> /etc/hosts
(3)創建掛載目錄
mkdir -p /test/{dis,stripe,rep,dis_stripe,dis_rep}

(4)掛載 Gluster 檔案系統
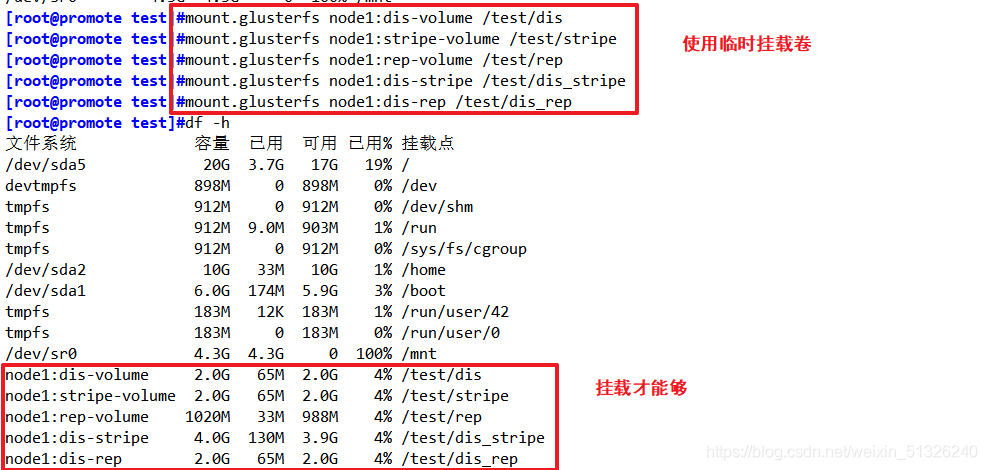
- 臨時掛載
mount.glusterfs node1:dis-volume /test/dis
mount.glusterfs node1:stripe-volume /test/stripe
mount.glusterfs node1:rep-volume /test/rep
mount.glusterfs node1:dis-stripe /test/dis_stripe
mount.glusterfs node1:dis-rep /test/dis_rep
df -h
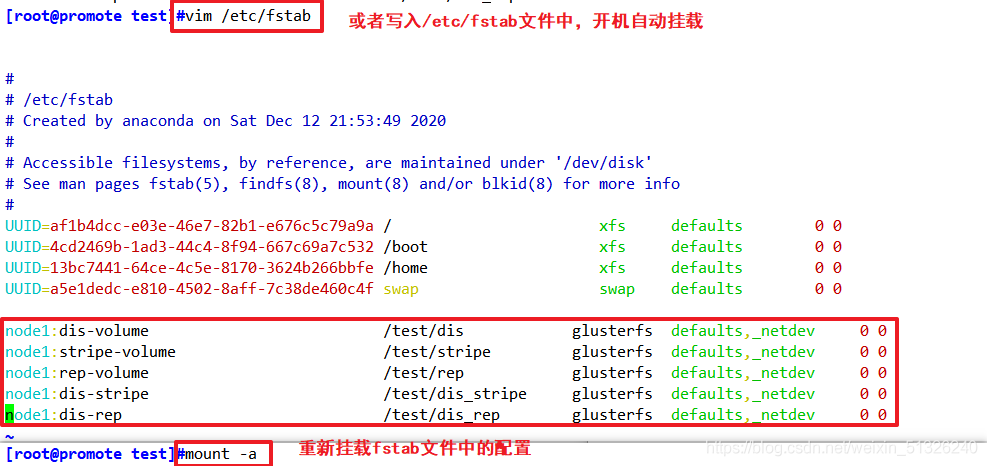
- 企業中最好用永久掛載,以防重啟或服務器宕機
vim /etc/fstab
node1:dis-volume /test/dis glusterfs defaults,_netdev 0 0
node1:stripe-volume /test/stripe glusterfs defaults,_netdev 0 0
node1:rep-volume /test/rep glusterfs defaults,_netdev 0 0
node1:dis-stripe /test/dis_stripe glusterfs defaults,_netdev 0 0
node1:dis-rep /test/dis_rep glusterfs defaults,_netdev 0 0
mount -a
7、測驗 Gluster 檔案系統
部署Gluster客戶端(192.168.163.15)
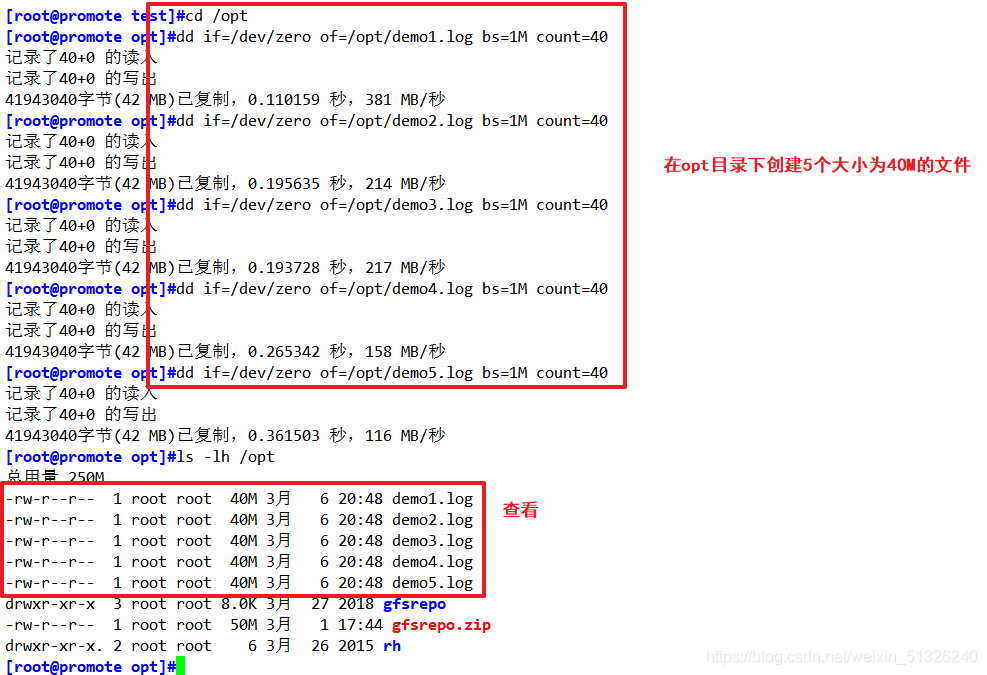
向卷中寫入檔案
cd /opt
dd if=/dev/zero of=/opt/demo1.log bs=1M count=40
dd if=/dev/zero of=/opt/demo2.log bs=1M count=40
dd if=/dev/zero of=/opt/demo3.log bs=1M count=40
dd if=/dev/zero of=/opt/demo4.log bs=1M count=40
dd if=/dev/zero of=/opt/demo5.log bs=1M count=40
ls -lh /opt
cp demo* /test/dis
cp demo* /test/stripe/
cp demo* /test/rep/
cp demo* /test/dis_stripe/
cp demo* /test/dis_rep/

7、查看檔案分布
查看卷對應的磁盤磁區中的檔案資料,驗證結果
(1)查看分布式檔案分布
node1:/dev/sdb1
ll -h /data/sdb1

node2:/dev/sdb1
ll -h /data/sdb1
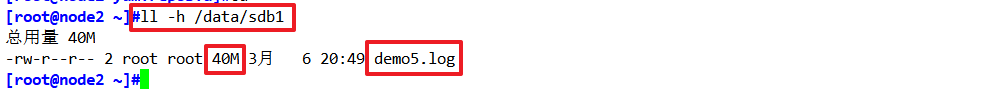
現象:分布式只會將demo檔案分開存盤(5個檔案不在同一磁盤磁區上),不會將資料分片和備份
(2)查看條帶卷檔案分布
node1:/dev/sdc1
ll -h /data/sdc1

node2:/dev/sdc1
ll -h /data/sdc1

現象:條帶卷會將每個demo檔案中的資料分片存盤(兩個磁區各有20M的檔案),沒有備份
(3)查看復制卷檔案分布
node3:/dev/sdb1
ll -h /data/sdb1

node4:/dev/sdb1
ll -h /data/sdb1

現象:復制卷會將每個檔案放入卷中的磁盤磁區中(兩磁區的檔案一樣)
(4)查看分布式條帶卷分布
node1:/dev/sdd1
ll -h /data/sdd1

node2:/dev/sdd1
ll -h /data/sdd1

node3:/dev/sdd1
ll -h /data/sdd1

node4:/dev/sdd1
ll -h /data/sdd1

現象:分布式條帶卷中,帶有分布式和條帶卷的特點,即將資料分片,又將檔案分開存盤,沒有備份
(5)查看分布式復制卷分布
node1:/dev/sde1
ll -h /data/sde1

node2:/dev/sde1
ll -h /data/sde1

node3:/dev/sde1
ll -h /data/sde1

node4:/dev/sde1
ll -h /data/sde1

現象:分布式復制卷中,帶有分布式和復制卷的特點,即將檔案分開存盤,又復制一遍檔案(備份)
四、冗余測驗
掛起 node2 節點或者關閉glusterd服務來模擬故障
systemctl stop glusterd.service

在客戶端(192.168.163.15)上查看檔案是否正常
1、分布式卷
ls -lh /test/dis
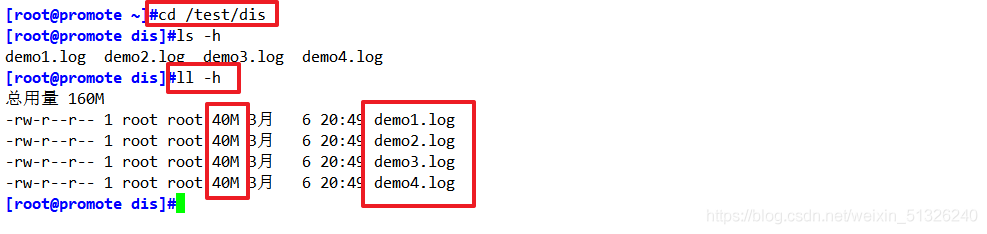
結論:資料查看,缺少demo5,檔案demo5是存盤在node2上的,所以分布式卷不具備冗余
2、條帶卷
ls -lh /test/stripe/

結論:檔案中沒有資料,說明資料全部丟失,所以條帶卷不具備冗余
3、分布式條帶卷
ls -lh /test/dis_stripe/

結論:存盤在node1和node2上的4個檔案不見了(資料是分片存盤的),所以分布式條帶卷不具備冗余
4、分布式復制卷
ls -lh /test/dis_rep/

結論:檔案和資料都在,所以分布式復制卷具有冗余
5、復制卷
在node3和node4中選一個關閉的,關閉node4(192.168.163.14)進行測驗,
具有冗余
ls -lh /test/rep/

結論:檔案和資料都在,所以復制卷具有冗余
總結
分布式卷:屬于檔案級的RAID0,不具備容錯能力,如果有一塊磁盤損壞,資料就丟失
條帶卷:類似RAID0,檔案將被分成資料塊并以輪詢方式分布到Brick server上
復制卷:將檔案同步到多個Brick上,屬于檔案RAID1,資料分數在多個Brick中
分布式條帶卷:Brick server 數量是條帶數兼具分布式卷和條帶卷的特定
分布式復制卷:Brick server數量是鏡像數,兼具分布式卷和復制卷的特點
條帶復制卷:類似RAID10,同時具有條帶卷和復制卷的特點
分布式條帶復制卷:三種基本卷的集合
在企業中資料的安全性是非常重要的,不具備冗余的卷是不會被企業所接受,所以使用頻率較高的就是冗余性好的幾種,例如本章講的復制卷、分布式復制卷,還有沒講的條帶復制卷和分布式條帶復制卷了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/267461.html
標籤:其他