目錄
- 前言
- 論文思想
- 網路詳細結構
- MBConv結構
- EfficientNet(B0-B7)引數
前言
原論文名稱:EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
論文下載地址:https://arxiv.org/abs/1905.11946
原論文提供代碼:https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
自己使用Pytorch實作的代碼: pytorch_classification/Test9_efficientNet
自己使用Tensorflow實作的代碼: tensorflow_classification/Test9_efficientNet
在之前的一些手工設計網路中(AlexNet,VGG,ResNet等等)經常有人問,為什么輸入影像解析度要固定為224,為什么卷積的個數要設定為這個值,為什么網路的深度設為這么深?這些問題你要問設計作者的話,估計回復就四個字——工程經驗,而這篇論文主要是用NAS(Neural Architecture Search)技術來搜索網路的影像輸入解析度
r
r
r,網路的深度
d
e
p
t
h
depth
depth以及channel的寬度
w
i
d
t
h
width
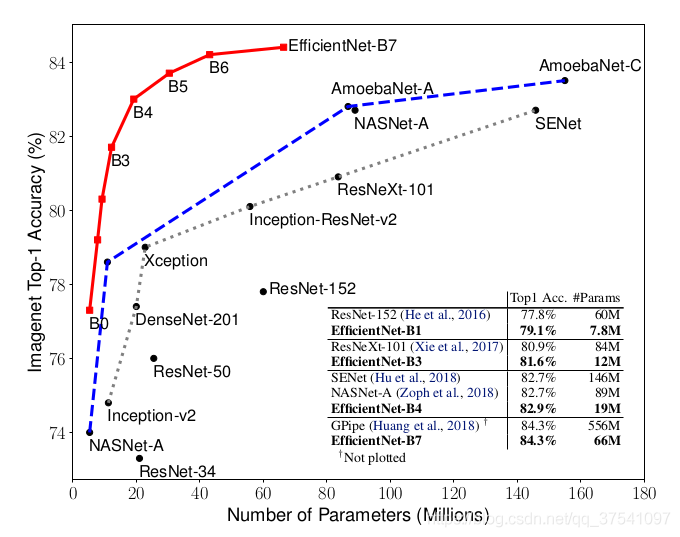
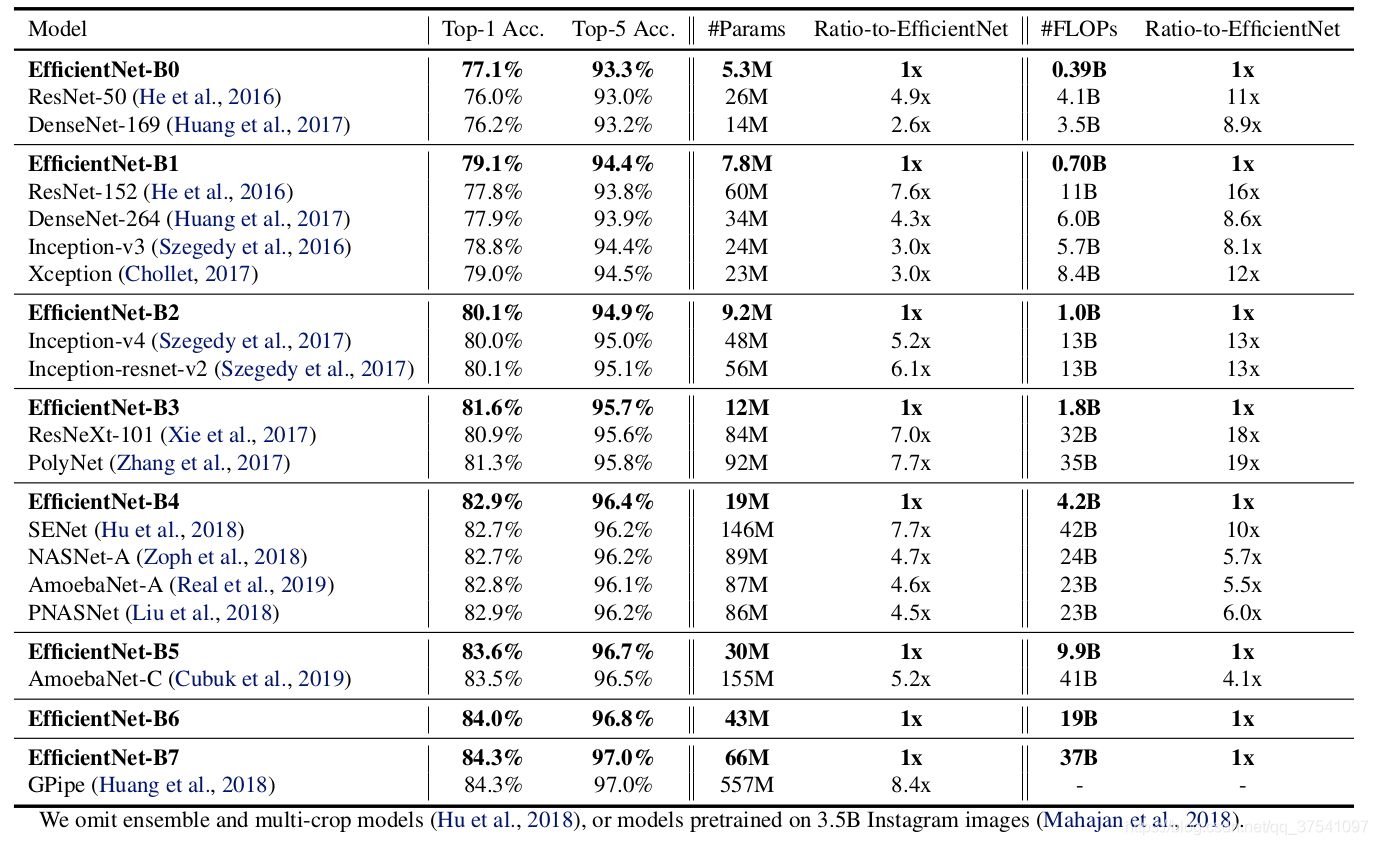
width三個引數的合理化配置,在之前的一些論文中,基本都是通過改變上述3個引數中的一個來提升網路的性能,而這篇論文就是同時來探索這三個引數的影響,在論文中提到,本文提出的EfficientNet-B7在Imagenet top-1上達到了當年最高準確率84.3%,與之前準確率最高的GPipe相比,引數數量(Params)僅為其1/8.4,推理速度提升了6.1倍(看上去又快又輕量,但個人實際使用起來發現很吃顯存),下圖是EfficientNet與其他網路的對比(注意,引數數量少并不意味推理速度就快),
論文思想
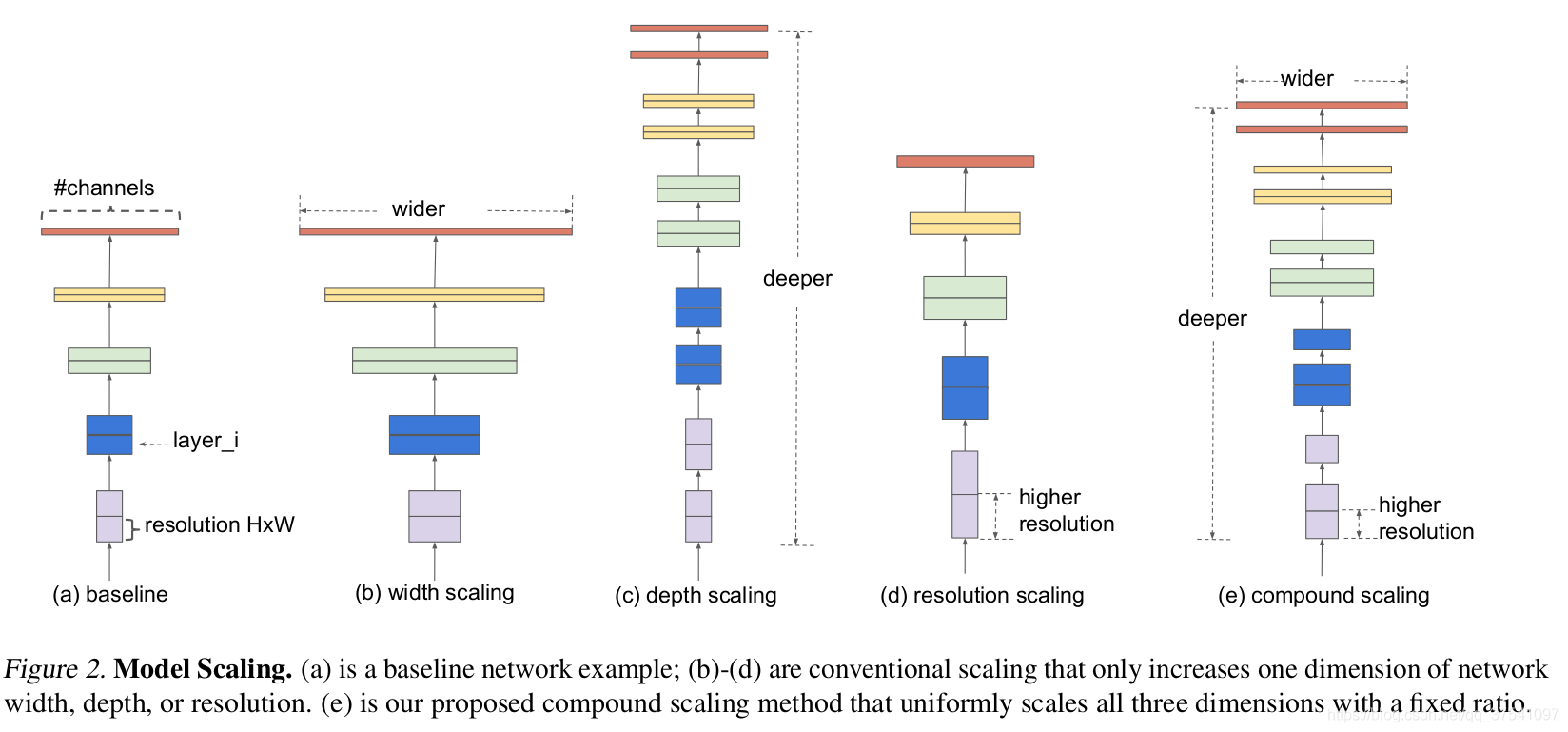
在之前的一些論文中,有的會通過增加網路的width即增加卷積核的個數(增加特征矩陣的channels)來提升網路的性能如圖(b)所示,有的會通過增加網路的深度即使用更多的層結構來提升網路的性能如圖(c)所示,有的會通過增加輸入網路的解析度來提升網路的性能如圖(d)所示,而在本篇論文中會同時增加網路的width、網路的深度以及輸入網路的解析度來提升網路的性能如圖(e)所示:
-
根據以往的經驗,增加網路的深度
depth能夠得到更加豐富、復雜的特征并且能夠很好的應用到其它任務中,但網路的深度過深會面臨梯度消失,訓練困難的問題,
The intuition is that deeper ConvNet can capture richer and more complex features, and generalize well on new tasks. However, deeper networks are also more difficult to train due to the vanishing gradient problem -
增加網路的
width能夠獲得更高細粒度的特征并且也更容易訓練,但對于width很大而深度較淺的網路往往很難學習到更深層次的特征,
wider networks tend to be able to capture more fine-grained features and are easier to train. However, extremely wide but shallow networks tend to have difficulties in capturing higher level features. -
增加輸入網路的影像解析度能夠潛在得獲得更高細粒度的特征模板,但對于非常高的輸入解析度,準確率的增益也會減小,并且大解析度影像會增加計算量,
With higher resolution input images, ConvNets can potentially capture more fine-grained patterns. but the accuracy gain diminishes for very high resolutions.
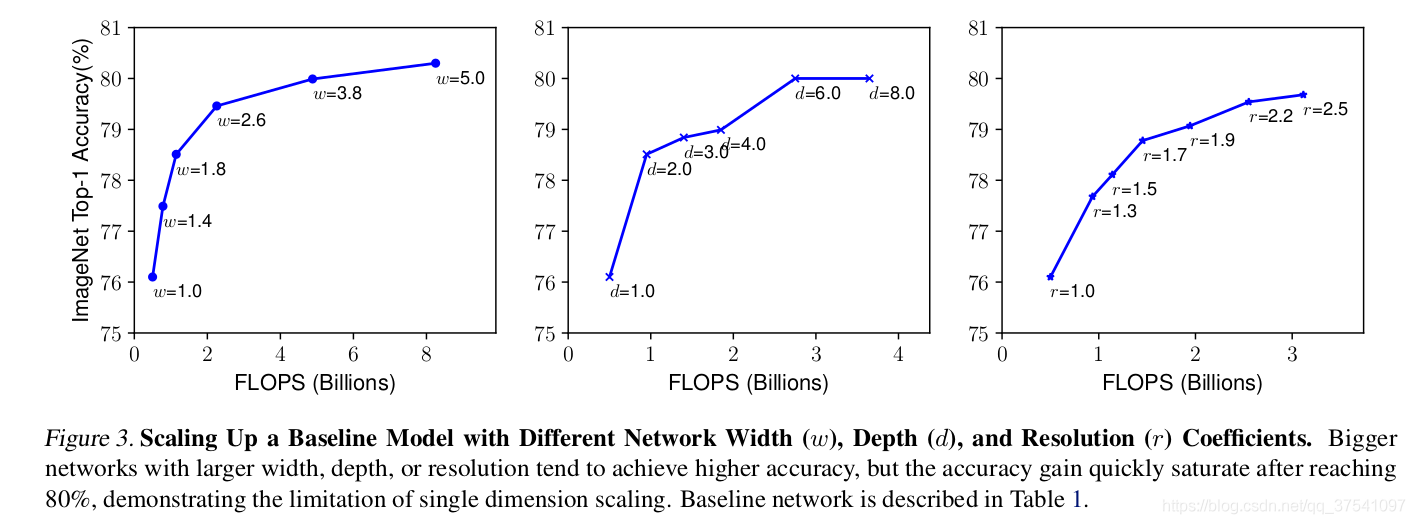
下圖展示了在基準EfficientNetB-0上分別增加width、depth以及resolution后得到的統計結果,通過下圖可以看出大概在Accuracy達到80%時就趨于飽和了,
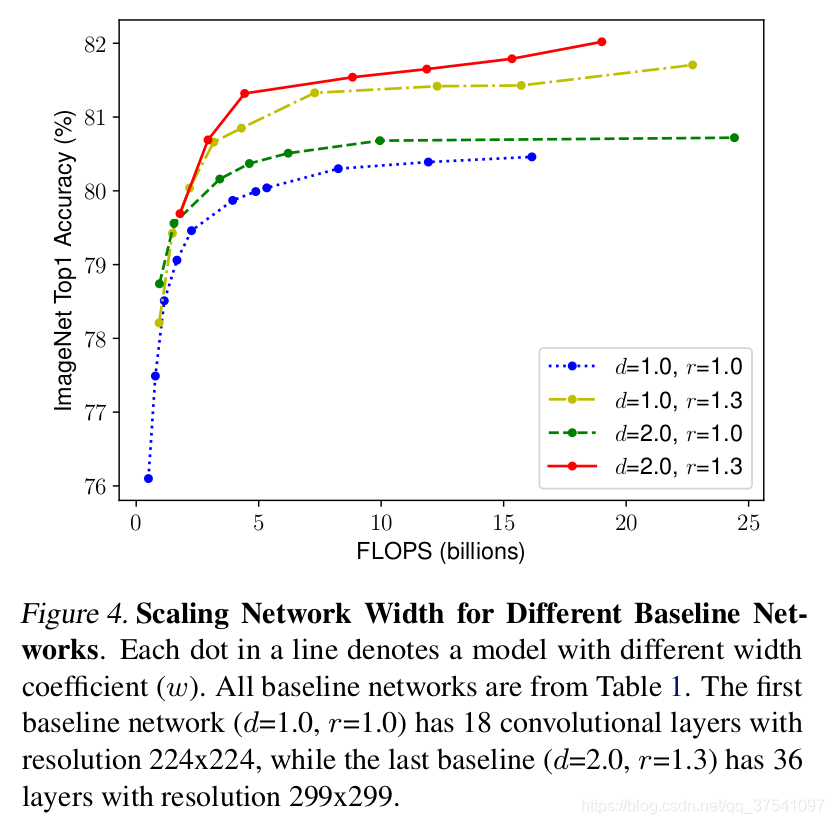
接著作者又做了一個實驗,采用不同的
d
,
r
d, r
d,r組合,然后不斷改變網路的width就得到了如下圖所示的4條曲線,通過分析可以發現在相同的FLOPs下,同時增加
d
d
d和
r
r
r的效果最好,
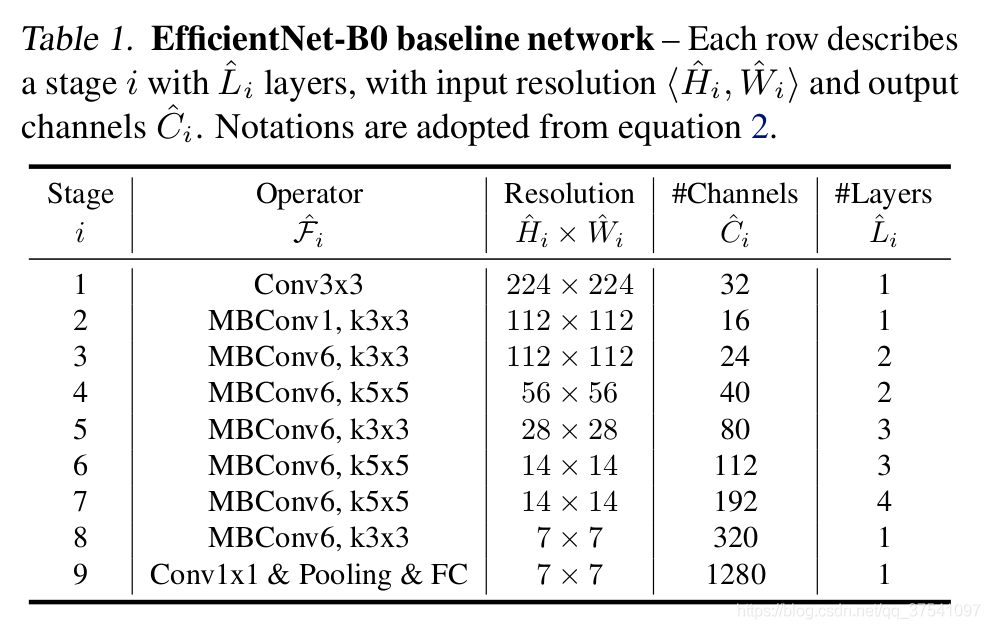
為了方便后續理解,我們先看下論文中通過 NAS(Neural Architecture Search) 技術搜索得到的EfficientNetB0的結構,如下圖所示,整個網路框架由一系列Stage組成,
F
^
i
\widehat{F}_i
F
i?表示對應Stage的運算操作,
L
^
i
\widehat{L}_i
L
i?表示在該Stage中重復
F
^
i
\widehat{F}_i
F
i?的次數:
作者在論文中對整個網路的運算進行抽象:
N
(
d
,
w
,
r
)
=
⊙
i
=
1...
s
F
i
L
i
(
X
?
H
i
,
W
i
,
C
i
?
)
N(d,w,r)=\underset{i=1...s}{\odot} {F}_i^{L_i}(X_{\left\langle{{H}_i, {W}_i, {C}_i } \right\rangle})
N(d,w,r)=i=1...s⊙?FiLi??(X?Hi?,Wi?,Ci???)
其中:
- ⊙ i = 1... s \underset{i=1...s}{\odot} i=1...s⊙?表示連乘運算,
-
F
i
{F}_i
Fi?表示一個運算操作(如上圖中的
Operator),那么 F i L i {F}_i^{L_i} FiLi??表示在 S t a g e i {\rm Stage}i Stagei中 F i {F}_i Fi?運算被重復執行 L i L_i Li?次, -
X
X
X表示輸入
S
t
a
g
e
i
{\rm Stage}i
Stagei的特征矩陣(
input tensor), -
?
H
i
,
W
i
,
C
i
?
{\left\langle{{H}_i, {W}_i, {C}_i } \right\rangle}
?Hi?,Wi?,Ci??表示
X
X
X的高度,寬度,以及Channels(
shape),
為了探究
d
,
r
,
w
d, r, w
d,r,w這三個因子對最終準確率的影響,則將
d
,
r
,
w
d, r, w
d,r,w加入到公式中,我們可以得到抽象化后的優化問題(在指定資源限制下),其中
s
.
t
.
s.t.
s.t.代表限制條件:
Our target is to maximize the model accuracy for any given resource constraints, which can be formulated as an optimization problem:
m
a
x
d
,
w
,
r
A
c
c
u
r
a
c
y
(
N
(
d
,
w
,
r
)
)
s
.
t
.
N
(
d
,
w
,
r
)
=
⊙
i
=
1...
s
F
^
i
d
?
L
^
i
(
X
?
r
?
H
^
i
,
r
?
W
^
i
,
w
?
C
^
i
?
)
M
e
m
o
r
y
(
N
)
≤
t
a
r
g
e
t
_
m
e
m
o
r
y
F
L
O
P
s
(
N
)
≤
t
a
r
g
e
t
_
f
l
o
p
s
(
2
)
\underset{d, w, r}{max} \ \ \ \ \ Accuracy(N(d, w, r)) \\ s.t. \ \ \ \ N(d,w,r)=\underset{i=1...s}{\odot} \widehat{F}_i^{d \cdot \widehat{L}_i}(X_{\left\langle{r \cdot \widehat{H}_i, \ r \cdot \widehat{W}_i, \ w \cdot \widehat{C}_i } \right\rangle}) \\ Memory(N) \leq {\rm target\_memory} \\ \ \ \ \ \ \ \ \ \ \ FLOPs(N) \leq {\rm target\_flops} \ \ \ \ \ \ \ \ (2)
d,w,rmax? Accuracy(N(d,w,r))s.t. N(d,w,r)=i=1...s⊙?F
id?L
i??(X?r?H
i?, r?W
i?, w?C
i???)Memory(N)≤target_memory FLOPs(N)≤target_flops (2)
其中:
- d d d用來縮放深度 L ^ i \widehat{L}_i L i?
- r r r用來縮放解析度即影響 H ^ i \widehat{H}_i H i?和 W ^ i \widehat{W}_i W i?
-
w
w
w就是用來縮放特征矩陣的
channel即 C ^ i \widehat{C}_i C i? target_memory為memory限制target_flops為FLOPs限制
接著作者又提出了一個混合縮放方法 ( compound scaling method) 在這個方法中使用了一個混合因子
?
\phi
?去統一的縮放width,depth,resolution引數,具體的計算公式如下,其中
s
.
t
.
s.t.
s.t.代表限制條件:
d
e
p
t
h
:
d
=
α
?
w
i
d
t
h
:
w
=
β
?
r
e
s
o
l
u
t
i
o
n
:
r
=
γ
?
(
3
)
s
.
t
.
α
?
β
2
?
γ
2
≈
2
α
≥
1
,
β
≥
1
,
γ
≥
1
depth: d={\alpha}^{\phi} \\ width: w={\beta}^{\phi} \\ \ \ \ \ \ \ resolution: r={\gamma}^{\phi} \ \ \ \ \ \ \ \ \ \ (3) \\ s.t. \ \ \ \ \ \ \ {\alpha} \cdot {\beta}^{2} \cdot {\gamma}^{2} \approx 2 \\ \alpha \geq 1, \beta \geq 1, \gamma \geq 1 \ \ \ \ \ \
depth:d=α?width:w=β? resolution:r=γ? (3)s.t. α?β2?γ2≈2α≥1,β≥1,γ≥1
注意:
- FLOPs(理論計算量)與
depth的關系是:當depth翻倍,FLOPs也翻倍, - FLOPs與
width的關系是:當width翻倍(即channal翻倍),FLOPs會翻4倍,因為卷積層的FLOPs約等于 f e a t u r e w × f e a t u r e h × f e a t u r e c × k e r n e l w × k e r n e l h × k e r n e l n u m b e r feature_w \times feature_h \times feature_c \times kernel_w \times kernel_h \times kernel_{number} featurew?×featureh?×featurec?×kernelw?×kernelh?×kernelnumber?(假設輸入輸出特征矩陣的高寬不變),當width翻倍,輸入特征矩陣的channels( f e a t u r e c feature_c featurec?)和輸出特征矩陣的channels或卷積核的個數( k e r n e l n u m b e r kernel_{number} kernelnumber?)都會翻倍,所以FLOPs會翻4倍 - FLOPs與
resolution的關系是:當resolution翻倍,FLOPs也會翻4倍,和上面類似因為特征矩陣的寬度 f e a t u r e w feature_w featurew?和特征矩陣的高度 f e a t u r e h feature_h featureh?都會翻倍,
所以總的FLOPs倍率可以用近似用 ( α ? β 2 ? γ 2 ) ? (\alpha \cdot \beta^{2} \cdot \gamma^{2})^{\phi} (α?β2?γ2)?來表示,當限制 α ? β 2 ? γ 2 ≈ 2 \alpha \cdot \beta^{2} \cdot \gamma^{2} \approx 2 α?β2?γ2≈2時,對于任意一個 ? \phi ?而言FLOPs相當增加了 2 ? 2^{\phi} 2?倍,
接下來作者在基準網路EfficientNetB-0(在后面的網路詳細結構章節會詳細講)上使用NAS來搜索 α , β , γ \alpha, \beta, \gamma α,β,γ這三個引數,
- (step1)首先固定 ? = 1 \phi=1 ?=1,并基于上面給出的公式(2)和(3)進行搜索,作者發現對于EfficientNetB-0最佳引數為 α = 1.2 , β = 1.1 , γ = 1.15 \alpha=1.2, \beta=1.1, \gamma=1.15 α=1.2,β=1.1,γ=1.15
- (step2)接著固定 α = 1.2 , β = 1.1 , γ = 1.15 \alpha=1.2, \beta=1.1, \gamma=1.15 α=1.2,β=1.1,γ=1.15,在EfficientNetB-0的基礎上使用不同的 ? \phi ?分別得到EfficientNetB-1至EfficientNetB-7(在后面的EfficientNet(B0-B7)引數章節有給出詳細引數)
需要注意的是,對于不同的基準網路搜索出的
α
,
β
,
γ
\alpha, \beta, \gamma
α,β,γ也不定相同,還需要注意的是,在原論文中,作者也說了,如果直接在大模型上去搜索
α
,
β
,
γ
\alpha, \beta, \gamma
α,β,γ可能獲得更好的結果,但是在較大的模型中搜索成本太大(Google大廠居然說這種話),所以這篇文章就在比較小的EfficientNetB-0模型上進行搜索的,
Notably, it is possible to achieve even better performance by searching for α, β, γ directly around a large model, but the search cost becomes prohibitively more expensive on larger models. Our method solves this issue by only doing search once on the small baseline network (step 1), and then use the same scaling coefficients for all other models (step 2).
網路詳細結構
下表為EfficientNet-B0的網路框架(B1-B7就是在B0的基礎上修改Resolution,Channels以及Layers),可以看出網路總共分成了9個Stage,第一個Stage就是一個卷積核大小為3x3步距為2的普通卷積層(包含BN和激活函式Swish),Stage2~Stage8都是在重復堆疊MBConv結構(最后一列的Layers表示該Stage重復MBConv結構多少次),而Stage9由一個普通的1x1的卷積層(包含BN和激活函式Swish)一個平均池化層和一個全連接層組成,表格中每個MBConv后會跟一個數字1或6,這里的1或6就是倍率因子n即MBConv中第一個1x1的卷積層會將輸入特征矩陣的channels擴充為n倍,其中k3x3或k5x5表示MBConv中Depthwise Conv所采用的卷積核大小,Channels表示通過該Stage后輸出特征矩陣的Channels,
MBConv結構
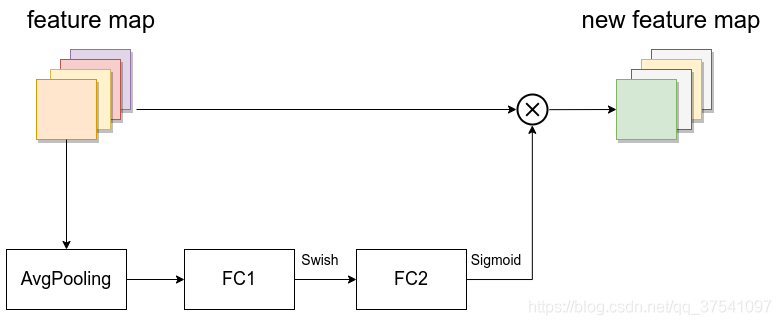
MBConv其實就是MobileNetV3網路中的InvertedResidualBlock,但也有些許區別,一個是采用的激活函式不一樣(EfficientNet的MBConv中使用的都是Swish激活函式),另一個是在每個MBConv中都加入了SE(Squeeze-and-Excitation)模塊,下圖是我自己繪制的MBConv結構,
 如圖所示,
如圖所示,MBConv結構主要由一個1x1的普通卷積(升維作用,包含BN和Swish),一個3x3的Depthwise Conv卷積(包含BN和Swish),一個SE模塊,一個1x1的普通卷積(降維作用,包含BN),一個Droupout層構成,搭建程序中還需要注意幾點:
- 第一個升維的
1x1卷積層,它的卷積核個數是輸入特征矩陣channel的 n n n倍, n ∈ { 1 , 6 } n \in \left\{1, 6\right\} n∈{1,6}, - 當
n
=
1
n=1
n=1時,不要第一個升維的
1x1卷積層,即Stage2中的MBConv結構都沒有第一個升維的1x1卷積層(這和MobileNetV3網路類似), - 關于
shortcut連接,僅當輸入MBConv結構的特征矩陣與輸出的特征矩陣shape相同時才存在(代碼中可通過stride==1 and inputc_channels==output_channels條件來判斷), - SE模塊如下所示,由一個全域平均池化,兩個全連接層組成,第一個全連接層的節點個數是輸入該
MBConv特征矩陣channels的 1 4 \frac{1}{4} 41?,且使用Swish激活函式,第二個全連接層的節點個數等于Depthwise Conv層輸出的特征矩陣channels,且使用Sigmoid激活函式,
EfficientNet(B0-B7)引數
還是先給出EfficientNetB0的網路結構,方便后面理解,
通過上面的內容,我們是可以搭建出EfficientNetB0網路的,其他版本的詳細引數可見下表:
| Model | input_size | width_coefficient | depth_coefficient | dropout_ratio |
|---|---|---|---|---|
| EfficientNetB0 | 224x224 | 1.0 | 1.0 | 0.2 |
| EfficientNetB1 | 240x240 | 1.0 | 1.1 | 0.2 |
| EfficientNetB2 | 260x260 | 1.1 | 1.2 | 0.3 |
| EfficientNetB3 | 300x300 | 1.2 | 1.4 | 0.3 |
| EfficientNetB4 | 380x380 | 1.4 | 1.8 | 0.4 |
| EfficientNetB5 | 456x456 | 1.6 | 2.2 | 0.4 |
| EfficientNetB6 | 528x528 | 1.8 | 2.6 | 0.5 |
| EfficientNetB7 | 600x600 | 2.0 | 3.1 | 0.5 |
input_size代表訓練網路時輸入網路的影像大小width_coefficient代表channel維度上的倍增因子,比如在 EfficientNetB0中Stage1的3x3卷積層所使用的卷積核個數是32,那么在B6中就是 32 × 1.8 = 57.6 32 \times 1.8=57.6 32×1.8=57.6接著取整到離它最近的8的整數倍即56,其它Stage同理,depth_coefficient代表depth維度上的倍率因子(僅針對Stage2到Stage8),比如在EfficientNetB0中Stage7的 L ^ i = 4 {\widehat L}_i=4 L i?=4,那么在B6中就是 4 × 2.6 = 10.4 4 \times 2.6=10.4 4×2.6=10.4接著向上取整即11.dropout_ratio即MBConv結構中的dropout層的drop_rate,在官方keras模塊的實作中MBConv結構的drop_rate是從0遞增到dropout_ratio的(具體實作可以看下原始碼),
最后給出原論文中關于EfficientNet與當時主流網路的性能引數對比:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/267506.html
標籤:AI
上一篇:K8S基礎
下一篇:c語言 由字串轉ASCII碼