小白剛開始學爬蟲,xpath決議不知道為什么用不了,求大神指正

不知道為什么,xpath只能獲取到body標簽
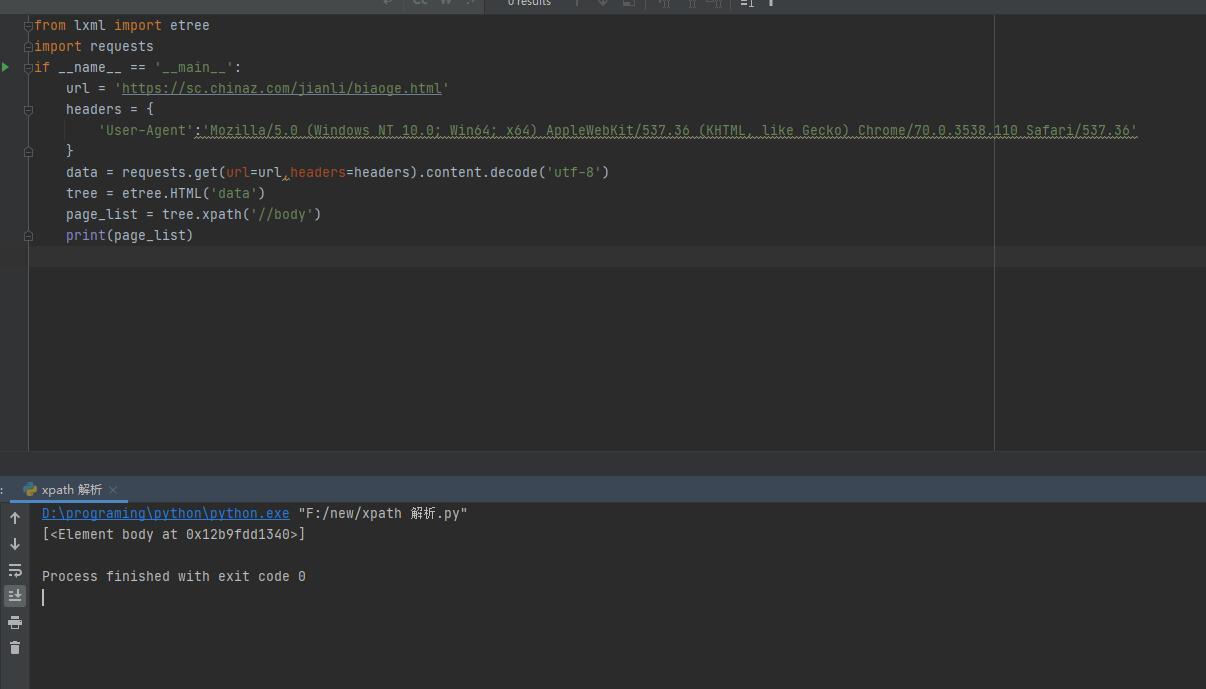
在決議路徑body標簽后面加上div標簽后,回傳的就是一個空串列
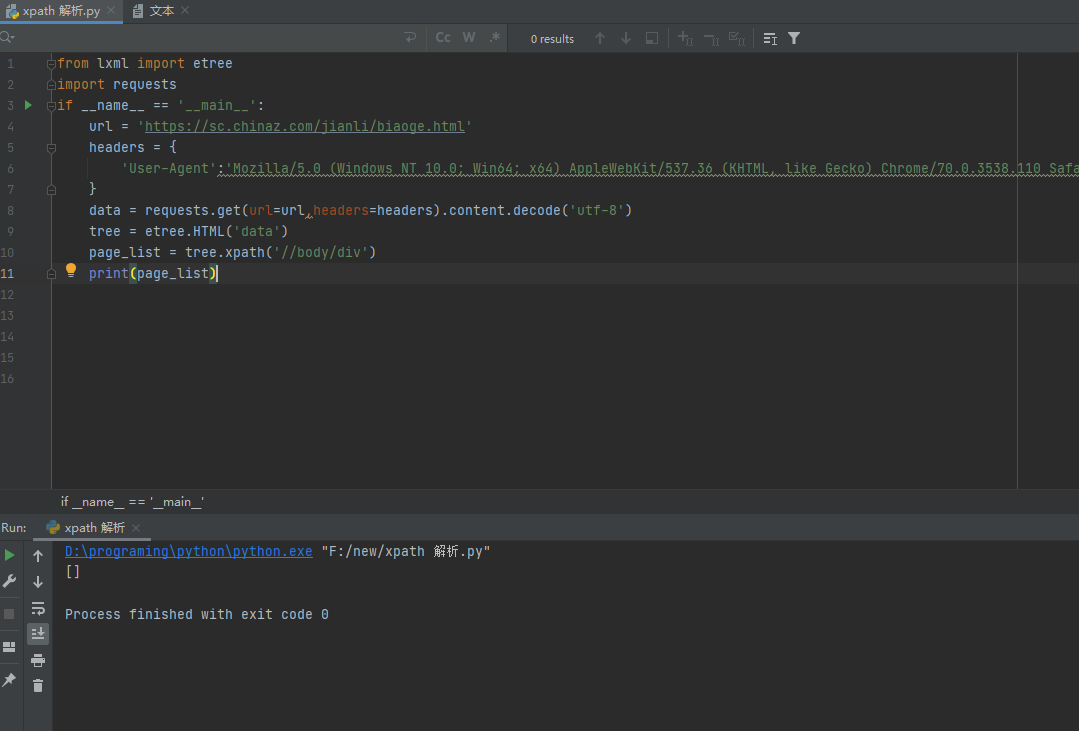
嘗試在body標簽后面加上text()獲取文本,回傳的也是一個空串列
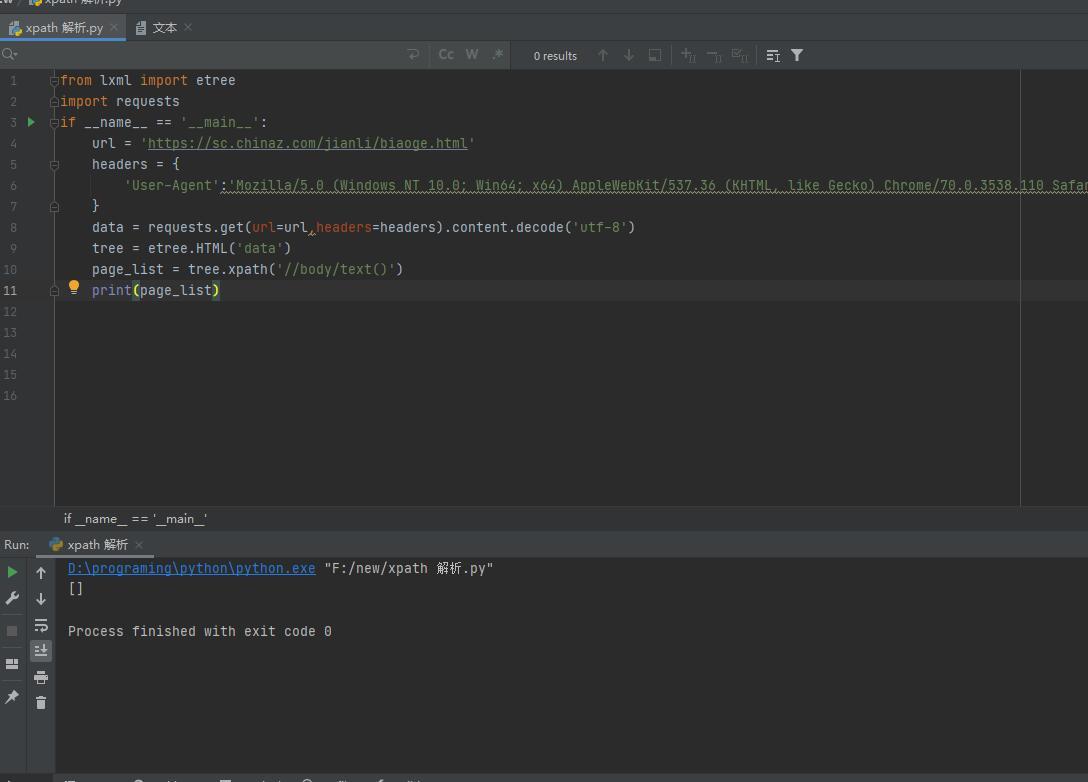
以下是代碼
from lxml import etree
import requests
if __name__ == '__main__':
url = 'https://sc.chinaz.com/jianli/biaoge.html'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}
data = requests.get(url=url,headers=headers).content.decode('utf-8')
tree = etree.HTML('data')
page_list = tree.xpath('//body/text()')
print(page_list)
uj5u.com熱心網友回復:
沒人么[face]monkey2:019.png[/face]轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/267548.html
標籤:其他