沒有找到對應板塊,暫時發布在這里,目的是讓大家0分,就可閱讀。
目前,本人業余從事足球資料的搜集整理挖掘作業,建立的資料集合用moddler c5.0來運算。結果如下:
訓練集 和驗證集的結果如下:
總數885多條,70%訓練,30%驗證。
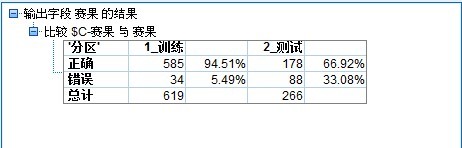
如上圖所示,訓練集存在一定的過擬合情況。
運算結果,即預測賽果和預測賽果可信度示例如下圖。
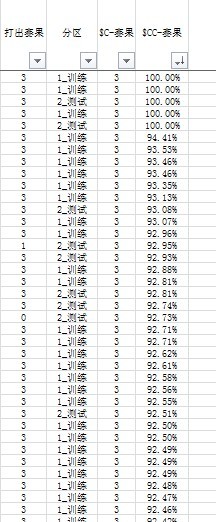
我的問題是:
第一,上邊訓練集合驗證集的混合結果,是否可以作為實際預測依據? 因為無論訓練集還是驗證集,有些比賽場次工具預測結果對應的可信度還是很高的(當然訓練集94%肯定有過擬合的情況),但 驗證集2的高可信度是否可以作為預測依據?
第二,有個極其有意思的發現,如果上述885條資料不做磁區,直接建模,也不考慮是否過擬合的問題,結果發現,如果預測可信度低于80%以上和以下,結果如下
:
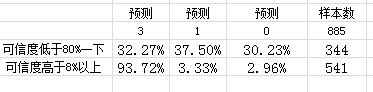
也就是說,不管c5.0運行結果是否過擬合,只要可信度在80%以上,主勝概率在93%,可單選3(說明總885個對陣,主勝賠率均低于2.0),同時可信度在80%以下的比賽場次,3、1、0三個結果出現的概率都是差不多的,預示,一旦預測可信度低于80%,這種比賽就可全包。十分神奇,也十分不解。
疑惑:不考慮過擬合與否,如上結果說明一個問題,c5.0把885個對陣,有效的分為兩大類比賽,即一類打出3的結果較高,一類最好全包。
以上從基本資料挖掘來分析,覺得矛盾很多---比如過擬合的問題,但是即使過擬合的情況下,運算結果卻給出一個意外的“分類”的“驚喜”。
上述,不知該作何解釋?
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/268384.html
標籤:人工智能技術