前言:
這篇文章主要講 explain 如何使用,還有 explain 各種引數概念,之后會講優化
一、Explain 用法
模擬Mysql優化器是如何執行SQL查詢陳述句的,從而知道Mysql是如何處理你的SQL陳述句的,分析你的查詢陳述句或是表結構的性能瓶頸,
語法:Explain + SQL 陳述句;
如:Explain select * from user; 會生成如下 SQL 分析結果,下面詳細對每個欄位進行詳解

二、id
是一組數字,代表多個表之間的查詢順序,或者包含子句查詢陳述句中的順序,id 總共分為三種情況,依次詳解
- id 相同,執行順序由上至下
- id 不同,如果是子查詢,id 號會遞增,id 值越大優先級越高,越先被執行
- id 相同和不同的情況同時存在
三、select_type
select_type 包含以下幾種值
- simple
- primary
- subquery
- derived
- union
- union result
simple
簡單的 select 查詢,查詢中不包含子查詢或者 union 查詢
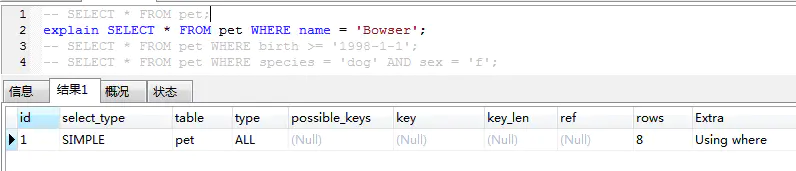
primary
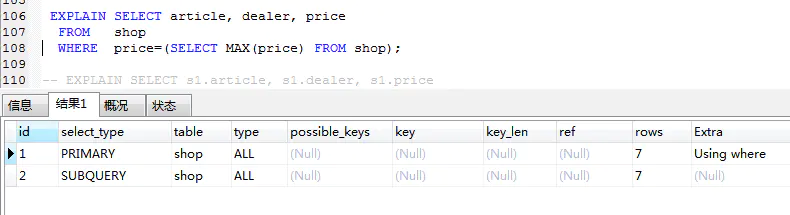
如果 SQL 陳述句中包含任何子查詢,那么子查詢的最外層會被標記為 primary
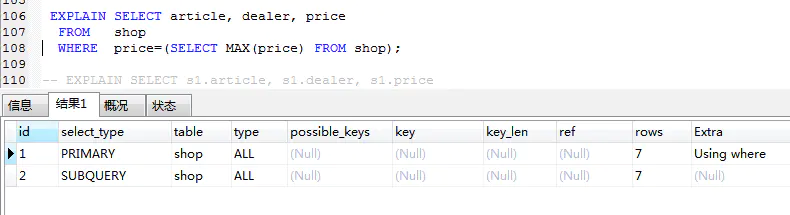
subquery
在 select 或者 where 里包含了子查詢,那么子查詢就會被標記為 subQquery,同三.二同時出現
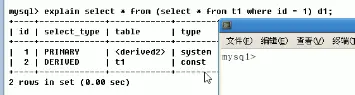
derived
在 from 中包含的子查詢,會被標記為衍生查詢,會把查詢結果放到一個臨時表中
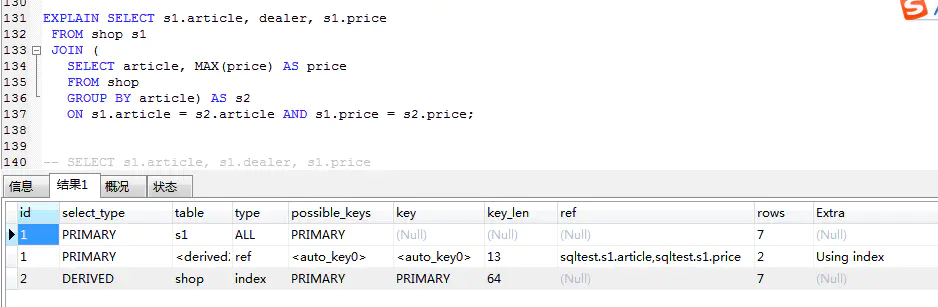
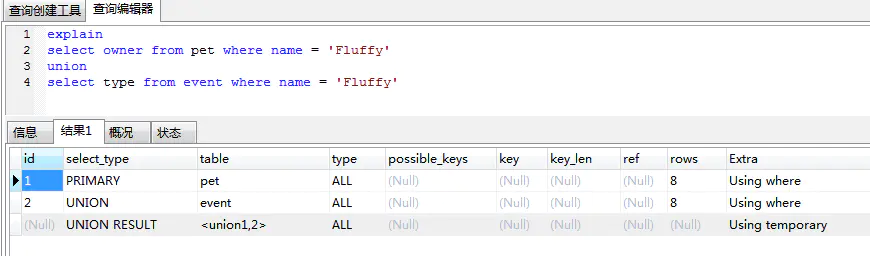
union / union result
如果有兩個 select 查詢陳述句,他們之間用 union 連起來查詢,那么第二個 select 會被標記為 union,union 的結果被標記為 union result,它的 id 是為 null 的
四、table
表示這一行的資料是哪張表的資料
五、type
type 是代表 MySQL 使用了哪種索引型別,不同的索引型別的查詢效率也是不一樣的,type 大致有以下種類
- system
- const
- eq_ref
- ref
- range
- index
- all
system
表中只有一行記錄,system 是 const 的特例,幾乎不會出現這種情況,可以忽略不計
const
將主鍵索引或者唯一索引放到 where 條件中查詢,MySQL 可以將查詢條件轉變成一個常量,只匹配一行資料,索引一次就找到資料了
eq_ref
在多表查詢中,如 T1 和 T2,T1 中的一行記錄,在 T2 中也只能找到唯一的一行,說白了就是 T1 和 T2 關聯查詢的條件都是主鍵索引或者唯一索引,這樣才能保證 T1 每一行記錄只對應 T2 的一行記錄
舉個不太恰當的例子,EXPLAIN SELECT * from t1 , t2 where t1.id = t2.id

ref
不是主鍵索引,也不是唯一索引,就是普通的索引,可能會回傳多個符合條件的行,

range
體現在對某個索引進行區間范圍檢索,一般出現在 where 條件中的 between、and、<、>、in 等范圍查找中,

index
將所有的索引樹都遍歷一遍,查找到符合條件的行,索引檔案比資料檔案還是要小很多,所以比不用索引全表掃描還是要快很多,
all
沒用到索引,單純的將表資料全部都遍歷一遍,查找到符合條件的資料
六、possible_keys
此次查詢中涉及欄位上若存在索引,則會被列出來,表示可能會用到的索引,但并不是實際上一定會用到的索引
七、key
此次查詢中實際上用到的索引
八、key_len
表示索引中使用的位元組數,通過該屬性可以知道在查詢中使用的索引長度,注意:這個長度是最大可能長度,并非實際使用長度,在不損失精確性的情況下,長度越短查詢效率越高
九、ref
顯示關聯的欄位,如果使用常數等值查詢,則顯示 const,如果是連接查詢,則會顯示關聯的欄位,

- tb_emp 表為非唯一性索引掃描,實際使用的索引列為 idx_name,由于 tb_emp.name='rose'為一個常量,所以 ref=const,
- tb_dept 為唯一索引掃描,從 sql 陳述句可以看出,實際使用了 PRIMARY 主鍵索引,ref=db01.tb_emp.deptid 表示關聯了 db01 資料庫中 tb_emp 表的 deptid 欄位,
十、rows
根據表資訊統計以及索引的使用情況,大致估算說要找到所需記錄需要讀取的行數,rows 越小越好
十一、extra
不適合在其他列顯示出來,但在優化時十分重要的資訊
using fileSort(重點優化)
俗稱 " 檔案排序 " ,在資料量大的時候幾乎是“九死一生”,在 order by 或者在 group by 排序的程序中,order by 的欄位不是索引欄位,或者 select 查詢欄位存在不是索引欄位,或者 select 查詢欄位都是索引欄位,但是 order by 欄位和 select 索引欄位的順序不一致,都會導致 fileSort

using temporary(重點優化)
使用了臨時表保存中間結果,常見于 order by 和 group by 中,
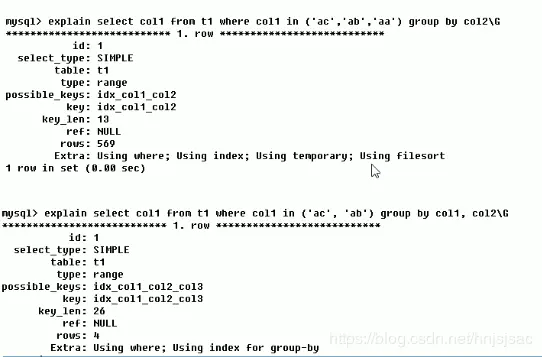
USING index(重點)
表示相應的 select 操作中使用了覆寫索引(Coveing Index),避免訪問了表的資料行,效率不錯! 如果同時出現 using where,表明索引被用來執行索引鍵值的查找;如果沒有同時出現 using where,表面索參考來讀取資料而非執行查找動作,

Using wher
表明使用了 where 過濾
using join buffer
使用了連接快取
impossible where
where 子句的值總是 false,不能用來獲取任何元組
select tables optimized away
在沒有 GROUPBY 子句的情況下,基于索引優化 MIN/MAX 操作或者 對于 MyISAM 存盤引擎優化 COUNT(*)操作,不必等到執行階段再進行計算, 查詢執行計劃生成的階段即完成優化,
distinct
優化 distinct,在找到第一匹配的元組后即停止找同樣值的作業
作者:IT老哥
鏈接:https://juejin.im/post/5f0535dae51d45348d39ffbe
來源:掘金
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/26911.html
標籤:其他